
快速识别密度骨架的聚类算法
2018-01-08 07:47邱保志唐雅敏
计算机应用 2017年12期
邱保志,唐雅敏
(郑州大学 信息工程学院,郑州450001)
快速识别密度骨架的聚类算法
邱保志,唐雅敏*
(郑州大学 信息工程学院,郑州450001)
针对如何快速寻找密度骨架、提高高维数据聚类准确性的问题,提出一种快速识别高密度骨架的聚类(ECLUB)算法。首先,在定义了对象局部密度的基础上,根据互k近邻一致性及近邻点局部密度关系,快速识别出高密度骨架;然后,对未分配的低密度点依据邻近关系进行划分,得到最终聚类。人工合成数据集及真实数据集上的实验验证了所提算法的有效性,在Olivetti Face数据集上的聚类结果显示,ECLUB算法的调整兰德系数(ARI)和归一化互信息(NMI)分别为0.877 9和0.962 2。与经典的基于密度的聚类算法(DBSCAN)、密度中心聚类算法(CFDP)以及密度骨架聚类算法(CLUB)相比,所提ECLUB算法效率更高,且对于高维数据聚类准确率更高。
聚类算法;高维数据;k近邻;密度骨架;局部密度
0 引言
聚类是数据挖掘中研究最活跃的领域之一,它依据相似性将相似的对象聚集在一起形成一个簇,不同簇中的对象具有高度不相似性。聚类是无监督学习,在分析数据的内部结构、属性之间的关系等方面有重要的作用,并已经广泛应用于模式识别、图像处理、市场分析等领域[1-4]。目前,学者们对聚类技术进行了深入的研究,提出了大量算法,如K-means[5]、经典的基于密度聚类(Density-Based Spatial Clustering of Applications with Noise, DBSCAN)算法[6]等,如何提高算法的效率和对高维空间聚类的准确性依然是值得研究的问题[7-8]。
K-means是基于划分的聚类算法,适用于对含有球形簇的数据集进行聚类,由于算法中使用欧氏距离,故对高维数据集的聚类结果精度不高。
基于密度的聚类由于其能发现任意形状、大小的聚类而备受关注[9]。DBSCAN是基于密度聚类的经典算法,它认为一个聚类由核心点和非核心点组成,密度可达的核心点集合构成聚类的骨架,由骨架中的核心点可达的非核心点组成聚类肌肉。但基于密度的聚类算法不适合于多密度数据集和含有桥接聚类的数据集,聚类精度与邻域半径、密度阈值两个参数高度相关,时间复杂度为O(n2),由于DBSCAN使用欧几里得度量距离,致使在处理高维数据集时陷入维数灾难。
为提高聚类质量,Rodriguez等[10]将基于中心划分和基于密度划分的方法相结合提出密度中心聚类(Clustering by Fast search and find of Density Peaks, CFDP)算法,该算法认为聚类中心具有较大局部密度且彼此相距较远,剩余点就近分配给比其密度高的点所在聚类。从骨架的角度分析,聚类中心及其周围拥有大于平均局部密度上界的核心点集合构成聚类的骨架,与已分类数据点距离小于截断距离(cutoff distance)的非核心点集合形成聚类肌肉。CFDP算法可自动识别出含噪声和任意形状、密度的簇;但是当一个簇中包含多个核心点时,算法会将一个完整的簇划分为多个簇,且该算法的整体时间复杂度较高。
针对DBSCAN和CFDP均不适用于多密度数据集且时间复杂度较高的问题,Chen等提出密度骨架聚类(CLUstering based on Backbone, CLUB)算法[11],依据互k近邻一致性,将互为k近邻的点划为同一簇[12],形成初始簇,并在每个初始簇中分别使用k近邻识别出密度骨架,未分配的低密度点寻找距离其最近的高密度点,形成聚类肌肉。该算法使用密度骨架获得簇结构,有效解决了桥接簇和同一个簇中出现多个聚类中心而导致错误划分的问题;使用空间索引查找k近邻点,将时间复杂度降低为O(n·logn)。但该算法在识别密度骨架的过程中,两次建立索引查找k近邻点,形成初始聚类之后,要计算每个簇中数据点的局部密度并进行排序,故实际的运行时间开销依旧很大。能否通过一次查找k近邻得到高密度骨架是值得研究的问题。
为提高聚类算法的效率和在高维数据集上的聚类准确性,本文提出一种快速识别高密度骨架的聚类(Efficient CLUstering based on density Backbone, ECLUB)算法。本文的主要工作如下:
1)定义一种基于k近邻的对象局部密度计算方法,可用于高维空间数据密度的计算;
2)提出一种识别密度骨架的简单方法,能快速识别出任意形状、任意密度的聚类骨架。
1 ECLUB算法
1.1 符号与定义
设数据集D={x1,x2,…,xn},其中xi=(xi1,xi2,…,xim)(i=1,2,…,n)。
定义1k近邻集。给定x∈D,距离点x最近的前k个点x构成的k近邻集,记作NNk(x):
NNk(x)={y∈D|d(x,y)≤kdist(x)}
其中:d(x,y)表示点x和y的欧氏距离;kdist(x)表示点x到其第k个最近邻点的欧氏距离。
定义2 互k近邻。给定x,y∈D,如果x∈NNk(y)且y∈NNk(x),称x和y互为k近邻。
互为k近邻的两个点,极有可能在同一个簇[11]。
定义3 共享k近邻集。给定x,y∈D,如果x和y互为k近邻,∃z∈D既属于NNk(x),又属于NNk(y),称z为x和y的共享k近邻点,这样的点构成集合称为x和y的共享k近邻集,记作SNN(x,y):
SNN(x,y)=NNk(x)∩NNk(y)
若点x和y互为k近邻且同属一个簇,则x和y的共享k近邻点也极有可能同属这一类[11]。
定义4 对象的局部密度。点x的局部密度定义为σ(x):
(1)

定义5 簇密度。簇密度是指簇中所有对象的局部密度的平均值,簇C的簇密度记为den(C):
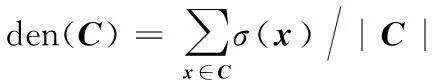
(2)
其中:|C|表示簇C中数据点总个数。簇密度作为判断是否将数据对象划分为同一簇和是否能合并两个簇的依据。
定义6 点簇密度相似度。给定x,y∈D,x与簇C的点簇密度相似度记作SDC(x,C):
SDC(x,C)=|1-σ(x)/den(C)|
(3)
点簇密度相似度表征点与簇在密度上的相似程度,越接近0,说明点x的局部密度与簇C中包含点的局部密度越接近。
定义7 簇密度相似度。给定两个簇Cp、Cq,Cp∩Cq=∅,簇密度相似度记作SCC(Cp,Cq)
(4)
在CLUB算法中,若点xi和xj互为k近邻,则xi、xj以及它们的SNN(xi,xj)极有可能在同一个簇。若增加CLUB算法在识别密度骨架时对密度的限制条件,则更有把握将满足以下条件的数据对象分为一类,ε值的取值范围为[0,1)。
条件1 若xi和xj互为k近邻,xi∈Cq,xj未标记,且满足SDC(xj,Cq)≤ε,则将点xi和xj划为同一簇,即xj∈Cq。
条件2 若xi,xj∈Cq,xk∈SNN(xi,xj),xk未标记,且满足SDC(xk,Cq)≤ε,则将点xk、xi和xj划分为同一簇,即xk∈Cq。
条件3 若xi和xj互为k近邻,xi∈Cp,xj∈Cq,且满足SCC(Cp,Cq)≤ε,则合并簇Cp和簇Cq。
1.2 ECLUB算法步骤
ECLUB算法基于以下思想:互为k近邻的高密度点及其SNN在满足密度相近的条件下可分为一类,形成高密度骨架,未分配的低密度点寻找距离其最近的高密度点形成聚类肌肉或标记为离群点。ECLUB算法描述如算法1所示。
算法1 ECLUB。
输入 数据集D、近邻点个数k;
输出 聚类结果C。

b)将满足条件1、2和3的数据对象分为一类,更新簇密度。
步骤3 低密度点的分配。未标记的低密度点与其互为k近邻的点分为一类,若其不存在互为k近邻的点,则标记为离群点。
ECLUB算法定义了对象的局部密度,在识别密度骨架的过程中,同时考虑近邻关系以及点、簇的密度关系,通过一次查找k近邻点,一次遍历数据对象,得到高密度骨架,提高了算法效率。
2 实验结果与分析
本文所有实验环境均为Windows 7 64位操作系统,Matlab R2015a软件,CPU为AMD 3.4 GHz,内存为4 GB。
2.1 实验数据集
实验选用8个数据集,其中3个人工合成数据集来自同类研究的相关文献[10-11],分别用于验证ECLUB算法在处理桥接簇、多密度簇和非球形簇的能力;5个真实数据集来源于UCI机器学习数据库[13]和Olivetti Face数据库[14]的100张头像,用于验证ECLUB算法对真实的高维数据处理的有效性。Olivetti Face数据集中包含10个人物,每个人物拥有不同表情、侧脸、是否佩戴眼镜等特征的10张头像图片。表1详细描述了实验中使用到的数据集。

表1 实验中用到的人工合成数据集和真实数据集Tab. 1 Synthetic datasets and real datasets used in the experiment
2.2 评价指标
实验的评价指标采用调整兰德系数(Adjusted Rand Index, ARI)和归一化互信息(Normalized Mutual Information, NMI),这两个指标用于度量聚类结果的准确性,取值越接近1,表明聚类结果越准确。
2.3 算法有效性分析
图1是ECLUB算法在不同数据集上的聚类结果,不同灰度点代表不同簇。图1(a)是k∈[16,18]时的聚类结果,表明ECLUB算法可以准确识别出aggregation数据集中桥接聚类的簇;图1(b)是k∈[6,9]时的聚类结果,表明ECLUB算法能够准确识别出compound数据集中相互嵌套的多密度簇;图1(c)是k∈[45,60]时的聚类结果,表明ECLUB算法能够有效识别T4数据集中带有干扰线的非球形聚类。上述三个二维数据集上的聚类结果验证了ECLUB算法的有效性。
图2显示ECLUB算法对Olivetti Face数据集的聚类结果,同一簇用相同灰度值的图片表示,右下最后一个头像图片灰度值最低,用于表示不属于任何簇。ECLUB算法能准确识别出8个簇,分别为前两个和后六个人物,中间(第3、4个)人物误分为一类,ARI和NMI分别为0.877 9和0.962 2;文献[11]给出了CLUB算法对Olivetti Face数据集的聚类结果,CLUB算法能够识别出8个簇,其中:3个头像未分类,14个头像误分类,ARI和NMI分别为0.775 8和0.884 3。可以看出,ECLUB算法对于Olivetti Face数据集的聚类结果准确性要高于CLUB算法。

图1 ECLUB算法在人工数据集上的聚类结果Fig. 1 Clustering results of ECLUB algorithm on artificial datasets

图2 ECLUB算法在Olivetti Face数据集的聚类结果Fig. 2 Clustering results of ECLUB algorithm on Olivetti Face dataset
表2采用ARI和NMI对4种算法在人工数据集和真实数据集的实验结果进行评价(T4数据集缺少真实类标号,不包含其评价)。ECLUB与CLUB算法相比,ECLUB算法的ARI值有6项为最高,NMI值有5项为最高;CLUB算法的ARI值有4项为最高,NMI值有5项为最高。ECLUB算法对Segmentation和compound数据集的聚类准确性低于CLUB算法,但偏差极小;对Glass和Olivetti Face数据集的聚类准确性比CLUB算法平均提高了25.02%。同样,ECLUB算法的ARI和NMI评价指标在绝大多数的数据集上均高于CFDP和DBSCAN算法。整体来看,上述结果验证了ECLUB算法在人工数据集和高维真实数据集聚类结果的有效性和准确性。
2.4 算法时间复杂度及运行效率分析
本文算法使用局部敏感哈希函数[7]查找k近邻,时间复杂度为O(nlogn),其中n为数据集总个数。在ECLUB算法步骤步骤1中使用快速排序算法对点局部密度降序排列,时间复杂度为O(nlogn);识别密度骨架时仅考虑前2/3的数据量,时间复杂度为O(2kn/3),其中,k为近邻个数,通常k≪n,故可记为O(n);对低密度点进行分配时,时间复杂度为O(kn/3),通常剩余点数远小于n/3,甚至接近于0,故可忽略不计。因此ECLUB算法的整体时间复杂度为O(nlogn)。
CFDP算法和DBSCAN算法的时间复杂度为O(n2),随着数据量的增加,算法运行时间呈指数型增长;ECLUB算法和CLUB算法的时间复杂度为O(nlogn),接下来主要对比ECLUB和CLUB算法在不同数据量上的运行时间。在人工合成数据集上分别执行ECLUB和CLUB算法,针对不同数据量,每种算法均独立运行10次,选取10次实验的平均值作为算法在该数据量上的运行时间。如图3所示,随着数据量的增加,ECLUB算法较CLUB的高效性逐步凸显。当数据量为20 000时,CLUB算法的运行时间为777.060 s,ECLUB算法的运行时间为486.008 s。

表2 不同算法在不同数据集上的聚类结果Tab. 2 Clustering results of different algorithms on different datasets

图3 不同数据量上ECLUB和CLUB的运行时间对比Fig.3 Running time comparison of ECLUB and CLUB on different data volumes
虽然ECLUB算法与CLUB算法时间复杂度相同,但后者在识别密度骨架时,首先通过互k近邻和共享k近邻集识别初始簇,然后要对每个初始簇中的数据点重新查找k近邻,并计算局部密度。在实际运行情况下,ECLUB算法仅需一步识别密度骨架,故与CLUB算法相比,运行效率更高。
2.5 高密度点所占比例与相似度阈值的分析
图4展示了经降序排列后的点局部密度的斜率变化情况,从a点之后,点局部密度值开始呈现快速降低,由高密度点逐步转化为低密度点。根据a点所处位置,判断出高密度点所占比例。在人工数据集和真实数据集上的实验显示,高密度点所占比例的选取具有鲁棒性,图4中两种数据的高密度点所占比例可选范围分别为[40%,80%]、[32%,82%]。本文中统一将2/3作为高密度点所占比例。
相似度阈值ε的大小约束着局部密度差异对数据点划分和簇合并的影响程度。根据点簇密度相似度和簇密度相似度的定义,SDC(x,C)≤ε,即|1-σ(x)/den(C)|≤ε,可转化为den(C)·(1-ε)≤σ(x)≤den(C)·(1+ε),故0≤ε<1;同理,SCC(Cp,Cq)≤ε,即|1-2den(Cq)/(den(Cp)+den(Cq))|≤ε,可转化为|den(Cp)-den(Cq)|/(den(Cp)+den(Cq))≤ε,故0≤ε<1。ε值过大,容易将密度差异大的数据点分为一类;相反,ε值过小,导致局部密度相近的点或簇不能准确地进行合并。从图5可以看出,随着ε值的增大,ARI呈现先增大后减小的趋势。在人工数据集和真实数据集上的实验结果表明,ε值在[0.01,0.8]的范围内,ARI均能取得较高值,当ε值为0.01时,ARI均为最高。本文实验中统一将ε取值为0.01。

图4 经降序排列后的局部密度斜率变化Fig.4 Slope changes of local density after listing in descending order
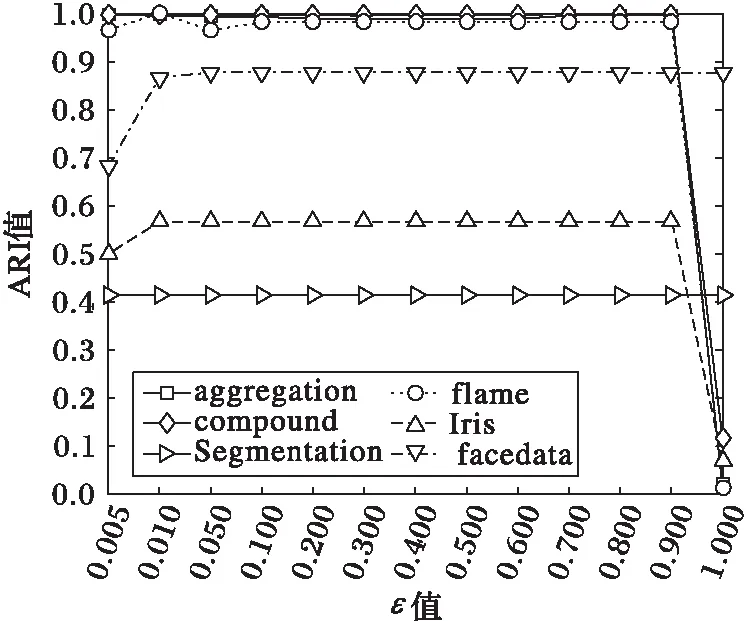
图5 不同数据集上ε值变化对ARI的影响Fig.5 Effect of ε value on ARI for different datasets
3 结语
本文提出一种快速识别密度骨架的聚类算法ECLUB,该算法在识别密度骨架的过程中,同时考虑近邻关系以及点和簇的密度关系,避免了CLUB算法必须通过两步识别高密度骨架的缺陷。ECLUB算法可以有效发现任意形状、不同密度的簇,可适用于任意维度,在保证算法聚类结果准确性有所提高的同时,提高算法聚类速度。如何在密度骨架的基础上,进一步提高聚类准确性是下一步的研究工作。
References)
[1] JAIN A K. Data clustering: 50 years beyondK-means [J]. Pattern Recognition Letters, 2010, 31(8): 651-666.
[2] 伍育红.聚类算法综述[J].计算机科学,2015,42(z1):491-499,524.(WU Y H. General overview on clustering algorithms [J]. Computer Science, 2015, 42(z1): 491-499,524.)
[3] FREY B J, DUECK D. Clustering by passing messages between data points [J]. Science, 2007, 315(5814): 972-976.
[4] 陈治平,胡宇舟,顾学道.聚类算法在电信客户细分中的应用研究[J].计算机应用,2007,27(10):2566-2569,2577.(CHEN Z P, HU Y Z, GU X D. Applied research of clustering algorithm in telecom consumer segments [J]. Journal of Computer Applications, 2007, 27(10): 2566-2569, 2577.)
[5] BRODER A, GARCIA-PUETO L, JOSIFOVSKI V, et al. ScalableK-means by ranked retrieval [C]// WSDM 2014: Proceedings of the 7th ACM International Conference on Web Search and Data Mining. New York: ACM, 2014: 233-242.
[6] MIYAHAR S, MIYANOTO S. A family of algorithms using spectral clustering and DBSCAN [C]// Proceedings of the 2014 IEEE International Conference on Granular Computing. Piscataway, NJ: IEEE, 2014: 196-200.
[7] 邱保志,贺艳芳,申向东.熵加权多视角核K-means算法[J].计算机应用,2016,36(6):1619-1623.(QIU B Z, HE Y F, SHEN X D. Multi-view kernelK-means algorithm based on entropy weighting [J]. Journal of Computer Applications. 2016,36(6):1619-1623.)
[8] PARSONS L, HAQUE E, LIU H. Subspace clustering for high dimensional data: a review [J]. ACM SIGKDD Explorations Newsletter, 2004, 6(1): 90-105.
[9] LYU Y H, MA T H, TANG M L, et al. An efficient and scalable density-based clustering algorithm for datasets with complex structures [J]. Neurocomputing, 2016, 171(C): 9-22.
[10] RODRIGUEZ A, LAIO A. Clustering by fast search and find of density peaks [J]. Science, 2014, 344(6191): 1492-1496.
[11] CHEN M, LI L J, WANG B, et al. Effectively clustering by finding density backbone based-onkNN [J]. Pattern Recognition, 2016, 60: 486-498.
[12] ALTMAN N S. An introduction to kernel and nearest-neighbor nonparametric regression [J]. American Statistician, 1992, 46(3): 175-185.
[13] ASUNCION A, NEWMAN D. UCI machine learning repository [EB/OL]. [2017- 03- 27]. http://archive.ics.uci.edu/ml/.
[14] AT&T Laboratories Cambridge. The database of faces at a glance [EB/OL]. [2017- 03- 27]. http://www.cl.cam.ac.uk/research/dtg/attarchive/facesataglance.html.
This work is partially supported by the Basic and Advanced Technology Research Project of Henan Province (152300410191).
QIUBaozhi, born in 1964, Ph. D., professor. His research interests include data mining, artificial intelligence.
TANGYamin, born in 1991, M. S. candidate. Her research interests include data mining.
Efficientclusteringalgorithmforfastrecognitionofdensitybackbone
QIU Baozhi, TANG Yamin*
(SchoolofInformationEngineering,ZhengzhouUniversity,ZhengzhouHenan450001,China)
In order to find density backbone quickly and improve the accuracy of high-dimensional data clustering results, a new algorithm for fast recognition of high-density backbone was put forward, which was named Efficient CLUstering based on density Backbone (ECLUB) algorithm. Firstly, on the basis of defining the local density of object, the high-density backbone was identified quickly according to the mutual consistency ofk-nearest neighbors and the local density relation of neighbor points. Then, the unassigned low-density points were divided according to the neighborhood relations to obtain the final clustering. The experimental results on synthetic datasets and real datasets show that the proposed algorithm is effective. The clustering results of Olivetti Face dataset show that, the Adjusted Rand Index (ARI) and Normalized Mutual Information (NMI) of the proposed ECLUB algorithm is 0.877 9 and 0.962 2 respectively. Compared with the Density-Based Spatial Clustering of Applications with Noise (DBSCAN) algorithm, Clustering by Fast search and find of Density Peaks (CFDP) algorithm and CLUstering based on Backbone (CLUB) algorithm, the proposed ECLUB algorithm is more efficient and has higher clustering accuracy for high-dimensional data.
clustering algorithm; high-dimensional data;k-nearest neighbor; density backbone; local density
2017- 06- 01;
2017- 08- 17。
河南省基础与前沿基金资助项目(152300410191)。
邱保志(1964—),男,河南驻马店人,教授,博士,CCF会员,主要研究方向:数据挖掘、人工智能; 唐雅敏(1991—),女,河南郑州人,硕士研究生,主要研究方向:数据挖掘。
1001- 9081(2017)12- 3482- 05
10.11772/j.issn.1001- 9081.2017.12.3482
(*通信作者电子邮箱yamin_tang@163.com)
TP391.4
A
猜你喜欢
数学杂志(2022年4期)2022-09-27
当代水产(2022年3期)2022-04-26
资源信息与工程(2021年5期)2022-01-15
四川大学学报(自然科学版)(2021年6期)2021-12-27
科学家(2021年24期)2021-04-25
唐山师范学院学报(2018年6期)2018-12-25
世界知识画报·艺术视界(2017年7期)2017-07-27
自动化学报(2017年11期)2017-04-04
文苑(2015年9期)2015-09-10
医学研究杂志(2015年12期)2015-06-10
