
基于GMDH混合模型的能源消费量预测研究
2018-01-25 00:54孙海燕刘敦虎曹瀚文汪寿阳
中国管理科学 2017年12期
肖 进,孙海燕,刘敦虎,曹瀚文,汪寿阳
(1. 四川大学商学院,四川 成都 610064;2. 成都信息工程学院管理学院,四川 成都 610225;3. 中国科学院数学与系统科学研究院,北京 100190)
1 引言
随着改革开放的发展,我国的能源消费呈现出逐年增长的势头,1978年至2013年,我国的能源消费总量由57144万吨标准煤增加至375000万吨标准煤,增长了6.56倍,其中,石油的年均增长率为12.34%[1]。近二十年来,如何科学预测能源消费一直是各国学者研究的热点问题[2]。能源是影响社会发展和国民经济的重要因素,随着我国工业化水平和城市化进程的进一步提高,能源将处于越来越重要的战略地位[3]。因此,准确的预测能源消费对我国能源行业的发展以及国家能源战略的制定有着重要的现实意义[4]。
20世纪70年代以来,国内外众多学者对能源消费预测进行了深入的研究,提出了许多预测方法[5]。这些方法大致可以分为两类:第一类,时间序列分析模型,包括自回归求积移动平均(Autoregressive Integrated Moving Average,ARIMA)模型[6]和灰色预测模型[7, 8]等。例如,Erdogdu[9]利用ARIMA模型对电力需求进行了分析。第二类,非线性预测模型。时间序列模型大多基于线性假设,不能很好地刻画原始数据中非线性的特征,在复杂度较高的非线性时间序列中预测效果不佳。常用的非线性模型有:1)人工神经网络(Artificial Neural Network,ANN)模型[10],包括反向传播(Back Propagation,BP)神经网络[11]和径向基函数(Radial Basis Function,RBF)神经网络[12-14]。这类模型运用灵活,估计合理,预测精度较高,同时也能处理数据中的噪声,因而得到广泛应用。例如,胡雪棉和赵国浩[11]运用BP神经网络预测煤炭需求;彭建良等[14]运用RBF神经网络预测我国的能源消费量。人工神经网络模型虽然有很好的范化能力,但是其包含许多参数,这些参数的最优取值往往很难确定。2)支持向量回归(Support Vector Regression, SVR)模型[15-16],它通过非线性变换将低维非线性问题转换到高维特征空间,然后在高维空间中构造线性决策函数实现线性回归。如Kavaklioglu[17]利用SVR模型对土耳其的电力消费进行预测并取得了较好的预测效果。SVR模型巧妙地解决了维数问题,并保证了较好的推广能力,但它的参数最优取值往往需要借助其他方法如遗传算法进行优化[18],而遗传算法又包含很多参数,因此增加了模型参数选择的复杂度。3)遗传规划(Genetic Programming, GP)模型[19],它随机产生一个适应于问题的初始群体,依据自然选择原理,通过复制、交叉和变异实现群体进化,找到问题的最优解或近似最优解。Lee等[20]运用GP模型预测长期电力需求取得了较为满意的预测结果。GP模型以生物进化为原型,具有强大的启发式寻优能力,适用性强、鲁棒性高,但仍然存在模型参数较多,计算量较大等不足。
由于经济时间序列通常具有复杂性的特点,单一的线性或者非线性模型模型往往不能准确地对能源需求进行预测分析,因此,一些学者使用混合预测模型来解决这一问题,该类模型通常先将能源需求时间序列分解为若干线性或者非线性子序列,然后分别对它们进行建模预测,最后将这些子序列的预测结果进行综合。例如Wang等[21]为了预测水电消耗量,提出了一种基于季节分解的集成预测模型,该模型首先使用季节分解方法将水电消耗量原始时间序列分解为周期趋势、季节成分以及不规则部分三个子序列,然后分别使用线性最小二乘支持向量回归模型来建模预测,最后将3个模型的预测结果进行整合。
上述研究都取得了比较满意的效果,但仔细分析发现这些研究在对非线性子序列进行预测时,都使用的单一的预测模型。事实上,由于对非线性时间序列的预测难度较大,单一的模型往往很难取得令人满意的预测性能。相反,如果能同时建立多个非线性预测模型,再将这些模型的预测结果进行组合,即组合预测,将可望提高预测性能。同时,参与组合的多个非线性基本预测模型的预测结果往往存在很高的多重共线性,如果将全部基本预测模型的预测结果进行组合,将可能产生重大的预测偏差。为了解决这一问题,数据分组处理(Group Method of Data Handling, GMDH)[22]技术无疑为我们提供了一种有力的工具。GMDH是自组织数据挖掘的核心技术,它能从一系列与对研究对象(因变量)可能存在影响的特征(自变量)中自组织地选择一部分关键特征,并确定模型的结构和参数。因此,我们可以运用GMDH技术从多个非线性预测模型中选择一部分进行组合,即选择性组合预测,从而进一步提高模型的预测性能。
本研究将GMDH引入到能源消费预测中,构建了基于GMDH的混合预测模型(GMDH Based Hybrid Forecasting Model, GHFM)。该模型首先使用基于GMDH的自回归(GMDH Based on Auto Regressive, GAR)模型来对原始能源消费序列建模预测,将原始序列分解为线性和非线性两个子序列,同时得到线性子序列的预测结果,进一步,在非线性子序列上,分别建立BP模型、SVR模型、GP模型和RBF模型,在此基础上建立基于GMDH的选择性组合预测模型,得到非线性子序列的组合预测结果。最后,将两部分的预测结果整合即可得到总的能源消费量预测值。实证分析结果表明,与已有的一些预测模型相比,GHFM模型能取得更好的预测效果。
2 相关理论
2.1 GMDH神经网络
GMDH神经网络最早是由Ivakhnenko[22]于1971年提出的,它是自组织数据挖掘的核心技术,能够自组织地确定进入模型的变量、结构和参数。近年来,GMDH神经网络已经被广泛应用于工程、科学以及经济研究等多个领域[23-28]。
GMDH以参考函数的形式建立输入输出变量之间的一般关系。一般取K-G多项式的离散形式作为参考函数:
(1)
这里,输出记为y,输入向量记为X=(x1,x2,…),a是系数或权值向量。特别地,包含n个变量的一阶线性K-G多项式的形式可以表示如下:
f(x1,x2,…,xn) =a1x1+a2x2+…+anxn
(2)
并以它的所有子项作为建模网络结构中的n个初始模型:
v1=a1x1,v2=a2x2,…,vn=anxn.
(3)
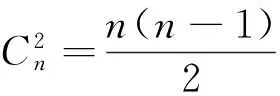
w=f(vi,vj);i,j=1,2,...,n;i≠j
(4)
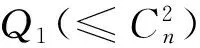
z=f(wi,wj);i,j=1,2,...,Q1;i≠j
(5)
如此不断循环下去,依次可以得到3, 4, … ,L层的中间候选模型。终止运算的规则是由最优复杂度原理[29]给出的:随着中间候选模型复杂度的增加,外准则值会呈现先减小后增大的变化趋势,因此当外准则值达到最小时,相应的模型即为最优复杂度模型y*(见图1)。

图1 GMDH模型寻找最优复杂度模型y*的过程
2.2 基于GMDH的自回归模型
前期我们将GMDH与传统的自回归模型相结合,构造了基于GMDH的自回归模型( GMDH based on Auto-Regressive, GAR)[30]。作为一种计量经济模型,ARIMA(p,d,q)模型在建模过程中需要对时间序列进行单位根检验,以便确定被检验序列是否稳定;同时,为了找到最优的自回归滞后阶数p和移动平均项滞后阶数q的值,建模者需要反复尝试。而GAR模型是在传统的计量经济学模型ARIMA的基础上发展起来的,它在建模时不需要太多的先验知识和理论假设。它能够自组织地找到最优复杂度模型,自动确定进入模型的自回归阶数,并得到模型参数,大大降低了人为因素的干扰。
3 基于GMDH的混合预测模型
3.1 基本思想
本文提出的基于GMDH的混合预测模型GFHM与其他模型比较存在两点不同:第一,无须考虑能源需求的任何影响因素,模型的建立仅依赖于原始能源消费时间序列;第二,在对非线性时间序列进行选择性组合预测时,利用GMDH的自动建模机制,能够自组织地从参与组合的全部预测模型中选择出一部分模型进行组合,并确定组合的权重,从而尽可能的避免了人为因素的干扰。
3.2 外准则的构建
在实际系统建模时,会提出不同的要求,这些要求或者是建模的目的,或者是对系统先验知识的认识。在自组织数据挖掘中,外准则是这些特定要求的数学描述,它能从简单的候选模型类中选出“最优的”模型。GMDH有一个外准则体系[29],可以根据不同的建模目的从中选择不同的外准则,还可以根据需要构造新的外准则。在本研究中,我们选择非对称最小偏差(Asymmetric and Minimum Error, AME)准则,其定义如下:
(6)

表1 非线性子序列时间序列转换矩阵
3.3 建模步骤
本研究提出的混合预测模型GHFM的建模流程如图2所示。具体包括以下三个建模步骤:
(1)建立GAR模型预测序列的线性趋势
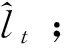
(2)产生非线性子序列并训练基本预测模型
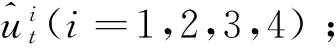
(3)使用GMDH对非线性子序列进行组合预测,进一步得到最终预测结果
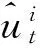
②建立因变量(输出)和自变量(输入)之间的一般关系,作为“参考函数”:
(7)
并以它的所有子项作为建模网络结构中的初始模型(见图1(a)):
(8)
④选择非对称最小偏差(AME)准则作为非线性子序列预测模型的外准则,计算所有中间候选模型的外准则值;
⑤从第一层中间候选模型中选择外准则值最小的4个中间候选模型进入下一层,作为GMDH网络结构第二层的输入变量;
⑥重复步骤c-e,可依次产生第2, 3, …, L层中间候选模型,最终根据最优复杂度原理找到最优复杂度组合预测模型y*,算法停止;
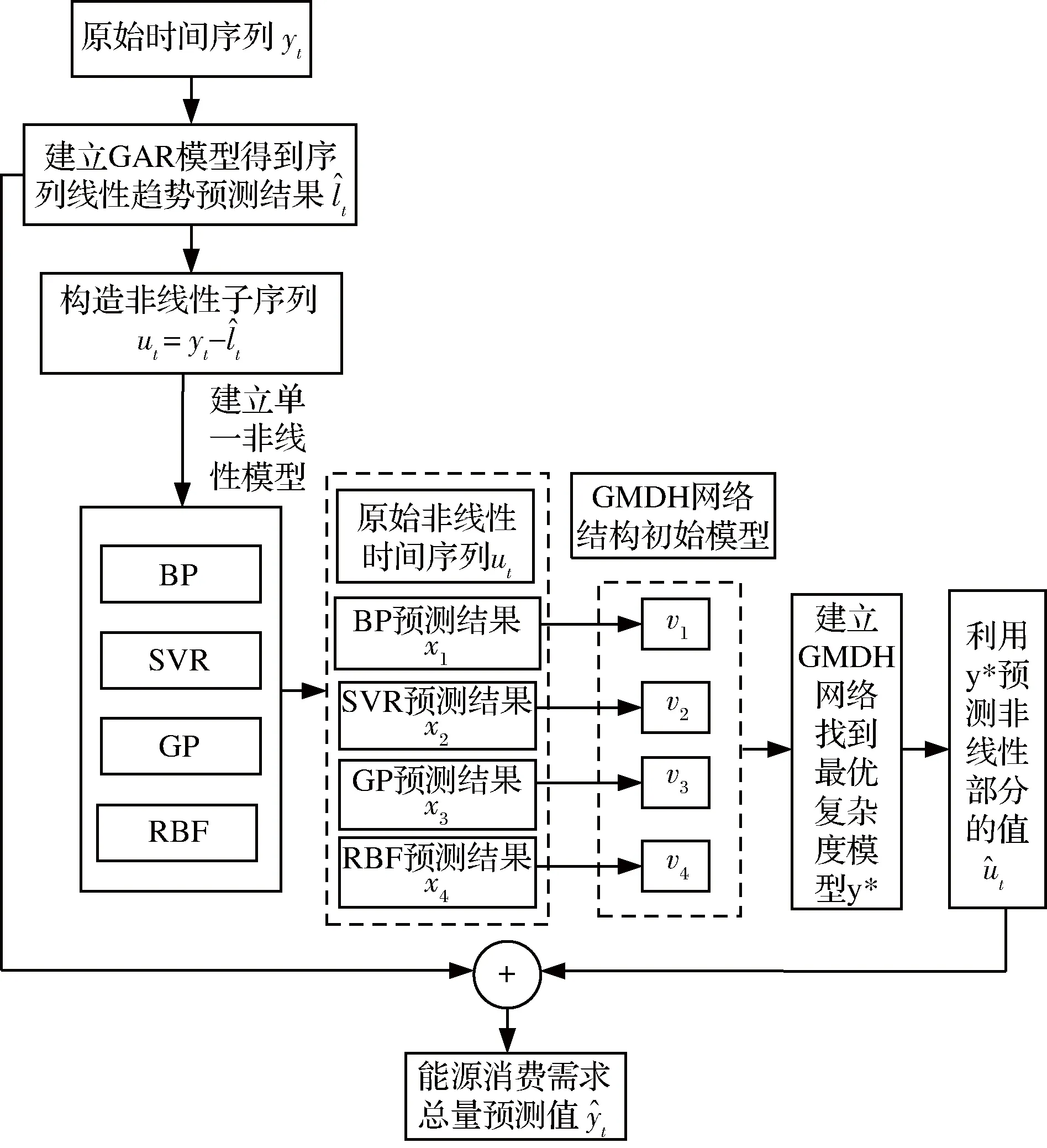
图2 基于GMDH的混合模型GHFM建模流程图
4 实证分析
本研究将构建的基于GMDH的混合预测模型GHFM用于预测能源消费总量时间序列和石油消费量时间序列。并将预测结果与其他混合模型进行比较,最后在两个时间序列上分别进行样本外预测。
4.1 数据来源及实验设置
本研究建模所需数据来自《中国统计年年鉴2014能源统计数据》,数据样本为1978年至2013年的能源消费总量和石油消费量各36年的年度数据,能源消费量的单位为万吨标准煤。
选取1978-2008年的能源消费数据作为训练集、2009-2013年的数据作为测试集。本文所涉及的各模型均在训练集上训练相应的模型,在测试集上评价各模型的性能。
对于用来预测能源消费时间序列线性趋势的GAR模型,其可能包含的最大滞后(自回归)阶数k是一个重要参数。本研究通过实验发现,k的取值并不是越大越好,当k=4时,GAR模型已经能达到比较满意的性能,而当其值进一步增加时,模型的预测性能并未再有显著性提高,因此,在后续的所有比较中,我们设定最大滞后阶数k为4。
对于用来预测能源消费时间序列非线性子序列的各个预测模型,其参数设置如下:1)BP神经网络模型,在构建模型来预测能源消费量时,其用于训练模型的训练集中包含的最大滞后(自回归)阶数k以及其隐层节点d个数是两个非常重要的参数。在本研究中,通过反复实验,我们发现在能源消费总量时间序列上当滞后阶数k取1,而隐层节点d取3;在石油消费量时间序列上当滞后阶数k取3,而隐层节点d取3时,BP神经网络模型能够得到比较满意的预测效果。2)SVR模型,我们选用了faruto编写的Matlab SVM算法工具箱,选取1978-2008年最大滞后k期的能源消费量时间序列作为输入,对应的当期能源消费量作为输出,经反复试算,确定当滞后阶数k的取值分别为3和1时,能达到最理想的预测结果。3)GP模型,在GP的建模过程中,模型的各参数设置对模型性能的影响至关重要。经反复尝试,在能源消费总量时间序列序列上,分别设置初始树为50,交叉概率为0.8,拟合优度阈值为0.85,最大迭代次数为50;在石油消费量时间序列序列上,分别设置初始树为50,交叉概率为0.8,拟合优度阈值为0.8,最大迭代次数为50时,GP模型可以分别取得最理想的预测效果。4)RBF神经网络,径向基函数扩展速度spread是一个很重要的参数,若spread过小,则需许多神经元来适应函数的缓慢变化,若spread过大,同样也需许多神经元来适应函数的快速变化,这两种情况都会导致设计网络的性能不佳。另外,模型的滞后阶数k也非常重要,在本实验中,通过多次试算,得知在两个时间序列上分别取spread为3、1.5,取k为1、5时,RBF模型的预测性能最佳。
对非线性子序列各模型进行组合的GMDH组合模型,将各单一非线性模型的预测结果作为组合模型的输入,选出的基准模型和非线性的组合预测结果作为输出,设置测试区间的长度为5.
对于用于比较的ARIMA模型,首先运用ADF单位根检验对序列的平稳性进行检验,ADF 检验结果表明原序列都在二阶差分后平稳,即d= 2,然后使用Eviews8.0软件对能源消费时间序列做自相关系数和偏自相关系数分析,得自回归参数p1= 5、p2= 1移动平均参数q1= 2,q2= 6. ARIMA(5,2,2) 模型和ARIMA(1,2,6)模型的残差序列是白噪声序列,检验效果较好。
本文所涉及的各模型中,ARIMA模型的建模过程是使用Eviews8.0 软件来实现的,而对于另外的几种模型,我们都是在Matlab2011b平台上编程实现,同时对于每一个实验数据,都是重复运行10次,取10次实验的平均值。
4.2 模型性能评价指标选择
本研究共选用了三种不同的模型性能评价指标,即均方根误差(RMSE)、绝对平均百分比误差(MAPE)和相对平方根误差(RRSE):
(9)
(10)
(11)
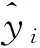
4.3 线性预测与其它模型的比较
在本小节,我们构建了GAR模型对能源需求时间序列的线性部分进行预测。并将预测结果与常用的线性预测模型ARIMA进行比较,旨在找出两者在挑选最优滞后阶数上的不同之处,并对它们的预测效果进行分析比较。表2给出了GAR模型与ARIMA模型在测试集上预测误差RMSE、MAPE和RRSE的比较结果。
由表2可知,在两个时间序列上,GAR模型的三个评价指标均要优于ARIMA模型。因此,我们可以得出结论,与ARIMA模型相比,GAR模型对能源消费时间序列线性趋势的预测效果更好。此外,表2中每个评价指标比较的第三列还给出了两个模型预测误差的差值,这个值说明了GAR与ARIMA模型在测试集上预测性能的差异程度,差值越大则GAR模型的性能较ARIMA模型越好。无论是模型评价指标的比较还是预测误差差值的比较都说明GAR模型的预测性能明显优于传统的ARIMA模型。

表2 GAR模型与ARIMA模型预测误差的比较
4.4 非线性组合预测和其它模型的比较
对于能源需求时间序列非线性子序列的预测,我们将基于GMDH的选择性组合预测模型与其它四种单一的非线性模型进行比较。表3给出了各模型在非线性子序列上的预测误差。表中加粗的数值对应为该行误差最小的值。表中的平均排名是在每一个时间序列上,计算每一种模型三个评价指标上的排序的平均值得到的。排序越小,表示对应模型的预测性能越高。
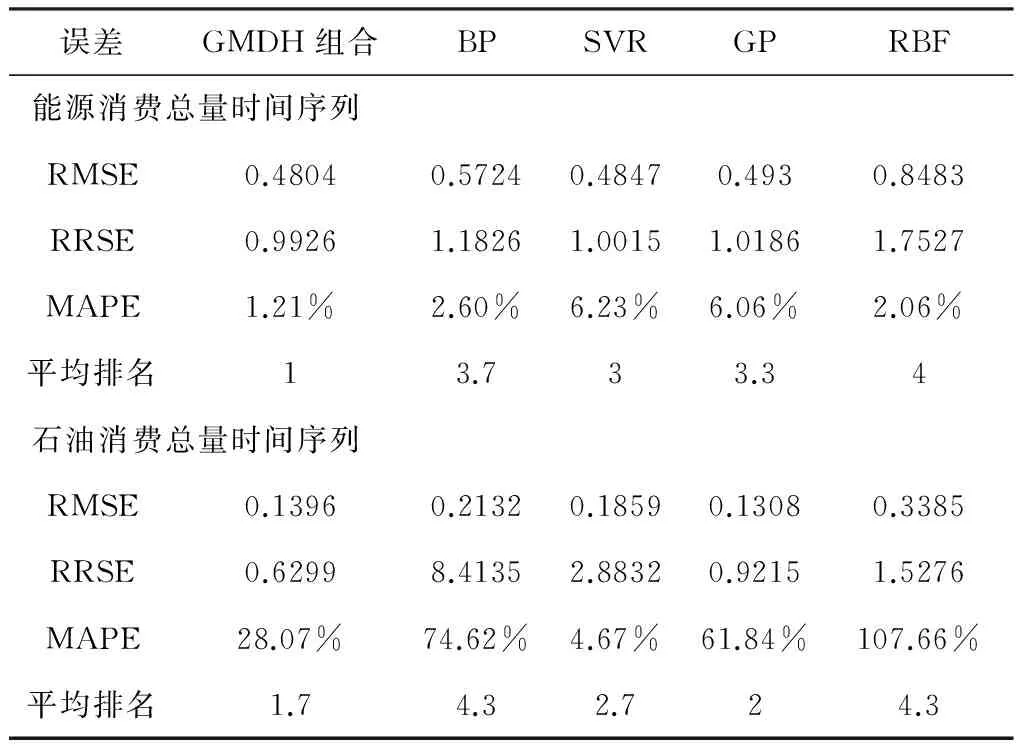
表3 非线性子序列各模型预测误差比较
由表3可知,在能源消费总量时间序列上,GMDH组合模型的三个误差值均最小,表明基于GMDH的选择性组合模型在能源消费总量的非线性时间序列上具有最好的预测性能。在石油消费总量的非线性子序列上,GMDH组合模型虽然只取得了最小的RRSE误差值,但是它的预测误差的平均排名是最小的,表明基于GMDH的选择性组合模型仍然具有最好的预测性能。由此我们可以得出结论,基于GMDH的选择性组合模型在非线性子序列上的整体预测性能要优于4种单一预测模型。
进一步分析发现,GMDH选择性组合预测模型在能源消费总量时间序列上,选取了基准模型中的BP、SVR和RBF模型进行组合。而在石油消费总量时间序列上,只选取了SVR和GP模型进行组合。这也表明,GMDH选择性组合预测模型通过自组织建模技术选出的关键模型既不仅仅是单个模型,也不是全部基准模型,从而可以有效的弥补单一模型信息不足和组合全部基本模型可能带来信息冗余的缺点,从而提高模型的预测性能。
4.5 混合模型与其它模型的比较
为了验证GHFM混合预测模型的整体预测性能的好坏,本研究还比较了它与其他混合模型在测试集上的预测误差,表4和表5给出了具体的比较。表中,第二列表示的是线性趋势用GAR预测、非线性趋势用GMDH选择性组合预测的模型;第三至最后一列表示的是线性趋势用GAR预测,非线性趋势分别用BP、SVR、GP和RBF预测的混合模型。表中加粗的数值对应为该行误差最小的值。
由表4和5的比较可得出以下几个结论:1)表中三个最小的误差值均由模型GHFM取得,表明该模型的性能明显优于其它混合预测模型;2)由于其他混合模型同样使用GAR模型来预测线性趋势,说明模型GHFM最小预测误差的取得得益于非线性部分的GMDH选择性组合预测;3)使用GMDH对非线性子序列进行选择性组合预测即能够充分综合各模型的优点又能有效避免多重共线性。

表4 GHFM模型与其他混合模型在能源消费总量时间序列上预测性能的比较

表5 GHFM模型与其他混合模型在石油消费量时间序列上预测性能的比较
4.6 混合模型样本外预测
基于以上分析和比较可知,GHFM模型能较准确的拟合数据间的关系及变化。表6是GHFM模型2014-2020年的样本外预测结果。

表6 GHFM模型2015-2020年外推预测
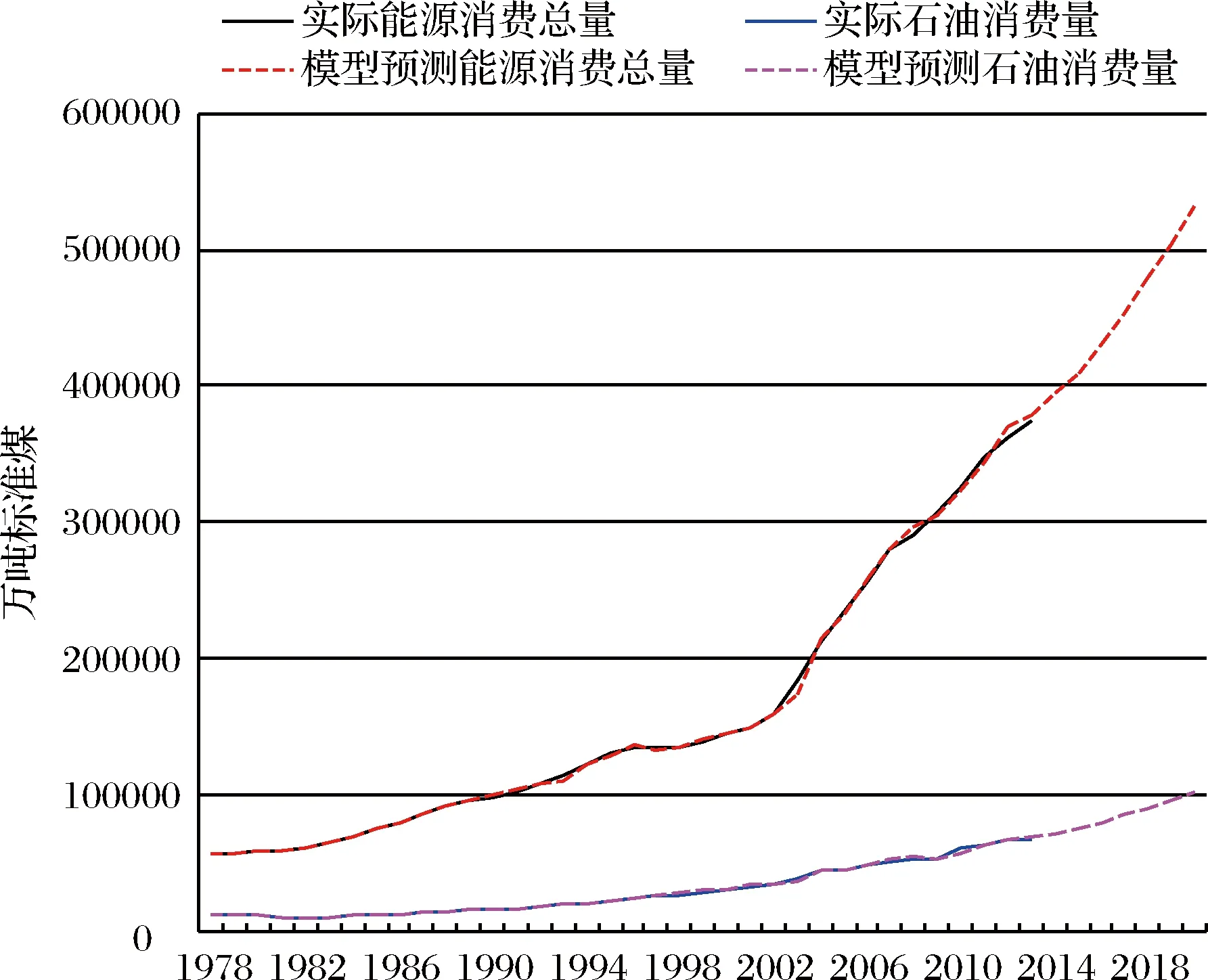
图3 能源消费量预测值趋势以及与真实值的比较
由表6可知,2014-2020年我国的能源消费量会仍保持持续上涨的势头,至2020年能源消费总量和石油消费量将分别达到532078万吨标准煤和102890万吨标准煤。2014-2020年的能源消费总量年均增长率为5.01%,其中,石油的消费年均增长率为5.88%. 图3描绘了能源消费量预测结果的趋势以及与真实值的比较,红色和粉色虚线分别表示GHFM模型估计出的能源消费总量和石油消费量,黑色和蓝色实线表示实际能源消费总量和实际石油消费量,图中1978-2013年的虚线与实线几乎完全重合,2014年以后虚线保持着增长的趋势,进一步说明了GHFM模型可以较好的拟合能源消费时间序列的发展。
5 结语
本文利用GMDH技术研究了能源消费量预测的问题,提出了基于GMDH的混合预测模型GHFM,并利用2个能源消费时间序列进行实证。实证结果表明,基于GMDH的混合预测模型相比传统的能源消费预测模型具有更好的预测效果。说明将GMDH方法应用于能源需求预测是可行且有效的。
虽然对能源消费量时间序列非线性趋势的预测采用组合模型取得的预测效果要明显优于单一模型,但每种模型都会存在不足之处。如果能采用集成预测,如Boosting方法来提升单一非线性模型的性能,将有望进一步提高模型的预测效果。因此,下一步研究将使用集成模型,构建基于GMDH的集成预测模型。
[1] Zhu Z X. China statistical yearbook[M]. Beijing: China Statistics Press,2013.
[2] Ahmad A, Hassan M Y, Abdullah M P, et al. A review on applications of ANN and SVM for building electrical energy consumption forecasting[J]. Renewable and Sustainable Energy Reviews, 2014, 33(5): 102-109.
[3] Yu Shiwei, Wei Yiming, Wang Ke. China’s primary energy demands in 2020: Predictions from an MPSO-RBF estimation model[J]. Energy Conversion and Management, 2012, 61: 59-66.
[4] 杨波, 郭剑川, 谭章禄. 基于国民生产总值增长率微调制的国家能源年度消费总量 Logistic 修正模型研究[J]. 中国管理科学, 2017,25(6): 32-38.
[5] Zeng Chunlei, Wu Changchun, Zuo Lili, et al., Predicting energy consumption of multiproduct pipeline using artificial neural networks[J]. Energy, 2014,66: 791-798.
[6] Pindyck R S, Rubinfeld D L. Econometric models and economic forecasts[M]. Boston: McGraw-Hill Boston, 1998.
[7] 曾波, 刘思峰, 曲学鑫. 一种强兼容性的灰色通用预测模型及其性质研究[J]. 中国管理科学, 2017, 25(5): 150-156.
[8] 杨保华, 赵金帅. 优化离散灰色幂模型及其应用[J]. 中国管理科学, 2016, 24(2): 162-168.
[9] Erdogdu E. Electricity demand analysis using cointegration and ARIMA modelling: A case study of Turkey[J]. Energy Policy, 2007, 35(2): 1129-1146.
[10] Nilsson N J. Principles of artificial intelligence[M]. San Francisceo:Morgan Kaufmann, 2014.
[11] 胡雪棉, 赵国浩. 基于 Matlab 的 BP 神经网络煤炭需求预测模型[J]. 中国管理科学, 2008, 16(S1): 512-525.
[12] 卫敏, 余乐安. 具有最优学习率的 RBF 神经网络及其应用[J]. 管理科学学报, 2012, 15(4): 50-57.
[13] 张冬青, 马宏伟, 宁宣熙. 基于结构可变的 RBF 神经网络的时间序列预测[J]. 中国管理科学, 2010, 18(3): 83-89.
[14] 彭建良, 李新建. 能源消费量模拟分析和预测的神经网络方法[J]. 系统工程理论与实践, 1998, 18(7): 76-83.
[15] Lu C J, Lee T S, Chiu C C. Financial time series forecasting using independent component analysis and support vector regression[J]. Decision Support Systems, 2009, 47(2): 115-125.
[16] Brereton R G,Lloyd G R. Support vector machines for classification and regression[J]. The Analyst,2009,135(3):230-287.
[17] Kavaklioglu K. Modeling and prediction of Turkey’s electricity consumption using support vector regression[J]. Applied Energy, 2011, 88(1): 368-375.
[18] 陈荣, 梁昌勇, 谢福伟,等. 基于自适应 GA-SVR 的旅游景区日客流量预测[J]. 中国管理科学, 2012,20(S1):61-66.
[20] Lee D G, Lee B W, Chang S H. Genetic programming model for long-term forecasting of electric power demand[J]. Electric Power SystemsResearch, 1997, 40(1): 17-22.
[21] Wang Shuai, Yu Lean, Tang Ling, et al. A novel seasonal decomposition based least squares support vector regression ensemble learning approach for hydropower consumption forecasting in China[J]. Energy, 2011, 36(11): 6542-6554.
[22] Ivakhnenko A G. Polynomial theory of complex systems[J]. IEEE transactions on Systems, Man and Cybernetics, 1971, 1(4): 364-378.
[23] Xiao Jin, Xie Ling,He Changzheng,et al. Dynamic classifier ensemble model for customer classification with imbalanced class distribution[J]. Expert Systems with Applications, 2012, 39(3): 3668-3675.
[24] Xiao Jin, Xiao Yi,Huang Anqiang, et al. Feature-selection-based dynamic transfer ensemble model for customer churn prediction[J]. Knowledge and Information Systems, 2015, 43(1): 29-51.
[25] Xiao Jin,Jiang Xiaoyi,He Changzheng, et al. Churn prediction in customer relationship management via GMDH-based multiple classifiers ensemble[J]. IEEE Intelligent Systems, 2016, 31(2): 37-44.
[26] Xiao Jin,He Changzheng,Jiang Xiangyi, et al. A dynamic classifier ensemble selection approach for noise data[J]. Information Sciences, 2010, 180(18): 3402-3421.
[27] Xiao Jin, He Changzheng, Jiang Xiaoyi. Structure identification of bayesian classifiers based on GMDH[J]. Knowledge-Based Systems, 2009. 22(6): 461-470.
[28] Xiao Jin, Cao Hanwen,Jiang Xiaoyi, et al. GMDH-based semi-supervised feature selection for customer classification[J]. Knowledge-Based Systems, 2017, 132(9): 236-248.
[29] 贺昌政. 自组织数据挖掘与经济预测[M]. 北京: 科学出版社, 2005.
[30] Xiao Jin, Sun Haiyan,HuYi, et al. GMDH based auto- regressive model for China’s energy consumption prediction[C]//Proceedings of 2015 International Conference on Logistics, Informatics and Service Sciences,Barelona,Sipain,July,27-29. 2015.
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
初中生世界·九年级(2020年2期)2020-04-10
矿山安全信息(2020年12期)2020-01-05
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
电子制作(2018年17期)2018-09-28
卷宗(2018年14期)2018-06-29
世界热带农业信息(2016年12期)2017-05-23
印刷技术·数字印艺(2015年6期)2015-08-31
