
结合本体子图的RDF数据关键词分布式搜索
2018-01-16 03:14汪璟玢
福州大学学报(自然科学版) 2017年6期
陈 双,汪璟玢
(福州大学数学与计算机科学学院,福建 福州 350116)
0 引言
近年来,随着Linking Open Data和Wikipedia等项目的全面开展,使得Web 上的RDF数据量呈爆炸式增长[1]. 目前有关RDF上的关键词搜索方法, 可分为两类: 关键词结构化和关键词直接匹配[2]. 第一种由关键字构造结构化查询语句进行查询得到结果, 文献[3-4]将关键字翻译成联合查询, 再得到SPARQL查询语句. Ladwig等[4]从RDF数据中抽取结构信息,构造结构化查询,然后查询得到结果. 但这类方法实时响应速度并不理想,时间开销大, 执行策略依赖于用户的反馈,难以适应大规模RDF数据存储与搜索需求. 另一种关键词直接匹配方法[5-6], 在图数据上直接匹配包含所有查询关键词的子图, 利用评分函数对候选答案排序,返回Top-k查询结果. Le等[5]从RDF图数据根据其类型抽取摘要信息,进行剪枝从而加速搜索效率. 李慧颖等[7]将RDF数据建模成顶点带标签的实体三元组关联图,利用斯坦纳树近似算法实现了快速查询响应. 但都是集中式处理难以扩展为分布式搜索,从图中匹配关键词的节点相对容易,确定节点之间的连接需要迭代地在图上搜索. 因此,Virgilio[8]等提出一种新颖的完全分布式的RDF关键字搜索方法,预先存储大量图数据路径索引,利用MapReduce 将图并行问题转换为数据并行处理问题,进行高效的分布式搜索.
现存的分布式RDF数据查询处理方案,集中于结构化查询SPARQL的研究,查询规则复杂不能满足普通用户查询需求,且难以适用于面向大规模RDF数据的关键词搜索的场景. 因此,本研究提出一种面向大规模RDF数据的分布式关键词搜索算法(KDSOS), 首先结合RDF本体构造关键词对应的本体子图集并利用评分函数评分,接着利用MapReduce计算框架分布式并行搜索,优先按评分高的本体子图连接生成查询结果子图,直至找到Top-k搜索结果.
1 相关定义
1.1 RDF数据模型
资源描述框架(resource description framework,RDF)是W3C推荐的用于在语义万维网上表示信息的重要框架标准,通常采用 XML和三元组形势来刻画RDF,简单易于掌握,可以灵活地表达数据语义. RDF数据集可由许多三元组构成,其中每个三元组由主语(subject)、谓语(predicate)和宾语(object)3部分依次构成. 把主语和宾语看作两个点,谓语是由主语指向宾语的一条边,那么一个RDF数据集可被看成一个有向标记图. 文中采用三元组形式表示RDF数据图.
1.2 OWL本体

图1 RDF本体图片段Fig.1 Segment of RDF ontology graph
OWL(web ontology language)是W3C推荐的语义互联网中本体描述语言的标准,由个体(individual)、属性(property)和类(class)3部分组成. RDFS (RDF schema)是RDF图数据的本体,定义类、属性、类间及属性间的关系,涵盖了个体资源的分类及关联关系. 图1为数据集DBPedia[9]对应的 RDF本体图片段,其中实例类SpaceMission和实例类Rocket通过属性booster关联起来,属性booster边由SpaceMission指向Rocket.
1.3 相关定义
待解决的问题:给定关键词查询Q={q1,q2, …,qi, …,qm},RDF数据图G,返回Top-k搜索结果. 以下给出RDF关键词搜索的相关定义.
定义1(RDF三元组) 设t〈s,p,o〉表示RDF三元组. 其中,s∈(IUB),p∈(IUB),o∈(IUBUL),I是URI顶点的集合,B是空白顶点集合,L是文本顶点集合.
定义2(RDF图) 设G={t1,t2, …,ti, …,tn}表示RDF图,一个RDF图由一组RDF三元组定义.

图2 类-属性二维模型Fig.2 Class-property dimensional model
定义3(单元路径, 记为p) 图1等价转换为图2类-属性二维模型(记为CP),定义X-CP[X][Y]-Y为单元路径,X、Y取值为实例类,CP[X][Y]取值为属性,X与Y之间通过属性关联起来. 若实例类X和Y无关联属性,则为CP[X][Y]= ⊄. 通过单元路径就可以直观地表示出类与类、类与属性间的关联关系.
定义4(本体子图, ontology subgraph) 设Gs={p1,p2, …,pi, …,pn},一个本体子图由n条单元路径组成,其中任意两个单元路径pi=Xi-CP[Xi][Yi]-Yi和pj=Xj-CP[Xj][Yj]-Yj,通过X或Y或经过其他单元路径pk连接起来,即(Xi=Xj)或(Yj=Yi)或(Yi=Xj)或(Yj=Xi)或(pi-pk-pj). 一个本体子图表示为一组单元路径构成的集合.
定义5(查询结果,记为R) 设R= {t1,t2, …,tk, …,tr},查询结果是包含所有查询关键词顶点的一组三元组构成的连通子图,两个三元组集合中元素不完全相同,则认为是不同的查询结果.
定义6(评分函数score estimation, 记为SE) 输入查询Q={q1,q2, …,qi, …,qm},对应RDF本体实例类C={c1,c2, …,ci, …,cm},假定Q对应的一个本体子图Gsk={p1,p2, …,pi, …,pq},其中pi=ch-CP[ch][cg]-cg,ch,cg∈C.


2 KDSOS算法
为了减小在大规模图上迭代计算关键词间连接路径的开销,方法先结合RDF本体图为输入关键词构建对应的本体子图集,然后利用SE评分函数进行评分排序,最后在RDF数据图上分布式搜索关键词顶点按本体子图连接关系进行连接即可生成结果子图,从而避免在大量数据图顶点上直接迭代搜索顶点间连接路径,提高搜索效率. KDSOS算法的总体框架设计如图3所示.

图3 KDSOS算法框架Fig.3 Algorithm framework of KDSOS
2.1 RDF分布式存储模型
根据RDF图数据的特点,同一类型的RDF实例三元组数据间的语义关系较密切. 实验借助分布式数据库Hbase作为存储媒介,依据类别进行分布式存储,具有关联的同类数据存放一起. 具体Hbase表及存储内容说明:
OWL_Table表:存储RDF本体信息,类、属性的定义信息及关联关系;
Index_S_Table表:主语S索引表, 存储所有主语为S的实例三元组对应类表
Index_O_Table表:宾语O索引表, 存储所有宾语为O的实例三元组对应的类表
ClassName_SPO表:存储每个类的实例三元组信息,以(S, P, O)形式
ClassName_OPS表: 存储每个类的实例三元组信息, 以(O, P, S)形式
其中,Index_S_Table和Index_O_Table是以S和O为主键的索引表,根据输入查询关键词快速定位到对应的具体实例类表ClassName_SPO或ClassName_OPS,帮助提高搜索效率.
2.2 构建关键词对应本体子图集
在2.1节基础上,为用户输入查询关键词构建本体子图集. 首先确定各个查询关键词对应本体中的实例类,构建类-属性二维模型CP,然后从中查找所有实例类对应的单元路径连接生成本体子图集. 由于一个关键词对应的实例类可能存在多个或类间有多种关联关系,因此一个查询Q会存在多个本体子图,通过SE函数评分排序. 算法1如下所示.

算法1:build-Gsk(Q,CP)输入:关键词查询Q,Hbase数据表,CP输出:本体子图集按降序排列1. typeList←Q中m个查询关键词对应实例类集2. H←⊄;//大小为k的大堆,堆中SE(Gs)≥SE(Gs’)3. Gs←⊄;//初始化4. forci∈typeList&i=1,2,…,m5. forcj∈typeList&j=1,2…,m{6. buildCP(CP,ci,cj);//构建实例类ci,cj关联路径7. Gs.add(
举例说明,输入查询关键词“Apollo-11, Rocket, Armstrong”表达用户想查询关于“阿波罗11号”的信息. 为了便于解释算法1执行过程,如图4所示,其中01, 02, 03和04分别表示关键词对应本体中实例类SpaceMission, string, Person和Rocket,CP[01][02]=name,CP[01][03]=crew, CP[01][04]=booster, CP[03][02]=name, 得到多个单元路径连接生成一个本体子图Gs1={p1,p2,p3,p4},图结构表示见图5.
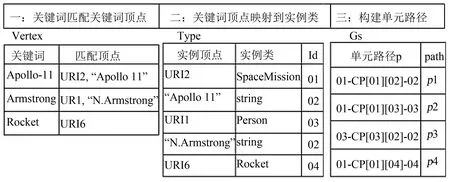
图4 搜索过程示例Fig.4 Process of search example
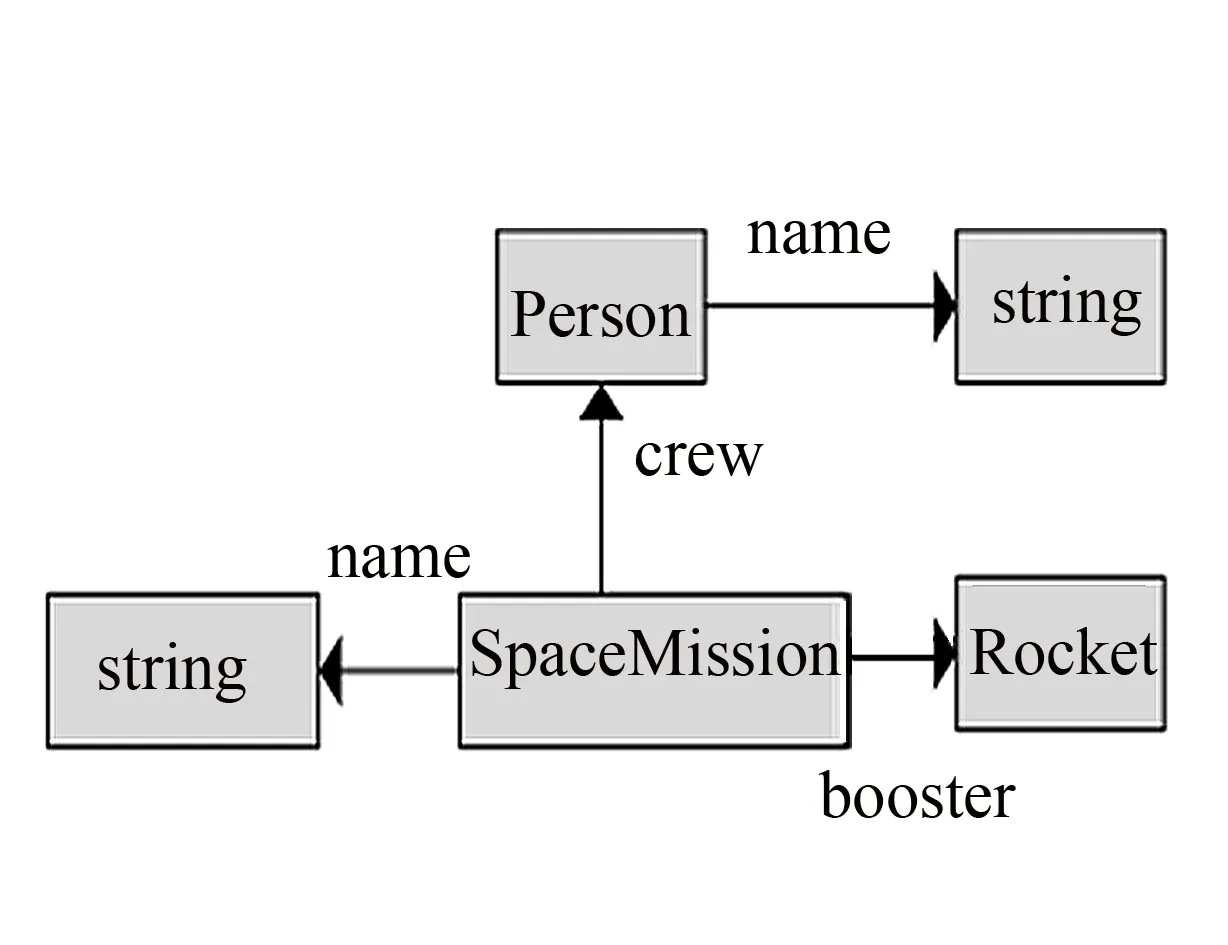
图5 关键词对应的本体子图Fig.5 Ontology sub-graph for query keywords
2.3 分布式并行搜索
借助MapReduce并行计算模型来完成分布式搜索. MapReduce处理过程包括Map阶段与Reduce阶段. 假定用户输入由m个关键词构成的查询Q,其对应RDF本体中的实例类集合C和匹配的关键词顶点集合V. 执行2.2节算法1,得到查询Q对应的本体子图集Gs={Gs1, Gs2, …, Gsi, …, Gsk}. 一个本体子图Gsi由多个单元路径段构成的,显然Gs中不同本体子图间有公共单元路径,因此,在进行MapReduce 计算前,先提取Gs所有本体子图公共单元路径,若Gs1和Gs2具有公共单元路径{p1,p2},记为〈(1, 2), (p1,p2)〉,保证公共单元路径在搜索过程中只要计算一次.
Map阶段:V和Gs作为Map的输入,搜索本体子图集中所有单元路径对应的实例三元组,若三元组满足条件则生成一对〈key,value〉,key为对应的本体子图Gsi,value为四元组,如〈(Gsi), (p1,st,pt,ot)〉表示实例三元组(st,pt,ot)满足本体子图Gsi中一条单元路径p1.
Reduce阶段: Map的输出作为Reduce的输入,优先按评分值高的本体子图连接关系连接满足条件的实例三元组,最后返回查询Top-k结果Rs = {R1,R2, …,Ri, …,Rk}. 本研究方法只需开启一个MapReduce任务就可以完成搜索. MapReduce分布式并行搜索过程如图6所示.

Map阶段Reduce阶段Input:Q={q1,q2,…,qi,…,qm}Output:
图6 MapReduce分布式搜索过程
Fig.6 Process of MapReduce distributed search
2.4 算法复杂度和完整性分析
2.4.1 算法复杂度分析
算法的时间复杂度包括两部分构建本体子图集和MapReduce分布式搜索阶段的时间复杂度. 假定用户输入关键词个数M,关键词映射后匹配类-属性二维模型中单元路径条数为N,生成的本体子图个数为K,每条单元路径匹配实例三元组条数为p,关键词匹配的实例三元组条数为n. 下面列出这两个阶段最坏情况下的时间复杂性.
1) 构建本体子图集阶段:O(N2×K).
2) 分布式搜索阶段:Map阶段的时间复杂度O(p)和Reduce阶段的时间复杂度O(p×n×K).
综上可知,KDSOS算法最坏情况下搜索一次的时间复杂度为O(N2×K) +O(p)+O(p×n×K). 相比于RDF数据图规模的大小,N、K都非常小,而且搜索时通过类别进行高效的过滤和匹配,每条单元路径匹配到的实例数据p都是小规模且具有语义关联的同类数据,因此算法整体时间复杂度近似常量级别. 算法的时间复杂性验证详见3.2.1小节的对比实验.
2.4.2 算法完整性分析
现有RDF关键词搜索算法是基于图搜索的思想,没有考虑RDF语义信息,存在结果不全或不准确的情况. 算法则充分利用RDF本体,通过将关键词从内容匹配映射到本体语义层面,将原本连接关系未知的关键词通过本体进行语义关联起来. 在分布式搜索的阶段,得到的本体子图集作为MapReduce的一部分输入,MapReduce阶段只要完成数据并行搜索任务,并行搜索各个单元路径匹配到的实例三元组按本体子图进行连接,就能够精确返回与查询关键词匹配的结果子图,从而保证查询结果准确性和完整性. 同时通过SE评分函数评分,优先搜索高匹配的结果. 相比于现有的RDF关键词搜索算法,算法具有与之相当甚至更高的查准率和查全率. 算法的完整性和正确性验证详见3.2.1小节的对比实验.
3 实验结果与分析
实验环境采用完全分布式Hadoop集群和Hbase分布式数据库,由8个节点构成,其中1个主节点,7个从节点. 实验所使用的硬件环境为Intel(R) Core(TM) i5-3570,CPU 3.40GHz,内存8 GB. 软件环境为操作系统Linux Ubuntu,编程语言java,开发环境为Eclipse.
3.1 实验数据集
为验证KDSOS方法的有效性,采用dblp[10]和DBpedia[9]两个真实RDF数据集,与文献[8]方法进行了对比实验. 表1列出10个有代表性的查询示例, 分别包括1~5个关键词, 第1组Q1~Q5用来测试dblp的查询,第2组Q6~Q10用来测试DBpedia的查询. 实验评价原则和结果的评测指标参见第3.2节.

表1 查询关键词
3.2 实验结果分析
从开启MapReduce任务数、搜索响应时间、查准率和查全率方面来分析实验结果,并在不同节点个数的集群和不同大小规模的数据上进行实验分析,验证算法具有良好的可扩展性.
3.2.1 搜索响应时间和正确性分析

图7 查询响应时间对比 Fig.7 Comparison of response time
算法查询时间包括构建本体子图集时间和分布式并行搜索时间,因为RDF本体规模大小一般都为KB级别的(RDF本体中定义的类和属性个数一般是几百到千级别的),构建出查询关键词对应的本体子图集是很高效的,构建时间<1 s. 查准率(precision)用来衡量Top-k搜索结果的准确率,指搜索结果中正确的条数与搜索结果总条数的比值. 查全率(recall)指搜索结果中正确的条数与数据集中相关的总条数的比值. 实验k值取10,查询响应时间取值为执行10次查询的平均值,查询单位时间为秒(s). 对比实验结果如图7~9所示,图7~9中的查询Q1~Q5是测试dblp数据集的查询,查询Q6~Q10为测试DBpedia数据集的查询,Q1~Q10具体查询关键词如表1所示.

图8 查准率对比 Fig.8 Comparison of precision

图9 查全率对比 Fig.9 Comparison of recall
通过对比实验发现, 文献[8]方法要开启2个MapReduce任务,第一个任务处理产生可连接的路径,第二个任务分析计算得到Top-k查询结果. KDSOS方法需开启的MapReduce任务数为1,有效地减少开启多个MapReduce任务迭代处理消耗的时间. 分析图7可知,KDSOS方法的查询效率明显优于文献[8]方法. 文献[8]通过为RDF数据图构建大量的路径索引帮助查询,大量的图路径分布式在集群的不同节点,进行查询连接返回结果,MapReduce并行度大,网络传输开销大,因此查询耗时较长. KDSOS方法通过本体子图构建关键词KDSOS降低并行计算复杂度提高查询效率. 分析图8~ 9,查询结果的查准率和查全率与文献[8]比,也具有一定优势. KDSOS方法基于RDF本体可以更好地查询关键词间语义关联信息,SE评分函数有效地筛选出高匹配的本体子图,缩小搜索范围,从而提高查询准确率和搜索效率.
3.2.2 算法可扩展性分析
为了验证KDSOS算法的扩展性,在不同节点个数的集群和不同大小规模的数据上进行实验分析,实验结果如图10、11所示. 图10 是集群节点个数分别为4、6、8和10,测试数据集DBpedia的查询Q6~Q10的响应时间对比结果. 随着集群节点增加,两种方法的查询响应时间均有所增加,是因为当集群节点个数增加,开启MapReduce任务时间会增加,且数据分布在不同节点导致节点间数据传输时间会增加,但文献[8]方法的查询时间增加更明显. 因为文献[8]方法需开启多个任务,查询连接并行度大,网络传输开销也大. 图11 为DBpedia数据集从版本3.7,3.8到3.9数据规模不断变大的情况下,执行查询Q6~Q10响应时间的对比结果. 从图11实验对比结果,可以看出KDSOS算法执行查询所需时间不会随着数据量的倍数增大而增加倍数,增长近似平缓. 当数据量增大时,方法的优势越能得到体现,这得益于通过本体子图连接查询关键词顶点使查询连接计算复杂度不会随数据规模呈线性增长. 综上所述,KDSOS算法具有良好的可扩展性.

图10 不同节点个数的集群下查询响应时间对比Fig.10 Comparison of response time on different cluster nodes
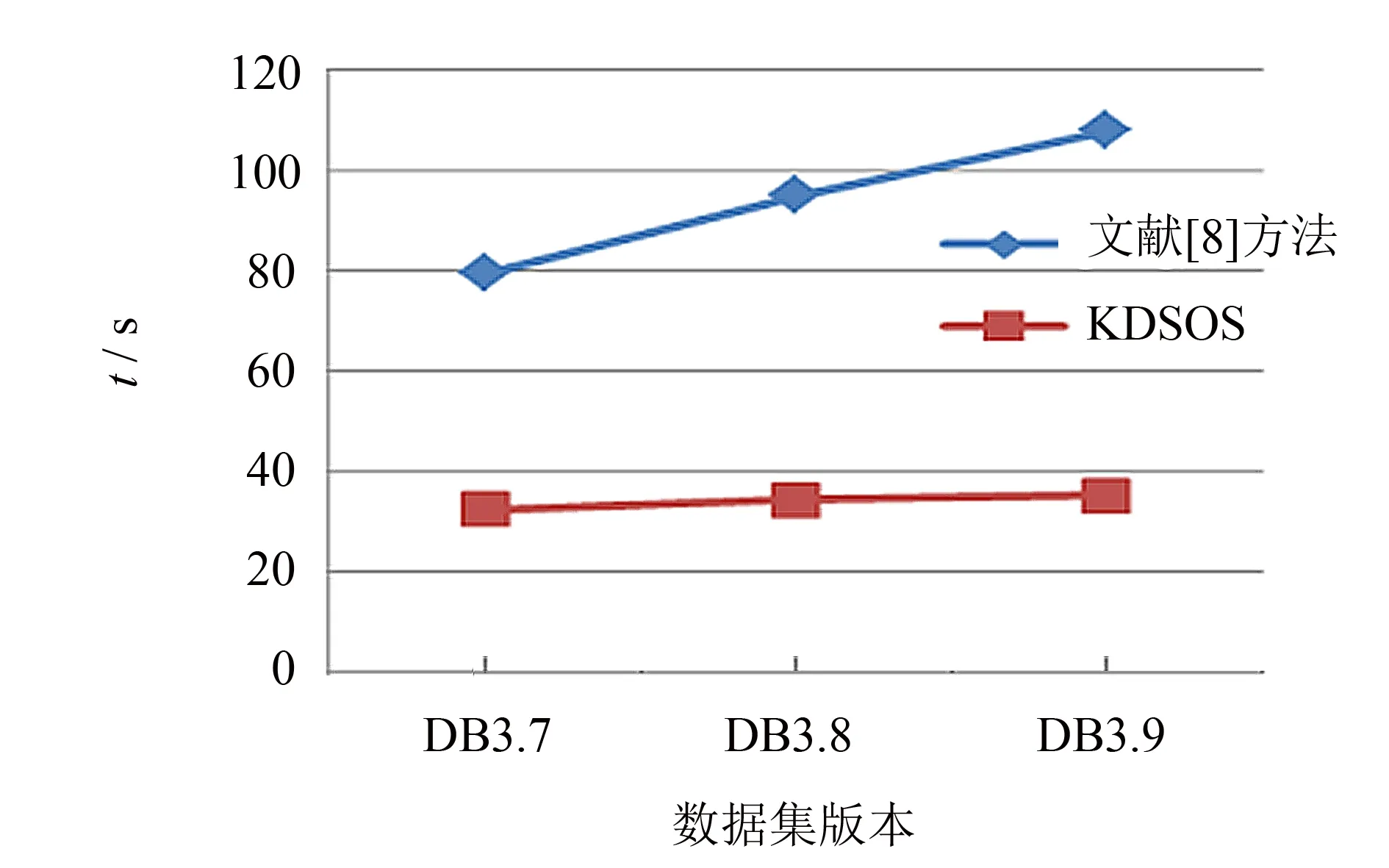
图11 不同大小规模数据查询响应时间对比Fig.11 Comparison of response time on different scale data
4 结语
本研究提出结合RDF本体构建本体子图更好地查询关键词间语义关联信息,减少在大规模图数据上迭代连接计算的复杂度,实现面向大规模RDF数据的高效的分布式关键词搜索. 同时定义评分函数,提高查询关键词与查询结果匹配度,改进搜索质量. 后续研究工作将重点研究如何构建有效地图路径索引,同时考虑缓存技术来帮助提高查询效率并支持对动态数据进行搜索.
[1] KAOUDI Z, MANOLESCU I. RDF in the clouds: a survey[J]. The VLDB Journal, 2015, 24(1): 67-91.
[2] 杜方,陈跃国,杜小勇. RDF数据查询处理技术综述[J]. 软件学报,2013,24(6):1 222-1 242.
[3] ELBASSUONI S, RAMANATH M, SCHENKEL R,etal. Searching RDF graphs with SPARQL and keywords[J]. IEEE Data Eng Bull, 2010, 33(1): 16-24.
[4] LADWIG G, TRAN T. Combining query translation with query answering for efficient keyword search[M]//The Semantic Web: Research and Applications. Berlin: Springer, 2010: 288-303.
[5] LE W, LI F, KEMENTSIETSIDIS A,etal. Scalable keyword search on large RDF data[J]. IEEE Transactions on Knowledge and Data Engineering, 2014, 26(11): 2 774-2 788.
[6] ELBASSUONI S, BLANCO R. Keyword search over RDF graphs[C]//ACM International Conference on Information and Knowledge Management. New York: ACM, 2011: 237-242.
[7] 李慧颖, 瞿裕忠. KREAG: 基于实体三元组关联图的 RDF 数据关键词查询方法[J]. 计算机学报, 2011, 34(5): 825-835.
[8] VIRGILIO R D, MACCIONI A. Distributed keyword search over RDF via MapReduce[M]//The Semantic Web: Trends and Challenges. [S.l.]: Springer, 2014: 208-223.
[9] AUER S, BIZER C, KOBILAROV G,etal. Dbpedia: a nucleus for a web of open data[M]. Berlin: Springer, 2007: 722-735.
[10] LEY M. DBLP: some lessons learned[J]. Proceedings of the VLDB Endowment, 2009, 2(2): 1 493-1 500.
猜你喜欢
山西大学学报(自然科学版)(2021年1期)2021-04-21
五邑大学学报(自然科学版)(2019年3期)2019-09-06
同济大学学报(自然科学版)(2019年2期)2019-04-02
计算机技术与发展(2018年12期)2018-12-20
电子科技大学学报(2016年2期)2016-08-31
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
华东师范大学学报(自然科学版)(2014年1期)2014-04-16
现代防御技术(2014年6期)2014-02-28
采矿技术(2011年5期)2011-11-15
