
基于带权超图的跨网络用户身份识别方法
2018-01-08 07:46陈鸿昶黄瑞阳
计算机应用 2017年12期
徐 乾,陈鸿昶,吴 铮,黄瑞阳
(国家数字交换系统工程技术研究中心,郑州 450002)
基于带权超图的跨网络用户身份识别方法
徐 乾*,陈鸿昶,吴 铮,黄瑞阳
(国家数字交换系统工程技术研究中心,郑州 450002)
随着各种社交网络的不断涌现,越来越多的研究者开始从多源的角度分析社交网络数据,多社交网络的数据融合依赖于跨网络用户身份识别。针对现有的基于好友关系(FRUI)算法对社交网络中的异质关系利用率不高的问题,提出了基于带权超图的跨网络用户身份识别(WHUI)算法。首先,通过在好友关系网络上构建带权超图来准确地描述同一网络中的好友关系及异质关系,以此提高表示节点所处拓扑环境的准确性;然后,在构建好的带权超图的基础上,根据节点所处拓扑环境在不同网络中大致相同这一特性,定义节点之间的跨网络相似性;最后,结合迭代匹配算法,每次选取跨网络相似性最高的用户对进行匹配,并加入双向认证和结果剪枝来保证识别准确率。在合作网络DBLP和真实社交网络上进行了实验,实验结果表明,在真实社交网络上,所提算法相比FRUI算法,平均准确率提高了5.5个百分点,平均召回率提高了3.4个百分点,平均F值提高了4.6个百分点。在只有网络拓扑信息的情况下,所提WHUI算法有效提高了实际应用中身份识别的准确率和召回率。
跨网络用户身份识别;带权超图;异质关系;节点相似度;迭代匹配
0 引言
多种多样的社交网络极大地丰富了人们的生活,人们通过QQ、微信与朋友保持联系,通过微博关注自己喜爱明星的动态,通过LinkedIn来发展职场社交。然而大多数社交网络间没有建立起公开的连接,因此用户的信息分散在多个社交网络中。识别出网民在不同网络中的虚拟账号的问题就是跨网络用户身份识别问题[1]。这一问题的解决在现实应用中具有十分重要的意义:社交网络的管理者识别出用户的多个虚拟账号之后,可以获取用户在其他社交网络中的信息,从而在自己的网络中进行准确的推荐;公安机关在识别出用户的多个虚拟账号之后,可以全面地了解某一用户,为侦查工作提供支持。除此之外,这项研究还在信息检索等多个领域有着广泛的应用前景[2]。
目前,在跨网络用户识别技术的研究上,现有的方法主要分为三类:基于属性信息[2-4]、基于用户产生内容[5-6]以及基于网络拓扑结构[7-11]的用户身份识别方法。基于属性信息的方法是利用用户名、所在地、用户头像等用户在注册社交网络时填写的档案信息进行身份识别;基于用户产生内容的方法是利用用户在使用社交网络过程中产生的微博、状态及地理位置等信息进行身份识别;基于网络拓扑结构的方法是利用用户在社交网络中的好友关系信息进行身份识别。由于好友关系信息较易被获取,而且好友关系与他人完全重叠的现象非常少见,所以本文选择基于网络拓扑结构进行跨网络用户身份识别。
文献[7]仅仅利用网络拓扑结构进行识别,将不同网络中的两个节点所共有的种子节点数作为节点的跨网络相似性,选择相似性较大的进行匹配。文献[8]提出利用扩展的Adamic-Adar指数、Jaccard相关系数来计算用户节点间的跨网络相似性。文献[9]提出有向网络上的身份识别,节点的跨网络相似性使用共有的in/out邻居个数以及出度、入度来度量。文献[10]使用属性信息和网络结构信息构建目标函数,对目标函数进行优化得到最优的匹配结果,其中节点相似性使用Dice系数进行度量。纵观现有方法,主要是在好友关系网络中的拓扑信息的基础上,利用共同邻居个数、Adamic-Adar指数等传统的节点相似性度量方法得到节点之间的跨网络相似性。然而现实网络中的节点之间的关系具有异质性,节点之间不仅存在好友关系或者关注与被关注关系,还存在更加复杂多样的关系,例如多个用户同时加入了某个兴趣小组、同时加入了某次活动、共同关注某一个用户等。现有的节点相似性计算方法忽略了节点间关系的异质性,因此造成身份识别的准确率不高。
针对上述问题,本文提出了一种基于带权超图模型的跨网络用户身份识别(Weighted Hypergraph based User Identification, WHUI)算法。该算法分为两个阶段:第一个阶段是超图构建阶段,首先从普通好友关系网络结构出发,在两个待匹配网络上分别构建超图模型来反映网络中的好友关系及异质关系,其次在超图模型基础上定义同一网络中节点间的相似性,以此实现对于同一网络用户节点间相似性的准确刻画,然后利用种子节点计算得到两个网络中未匹配节点之间的跨网络相似性。第二阶段是身份识别阶段,这一阶段解决的问题是如何根据节点之间的跨网络相似性进行节点匹配,主要方法是在节点跨网络相似性的基础上,每次选取跨网络相似性最大的节点对进行匹配,并加入双向认证保证识别的准确率。最后迭代更新种子节点集,以达到跨网络用户身份识别的目的。实验结果表明,该算法在准确率和综合评价指标上都得到了改善。
1 相关定义
1.1 用户身份识别

1.2 种子节点
1.3 基于好友关系的跨网络用户身份识别
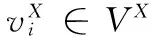
(1)
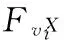
2 超图模型构建
2.1 超图
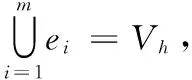
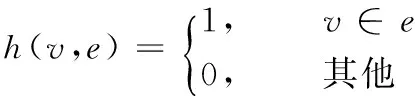
(2)
2.2 超图模型

2.3 在好友关系网络上构建超图模型
在实际应用中,如果有已知的异质关系信息,例如多个用户加入了同一个兴趣小组,或者同时参加了某个活动,那么就可以直接将这些用户划分到一个超边中,然后通过设置超边权值来体现超边中的节点之间具有某种程度的亲密关系。但是上述信息通常难以获取,有时只能获取用户好友关系信息。所以本文根据普通的好友关系网络来得到近似的用户关系信息,从而构建超图模型。如果同一个网络中的两个用户v1和v2直接相连,就将v1和v2划分到同一个超边中,例如图2所示的有向图中,由于v1和v2以及v1和v3之间都是直接相连关系,这种关系通常是反映了现实中的好友关系,在另一个网络可能也存在这样的关系,因此分别构建超边e1={v1,v2}、e2={v1,v3}分别表示v1和v2以及v1和v3之间的好友关系,为下一步计算节点相似性提供支撑。
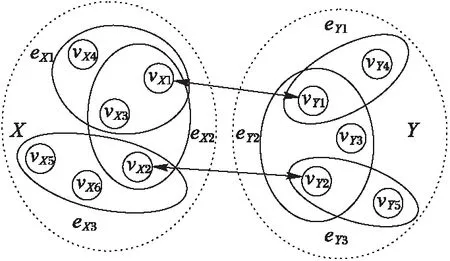
图1 用于跨网络身份识别的超图模型Fig. 1 Hypergraph model for user identification across social networks
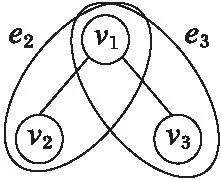
图2 直接相连关系对应的超边划分Fig. 2 Hyperedge construction of direct connected relation
除此之外,本文在拥有共同邻居的两个或多个节点上构建超边,例如图3所示,v2、v3、v4是v1的所有邻居节点且都和v1直接相连,在这种网络结构下,可以认为v2、v3、v4都具有“与v1是好友”这个属性,因此在其上构建超边e3={v2,v3,v4},表示v2、v3、v4所在的拓扑环境有部分相似之处,从而为下一步计算节点相似性提供支撑。
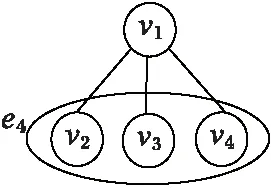
图3 拥有共同邻居的两个或多个节点上的超边划分Fig. 3 Hyperedge construction of two or more nodes with common neighbors
2.3.1 超边权重设定
通过上述分析可知,超图不仅保留了好友关系网络中原始的拓扑信息,而且还可以体现网络中的异质关系。这些关系有些是紧密的关系,有些则是相对疏远的关系,因此需要通过设置超边的权重来表示超边内节点的亲密度,权重越大则认为超边中的节点关系越紧密。对于在直接相连关系上建立起的超边,超边内节点对应的是社交网络中的好友关系,将这种超边权重设置为p,p相对较大;对于在拥有共同好友的节点上构建的超边,由于超边内节点彼此之间不一定直接相连,因此这种超边节点关系通常比直接相连的好友关系疏远,将这种超边权重统一设置为q,q相对较小。本文的实验部分,会考察p和q的设置对于实验结果的影响。
2.3.2 超图模型构建算法
基于以上分析,本文给出在好友关系网络上构建带权超图的算法,算法描述如算法1所示。
算法1 带权重超图构建算法。
输入 好友关系网络G(V,E),超边权重p、q;
输出 带权超图Gh(Vh,Eh)。
HypergraphConstruction(G,p,q)
1)
初始化Vh=V,Eh={},i=1
2)
forv∈Vhdo
3)
foru∈Neighbor(v) do
4)
ei={v,u}
5)
if 超边集中含有仅包含v,u且超边权重为p的超边 do
6)
continue
7)
else
8)
Eh=Eh+ei,w(ei)=p,i=i+1
9)
end if
10)
end for
11)
ifNeighbor(v)中含有两个或两个以上的节点
12)
ei=Neighbor(v)
13)
Eh=Eh+ei,w(ei)=q,i=i+1
14)
end if
15)
end for
16)
return (Vh,Eh)
上述算法中,Neighbor(v)是v的所有邻居节点组成的集合,第3)~10)行是在直接相连的两个节点上构建超边,第11)~14)行是在拥有共同好友的两个或多个节点上构建超边。
3 基于带权超图的用户身份识别
3.1 节点相似性计算
由于好友关系在不同社交网络中非常容易保持一致性[14],所以两个网络中互相匹配的两个节点,它们与种子节点的相似性也具有跨网络的一致性。这种一致性可以用来计算未匹配节点间的跨网络相似性,进而判断这两个节点是否匹配。由于超图可以准确地描述网络中节点之间的关系,所以本文利用超图来计算身份未识别节点与种子节点的同网络相似性,然后根据的跨网络一致性,定义不同网络中节点间的跨网络相似性,为下一步节点匹配提供支撑。
3.1.1 同一网络中的节点间相似性
已知用户好友关系网络G(V,E),根据在其上构建的超图Gh(Vh,Eh),超图Gh中的两个节点vi∈Vh和vj∈Vh的相似性计算方法如式(3)所示:
(3)
式(3)体现的思想是,如果vi和vj同时所在的超边个数越多,vi和vj的相似度就越高。w(ek)是超边的权重,它体现超边中各个节点关系的紧密性,权重越大说明超边中的节点关系越密切,相似度越高。δ(ek)是超边的度,δ(ek)=2时超边中的节点在好友关系网络中是直接相连的关系,此时超边中的两个节点之间的关系较为紧密,相似度较高;δ(ek)>2时,超边中的节点在好友关系网络中只是拥有共同关注的好友,它们可能并不直接相连,所以此时超边中的节点之间的关系相对疏远,相似度较低。h(v,e)是节点-超边函数,当v∈e时,h(v,e)=1,否则h(v,e)=0。
3.1.2 跨网络的节点间相似性
对于互相匹配的两个节点,它们与种子节点的相似性具有跨网络一致性,所以本文利用未识别节点与种子节点的同网络相似性来计算两个节点跨网络的相似性。

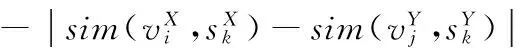
(4)
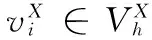

(5)
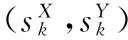
3.2 跨网络节点匹配
有了跨网络相似性之后,接下来面对的问题就是如何进行跨网络节点的匹配,算法在身份识别阶段解决的就是这一问题。本文将跨网络节点匹配分解成逐步迭代求取的过程(如图4所示),在每一步迭代的过程里,算法的计算过程分为节点选择、节点匹配和双向认证,在每一步迭代过程中选取当前跨网络相似性最大的两个节点进行匹配,加入到种子节点集S中,新加入的种子节点也作为计算跨网络相似性所参照的种子节点,从而提高识别准确度。当没有可以匹配的节点时,算法停止迭代。最终通过结果剪枝,删除一部分算法后期挖掘出的种子节点以保证准确率,剪枝后的结果即为最终的结果。算法进行跨网络匹配的流程如图4所示。
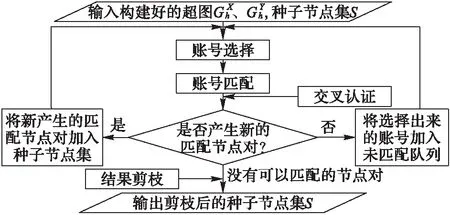
图4 WHUI算法在身份识别阶段的流程Fig. 4 Flow chart of WHUI algorithm at identification stage
3.2.1 节点选择
WHUI算法在用户身份识别阶段,每一次迭代运行的第一个步骤就是从两个网络中选择一个最有可能在另一个网络中存在匹配的节点。由于用户使用社交网络的习惯很大程度上受好友的影响,用户的好友中种子节点越多,他在另一个网络中存在匹配节点的概率就越大,因此本文优先选择好友中种子节点数量多的优先进行匹配,算法描述如算法2所示。
算法2 节点选择算法。
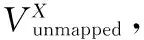
输出 待匹配的用户节点vselect。
1)
if unmapped queue非空 then
2)
return 队列中第一个元素
3)
end if
4)
5)
计算v0的邻居中种子节点的个数
6)
end for
7)
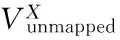
8)
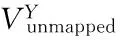
9)
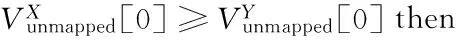
10)
11)
else
12)
13)
end if
14)
returnvselect
其中unmapped queue表示未匹配队列,未匹配队列中的节点,是在之前迭代过程中被选中了但并未成功匹配的节点。第4)~8)行是在计算两个网络中每一个节点相邻的种子节点的个数,并且对两个网络中的节点集合,按照之前计算的相邻的种子节点个数进行降序排列。第9)~13)行是在对比两个网络中排在首位的节点,返回较大的作为最终选中的节点。
3.2.2 节点匹配
当得到节点选择过程中返回的待匹配节点vselect,接下来就需要基于3.1.2节提出的跨网络相似性进行匹配。节点匹配算法首先需要确定该用户节点是来自于网络X还是来自于网络Y;然后选择与vselect跨网络相似性最高的节点vmatch作为最有可能的匹配返回。节点匹配算法描述如算法3所示。
算法3 节点匹配算法。

输出 候选匹配节点vmatch。
1)
ifvselect来自网络Xthen
2)
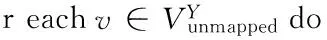
3)
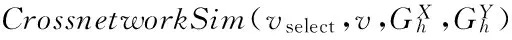
4)
end for
5)
6)
returnvmatch
7)
else
8)
9)
end if
3.2.3 双向认证
考虑到在节点选择和节点匹配阶段都需要用到种子节点,根据已有的种子节点来选择待匹配节点vselect及候选匹配节点vmatch,使得因此一个错误的种子节点将会对接下来的迭代过程造成误导,并且这种坏的影响会不断积累导致算法失败。因此本文使用双向认证的方法来保证每次产生的种子节点的准确性。即验证与vmatch跨网络相似性最大的节点是否为vselect:如果是则将(vmatch,vselect)加入到种子节点集;如果不是,则将vselect加入到未匹配队列中等待机会再匹配,并将vselect重置为vmatch进入新的一轮迭代。双向认证算法描述如算法4所示。
算法4 双向认证算法。
输出 一个新的种子节点。
CrossMatching(vselect,vmatch,S)
1)
2)
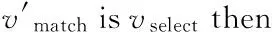
3)
S=S∪vnew
4)
5)
6)
vselect=NULL
7)
return NULL
8)
else
9)
将vselect加入到unmapped queue中
10)
vselect=vmatch
11)
12)
return (vselect,vmatch)
13)
end if
其中vnew表示新生成的种子节点。第3)~7)行是在双向认证成功后,将匹配成功的节点对从尚未匹配的节点集合中删除,并将它们加入到种子节点集中。第9)~12)行是算法在双向认证失败后,将vselect加入到unmapped queue中等待合适的节点与之匹配,并将vselect和vmatch互换并返回,返回之后将会在vselect和vmatch基础上继续执行双向认证过程。
3.2.4 结果剪枝
考虑到本文仅仅利用拓扑信息进行匹配,因此即使加入了双向认证的过程,算法前期的准确率也不能够达到100%,也就是说在算法的最后阶段,会产生大量的错误配对,因此需要一个剪枝的过程将结果中错误的匹配排除在结果之外。由于算法在身份识别阶段优先选择最有可能匹配的节点并且使用双向认证算法,因此有理由相信,早期产生的种子节点有很高的可信度,而后面产生的种子节点错误的可能性比较大。所以本文采取一个非常简单的方式,也就是只选取前期产生的结果作为最终结果。选择95%、90%或者其他百分比,这个取决于具体的网络环境。本文实验部分验证了剪枝百分比对准确率的影响。
3.3 WHUI算法
算法5展示了基于带权超图的跨网络用户身份识别(WHUI)算法的完整过程。输入两个好友关系网络及种子节点集合,然后通过在好友关系网络上构建超图从而得到节点的跨网络相似性,最终在身份识别阶段通过持续的选择、匹配、双向认证,最终对结果剪枝得到完整的结果。
算法5 双向认证算法。
输入 好友关系网络GX(VX,EX)和GY(VY,EY),超图权重p、q,匹配前已知的种子用户集合S;
输出 最终的种子用户集合Sresult。
1)
2)
3)
Sresult=S
4)
初始化空队列unmapped queue
5)
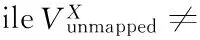
6)
ifvselect=NULL then
7)
8)
9)
end if
10)
(vselect,vmatch)=CrossMatching(vselect,vmatch,Sresult)
11)
end while
12)
对Sresult进行结果剪枝
13)
returnSresult
3.4 时间复杂度分析
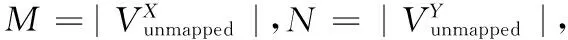
一部分是超图的构建,由于算法在直接相连节点和具有共同好友的节点上构建超边,因此复杂度分别为O(|VX|+|EX|)和O(|VY|+|EY|)。
另一部分是跨网络账号匹配产生的复杂度,在账号选择过程中,需要计算每一个未匹配节点的好友中种子节点的个数,它随种子节点的增加而改变。因此第一次花销为M+N;第二次只需要计算与新加入的种子节点直接相连的未匹配节点,在最坏的情况下,每一个未匹配节点都需要计算,花销为M-1+N-1;第三次需要M-2+N-2。以此类推,每一项的通项公式为M+N-2n,到N-1次后算法结束,所以总时间为(M+N)(N-1)-N(N-1),化简后为M(N-1)。接着要计算的是账号匹配和双向认证阶段,需要找出与vselect跨网络相似性最大的节点然后进行双向认证,假设vselect∈VX,因此第一次在账号匹配过程中最多需要计算vselect与N个节点的跨网络相似性,对应双向认证需要计算M-1次,第一次时间开销为M+N-1,第二次为(M-1)+(N-1)-1。每一项的通项公式为M+N-2n-1。同样到N-1次后算法结束,所以总时间为(M+N)(N-1)-N(N-1)-N,化简后为M(N-2)。所以账号在跨网络匹配部分的复杂度为O(MN)。
综合超图构建与跨网络账号匹配,得到总的时间复杂度为O(MN)。
4 实验及结果分析
4.1 实验数据
4.1.1 DBLP网络
为了验证算法的有效性,本文使用文献[15]中的英文文献数据库DBLP来建立一个模拟的社交网络:DBLP中包含很多文章,每篇文章由多个作者合作完成。将每一个作者作为社交网络中的用户,将作者之间的合作关系认为是社交网络中的好友关系。然后将DBLP数据集中的所有文章随机分为两个部分,按照上述方法在这两个部分上分别构建模拟的社交网络,从而得到两个DBLP网络。这样,对于属于两个部分的两篇文章,如果这两个文章中都包含同一作者,那么这个作者在两个网络中的两个账号就可以组成种子节点。两个网络中的用户数量分别为2 317和2 327。DBLP网络具体信息如表1所示。
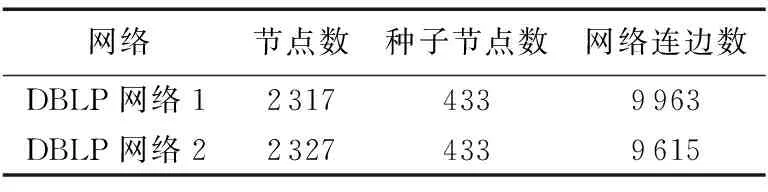
表1 DBLP网络数据统计Tab. 1 DBLP network data statistics
图5是两个网络度的分布,近似服从幂律分布。
4.1.2 真实社交网络数据
为了验证算法的实用性,本文使用文献[10]提出的标准数据集,该数据集在Twitter和Facebook这两个社交网络上,以16位在两个网络上都注册账号的用户为起点,通过好友关系逐步扩展网络,最终得到了1 475个账号,如表2所示,其中:Facebook账号有422个,Twitter账号有1 053个。其中有152个对应关系已知的种子节点。
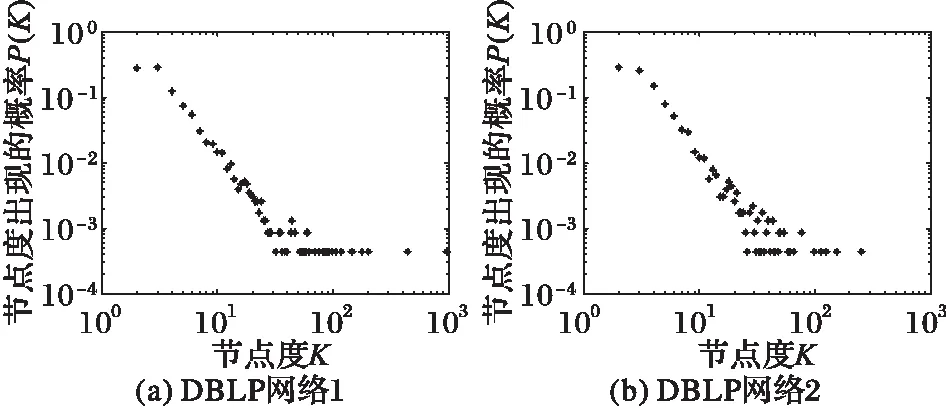
图5 DBLP网络的度分布Fig. 5 Degree distribution of DBLP networks表2 Facebook和Twitter社交网络数据统计Tab. 2 Social network data statistics of Facebook and Twitter
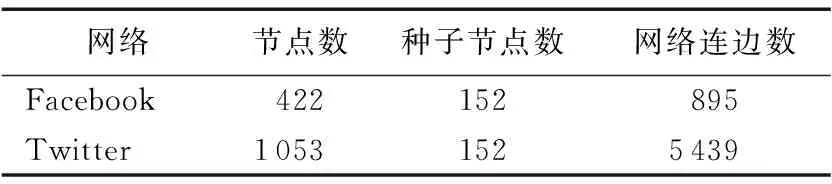
网络节点数种子节点数网络连边数Facebook422152895Twitter10531525439
图6是两个网络度的分布,近似服从幂律分布。
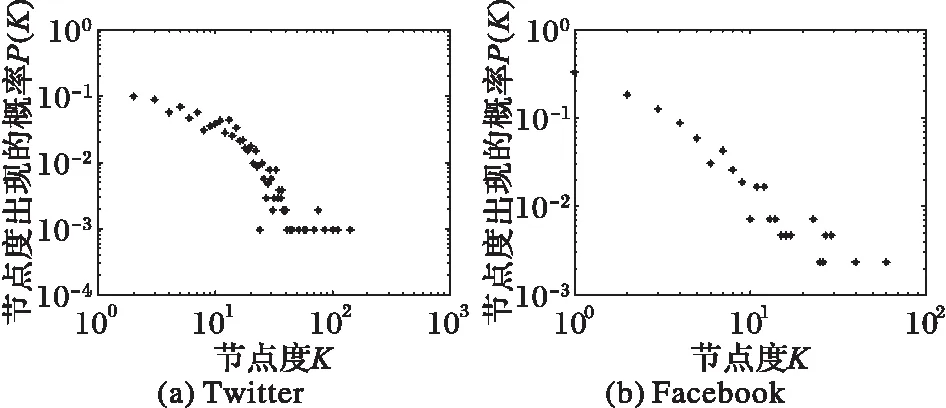
图6 Twitter网络和Facebook网络的度分布Fig. 6 Degree distribution of Twitter network and Facebook network
4.2 评价指标
本文评价指标采用信息检索中的准确率P、召回率R、综合指标F,其计算公式为:
R=Nc/Ne
(6)
P=Nc/Ns
(7)
F=2RP/(R+P)
(8)
其中:Nc是算法识别出的正确匹配的用户节点的对数;Ne是实验数据中实际存在的匹配节点对个数;Ns是算法识别出的匹配的节点对(包括正确匹配的和正确匹配的)。
4.3 实验分析
本文选取度数排名靠前的一部分种子节点作为初始时已知的种子节点,其余的种子节点在初始时作为未匹配节点,在算法结束后用来验证算法的准确性。
4.3.1 超图权值的影响
为了验证超图权值对实验结果的影响,令权重p=1,权重q从1递减到0。在DBLP网络和真实社交网络(Facebook和Twitter)上实验结果如图7所示。
在DBLP网络上,当p比q约等于4.5时,F达到最大值62.4%。在真实社交网络上,当权重p一定(p=1),q从1开始逐渐减小时,共同好友关系在计算节点相似性时所占比重减小,当q减小到约为p值的十分之一时(p/q≈10),F值达到最大值72.4%,说明共同好友关系比于直接相连关系相对较弱,过多地依靠共同好友关系来得到节点相似性时,F值将会大幅降低;当q值从0.1继续减小时,F值降低,说明了共同好友关系在计算用户相似性时也应该占一定比重,忽略了共同好友关系会导致F值下降。
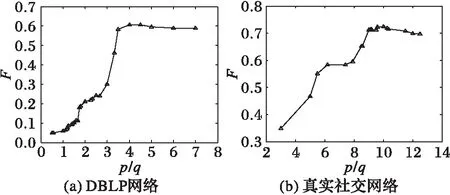
图7 综合指标F随权重的变化Fig. 7 Change of comprehensive index F with weight
4.3.2 剪枝率的影响
此外,本文还验证了在不同的剪枝率下算法的评价指标。剪枝率为算法在迭代得到的种子节点集合上所减去的种子节点的比例,结果如图8所示。
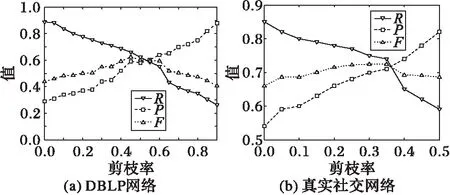
图8 评价指标随剪枝率的变化Fig. 8 Change of evaluation indexes with pruning rate
在DBLP网络上,随着剪枝率的增加,算法的召回率减小,准确率增大;剪枝率为45%时,F达到最大值62.4%。由于数据集合中种子节点所占比例非常小仅为18%,算法前期可能就挖掘出大部分种子节点,之后便会产生大量错误匹配,因此需要减去大部分迭代产生的结果,来保证最优的F值。在真实社交网络上,当剪枝率为35%的时候,F值达到最大值72.4%。此时虽然召回率不高,但是保证了一定的准确率。
4.3.3 算法性能对比
为了验证算法的有效性,本文将提出的WHUI与传统的FRUI算法进行对比,实验中的参数均选用最佳情况下的取值(p=1,q=0.3,剪枝率在DBLP网络上设置为90%,在真实社交网络上设置为35%)。表3汇总了在DBLP网络和真实社交网络的测试结果。图9是两种算法的评价指标对比。
通过在DBLP网络上的实验测试,发现当种子节点数量较少时,对于FRUI算法,由于可以利用的种子节点不多,因此通过节点跨网络相似度来区分不同的用户准确率和召回率都相对较低;对于WHUI算法,由于充分利用当前所有种子节点来计算跨网络相似性,在种子节点数较少时,其准确率、召回率高于FRUI。当种子节点数量增多时,FRUI在召回率和F值上拥有微小的优势。总的来说,在DBLP网络上,WHUI相对于FRUI算法,平均F值提高了1.2个百分点。
在真实社交网络上的测试结果表明,WHUI算法在准确率、召回率和F值上全面优于FRUI,这是因为WHUI算法中使用的超图模型不仅保留了好友关系网络中的拓扑信息,还加入了网络中的异质关系信息,从而更加准确地度量出节点间跨网络相似性,实现了相对准确的匹配。在真实网络上,WHUI算法相对于FRUI算法,平均准确率提高了5.5个百分点,平均召回率提高了3.4个百分点,平均F值提高了4.6个百分点。
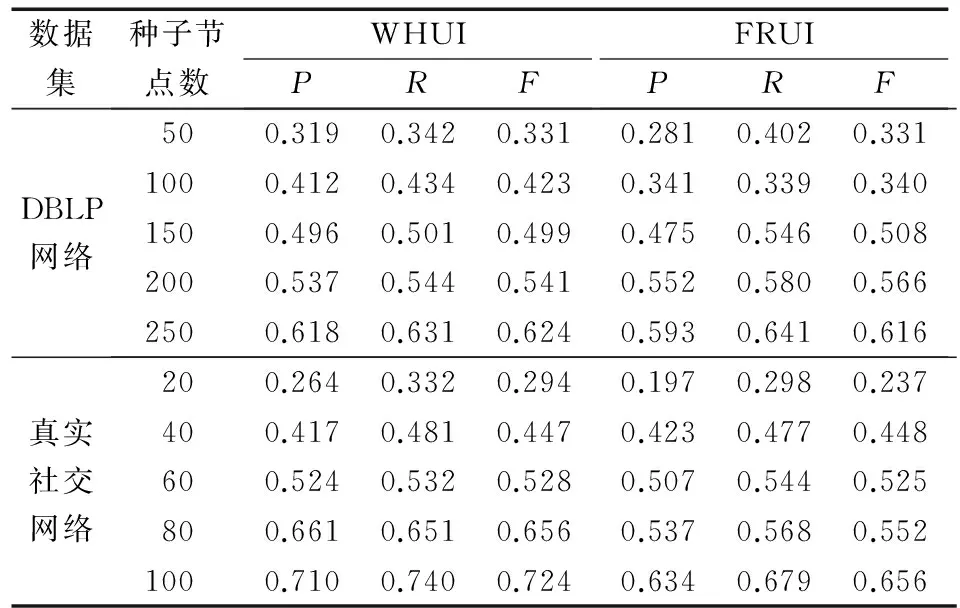
表3 WHUI和FRUI节点匹配效果对比Tab. 3 Comparison of node matching results by WHUI and FRUI
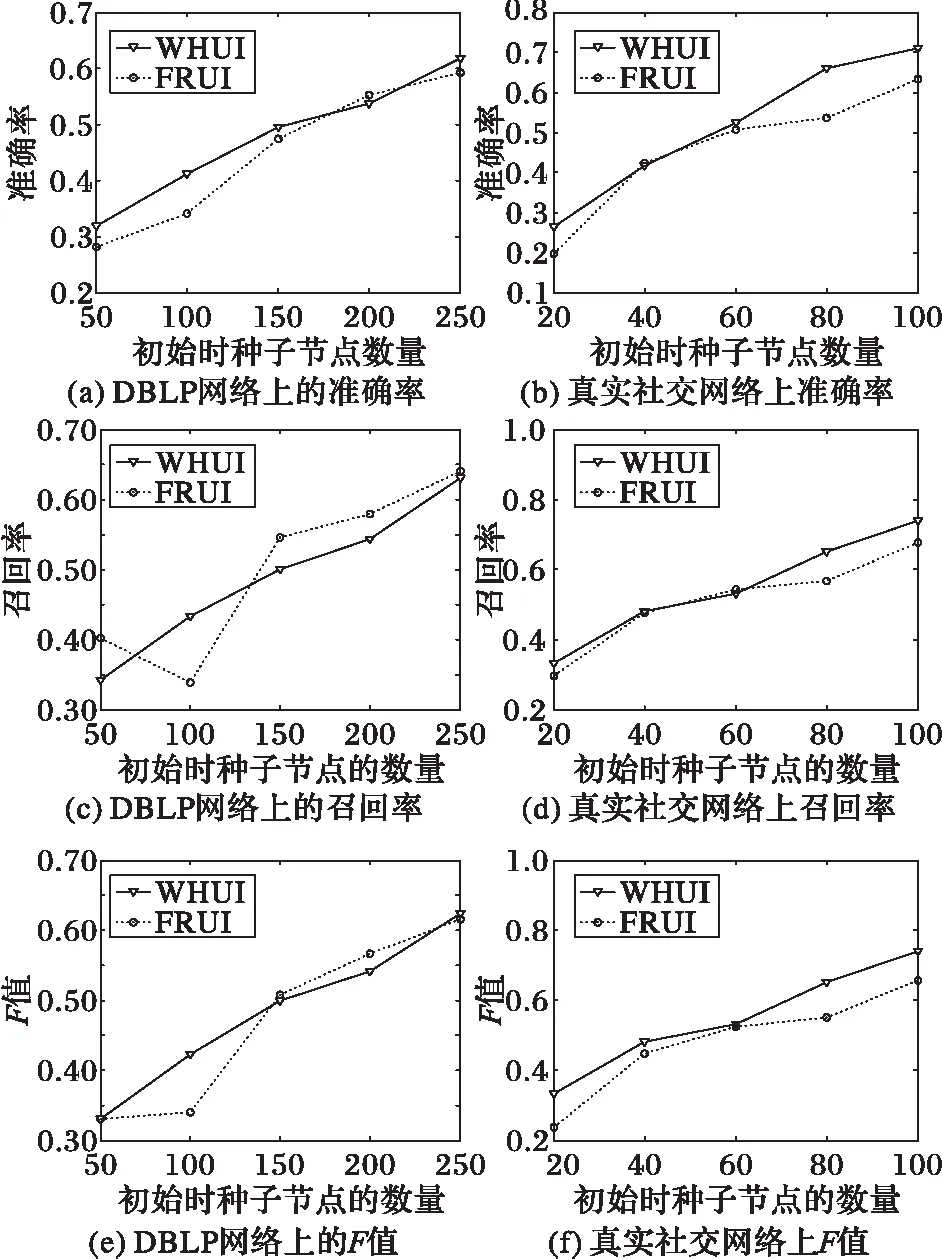
图9 WHUI与FRUI的评价指标对比Fig. 9 Comparison of evaluation indexes of WHUI and FRUI
4.3.4 算法时间复杂度对比
在DBLP网络和真实社交网络上对比了WHUI与FRUI的算法效率,参数设置与4.3.3节中的实验参数相同,实验结果如图10所示。
从图10中看出,WHUI算法运行时间普遍高于FRUI算法。这是因为WHUI算法相比FRUI算法具有超图构建以及双向认证的过程,这两个步骤在一定程度上增加了时间开销,但是同时也提高了算法的准确率,在实际应用中,多出的时间开销在可接受的范围之内。
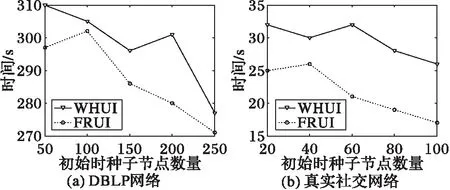
图10 WHUI与FRUI的效率比较Fig. 10 Time complexity comparison of WHUI and FRUI
5 结语
针对现有匹配算法对于社交网络中异质关系利用率不高的缺点,本文提出了使用带权超图来描述节点间的社会关系,带权超图不仅保留了好友关系网络中原始的拓扑信息,而且还可以体现网络中的异质关系。在带权超图的基础上定义节点间的跨网络相似性,并结合迭代匹配算法实现更加准确的跨网络用户身份识别。实验结果表明,本文算法在准确率和综合评价指标上均有明显的优势,验证了带权超图模型在跨网络节点相似性计算上的有效性。下一步将进一步细化网络中的异质关系,对不同类型的异质关系赋予不同的超图权重,以此实现在异质关系信息已知的条件下,更加准确地跨网络身份识别。
References)
[1] 孟波.多社交网络用户身份识别算法研究[D].大连:大连理工大学,2015:1-10. (MENG B. Research on algorithms for identifying users across multiple online social networks [D]. Dalian: Dalian University of Technology, 2015:1-10.)
[2] 刘东,吴泉源,韩伟红,等.基于用户名特征的用户身份统一性判定方法[J].计算机学报,2015,38(10):2028-2040.(LIU D, WU Q Y, HAN W H, et al. User identification across multiple websites based on username features [J]. Chinese Journal of Computers, 2015, 38(10): 2028-2040.)
[3] PERITO D, CASTELLUCCIA C, KAAFAR M A, et al. How unique and traceable are usernames? [C]// PETS’11: Proceedings of the 2011 11th International Conference on Privacy Enhancing Technologies. Berlin: Springer, 2011: 1-17.
[4] LIU J, ZHANG F, SONG X, et al. What’s in a name?: an unsupervised approach to link users across communities [C]// Proceedings of the 2013 ACM International Conference on Web Search and Data Mining. New York: ACM, 2013: 495-504.
[5] ZHENG R, LI J, CHEN H, et al. A framework for authorship identification of online messages: writing-style features and classification techniques[J]. Journal of the American Society for Information Science and Technology, 2006, 57(3): 378-393.
[6] ALMISHARI M, TSUDIK G. Exploring linkability of user reviews [C]// Proceedings of the 2012 European Symposium on Research in Computer Security, LNCS 7459. Berlin: Springer, 2012: 307-324.
[7] ZHOU X, LIANG X, ZHANG H, et al. Cross-platform identification of anonymous identical users in multiple social media networks [J]. IEEE Transactions on Knowledge & Data Engineering, 2016, 28(2): 411-424.
[8] KONG X, ZHANG J, YU P S. Inferring anchor links across multiple heterogeneous social networks [C]// CIKM’13: Proceedings of the 22nd ACM International Conference on Information & Knowledge Management. New York: ACM, 2013: 179-188.
[9] NARAYANAN A, SHMATIKOV V. De-anonymizing social networks [C]// Proceedings of the 30th IEEE Symposium on Security and Privacy. Piscataway, NJ: IEEE, 2009: 173-187.
[10] BARTUNOV S, KORSHUNOV A, PARK S T, et al. Joint link-attribute user identity resolution in online social networks [C]// SNAKDD’12: Proceedings of the 2012 6th International Conference on Knowledge Discovery and Data Mining, Workshop on Social Network Mining and Analysis. New York, ACM, 2012: 1-9.
[11] MAN T, SHEN H, LIU S, et al. Predict anchor links across social networks via an embedding approach [C]// IJCAI’16: Proceedings of the 2016 International Joint Conference on Artificial Intelligence. New York, ACM, 2016: 1823-1829.
[12] BERGE C. Graphs and Hypergraphs [M]. Amsterdam: Elsevier, 1973: 389-390.
[13] BERGE C. Hypergraphs: Combinatorics of Finite Sets [M]. Amsterdam: Elsevier, 1984: 3-4.
[15] 桑基韬,路冬媛,徐常胜.基于共同用户的跨网络分析:社交媒体大数据中的多源问题[J].科学通报,2014,59(36):3554-3560.(SANG J T, LU D Y, XU C S. Overlapped user-based cross-network analysis: exploring variety in big social media data [J]. Chinese Science Bulletin, 2014, 59(36): 3554-3560.)[15] DENG H, HAN J, ZHAO B, et al. Probabilistic topic models with biased propagation on heterogeneous information networks [C]// Proceedings of the 2011 ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2011: 1271-1279.
This work is partially supported by the National Natural Science Foundation of China (61521003).
XUQian, born in 1993, M. S. candidate. His research interests include social network mining, machine learning.
CHENHongchang, born in 1964, Ph. D., professor. His research interests include information security of telecommunication network, information communication security.
WUZheng, born in 1992, M. S. candidate. His research interests include complex network, network large data analyzing and processing.
HUANGRuiyang, born in 1986, Ph. D., associate research fellow. His research interests include network large data analyzing and processing, big data distributed processing.
Useridentificationmethodacrosssocialnetworksbasedonweightedhypergraph
XU Qian*, CHEN Hongchang, WU Zheng, HUANG Ruiyang
(NationalDigitalSwitchingSystemEngineering&TechnologicalResearchCenter,ZhengzhouHenan450002,China)
With the emergence of various social networks, the social media network data is analyzed from the perspective of variety by more and more researchers. The data fusion of multiple social networks relies on user identification across social networks. Concerning the low utilization problem of heterogeneous relation between social networks of the traditional Friend Relationship-based User Identification (FRUI) algorithm, a new Weighted Hypergraph based User Identification (WHUI) algorithm across social networks was proposed. Firstly, the weighted hypergraph was accurately constructed on the friend relation networks to describe the friend relation and the heterogeneous relation in the same network, which improved the accuracy of presenting topological environment of nodes. Then, on the basis of the constructed weighted hypergraph, the cross network similarity between nodes was defined according to the consistency of nodes’ topological environment in different networks. Finally, the user pair with the highest cross network similarity was chosen to match each time by combining with the iterative matching algorithm, while two-way authentication and result pruning were added to ensure the recognition accuracy. The experiments were carried out in the DBLP cooperation networks and real social networks. The experimental results show that, compared with the existing FRUI algorithm, the average precision, recall,Fof the proposed algorithm is respectively improved by 5.5 percentage points, 3.4 percentage points, 4.6 percentage points in the real social networks. The WHUI algorithm can effectively improve the precision and recall of user identification in practical applications by utilizing only network topology information.
user identification across social network; weighted hypergraph; heterogeneous relation; node similarity; iterative matching
2017- 05- 23;
2017- 08- 10。
国家自然科学基金资助项目(61521003)。
徐乾(1993—),男,辽宁大连人,硕士研究生,主要研究方向:社交网络挖掘、机器学习; 陈鸿昶(1964—),男,河南郑州人,教授,博士,主要研究方向:电信网信息关防、信息通信安全; 吴铮(1992—),男,江苏徐州人,硕士研究生,主要研究方向:复杂网络、网络大数据分析与处理; 黄瑞阳(1986—),男,福建漳州人,副研究员,博士,主要研究方向:网络大数据分析与处理、大数据分布式处理。
1001- 9081(2017)12- 3435- 07
10.11772/j.issn.1001- 9081.2017.12.3435
(*通信作者电子邮箱549529376@qq.com)
TP391.4
A
猜你喜欢
数学物理学报(2022年5期)2022-10-09
河北画报(2020年8期)2020-10-27
小雪花·初中高分作文(2019年10期)2019-02-12
杂文月刊(2017年20期)2017-11-13
时代英语·高二(2017年4期)2017-08-11
学生天地·小学中高年级(2017年5期)2017-06-09
红领巾·成长(2016年10期)2017-05-10
浙江大学学报(工学版)(2016年2期)2016-06-05
今日教育(2014年1期)2014-04-16
俄罗斯问题研究(2013年1期)2013-03-11
