
基于聚类分析和时序预测方法的电视剧收视率预测
2018-01-26 04:58南京市第二十九中学倪子航
电子世界 2018年1期
南京市第二十九中学 倪子航
1.前言
电视剧(又称为剧集、电视戏剧节目、电视戏剧或电视系列剧)是一种适应电视广播特点、融合舞台和电影艺术的表现方法而形成的艺术样式。电视剧热度值,不仅体现了人们对于娱乐生活的舆论趋势,更是电视剧平台多元化发展的体现。
对于电视剧热度值的研究正在快速发展,人民大学新闻学院的周小、韩瑞娜、凌姝在其相关研究中,开展了对网上收视度与线下收视率的关系探讨,并提出了多屏发展下新的电视评估体系的参考因素[1]。此外,胡兵、邓极在《微博对电视剧收视率的影响研究》中,还深入探究了新媒体微博对于传统电视剧收视率的影响[2]。各大视频网站都在近几年推出了关于电视剧指数的综合评价体系,如“爱奇艺指数”、“优酷指数”等。
本文在前人研究的基础上,逐步深入地对多屏播放模式下的电视剧热度展开了研究,探寻了电视剧收视率变化模式的客观规律,提出描述收视率变化模式的四个特征,并用k-means方法进行聚类分析,根据三类电视剧的特点,建立了自回归模型和灰色预测模型进行时间序列预测,按类别对比了不同阶次间自回归模型的拟合效果,最终建立了通过历史数据对电视剧最后三集的收视率进行预测的模型。
2.电视剧收视率预测模型的建立和求解
2.1 数据收集和预处理
本文中用到的电视剧相关信息主要来源于百度百科资料库,其中收视率数据来源于CSM52城市网和全国网收视率(www.csm.com.cn),播放量数据来源于腾讯、优酷、爱奇艺等主流视频网站。当一部电视剧在同一时间段于多个电视台播出时,我们将各个台收视率加在一起,作为数据用收视率。
在收集到近几年电视剧的比较权威的大量数据后,我们小组对数据进行了预处理工作。电视剧的热播有很多原因,为了研究热度高的电视剧内在的规律,我们将研究对象定为近几年的“大热剧”。研究对象符合以下两条标准:
(1)最近三年播出:由于近几年网络化发展迅速,收视率和播放量的发展模式与数年前有所不同。若加入很早之前的热门电视剧(如《还珠格格》、《西游记》)为研究对象,势必会造成收视率与网络播放量的异常波动,所以我们将研究对象定为近三年电视剧。
(2)平均首播收视率在2%以上:通过收视率以及网络搜索量数据比较,我们发现,近三年的电视剧中,平均收视率在2% 以上的电视剧,在播出时均造成了不小的轰动,并成为了当时的热点,符合我们对于研究对象热度高的要求。
所以,我们用以上条件为标准,并结合了社会舆论、观众口碑和电视剧影响力等因素进行调整。从近三年所有电视剧范围内,最终选择了《琅琊榜》、《人民的名义》、《芈月传》、《三生三世十里桃花》、《花千骨》、《欢乐颂1》、《欢乐颂2》、《微微一笑很倾城》、《武媚娘传奇》、《虎妈猫爸》、《何以笙箫默》、《亲爱的翻译官》、《女医明妃传》这13部类型、风格、播出时间并不相同的“大热剧”为研究对象。
2.2 基于收视率特征的电视剧聚类分析
对于收视率来说,因为前几集的收视率势必与后几集的收视率有很大的关联性,所以通过历史数据可以一定程度上揭示现象的变化规律,所以我们采用时间序列预测模型。本文选用自回归模型进行预测。由于不同类型的电视剧具有不同的收视规律,显然不适合用同一模型求解。因此,我们将收视率的变化模式作为电视剧聚类标准,将研究对象进行聚类分析。为了定量地刻画电视剧的变化模式,我们对13部电视剧的收视率 与集数 进行了一次、二次拟合,将拟合得到的参数作为聚类特征,进行了如表1的统计分析。

表1 描述收视率变化模式的四个特征
用上述方法,可以分别计算出13部电视剧的每个特征值,由于篇幅所限不再一一赘述。进而利用python实现k-means聚类分析的方法,将所有电视剧分为三个类别,每个类别具有如下表2的特征:

表2 利用k-means聚类分析得到的电视剧类别
2.3 收视率自回归模型的建立与优化
2.3.1 利用AR(2)模型预测第一种模式电视剧收视率
首先,对于第一种模式,我们选取了《人民的名义》作为研究对象,分别尝试了四种自回归模型。采用同样的训练集和测试集,来评估不同回归模型的性能。此处代表第集的收视率:
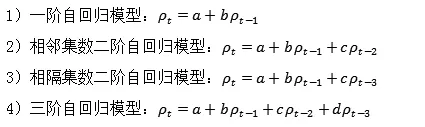
经过研究发现,第三种模型,即运用前一集和前第三集的数据的二阶自回归模型拟合最好。因为收视率会受到人为因素影响,相邻剧集间收视率会小范围波动,而采用隔一集的收视率数据可以一定程度上减少波动带来的影响。而三阶自回归模型会因为参数较多,出现一定的过拟合现象。因此,我们选择的自回归模型为:

我们利用《人民的名义》、《三生三世十里桃花》、《欢乐颂1》、《虎妈猫爸》、《何以笙箫默》作为训练集,以《女医明妃传》作为与测试集检验模型的性能,利用excel的拟合工具进行求解,最终得到模型的表达式为:
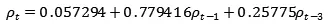
之后分析该模型的拟合性能,模型的拟合优度R2= 0.92988,Significance F=3.67*10-45。两个影响因素的P-value也通过了0.05的显著性水平检测。可见,该模型在训练集上能够较好地反映出数据的波动性。之后对该模型的预测性能进行检测,将《女医明妃传》后23个收视率数据代入模型中,求解出《女医明妃传》后20个收视率数据的预测值。经过计算,该模型在测试集结果中,真实值与预测值的相关系数为0.923112,均方差为0.981483。能够看出,模型具有较好的预测能力。
2.3.2 利用GM(1,1)模型预测第二种模式电视剧收视率
接着,我们分析了第二种模式中剧集的收视率变化。在第二种收视率变化模式中,由于存在收视率的拐点,所以最后的10集的收视率可能有所下降(如芈月传),也可能上下波动(如花千骨)。所以在该模式中,我们选取电视剧的后半段收视率作为训练集,并选取非线性的时序预测模型——灰色预测GM(1,1) 来进行建模。
GM(1,1) 模型是一种灰色动态预测模型,在灰色系统理论中应用最为广泛的,该模型是由一个单变量的一阶微分方程组成,可以用于复杂系统某一主导因素特征值的拟合和预测,以探究主导因素变化规律和未来发展变化态势。该模型训练需要的数据少,能够反映非线性的变化趋势,同时对样本分布没有严格的平稳性要求,所以非常符合该模式的收视率预测。
我们利用 python 编程实现了灰色预测模型,训练集采用《芈月传》、《琅琊榜》、《花千骨》、《微微一笑很倾城》、《欢乐颂2》五部电视剧的后一半集数的收视率,测试集选取这五部电视剧的最后三集收视率。我们建立了GM(1,1) 模型和二阶自回归模型进行对比,希望体现出灰色预测模型对于该类电视剧的适用性。经过模型的训练和求解,在测试集上的测试性能如表3所示。
从表3可以看出,真实值和预测值的均方差方面,GM(1,1)模型均方误差为,而AR(2)模型的均方误差为,灰色预测模型表现更加优秀。同时以《芈月传》和《微微一笑很倾城》为例(在表格中标注为黄色),灰色预测模型成功预测出了最后两天的下降趋势,而自回归模型则并未能预测出来。
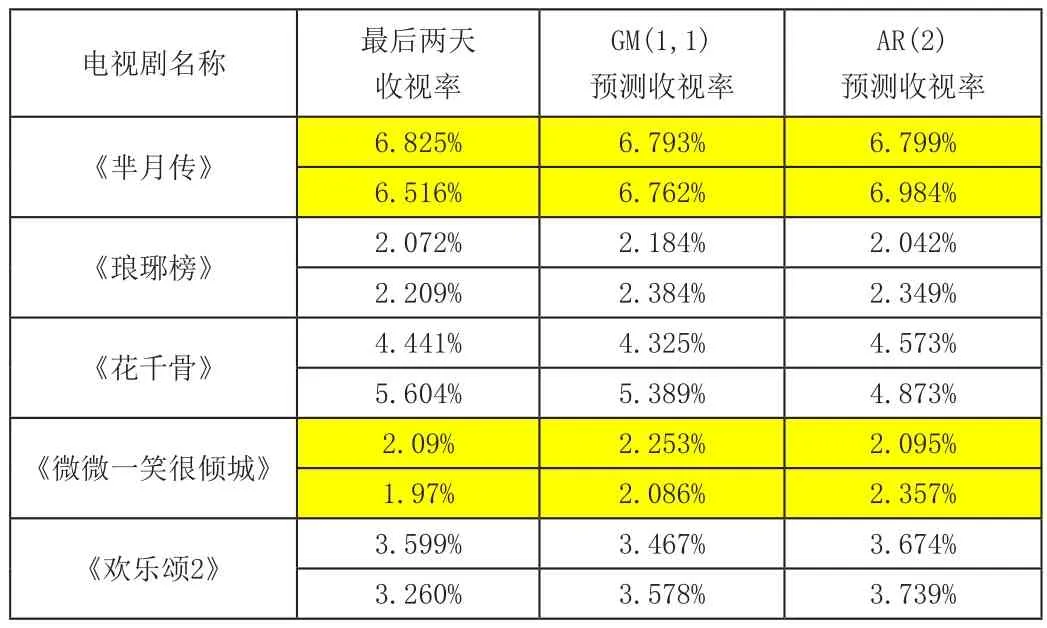
表3 GM(1,1)模型和AR(2)模型的性能对比
2.3.3 对第三种模式电视剧收视率的讨论
在数据统计过程中,我们也发现了诸如《亲爱的翻译官》、《古剑奇谭》等电视剧,其收视率变化模式存在较大幅度的波动。究其原因,这些电视剧的收视率收到很多其他外界因素的干扰。以《古剑奇谭》为例,该剧作为湖南卫视试水的首部周播剧,开创了周播剧先河,并且收获了大量粉丝,成为了当时的现象级热播剧,然而我们发现,其电视剧收视率在接近结尾的15集左右,出现大幅度下降。
经过分析发现,收视率缩水的时期正好在8月末9月初,处在开学期。由于《古剑奇谭》属于古装仙侠剧,主演们均为当红小鲜肉,所以面对的收视群体多为年轻观众,包括一大部分学生。所以导致在开学季出现收视下滑。从中我们也可看出收视群体的不同,对于电视剧收视率的影响。
由此看出,这类电视剧的后三集收视率很难用之前的收视率来预测。一种解决方案是排除异常点的干扰,通过数据预处理进行降噪,进而用AR(2)或者GM(1,1)模型求解;另一个解决方案是在模型中加入更多的影响因素,建立多元回归模型进行求解。
3.结论与展望
电视剧的收视率和网络播放量一直是衡量电视剧热度的重要评价指标。本文在前人研究的基础上,首先对收视率的时间序列变化进行研究。采用无监督学习的流程,总结出描述收视率变化的四个特征,用k-means聚类分析方法,依据四个特征将电视剧分成了三类,并根据每一类收视率的实际变化特点,分别采用自回归模型和灰色预测模型进行了时序预测,最终分析出了电视剧收视随时间的变化趋势。
[1]梁招娣,刘小龙.基于RBF神经网络的电视收视率预测[J].河南科学,2013(9):1428-1431.
[2]汪洋,田钢,温淑鸿.基于BP神经网络的电视节目收视率预测模型[J].电视技术,2014,38(6):94-96.
[3]张茜,吴超,乔晗,等.基于TEI@I方法论的中国季播电视综艺节目收视率预测[J].系统工程理论与实践,2016(11):2905-2914.
[4]黄玲莉,刘小龙.基于ARIMA与BP神经网络的收视率组合预测模型[J].电视技术 2015,39(9):117-121.
[5]胡兵,邓极.微博对电视剧收视率的影响研究[J].今传媒,2015(06):32-34.
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·七年级数学人教版(2020年10期)2020-11-26
数学物理学报(2020年2期)2020-06-02
小学生学习指导(低年级)(2020年3期)2020-06-02
Coco薇(2017年2期)2017-04-25
Coco薇(2017年2期)2017-04-25
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
光学精密工程(2016年6期)2016-11-07
