
基于Spark的并行ALS协同过滤算法研究∗
2017-12-18 06:21侯敬儒李英娜
计算机与数字工程 2017年11期
侯敬儒 吴 晟 李英娜
(昆明理工大学信息工程与自动化学院 昆明 650500)
基于Spark的并行ALS协同过滤算法研究∗
侯敬儒 吴 晟 李英娜
(昆明理工大学信息工程与自动化学院 昆明 650500)
ALS(最小二乘法)协同过滤推荐算法是通过矩阵分解进行推荐,它通过综合大量的用户评分数据进行计算,并存储计算过程中产生的大量特征矩阵。Hadoop的HA(高可用性)用来解决HDFS分布式文件系统的NameNode单点故障问题。Spark是一种基于内存的新型分布式大数据计算框架,具有优异的计算性能。文章基于QJM(Quorum Journal Manager)构建了HA下的Hadoop大数据平台,并在Spark计算框架基础上研究使用ALS协同过滤算法,实现基于ALS协同过滤算法在Spark上的并行化运行;通过和基于Hadoop的MapReduce思想的ALS协同过滤算法在Netflix数据集上的比对实验表明,基于Spark平台的ALS协同过滤算法的并行化计算效率有明显提升,并且更适合处理海量数据。
ALS;协同过滤;矩阵分解;High Available;Spark
1 引言
当前,整个世界已经迎来了大数据时代,在新零售等新兴业态形式下,互联网用户飞速增长以及互联网科技迅猛发展,在以用户为中心的信息生产模式下,互联网信息爆炸式增长[1],不仅数据量越来越大,数据类型也越来越大,人们正面临着严重的“信息过载”问题[2]。目前,解决该问题的技术主要分为两类,第一类是信息检索技术-搜索引擎,第二类是信息过滤技术-推荐系统[3]。区别在于搜索引擎依赖用户对信息的准确描述,而推荐系统则是以用户历史行为和数据为基点,建立相关数据模型从而挖掘出用户需求和兴趣,从而以此为依据从海量的信息中为用户筛选出用户感兴趣的信息。由此可见,在用户需求不明确时,推荐系统的作用显得尤为重要。
推荐系统中的协同过滤推荐技术简单、高效,得到了业界广泛的认同和应用。然而协同过滤技术也有缺点和不足,例如可扩展的问题、数据稀疏的问题、冷启动的问题,这些问题往往会导致推荐系统的推荐质量下降[4]。文章主要介绍的基于Spark的并行ALS协同过滤推荐算法模型中,通过一组隐性因子来预测缺失元素和表达用户和商品。其所用的学习潜在因子的方法就是交替ALS最小二乘法。
2 HA(High Available)集群构建
2.1 HA集群特点
一个成熟的企业级HA集群,在任何时间,只有一个NameNode处于活动状态,而另一个在备份状态,活动状态的NameNode会响应集群中所有的客户端,同时备份的只是作为一个副本,保证在必要的时候提供一个快速的转移[5]。
为了使备份的节点和活动的节点保持一致,两个节点通过一个特殊的守护线程相连,这个线程叫做“JournalNodes”(JNs)。当活动状态的节点(Active NameNode)因为新的分布式应用而修改命名空间(NameSpace),它均会通过线程JNs记录日志,备用的节点可以监控edit日志的变化,并且通过JNs读取到变化。备份节点查看edits可以拥有专门的namespace。在故障转移的时候备份节点将在切换至活动状态前确认它从JNs读取到的所有edits。这个确认的目的是为了保证NameSpace的状态和迁移之前是完全同步的。为了提供一个快速的转移,备份NameNode要求保存着最新的block在集群当中的信息。为了能够得到这个,DataNode都被配置了所有的NameNode的地址,并且发送block的地址信息和心跳给两个node。
2.2 HA集群配置
2.2.1 基于QJM(Quorum Journal Manager)配置HA集群原理
QJM是基于Paxos算法的,如果配置2N+1台JournalNode组成的集群,则最多能容忍N台机器down机。QJM的体系结构如图1所示。

图1 QJM体系结构
用QJM的方式实现HA的主要好处有以下几
点:
1)不再需要单独配置Fencing实现,因为QJM本身内置了Fencing的功能。
2)不存在单点故障。
3)系统健壮性的程度是可配置的。
4)存储日志的JournalNode不会因为其中一台的延迟而影响整体的延迟,也不会因为JournalNode的数量增多而影响性能。
图2所示为该实验环境下由3个计算节点,2个控制节点组成的HA集群的拓扑结构图例,各个节点之间使用局域网连接。
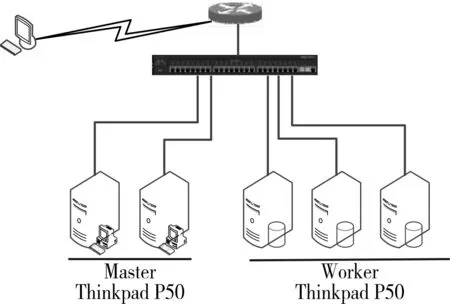
图2 集群拓扑结构
2.2.2 环境配置说明
ZooKeeper是提供一致性服务的软件,它的功能包括:配置维护、名字服务、分布式同步、组服务等[6~7]。该实验环境中使用Zookeeper保证Master节点down机之后能够快速切换到StandByMaster,继续为集群提供服务,从而使得整个集群正常工作,同时,也修复down机的Master。该环境部署的HA下的大数据实验平台由5台机器构成,包括2个Master节点和3个Worker节点,节点之间局域网连接。
该环境以Hadoop的HDFS为基础存储框架,主要以Spark为计算框架,Zookeeper统筹HA下的大数据平台,管理整个集群配置。具体5个节点的具体功能如表1所示。

表1 节点功能
2.2.3 修改Zookeeper配置过程
1)确定Zookeeper的数据存放位置,并且设定server的端口,响应时间等:
vim zoo.cfg
dataDir=/home/sparker/zookeeper-3.4.5/data
server.1=sparker000:2888:3888
server.2=sparker001:2888:3888
server.3=sparker005:2888:3888
tickTime=2000
initLimit=5
syncLimit=2
clientPort=2181
2)新建data文件夹:
/home/sparker000/zookeeper/下新建 data文件夹,然后在该文件夹下新建文件,文件名为myid,向其中加入server.1/2/3中的值,此处填1。
3)将安装完的Zookeeper分发到其他机器:
由于我们只在一台机器上安装了Zookeeper,所以需要将配置好的文件分发到其他的机器上,使用scp命令:
scp/-r/zookeeper-3.4.5 192.168.1.101:/home/sparker001/scp/-r/zookeeper-3.4.5 192.168.1.102:/home/sparker002/
修改101/102上中/data/myid的值。与server后面的值对应。在101中myid修改为2,在102中myid修改为3。
4)修改profile文件:
修改/etc/profile系统环境变量配置文件,加入zookeeper的环境变量
exportZOOKEEPER_HOME=/home/sparker000/zookeeper-3.4.5
exportPATH=$PATH:$ZOOKEEPER_HOME/bin
2.3 分布式计算框架-Spark
Apache Spark官方的定义为:Spark是一个通用的大规模数据快速处理引擎[8]。可以简单理解为Spark就是一个大数据分布式处理框架[8]。相比于传统的以Hadoop为基石的第一代大数据技术生态系统而言,Spark无论是性能还是方案的统一性都具有极为显著的优势。在Spark中,数据集的划分和任务的调度都是系统自动完成的,其工作流程如图3所示。

图3 Spark工作流程
其中,Driver是用户编写的Spark程序(用户编写的数据处理逻辑),这个逻辑中包含用户创建的SparkContext。SparkContext是用户逻辑与Spark集群主要的交互接口,它会和Cluster Manager交互,包括向它申请计算资源等。Cluster Manager负责集群的资源管理和调度,现在支持Standalone、Apache Mesos和Hadoop的Yarn。工作节点(Worker Node)是集群中可以执行计算任务的节点。Executor是在一个工作节点(Worker Node)上为某分布式应用程序启动的一个负责运行任务的进程,并且负责将所需要的数据存在内存或者磁盘上。每个应用都有各自独立的Executor,计算最终在计算节点的Executor中执行[9]。
3 基于Spark的ALS协同过滤算法研究
3.1 ALS协同过滤算法
基于矩阵分解模型的协同过滤推荐算法主要有:SVD(奇异值分解)和ALS[10]。下面就ALS算法理论做一个介绍。
对于Sm×n矩阵,ALS主要是找到2个低维矩阵Xm×k和Yn×k来近似逼近 Sm×n,即:
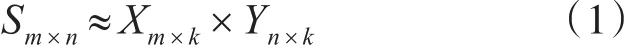
其中Sm×n表示用户对产品的偏好评分矩阵,Xm×k代表用户对隐含特征的偏好矩阵,Yn×k表示产品所包含的隐含特征矩阵。通常取k≪min(m,n),也就是相当于降维了。
为了找到使矩阵X和Y尽可能地无限接近S,需要最小化平方误差损失函数:

其中 Xi表示用户i的偏好的隐含特征向量,yj表示商品 j包含的隐含特征向量,sij表示用户i对商品 j的偏好评分,xiyjT是用户i对商品 j偏好评分的近似,λ表示正则化项的系数。其求解方法如下:
先固定Y,将误差损失函数L(X,Y)对 Xi求偏导,并另导数=0,得到:
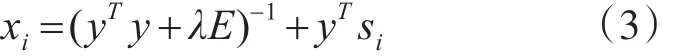
同理固定X,可得:

其中 xi是S的第i行,xj是S的第 j列,E是k×k的单位矩阵。
其迭代步骤是:首先随机初始化Y,利用式(3)更新得到 X,然后利用式(4)更新Y,直到RMSE(均方根误差)变化很小或者到达最大迭代次数为止[11]。其RMSE的计算公式如下:
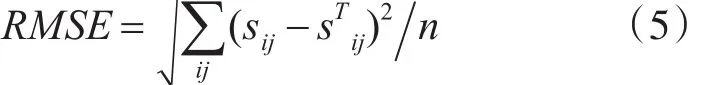
8)While iter<setValue//依据设定的次数迭代计算
9)Update user//更新User的因子矩阵
10)RDD[(Int,Array[Array[Double]])]⇒
11)Update item//更新Item的因子矩阵
12)End while
3.2 基于Spark的ALS协同过滤算法并行化实现
输入:评分数据
输出:矩阵分解模型
算法基本逻辑步骤如下:
1)var partitionNum//设置分区数
2)var sc=new SparkContext()
3)读入数据生成
Ratings:RDD[Rating],Ratings是序列
<user:Int,Item:Int,rating:Double>
4)依据用户设置或者默认的并行化数生成RatingsOfUserBlock、RatingsOfItemBlock的
RatingsOfUserBlock:Rating<u,p,R>—→——map<u,u,p,r>
RatingsOfItemBlock:Rating<u,p,R><p,p,u,r>
5)生成基于User或者Item的InLinkRDD(内连接信息)和OutLinkRDD(外连接信息)
6)将内外连接信息cache到内存中,减少磁盘I/O
7)初始化用户-项目因子矩阵
4 实验结果分析
4.1 实验数据集
本实验采用Netflix发布的电影评分数据集(TrainingSet、ProbeSetQualifyingSet)。该数据集包括用户数:480189,电影数:17770,评分数:103297638。其中,评分值都是整数值(1~5之间),分数越高则客户对相应电影的评分就越高。本实验分为两组,第一组使用整个数据集(665MB)为DataSet1;第二组随机抽取5000万条数据(330MB)作为DataSet2。将DataSet1、DataSet2分别分成两部分,其中90%归为训练数据集,10%归为测试数据集。
4.2 结果分析
文中分别做了两组实验,即基于ALS的协同过滤算法分别在基于Hadoop的MapReduce集群上和基于RDD的Spark集群上并行化实现。基于ALS的协同过滤算法模型中有两个参数:特征个数(复数范围内,矩阵的阶数和特征值个数是对应的)、迭代次数Iteration。
在第一组实验中,数据集采用DataSet1,设定默认特征个数为20,Iteration迭代次数依次为1、10、20、30、40、50,分别在集群上的实验结果如图4所示。

图4 DataSet1
由图4可以看出,随着Iteration的增加,基于ALS的协同过滤算法分别在两种集群上的运行时间比例也在增加,当迭代次数Iteration增加为50时,比例为3.3。由图4可知,当迭代次数设置为1次时,ALS协同过滤算法在基于Hadoop的MapReduce集群上运行时间比在基于内存的Spark集群上的运行时间短,原因是ALS协同过滤算法在基于内存的集群上的第一次迭代与基于Hadoop的MapReduce一样,需要创建新job,所以在基于内存的Spark集群上实现第一次迭代时运行速度比较慢。据之前分析,对基于Hadoop的MapReduce实现方式,每迭代一次就需要创建一个新的分布式job,如果迭代次数越多,需要执行的分布式job数量就越多。所以,随着迭代次数的增加,基于内存的Spark集群上的实现方式无需建立新的分布式job的优势得以发挥,该算法运算效率也提高的更明显。
在第二组实验中,数据集采用DataSet2,设定默认特征个数为20,Iteration迭代次数依次为1,10,20,30,40,50,分别在集群上的实验结果如图5所示。

图5 DataSet2
由图5可以看出,同第一组实验,随着Iteration的增加,基于ALS的协同过滤算法分别在两种集群上的运行时间比例也在增加,当迭代次数Iteration增加为50时,比例为2∶1。据之前分析可知,数据集越大创建新的分布式job所需要的时间就越久,基于内存的Spark集群实现方式比基于Hadoop的MapReduce实现方式优势更加明显,而第二组实验数据集DataSet2比第一组实验数据集DataSet1小,故第二组实验比第一组实验运行效率提高的比例小。
通过以上两组实验,可以看出当数据集越大,算法设置的迭代次数Iteration越多,并行ALS协同过滤算法在基于内存的Spark集群上的运算效率提高的就越多。
5 结语
文章构建了基于QJM的HA下的大数据平台,并通过对基于ALS即交替最小二乘法的协同过滤算法进行研究,将基于ALS的协同过滤算法分别在基于Hadoop的MapReduce和基于内存的Spark上并行化实现,在Netflix数据集上进行实验,结果表明通过在基于内存的Spark集群上提高了基于ALS协同过滤算法的分布式计算效率。
由于实验数据量还不够大,还不能看出基于内存的Spark对计算效率的显著提升,据之前的原理分析可知,如果数据量越大,基于内存的Spark计算效率的提升就会越明显。Spark作为基于内存的分布式数据处理框架,接下来需要展开的研究如下:1)智能化ALS模型训练参数的选择,帮助我们自动选择最优参数;2)基于Spark Streaming的ALS协同过滤算法研究。
[1]邓鹏,李枚毅,何诚.Namenode单点故障解决方案研究[J].计算机工程,2012,38(21):40-44.DENG Peng,LI Meiyi,HE Cheng.Research on Namenode Single Point of Fault Solution[J].Computer Engineering,2012,38(21):40-44.
[2]杨帆.Hadoop平台高可用性方案的设计与实现[D].北京:北京邮电大学,2012.YANG Fan.Design and Implementation of High Availability Solution for Hadoop[D].Beijing:Beijing University Of Posts And Telecommunications,2012.
[3]黄强,沈奇威,李炜.Hadoop高可用解决方案研究[J].电信技术,2015(11):16-19.HUANG Qiang,SHEN Qiwei,LI Wei.Research on High Availability Solution for Hadoop[J].Telecommunications Technology,2015(11):16-19.
[4]张宇,程久军.基于MapReduce的矩阵分解推荐算法研究[J].计算机科学,2013,631-632(1):138-141.ZHANG Yu,CHENG Jiujun.Study on Recommendation Algorithm with Matrix Factorization Method Based on MapReduce[J].Computer Science,2013,631-632(1):138-141.
[5]刘青文.基于协同过滤的推荐算法研究[D].合肥:中国科学技术大学,2013.LIU Qingwen.Research on Recommender Systems based on Collaborative Filtering[D].Hefei:University of Science and Technology of China,2013.
[6]刘强.协同过滤推荐系统中的关键算法研究[D].杭州:浙江大学,2013.LIU Qiang.Study on key algorithms in Collaborative Filtering Recommender Systems[D].Hangzhou:Zhejiang University,2013.
[7]原默晗,唐晋韬,王挺.一种高效的分布式相似短文本聚类算法[J].计算机与数字工程,2016,44(5):895-900.YUAN Mohan,TANG Jintao,WANG Ting.An Efficient Distributed Similar Short Texts Clustering Algorithm[J].Computer&Digital Engineering,2016,44(5):895-900.
[8]孙远帅.基于大数据的推荐算法研究[D].厦门:厦门大学,2014.SUN Yuanshuai.Recommendation Algorithms in the Big Data Era[D].Xiamen:Xiamen University,2014.
[9]邓雄杰.基于Hadoop的推荐系统的设计与实现[D].广州:华南理工大学,2013.DENG Xiongjie.The Design and Implementation of Recommendation System based on Hadoop[D].Guangzhou:South China University of Technology,2013.
[10]郑凤飞,黄文培,贾明正.基于Spark的矩阵分解推荐算法[J].计算机应用,2015,35(10):2781-2783.ZHENG Fengfei,HUANG Wenpei,JIA Mingzheng.Matrix factorization recommendation algorithm based on Spark[J].Journal of Computer Applications,2015,35(10):2781-2783.
[11]陈梦杰,陈勇旭,贾益斌,等.基于Hadoop的大数据查询系统简述[J].计算机与数字工程,2013,41(12):1939-1942.CHEN Mengjie,CHEN Yongxu,JIA Yibin,et al.A Brief Introduction Hadoop—based Big Data Query System[J].Computer& DigitalEngineering,2013,41(12) :1939-1942.
Research on Parallel Als Algorithm Based on Spark
HOU Jingru WU Sheng LI Yingna
(Kunming University of Science and Technology,School of Information Engineering and Automation,Kunming 650500)
ALS(least square)is a collaborative filtering recommendation algorithm recommended by matrix decomposition,it is calculated by a combination of a large number of user rating data,and stored the calculation process of a large number of characteristic matrix.Hadoop-HA(High Available)is used to solve the problem of the single point of failure of the NameNode.The Spark is a computing framework based on new type of large data come up with distributed memory,at the same time it has excellent computing performance.This study uses the QJM(Quorum Journal Manager)to construct the HA Hadoop big data platform.In this study,uses the ALS collaborative filtering algorithm with the spark coding Framework,at the same time,this study realizes the ALS collaborative filtering algorithm based on the Spark of parallel operation.Through the comparation experiments(the ALS collaborative filtering algorithm based on Hadoop graphs thought and the Netflix data set),the study based on Spark platform of parallel computation is more efficiency.It is more suitable for processing huge amounts of data.
ALS,collaborative filtering,Matrix decomposition,High Available,Spark
TP301
10.3969/j.issn.1672-9722.2017.11.024
Class Number TP301
2017年5月12日,
2017年6月14日
国家自然科学基金项目(编号:51467007)资助。
侯敬儒,男,硕士研究生,研究方向:数据挖掘与机器学习。
猜你喜欢
电子制作(2019年22期)2020-01-14
军事运筹与系统工程(2019年4期)2019-09-11
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
信息化建设(2019年2期)2019-03-27
电子制作(2018年11期)2018-08-04
制导与引信(2017年3期)2017-11-02
知识就是力量(2017年2期)2017-01-21
燕山大学学报(2015年4期)2015-12-25
电脑爱好者(2015年21期)2015-09-10
