
基于距离最大化和缺失数据聚类的填充算法
2018-01-18 07:10赵星王逊黄树成
电子设计工程 2018年1期
赵星,王逊,黄树成
(江苏科技大学计算机科学与工程学院,江苏镇江212003)
数据挖掘中的数据往往都不可避免的存在着缺失数据、冗余数据、不确定数据和不一致数据等多种问题[1]。在各个领域中,缺失数据这一问题都是不容忽视的。尤其是目前的数据收集工作,已渐渐从人工搜集转变为机器搜集。并且,由于数据量的急速膨胀,导致各种数据质量问题屡见不鲜,在这中间数据缺失尤为常见。导致数据中存在大量“空值”的因素有许多,例如数据收集条件的制约、度量方法错误、人工录入时出现遗漏和违反数据约束等[2]。在某些领域中的数据库中缺失值比例高达50%~60%以上[3,11-12]。这些不完整的数据不仅意味着信息空白,更重要的是它会影响后续数据挖掘抽取模式的正确性和导出规则的准确性[4]。因此,如何处理缺失数据已成为数据清洗及数据预处理领域研究的主要问题之一。
当前,存在的用于缺失值处理的方法共分为两类[13,15]。第一种方法为直接删除不完整数据,将含有缺失值的属性或记录从数据集中全部删除。这种方法的实现方式比较简单,并且容易实现。但这种方法可能会删除潜在的有用数据,使得挖掘结果产生偏差[14]。第二种方法为基于填充技术的方法。该方法是采取填充算法对不完整数据进行填充,大多是运用完整数据分析方法,分析完整数据来对不完整数据进行填充,从而用最接近的值来替代缺失值[5]。这种方法可以提高可用数据的数量。因此,采用填充算法来处理数据缺失问题,不管从量上还是质上,对缺失数据的处理效果都要好于第一种。目前国内外已提出了很多有关缺失数据填充的算法,在当前是一个研究热点。主要可以分为统计方法、分类方法、关联规则分类方法等[6]。虽然这些方法在不同的应用环境下都有各自的优点,但仍然存在一些不足[7]。
文中研究了聚类方法在缺失值填充中的使用,基于K-means聚类的缺失值填充算法根据与目标最相似的实例属性值来估计缺失值,处理后的结果具有较高的准确性。但这种算法方法依然存在一些不足,因此,文中在原有算法基础上,设计了一种改进的算法:基于距离最大化和缺失数据聚类的填充算法。新算法根据相距最远的数据不在同一类中的原则,改进后的算法使用数据间的最大距离确定聚类中心,可以自动确定k值,使得聚类结果达到最优,更高效的进行数据填充;其次,对聚类的距离函数进行改进,采用部分距离度量方式,改进后的算法可以对含有缺失值的记录进行聚类,做到同时进行聚类和标记缺失数据所属类,从而简化原填充算法步骤。最后,在填充过程中,增加对离散型数据的填充处理。
1 改进的基于K-means聚类的缺失数据填充算法
1.1 基于K-means聚类的缺失值填充算法
基于K-means聚类的缺失值填充方法需要对数据进行预处理:提前除去原始数据集中缺失过多数据,这些数据包括含有较多缺失值的记录或者属性。通常情况下,如果缺失的属性值比重达到50%及以上就选择去除该条记录[8]。由于同类事物间有许多属性是相似的。因此,在对完整数据进行聚类后,可以根据聚类结果计算出缺失值并加以填充。
基于K-means算法的缺失值填充算法的主要步骤如图1所示,具体描述如下:
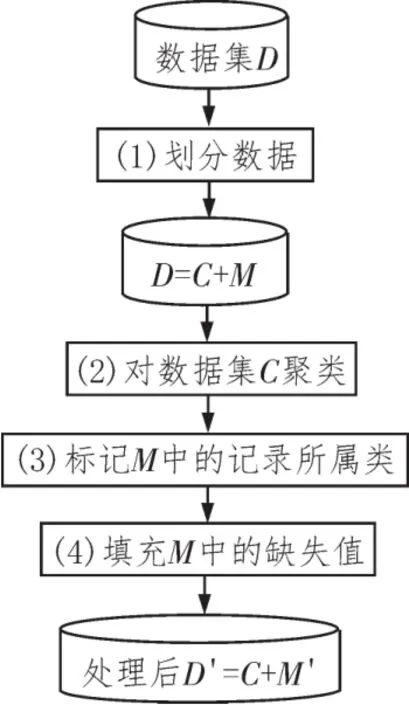
图1 基于聚类算法的缺失值填充算法流程图
输入:含有m个对象的数据集D,聚类个数k
输出:经过缺失值填充处理的数据集D′
步骤:
Step1.根据记录中是否含有缺失值将原始数据集D划分为两个数据子集,分别为完整数据子集C和缺失数据子集M。
Step2.在完整的数据子集C上进行K-means聚类,最终将数据集C分成k个类。
Step3.标记M中的记录所属类。计算缺失数据子集M中的每条记录与C上k个类重心之间的相似度,然后选出相似度最大的一个类,把记录赋给该类。
Step4.填充M中的缺失值。根据上一步标记的所属类,将M中的每条记录的缺失值用标记类相应的属性均值来填充。
经过填充后,得到经过缺失值填充处理的数据集D′,D′包含完整数据子集C和经填充后的子集M′。
从上述描述看出,该算法的输入值有两个,分别为含有m个对象的数据集D和聚类个数k。需要使用者提前输入聚类个数,这是它的缺点所在。并且在填充数据时使用均值,对于离散性数据,正确率会大大降低。
1.2 改进算法的策略
文中从以下几个方面对K-means聚类的缺失值填充算法进行改进。
1)通过最大距离确定k值。原算法要求用户提前输入聚类的个数(k值),这其实也是K-means算法自身的缺点。如果通过经验来评估出k值,有可能会导致最终形成的聚类的结果与实际的类别数目差别甚远。数据量越庞大,k值就越难以估算,并且在聚类的过程中极易陷入局部最优解的局面[10]。若想选择合适的k值,常常需要使用其他方法进行k值的估算。所以本文将基于聚类的缺失值填充算法加以改进,提出了基于距离最大化的k值自动生成算法,在一定程度解决了K-means算法中k值的确定问题。
改进算法思想:针对原算法的第二步加以改进,省略k值的输入,使k值自动生成。首先选择尽可能离得远的数据对象作为初始的聚类中心进行划分,然后分别按照欧式距离寻找各类中离聚类中心点最远的数据对象,再在其中选择距离最大的那个数据对象为新增的聚类中心点,进行重新划分,如此反复,直到满足一定的条件算法结束。聚类完成后,聚类的个数也就自动产生了。
在该算中相似度的计算均采用的是欧式距离度量方式,改进算法步骤与流程如下:
Step1.设定一个含有n个数据对象的集合D,。首先选择距离最大两个数据对象xp,xq作为初始的聚类中心,即xp,xq之间的距离满足,则把xp作为第一个类的聚类中心,记为S1,即S1=xp;把xq作为第二个类的聚类中心,记为S2,即S2=xq。
Step2.将集合Sn中其余的n-2个数据对象,按照欧式距离计算,并以S1,S2为聚类中心划分类,若,则将xi划分到类S1中,否则将xi划分到类S2中,这样就将集合D以S1,S2为聚类中心划分成了两大类,分别记作D21,D22。Step3.计算类D21中的所有数据对象到S1的距离,并取最大距离记为d21,即计算类D22中的所有数据对象到S2的距离,同样取最大距离,得
Step4.取d2=max{d21,d22} ,若d2>hd1(h为输入参数,一般由经验获得),对应的那个数据对象为第3个聚类中心点,记为S3,把D以S1,S2,S3为聚类中心划分成了3大类,分别记作D31,D32,D33。
Step5.计算类D31中的所有数据对象到S1的距离,得,计算类D32中的所有数据对象到S2的距离,得计算类D33中的所有数据对象到S3的距离,得
其中参数h的取值范围为0.5≤h≤1,可以看出h的取值与最终形成的聚类中心的个数成反比。因为h越小越容易满足Step6中的检验条件,即聚类中心之间的距离比较小,也就越容易找到新的聚类中心。根据实际经验,h一般取为0.5。
改进后的算法必须在去除孤立点之后才能使用,因为对未处理的数据进行聚类,恰恰容易选择两个孤立点作为初始的聚类中心,产生错误的聚类结果。但由于此算法应用于数据挖掘前,数据预处理的数据清洗中,数据清洗还需要对数据集光滑噪声并去除离群点,纠正数据的不一致性[9]。所以在此情况下,去除了“噪声”和孤立点数据的影响后,应用此方法,去除了不足之处。并且改进后的聚类算法避免了用户输入的参数对聚类结果的影响,在一定程度上也避免了聚类陷入局部最优解的局面。
2)将聚类和标记操作合并,省略计算缺失数据所属类这一步骤。在K-means聚类的缺失数据填充算法中,第三步为计算每个缺失记录所属类,该步骤需再次搜索数据集,计算缺失记录与类重心的相似度,增加了整个算法的处理时间,针对这一缺点,加以改进,直接对整个数据集进行聚类,在聚类同时对缺失记录做标记。
文中提出了将聚类(Step2)和标记操作(Step3)合并的方法。若要合并2、3步,需要含有缺失值的记录同时参与聚类,但K-means聚类算法不能计算含有缺失值记录之间的距离。并且,在第3步中,计算每个缺失记录所属类,需要计算缺失记录与每个类重心的相似度,最大相似度对应的类标记为缺失记录所属类。其中相似度的计算,则利用欧氏距离计算各个属性之间的相异度,变换之后,得到记录间的相似度。可以看出,第二步聚类中的距离函数和第三步计算缺失记录所属类中的相似度函数均基于欧氏距离。因此若要对含有缺失记录的数据集进行聚类,则需要对K-means算法的距离函数加以改进,来适用于计算含缺失值数据集中对象之间的距离。改进后的算法,属性值之间的距离依然采用欧氏距离,当遇到含有缺失值的记录时,使用该记录的剩余属性值来计算与其他记录之间的距离。通过添加指示变量ε来区分缺失属性值,然后再将该距离乘以扩展系数来计算二者的整体距离。
设整个数据集合为D,数据集D中存在缺失记录,D中每个记录均有m个属性用xi表示记录X的第i个属性值。数据集D中存在记录X和Y,若记录X和Y第i个属性值上存在缺失值,即X和Y其中一个第i个属性值缺失,或X和Y第i个属性值均缺失,则X和Y的第i个属性的指示变量εi为0,否则为1,εi计算公式如式(1):

欧式距离度量方法如式(2),在此基础上加入指示变量和扩展系数,改进后的距离函数如式(3)。
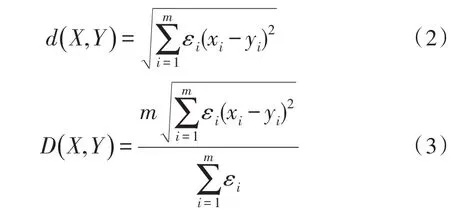
3)使用重值对离散型数据填充。在最后一步填充过程中,原算法采用标记类的属性均值来填充缺失值。若该属性值为离散性数据,使用均值填充,会大大的降低填充的准确性。所以针对此处不足,加以改进:如果缺失数据为数值型数据,则依然使用标记类的平均值作为缺失数据的值;如果缺失数据是离散型数据,则改使用标记类中出现次数最多的属性值作为缺失数据值。计算方法如下:其中Ai为缺失值所在属性的属性值,n为该类记录总数。

1.3 改进算法的步骤
改进的基于K-means算法的缺失值清洗算法的具体描述如下:
输入:含有m个对象的数据集D
输出:已经过缺失值填充处理的数据集D′
方法:
Step1.不做划分,对整个数据集D使用改进的K-means聚类算法进行聚类,会得到k个类,将聚类结果标记为D1,D2,…,Dk。
Step 2.依次检查中D1,D2,…,Dk是否存在缺失记录,若Di中包含缺失数据记录,则将Di拆分成两个子集,分别为完整数据子集Ci和缺失数据子集Mi,即数据子集Ci中的所有记录均为完整记录,不包含缺失值,而数据集Mi中的记录均含有一个及以上的属性存在缺失值。并且数据集Ci和Mi存在以下关系:Di=Ci⋃Mi,Ci⋂Mi=∅。
Step 3.根据数据子集Mi所在类,使用式(7),对记录的缺失数据进行填充,若缺失数据为数值型数据,则使用标记类的平均值作为缺失数据的值;若缺失数据是离散型数据,则使用标记类中出现次数最多的数值作为缺失数据值。填充后数据集记为
2 实验结果
本实验的数据集采用来自UCI的STUDENT ALCOHOL CONSUMPTION Data Set数据集,该数据集具有13个属性,1 044条数据。由于STUDENT ALCOHOL CONSUMPTION数据集并不存在缺失数据,为完整数据集,其中每条记录都已经含有类标签,为了实验,将人为地制造不同比例的缺失值到数据集中,也就是选取某一属性并且将一部分实例的该属性值设为unkown,这里要指出的是,属性的选取非常关键,需要选择对实例其他属性有关联的属性。
文中采用正确率衡量算法的填充精度。实验最终,将经过算法填充的数据集与原始数据集进行比较,通过计算正确率来体现填充算法的匹配程度。正确率计算方法如下:

其中m是正确填充的属性值个数,n为原始数据集中缺失的属性值个数,P为填充算法的正确率。当P值为0时,表示所有填充的缺失值都错误;相反,当P值为1时,所有填充的缺失值都正确。
实验结果及分析:

图2 基于K-means聚类的缺失值填充算法不同k值下的精确度曲线

图3 本文算法不同h值下的精确度曲线
从图2可以看出,对于原聚类填充算法,并非值越大缺失值填充效果就越好,而且k的取值没有规律可循,当与数据集的分类吻合时,其实k验结果较好。从图3可以看出,可以看出h的取值与正确率基本成反。因为h越小表示,即聚类中心之间的距离比较小,数据的相似度也就越高,填充效果也就更好。

图4 不同算法不同缺失比例下的精确度曲线
从图4可以看出,缺失值较少的情况下,填充的精确度普遍较高,当缺失值比例40%以上的时候,精确度降低。

表1 不同填充算法最优正确率对比表
通过此表可以看出,使用基于K-means的缺失值填充算法和经过改进的基于K-means的缺失值填充算法对缺失值进行有效填充的准确度较均值填充算法有所提高,特别是经过改进的K-means的缺失值填充算法,在没有损失正确率的前提下,成功的解决K-means算法对用户k值输入的依赖,另外也避免了初始值选取的非常近而增加算法迭代循环次数影响算法效率的问题。而且可根据实际情况,调节准确度。可见,改进后的算法对缺失值填充还是十分有效的。
3 结论
文中提出了一种基于距离最大化和缺失数据聚类的填充算法。首先,对K-means聚类算法加以改进,利用数据间的最大距离确定聚类中心;其次对聚类的距离函数进行改进,使之能够对缺失数据进行聚类,在聚类的同时完成标记缺失数据所属类,简化了原填充算法步骤;最后,在填充过程中,对于离散型数据,改用标记类中出现频率最高的值填充缺失值。改进后的算法不需要提前输入聚类个数,避免了用户输入的参数对聚类结果的影响,在一定程度上也避免了聚类陷入局部最优解的局面。并且通过化简原算法步骤和增加离散型数据的处理,使得填充过程更简洁高效。实验结果表明本文提出的算法在填充正确率上高于原有的经典算法,而且该算法具有更高的运行效率。
[1]Oud J H L,Voelkle M C.Do missing values exist?Incomplete data handling in cross- national longitudinal studies by means of continuous time modeling[J].Quality&;Quantity,2014,48(6):3271-3288.
[2]方匡南,谢邦昌.基于聚类关联规则的缺失数据处理研究[J].统计研究,2011(2):87-92.
[3]Julie M D,Kannan B.Attribute reduction and missing value imputing with ANN:prediction of learning disabilities[J].NeuralComputing and Applications,2012,21(7):1757-1763.
[4]Yozgatligil C,Aslan S,Iyigun C,et al.Comparison of missing value imputation methods in time series:the case of Turkish meteorological data[J].Theoretical and Applied Climatology,2013,112(1):143-167.
[5]Juhola M,Laurikkala J.Missing values:how many can they be to preserve classification reliability[J].Artificial Intelligence Review,2013,40(3):231-245.
[6]帅平,李晓松,周晓华,等.缺失数据统计处理方法的研究进展[J].中国卫生统计,2013(1):135-139,142.
[7]金连.不完全数据中缺失值填充关键技术研究[D].哈尔滨:哈尔滨工业大学,2013.
[8]Li Z,Sharaf M A,Sitbon L,et al.A web-based approach to data imputation[J].World Wide Web,2014,17(5):873-897.
[9]黄樑昌.kNN填充算法的分析和改进研究[D].桂林:广西师范大学,2010.
[10]Gokhale M,Frigo J,Mccabe K,et al.Experience withaHybridProcessor:K-MeansClustering[J].The Journal of Supercomputing,2003,26(2):131-148.
[11]Chang G,Zhang Y,Yao D.Missing Data Imputation for Traffic Flow Based on Improved Local Least Squares[J].Tsinghua Science and Technology,2012(3):304-309.
[12]武森,冯小东,单志广.基于不完备数据聚类的缺失数据填补方法[J].计算机学报,2012(8):1726-1738.
[13]沐守宽,周伟.缺失数据处理的期望-极大化算法与马尔可夫蒙特卡洛方法[J].心理科学进展,2011(7):1083-1090.
[14]沈琳,陈千红,谭红专.缺失数据的识别与处理[J].中南大学学报,2013(12):1289-1294.
[15]杨军,赵宇,丁文兴.抽样调查中缺失数据的插补方法[J].数理统计与管理,2008(5):821-832.
[16]Zou G H,LI Ying-fu,Zhu R,et al.Imputation of Mean ofRatios for Missing Data and Its Application to PPSWR Sampling[J]. Acta Mathematica Sinica(English Series),2010(5):863-874.
猜你喜欢
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
中华养生保健(2020年7期)2020-11-16
阜阳师范大学学报(自然科学版)(2020年3期)2020-08-13
南京大学学报(数学半年刊)(2020年1期)2020-03-19
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
家教世界·创新阅读(2016年11期)2016-12-27
天津护理(2016年3期)2016-12-01
故事会(2016年15期)2016-08-23
都市丽人(2015年4期)2015-03-20
