
基于构造空间金字塔度量矩阵的图像分类算法
2018-01-23 08:40李青彦彭进业
西北大学学报(自然科学版) 2018年1期
李青彦,彭进业,李 展
(1.西北工业大学 电子信息学院, 陕西 西安 710072;2.西北大学 信息科学与技术学院, 陕西 西安 710127)
词袋(Bag of words,BOW)被广泛地应用到图像分类技术中,是图像分类技术中最有效的算法之一。就如何提高词袋算法性能,学者们提出了多种算法,如码词和描述子共现的通用模型方法[1-4],以及用于取代无监督K-means聚类的码书判别学习方法[5-8]等。尤其需要注意的是,Grauman[9]提出了金字塔匹配核函数,该方法对特征空间进行网格分割,分成不同层次,利用不同的权重组合计算SIFT特征相似性,进而对图像进行分类。鉴于金字塔匹配核函数并没有充分考虑图像特征的空间位置,Lazebnik[10]进而提出了空间金字塔匹配算法(Spatial pyramid matching,SPM)。
在实际应用中,SPM仍然存在如下问题。一方面,SPM算法使用了SIFT(Scale-invariant feature transform,SIFT)[11]算法提取图像特征。SIFT在尺度空间利用高斯差分检测算子,对特征点的梯度位置和方向都作了相应的量化, 具有平移、 尺度和旋转不变性, 是对图像局部特征的一种描述方式。 但是, SIFT算法主要针对灰度图像进行特征提取, 忽略了图像的颜色信息和光照信息。 另一方面, SPM算法使用了非线性分类器进行图像分类。 若样本数量为n, 则训练集和测试集的复杂度分别为O(n3)和O(n)。 显然, 该方法在处理大规模图像集时会消耗大量的计算机资源。 为了解决该问题, 一些研究者开始使用线性分类器取代非线性分类器来进行图像分类处理, 如ScSPM(SPM on Sparse coding)方法[14]、LLC (Locality-constrained linear coding)方法[15]、基于流形的特征词典生成算法[16]、多核学习的核矩阵方法[17]、规范割对聚类特征词方法[18]、拉普拉斯非负稀疏编码方法(LNNSC)[19],Zou等[20]提出的将图像局部特征和全局特征融合的分类算法(LGP,Local-global fusion),Peng等[20]提出的通过对图像局部特征点进行哈希编码来提高编码速度和精度算法等,这些方法均是对特征点进行聚类获得特征词典,然后应用不同方法进行特征编码,在一定程度上提高了图像分类精度。但是,这些方法都没有考虑词典单词之间的相关性,图像集内部各子类的分类效果差异较大。
针对以上两个问题,本文提出了一种基于构造空间金字塔度量矩阵的图像分类算法。其特点在于,在图像视觉单词相关性建立方面,充分考虑图像视觉单词的空间关系,建立了邻接矩阵模型,从而保证线性分类器的使用;在图像底层特征提取方面,通过对比实验,发现使用融合了颜色特征的CSIFT(Colored SIFT)[12]比SIFT具有更好的分类效果。文献[13]提出的CSIFT将颜色信息加入到了SIFT的特征集中,使得CSIFT特征同时具有颜色和尺度不变性。而且,同一图像中获得的CSIFT特征数量平均是SIFT特征数量的1.94倍。同时,文献[21]建立了基于邻接矩阵的全文索引模型,在大规模文本索引中表现优异,提高了查询效率。
本文算法步骤流程为:首先,提取融合了图像颜色特征的CSIFT特征,进而获取图像特征的聚类中心;然后,对这些中心进行有向图建模,用邻接矩阵对聚类中心进行连通度测量,建立基于邻接矩阵度量的图像词典;最后,使用线性分类器进行图像分类。由于本文提出的方法考虑到了图像词典的空间关系,同时兼顾了图像的全局颜色特征和局部位置特征,提取的特征具有颜色、旋转、位置不变性。通过在Caltech-101图像库实验验证可得,本文算法提高了分类精度,尤其对彩色自然场景的图像具有更好的分类效果。
1 基于邻接矩阵的图像不变特征词典算法
本文首先使用融合了颜色特征和空间尺度不变特性的CSIFT方法进行图像底层特征提取,然后使用K-means聚类方法,获取底层图像特征聚类中心,接着建立由底层聚类特征中心构成的n阶有向图邻接矩阵,通过将图像特征向矩阵投影,建立图像直方图,获得了图像局部特征,最后选用线性核的支持向量机进行分类。算法主要步骤如图1所示。

图1 本文算法主要步骤Fig.1 The main step of the algorithm
1.1 获取图像底层特征
从图像训练集I中提取出由M个CSIFT特征组成的集合X,每一个图像特征为D维向量,即
X=[x1,…,xM]T,X∈RM×D。
(1)
应用式(2)的K-means优化模型对特征进行特征向量量化,
(2)
其中,V=[v1,…,vK]T,代表K-means方法获得的K个聚类中心,即视觉单词词典,每个聚类中心称之为词典的单词。‖·‖表示向量的L2范数,即两个向量的欧氏距离。
用U=[u1,…,uM]T表示任一CSIFT图像特征编码结果,um为转后的图像特征,特征量化用式(3)进行计算,
(3)
其中,Card(um)=1要求um中只有一个元素是非零值;|um|=1表示um的1-范数必须是1,即um中所有元素的绝对值之和为1;um≥0要求um均为非负数。
进一步考虑到CSIFT特征的位置信息,用位置因子λ|dm·um|替换式(3)的约束条件Card(um)=1,式(3)就转化成了式(4),
(4)
(5)
特征点xi与词典V的距离为
dist(xi,V)=[dist(xi,v1),…,dist(xi,vM)]T,
(6)
σ用来调节距离的取值范围,在高斯函数中,其表示宽度参数。
1.2 邻接矩阵建模
文献[23]建立了基于邻接矩阵的全文索引模型,在大规模文本索引中表现优异,提高了查询效率。文献[14-15]改进了图像编码方法,开始运用线性分类器进行分类,取得了很好的分类效果。虽然这些方法都是将图像特征投影到多个聚类中心,但均没有考虑特征聚类中心之间的关系。本文对特征聚类中心运用邻接矩阵进行建模,获得了视觉词典的相似度矩阵,然后再进行空间金字塔匹配。与文献[14-15]相比较,本文的方法考虑了图像字典中基元素之间的关联度。
1.2.1 邻接矩阵 数据结构中,图分为有向图和无向图两种,本文主要讨论有向图的邻接矩阵。
有向图D=〈V,E〉,其中,V={v1,v2,…,vn}代表图的顶点,E代表各顶点的关系。邻接矩阵Al表示D中长度为l的通路数,
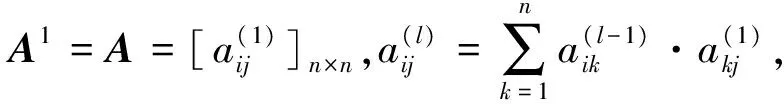
即
Al=Al-1·A。
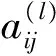
1.2.2 构建图像特征词典的邻接矩阵 构造有向图D=〈V,T〉,其中,词典V={v1,v2,…,vn},T为n个向量之间的相似度矩阵,则有
(7)
其中,tij为向量vi到vj的相似度。
向量之间的相似度可以通过求解它们之间的距离来获得。同时,为了使得相似的特征在编码过程中有更大的权重,并使得矩阵T为稀疏矩阵,只求解vi与其k个最小近邻的距离,其余均为0,即
tij=
(8)
其中,σ为高斯函数中的宽度参数,用来调节vi与vj距离的取值范围,σ越大,函数越平滑,特征之间的差异性也就会越小。
式(8)表明,当两个特征完全相同时,他们之间的相似度为1,完全不同时相似度为0。
令T(1)=T,我们称T(1)为V的一阶相似度矩阵。邻接矩阵T(t)=T(t-1)T(1),T(t)就是V的t阶相似度矩阵。
然后,对xi进行初始化,
yij=
(9)
其中,与文献[24]的要求一样,λ是归一化因子,用来保证yi内各元素之和为1。
转化后的图像特征结果ui表示为
(10)
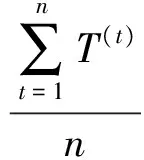
这样,图像的CSIFT特征最终转化成了ui。然后,将图像特征进行高分辨率的空间金字塔组合,最后得到表示图像整体特征的向量。
由于随着t值的增大,T(t)将不再稀疏,所以U也不是稀疏矩阵,这将给计算机带来很大的开销,尤其是对于大规模图像集,严重降低了计算机的运算性能。因此,在具体实验中对ui设置一个阈值e。由于小于这个阈值的元素对结果将产生非常小的影响,所以本文将其全部置为0,以保证U是稀疏矩阵。
2 实 验
2.1 实验概述
本文实验所用计算机的配置为:CPU Corei5-3470双核,主频3.2GHz,内存4GB,显存2GB。实验所用图像集为Caltech-101。Caltech-101图像集有101类共计9 144幅图像,每类图像有40~800幅图像,每幅图像的尺寸大约为300×200像素。从每类中随机选取10,15,25,30个训练样本,其余作为测试样本,同时为了保证实验的稳定性,每次实验重复进行10次,取平均值和方差作为实验的结果。
首先,把图像分成16×16像素大小的图像块,图像块之间间隙为6个像素,使用 CSIFT 特征提取算法,将每个图像块进行向量量化。然后,利用K-means聚类获得初始词典,随后利用本文提出的邻接矩阵模型对图像特征进行转化,获取每个图像特征描述子um。接着,计算不同尺度空间的图像特征,实验中将图像空间金字塔层级定为3层,即l=[0,1,2],这样每一个图像特征被空间金字塔方法转化成了一个M维的向量U。
接着构造一个pooling函数:z=F(U)。这个函数对U的每一列进行计算,其每一列反映出了所有特征点与词典中单词的关系,本实验采用了最大值函数,
zj=max{|u1j|,|u2j|,…,|uMj|}。
其中,uij是U的第i行j列的值,zj则是z的第j个元素。
2.2 实验结果
邻接矩阵阶次n的取值与最终精度影响如图2所示。其中,最小近邻K=5,高斯核函数宽度参数σ=1,稀疏化参数e=0.01。从图2可以看出,当邻接矩阵阶次n≤3时,分辨精度随着n的增长而提高,n>3后,分类精度并没有明显的提升。
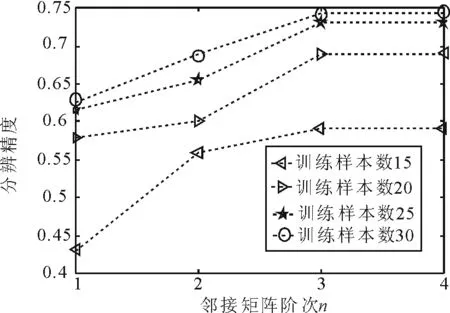
图2 不同的邻接矩阵阶次n的取值对最终分辨精度的影响Fig.2 The effect of the order n elements value in the adjacency matrix on the final classification accuracy
本文对每类图像分别随机选取20幅和30幅训练图像,与其他分类方法进行比较。实验发现,将经过邻接矩阵优化过的词典矩阵分别用于哈希编码[22]和LLC方法,使用了基于邻接矩阵的图像词典算法的分类精度获得一定程度的提高,当最小近邻K=5,邻接矩阵阶次n=3,高斯核函数宽度参数=1,稀疏化参数e=0.01时,本文算法与其他算法相比,分类精度如表1所示。
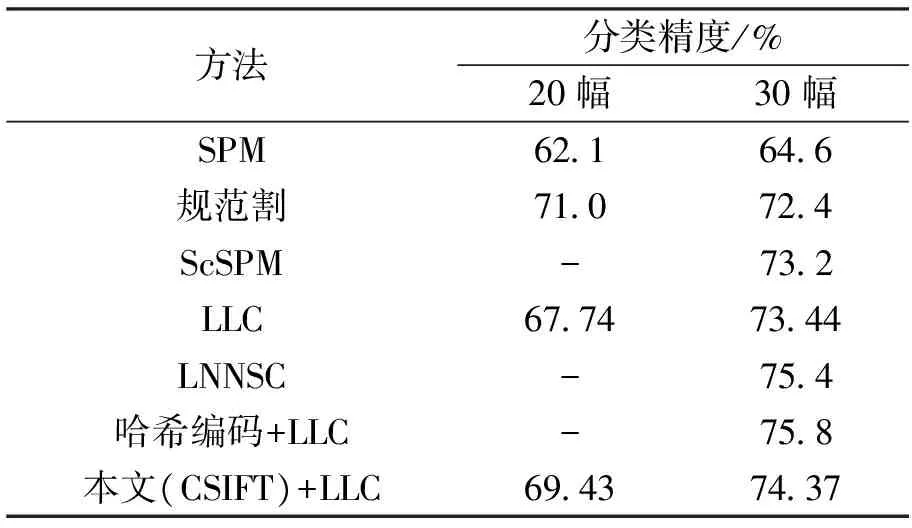
表1 本文与其他算法的分类精度对比Tab.1 Comparison of classification accuracy
本文的方法对于自然界中正常存在的图像具有更好的分类效果。图3列出了本文实验所用的6种图像,分别为水莲、停止标示、比萨、羚羊、宝塔、金字塔。表2展示了本文与LLC方法在部分图像类上的分类效果。水莲、停止标示、比萨和羚羊4类图像均为自然界中存在的彩色图像,其分类效果好于LLC方法,CSIFT算子优于SIFT算子。在宝塔图像集上,使用SIFT算子的邻接矩阵分类方法和LLC方法的分类效果相同,使用了CSIFT算子后,由于增加了颜色和光照信息,分类效果有了明显提升。对于含有电脑模拟或后期进行过再处理的图像集(如图3(f)金字塔),因为其包含了非自然界中正常存在的图像,本文的分类效果稍差。

图3 实验用到的部分图像示例Fig.3 Some image examples used in the experiment
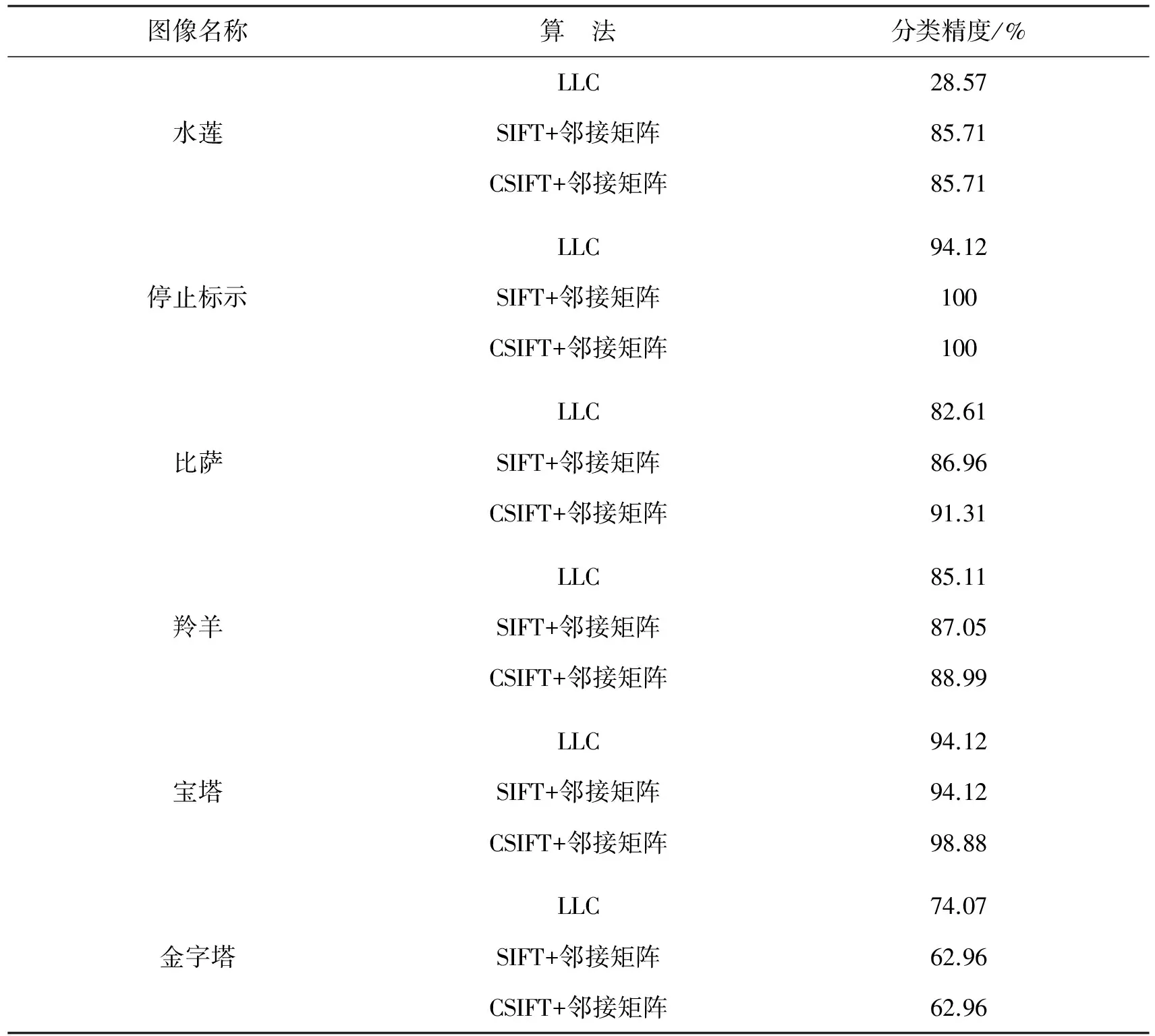
图像名称算 法分类精度/%LLC28.57水莲SIFT+邻接矩阵85.71CSIFT+邻接矩阵85.71LLC94.12停止标示SIFT+邻接矩阵100CSIFT+邻接矩阵100LLC82.61比萨SIFT+邻接矩阵86.96CSIFT+邻接矩阵91.31LLC85.11羚羊SIFT+邻接矩阵87.05CSIFT+邻接矩阵88.99LLC94.12宝塔SIFT+邻接矩阵94.12CSIFT+邻接矩阵98.88LLC74.07金字塔SIFT+邻接矩阵62.96CSIFT+邻接矩阵62.96
2.3 实验相关参数取值对结果的影响
在邻接矩阵模型中,参数取值涉及到训练样本数目、最小近邻取值K、邻接矩阵阶次n、高斯核函数宽度参数σ和稀疏化参数e。
第二,教育者在对大学生进行思想政治教育的过程中,要积极推动思想政治工作传统优势同信息技术高度融合,拓宽社会主义核心价值观教育的深度和广度,让社会主义核心价值观内化于心,外化于行。并将优秀健康的价值观及思想观念的良好引导作用渗透到学生的日常生活及学习中,引导学生树立正确的世界观、人生观、价值观,做到以文化人。
实验中,首先固定训练样本数目不变,然后变换其他参数,其中,最小近邻K={3,5,7},邻接矩阵阶次n={1,2,3,4},高斯核函数宽度参数σ的取值{2,1,0.1,0.01},稀疏化参数e取值为{0.1,0.01,0.001}。各参数对实验结果的影响情况为:
1)宽度参数σ太大或太小,分类精度都会降低。这是因为太大的宽度参数σ使得高斯函数变得平滑,相应特征之间的相似度度量取值趋向于1,同时如果宽度参数σ太小,则使得每个特征点变得孤立,与其他特征点的相似度趋近于0,使得算法还原成了没有进行邻接矩阵建模的情况,从而使本文算法失去了意义。
2)最小近邻K取值越大,特征点与其他特征点的关联度保留的越多。对于显著特征相关性较强的图像有更加强的分类能力,但同时会降低特征背景差异较大的图像的分类能力。
3)邻接矩阵阶次n的取值越大,图像特征点的相关性越强,算法对显著特征相关性较强的图像有更加强的分类能力,同时,其受稀疏化参数e的约束较为明显。若稀疏化参数e取值越小,则邻接矩阵阶次n的取值对分类结果的影响越显著,与此同时,矩阵稀疏化程度降低,运算消耗增加。
表3 CSIFT与SIFT特征提取时间平均消耗

Tab.3 The average cputime of extract features using CSIFT and SIFT ms
3 结 语
本文考虑了词典中显著特征之间的关系,利用邻接矩阵的思想建立了词典相似度矩阵。实验证明,本文提出的方法应用在对图像局部特征的各类改进算法中,能够起到优化图像词典的作用;同时,本方法对图像语义关联紧密的图像具有更高的分类精度,当使用了融合颜色和光照信息的底层特征CSIFT算子后,在自然界彩色图像分类方面表现更为突出。但同时也看到,随着图像类型的增加,维度灾难始终存在。实验中,各参数的取值根据实验经验来寻找最优,并不能确保选取的参数为最优参数。如何将更多的图像特征融合,并应用到图像分类中,提高图像分类精度,将是下一步研究的重点。
[1] BOIMAN O, SHECHTMAN E, IRANI M. In defense of Nearest-Neighbor based image classification[C]∥ IEEE Conference on Computer Vision and Pattern Recognition.IEEE, 2008:1-8.
[2] BOSCH A, ZISSERMAN A, MUOZ X. Scene classification using a hybrid generative/discriminative approach[J].IEEE Transactions on Pattern Analysis & Machine Intelligence, 2008, 30(4):712.
[3] LI F F,PERONA P. A Bayesian hierarchical model for learning natural scene categories[C]∥IEEE Computer Society Conference on Computer Vision and Pattern Recognition. IEEE Computer Society,2005:524-531.
[4] QUELHAS P, MONAY F, ODOBEZ J M, et al. Modeling scenes with local descriptors and latent aspects[C]∥Tenth IEEE International Conference on Computer Vision. IEEE, 2005:883-890.
[5] YANG L,JIN R,SUKTHANKAR R, et al. Unifying discriminative visual codebook generation with classifier training for object category recognition[C]∥IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2008: 1-8.
[6] ELAD M,AHARON M. Image denoising via sparse and redundant representations over learned dictionaries[J].IEEE Transactions on Image Processing,2006,15(12): 3736-3745.
[7] MOOSMAN F,TRIGGS B,JURIE F. Randomized clustering forests for building fast and discriminative visual vocabularies[J].Advances in Neural Information Processing Systems,2006.
[8] FREDERIC J,TRIGGS B. Creating efficient codebooks for visual recognition[C]∥Tenth IEEE International Conference on Computer Vision. IEEE, 2005: 604-610.
[9] GRAUMAN K,DARRELL T. The pyramid match kernel: discriminative classification with sets of image features[C]∥Tenth IEEE International Conference on Computer Vision. IEEE, 2005: 1458-1465.
[10] LAZEBNIK S,SCHMID C,PONCE J. Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories[C]∥IEEE Computer Society Conference on Computer Vision and Pattern Recognition. IEEE Computer Society , 2006: 2169-2178.
[11] LOWE D G. Object recognition from local scale-invariant features[C]∥The Proceedings of the Seventh IEEE International Conference on Computer Vision. IEEE,1999: 1150-1157.
[12] ABDELHAKIM A E, FARAG A A. CSIFT: A SIFT descriptor with color invariant characteristics[C]∥IEEE Computer Society Conference on Computer Vision and Pattern Recognition. IEEE, 2006: 1978-1983.
[13] GEUSEBROEK J M, BOOMGAARD R V D, SMEULDERS A W M, et al. Color invariance[J].IEEE Transactions on Pattern Analysis & Machine Intelligence, 2001, 23(12):1338-1350.
[14] YANG J,YU K,GONG Y,HUANG T. Linear spatial pyramid matching using sparse coding for image classification[C]∥IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2009: 1794-1801.
[15] WANG J,YANG J,YU K,et al. Locality-constrained Linear coding for image classification[C]∥IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2010: 3360-3367.
[16] 章毓晋, 刘宝弟,王宇雄, 图像分类中多流形上的词典学习[J].清华大学学报(自然科学版), 2012,52(04): 575-579.
[17] 亓晓振,王庆.一种基于稀疏编码的多核学习图像分类方法[J].电子学报, 2012,40(4): 773-779.
[18] 丁锴,陈伟海,吴星明,等.基于规范割的空间金字塔图像分类算法[J].北京航空航天大学学报, 2013,39(10): 1342-1347.
[19] LI Qianqian,CAO Guo. Image classification based on laplacian non-negative sparse coding[J].Computer Engineering, 2013,39(11):240-244.
[20] ZOU J,LI W,CHEN C,DU Q. Scene classification using local and global features with collaborative representation fusion[J].Information Sciences, 2016,348:209-226.
[21] LINDE Y,BUZO A,GRAY R. An Algorithm for Vector Quantizer Design[J].IEEE Transactions on Communications, 1980, 28(1):84-95.
[22] PENG T, LI F. Image classification algorithm based on hash codes and space pyramid[J].Journal of Image & Graphics, 2016:114-118.
[23] 周水庚, 胡运发,关佶红.基于邻接矩阵的全文索引模型[J].软件学报, 2002,13(10): 1933-1942.
[24] LIU L,WANG L,LIU X.In defense of soft-assignment coding[C]∥IEEE International Conference on Computer Vision. IEEE, 2011:2486-2493.
猜你喜欢
长春师范大学学报(2022年12期)2023-01-13
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
铁道通信信号(2019年6期)2019-10-08
英语文摘(2019年5期)2019-07-13
雷达学报(2017年6期)2017-03-26
网络空间安全(2016年3期)2016-06-15
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
电脑知识与技术(2015年17期)2015-09-11
