
面向不确定数据的概率障碍k聚集最近邻查询*
2018-02-05 03:46于嘉希张丽平
计算机与生活 2018年2期
于嘉希,李 松,张丽平,刘 蕾
哈尔滨理工大学 计算机科学与技术学院,哈尔滨 150080
1 引言
最近邻查询[1]问题是空间数据查询研究的重要问题之一,即给定一个查询点和数据点集,求解到该查询点距离最近的一个数据点。为了满足不同情况下的查询需求,近年来对最近邻查询的研究已扩展到k最近邻查询[2]、组最近邻查询[3]、组障碍最近邻查询[4]、障碍k最近邻查询[5-6]、反向最近邻查询[7]、聚集最近邻查询[8]、可视最近邻查询[9]、不确定数据的最近邻查询[10]、不确定数据的反近邻查询[11]、不确定数据的组近邻查询[12]等方面。
聚集最近邻查询是最近邻查询的变体之一,在基于位置的服务中有着广泛的应用。给定数据点集P={p1,p2,…,pn}和查询点集Q={q1,q2,…,qn},通过计算数据点p到查询点集Q的聚集距离,从而得到查询结果。这里定义了3种聚集函数,分别为sum、max和min,聚集最近邻的查询结果依赖于不同的聚集函数,并且返回到查询点集聚集距离最小的数据点。类似的,k聚集最近邻查询返回聚集距离最小的k个数据点的集合。
在实际应用当中,需要考虑一些真实环境下的限制因素。空间数据之间往往会存在无法穿过的障碍物,例如河流、建筑物等,这时两点间距离不再是欧氏距离,因此需要计算障碍距离。而随着技术的进步和人们对采集和获取数据技术逐渐深入,不确定数据得到了广泛的重视,由于原始数据的不准确、处理缺失值、粗细粒度的数据集合等原因,不确定数据广泛存在于经济、军事、物流、金融、电信、气象、地理信息等领域[13]。不确定数据和障碍环境下的k聚集最近邻查询是一个新的问题。本文主要针对不确定数据的概率障碍k聚集最近邻查询问题进行研究,提出基于不确定Voronoi图的概率障碍k聚集最近邻查询方法,返回到查询点集的聚集距离最小的k个数据点集,并保证其概率值大于给定阈值。
2 相关工作
传统的近邻查询问题都是在理想的欧氏环境下进行研究,但实际应用当中物体之间往往存在一些无法穿过的障碍物,因此需要考虑到障碍距离的计算。文献[4]研究了障碍组最近邻查询问题,通过构造剪枝区域去剪枝对障碍距离计算没有影响的障碍,从而减少计算量,提高查询效率。文献[5]和文献[6]利用障碍Voronoi图的特性提出剪枝策略,减少了需要处理的数据点个数。
文献[8]研究了聚集最近邻查询,提出了3种利用R树处理聚集最近邻查询的方法:MQM(multiple query method)、SPM(single point method)和 MBM(minimum bounding method)。这3种方法中,MBM是最优算法。文献[14]研究了路网环境下移动对象的k聚集最近邻查询方法,通过剪枝得到候选集合的方法进行求解。当聚集最近邻查询的聚集函数为sum时,被称为组最近邻查询。文献[3]给出了3种基于R树索引的处理组最近邻查询的方法,分别是MQM、SPM和MBM。文献[15]提出了一种基于查询点集Q中两种最远点构成的椭圆及其MBR(minimum bounding rectangle)对中间节点进行剪枝的方法。文献[16]针对无索引数据点集,提出了up-ANN算法和投影剪枝算法,有效提高了组近邻查询效率。
以上处理聚集最近邻查询的方法针对的都是确定数据,而现实应用中往往要处理大量的不确定数据。文献[17]对不确定数据的聚集最近邻查询进行研究,并提出了空间剪枝和概率剪枝两种方法,对数据点集进行剪枝,有效提高了查询效率。文献[18]基于存在不确定数据,研究了范围查询、最近邻查询、反最近邻查询的解决方法。文献[19-20]提出了不确定数据的组最近邻查询方法。
已有方法无法处理不确定数据的障碍k聚集最近邻查询问题,因此本文提出了基于不确定Voronoi图的概率障碍k聚集最近邻查询方法。
3 基础定义
本文研究位置不确定数据,并采用如下形式的不确定数据模型:给定不确定数据点集P={p1,p2,…,pn},每个不确定数据在各自的不确定区域中任意分布,该区域可以为任意形状,并以一个概率密度函数描述它在该区域内的分布情况。本文假定不确定数据pi位于一个以Cpi为圆心,为半径的不确定区域圆UR(pi)中。以O={O1,O2,…,On}描述障碍物集合,并假定各个障碍物之间互不相交,且障碍物与不确定数据的不确定区域互不重叠,以线段来表示障碍物。本文求解概率障碍k聚集最近邻查询问题使用不确定Voronoi图,其相关定义在文献[19,21]中已经给出,本文在文献[4]提出的可视性、障碍距离等基础上,提出以下定义。
定义1(不确定数据的最小障碍距离与最大障碍距离)给定不确定数据点集合P={p1,p2,…,pn},对于不确定数据点pi,pj∈P,其不确定区域半径分别为rpi、rpj,则pi到pj的最小障碍距离为,最大障碍距离为。
定义2(障碍聚集距离)给定数据点集P={p1,p2,…,pn},查询点集Q={q1,q2,…,qn},障碍集合O={O1,O2,…,On}。数据点p到查询点集Q的障碍聚集距离定义为:

其中,disto(p,qi)代表数据点p到查询点qi的障碍距离。f代表聚集函数sum、max或min。根据不同的聚集函数,可根据如下方式计算其相应的聚集距离:


定义3(障碍聚集最近邻查询)给定数据点集P={p1,p2,…,pn},查询点集Q={q1,q2,…,qn},障碍集合O={O1,O2,…,On},障碍聚集最近邻查询返回到查询点集的障碍聚集距离adisto-f(p,Q)最小的数据点,即满足:
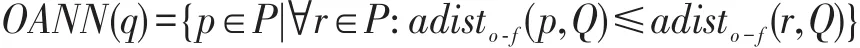
定义4(概率障碍k聚集最近邻查询)给定不确定数据点集合P={p1,p2,…,pn},查询点集合Q={q1,q2,…,qn},障碍集合O={O1,O2,…,On},阈值T,则不确定数据的概率障碍k聚集最近邻查询返回形如{s,prob(s)}的查询结果。其中s为数据点集合的子集,由到查询点集的障碍聚集距离最小的k个数据点组成,prob(s)为该集合成为查询点集Q的障碍k聚集最近邻集合的概率值,且prob(s)>T,T∈(0,1],i=1,2,…,k。prob(s)计算公式为:

其中,di(r)和Di(r)分别为pi到查询点集的障碍聚集距离的概率密度函数和累计分布函数。
4 基于不确定Voronoi图的概率障碍k聚集最近邻查询方法
4.1 查询点集处理阶段
聚集最近邻查询的难点为针对多个查询点求解在不同聚集函数下的聚集最近邻点,因此本节通过Min_Circle(Q)算法求解查询点集的最小覆盖圆,用该最小覆盖圆的圆心O代表查询点集的分布情况,以此作为查询点中心q,将问题进行简化,方便后文的剪枝处理阶段。本文采用增量法计算查询点集的最小覆盖圆,提出算法Min_Circle(Q)。首先做出前i-1个查询点的最小覆盖圆,再加入第i个点,如果它在圆内或圆周上,则什么也不做;否则取距离当前最小覆盖圆圆心的最远点qm,得到新的最小覆盖圆。重复以上过程依次遍历查询点集,直至所有查询点都在圆中(或圆周上),则该圆就是所求的最小覆盖圆。
如图1为求解最小覆盖圆的示例图。首先任取两点qi、qj,以两点间距离dist(qi,qj)为直径做圆,得到当前最小覆盖圆O1。对于Q中的点,判断它是否在当前最小覆盖圆内(或圆周上)。根据判断结果,执行相应语句,找到与当前最小覆盖圆圆心距离最远的查询点qm,不断扩大最小覆盖圆,最终使之覆盖所有查询点。所得到的圆就是覆盖所有查询点的最小覆盖圆。

Fig.1 Example of minimum covered circle图1 最小覆盖圆示例图
基于以上讨论,给出算法1。
算法1 Min_Circle(Q)


4.2 过滤阶段
过滤阶段为了更好地过滤掉无关数据点,采用剪枝策略对数据点集P进行剪枝处理,从而得到候选集合。为得到剪枝策略,首先给出如下定理。
定理1给定不确定数据点集合P={p1,p2,…,pn},对于某一查询点q,若它所在的不确定Voronoi区域生成点集合为M,则它的k最近邻点必包含在M及M的k级邻接生成点中。
证明由不确定Voronoi图的性质可知,若查询点q落在不确定Voronoi区域UVP(pi)中,则q到生成点pi的距离小于q到其他生成点的距离。若该Voronoi区域为单生成点Voronoi区域SUV(pi),则pi一定是q的最近邻点,故其k最近邻点在pi的k级邻接生成点中;若该Voronoi区域为多生成点Voronoi区域MUV(pi,pj),q的最近邻点一定在此区域的多生成点中,其k最近邻点一定在多生点的k级邻接生成点中。故该定理成立。 □
定理2[22]对于不确定Voronoi单元UVP(pi)内任意一点q,则对q的第k+1个最近邻qk+1有qk+1∈AG1(p)∪AG2(p)∪…∪AGk(p)(k为整数,k≥1),即q的第k+1个最近邻点在q的最近邻前k级生成点中。
定理3若某数据点pi在不确定Voronoi图中的所有邻接生成点都被剪枝,则pi也被剪枝。
证明若某数据点pi的所有邻接生成点都被剪枝,说明在其邻接生成点所在层次范围内,已有数据点的障碍聚集距离小于该邻接生成点,则pi不可能成为所求结果,故可被剪枝。 □
定理4对于某一不确定数据点p和查询点q,记num(p,q)为p与q之间所有到q可视的点的个数,若num(p,q)≥k,则将p剪枝。
证明当k=1时,设p与q之间经过点p1,且p1与q可视,则p1到q的距离一定小于p到q的距离,故p一定不是所求,可将其剪枝;当k>1时,p与q经过的数据点中已有超过k个与q可视,说明这些数据点到q的距离一定小于q到p的距离,则p一定不是所求,可将其剪枝。 □
定理5若某一数据点到查询点集的最小障碍聚集距离大于adistk-o-max,则可将该数据点剪枝。其中,adistk-o-max表示数据点到查询点集的最大障碍聚集距离中第k小的距离。
证明以第k小的最大障碍聚集距离为半径做圆,其圆心为查询点集的中心,则不确定区域与该圆无交集的数据点均可剪枝。这是由于这些点到查询点的最小障碍聚集距离已经大于第k小的最大距离adistk-o-max,说明在该圆范围内已经至少存在k个数据点到查询点的障碍聚集距离小于等于adistk-o-max,因此可将其剪枝。 □
过滤阶段的具体剪枝规则根据不同的聚集函数有所不同,下面针对不同的聚集函数,分别给出相应的剪枝规则。
4.2.1 聚集函数f=sum
当聚集函数为sum时,求解到查询点集的障碍距离之和最小的k个数据点。过滤阶段采用算法1得到的中心点q代表查询点集的分布。根据定理1至定理5,提出如下5项剪枝策略。
剪枝策略1只有查询点中心q到生成点的个数小于或等于k的生成点才能放入候选集中。
剪枝策略2若某数据点pi在不确定Voronoi图中的所有邻接生成点都被剪枝,则pi也被剪枝。
剪枝策略3对于某一不确定数据点p和查询点q,记num(p,q)为p与q之间所有到q可视的点的个数,若num(p,q)≥k,则将p剪枝。
剪枝策略4若某一数据点到查询点的最小障碍距离大于distk-o-max,则可将该数据点剪枝。其中distk-o-max表示数据点到查询点的最大障碍距离中第k小的距离,即distk-o-max=k-min{disto-max(q,Ci)}。
剪枝策略5用队列H存储元组(pi,disto-min(q,pi)),并按disto-min(q,pi)升序排列,使用剪枝策略4进行剪枝。若某数据点p被剪枝,则p后的所有查询点都被剪枝,过滤阶段结束。
图2为f=sum情况下的概率障碍k聚集最近邻查询剪枝阶段示例图。在对数据点集P进行剪枝时,剪枝策略1根据定理2提出,要查找q的第i+1个最近邻只需在q最近邻的前i级邻接生成点中进行查询,确保了查询点集的障碍k聚集最近邻点一定在候选集合中,且不会包含多余的点,保证了过滤算法的正确性。剪枝策略2根据定理3提出,对数据点集进行剪枝,若某数据点pi的所有邻接生成点都被剪枝,则说明在此区域中不会再有障碍聚集距离小于已获得的障碍聚集距离,则可将其剪枝。剪枝策略3根据定理4提出,若q与pi之间存在超过k个可视的数据点,则可将pi剪枝。剪枝策略4根据定理5提出,通过求解第k小的最大障碍距离进而剪枝不可能成为结果的数据点。剪枝策略5利用队列H并将其元素排序,结合剪枝策略4,将不满足查询要求的数据一次性剪枝。
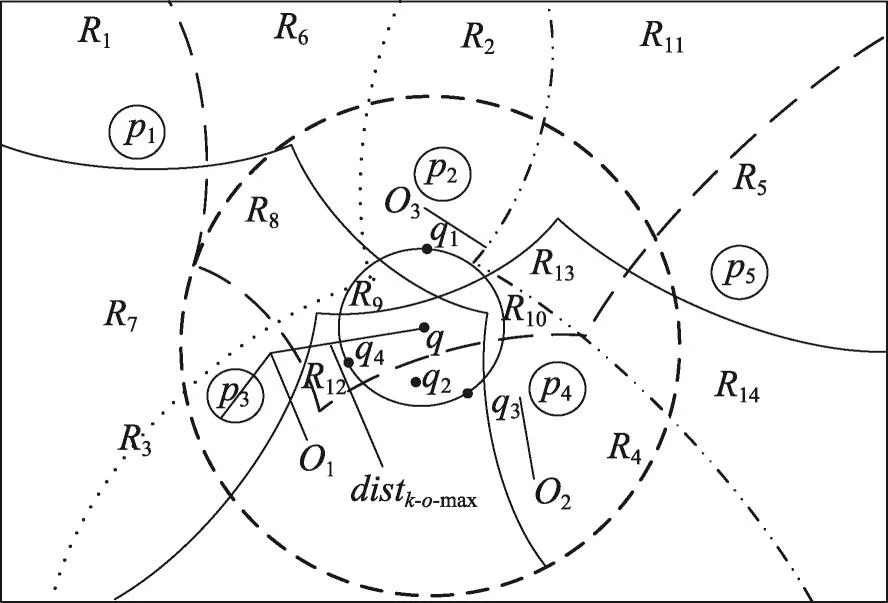
Fig.2 Example of pruning phase in case of f=sum图2 f=sum情况下的剪枝阶段示例图
基于以上讨论,给出算法2。
算法2 Sum_Can(Q,P,O,k)


4.2.2 聚集函数f=max
当聚集函数为max时,求解使到查询点集的障碍距离中最大值最小的k个数据点。过滤阶段使用以下几种剪枝策略对数据点集P进行剪枝处理,以减少无关数据对结果计算的影响。根据定理1至定理5,提出以下4项剪枝策略。
剪枝策略1根据定理2,只有查询点中心q到生成点的个数小于或等于k的生成点才能放入候选集中。
剪枝策略2根据定理3,若某数据点pi在不确定Voronoi图中的所有邻接生成点都被剪枝,则pi也被剪枝。
剪枝策略3根据定理4,对于某一不确定数据点p和查询点q,记num(p,q)为p与q之间所有到q可视的点的个数,若num(p,q)≥k,则将p剪枝。
剪枝策略4根据定理5,若某一数据点到查询点集的最小障碍聚集距离大于adistk-o-max,则可将该数据点剪枝。其中adistk-o-max表示第k小的最大障碍聚集距离,adistk-o-max=k-min{adisto-max(Q,pi)}。
基于以上讨论,给出算法3。
算法3 Max_Can(P,Q,O,k)

4.2.3 聚集函数f=min
当聚集函数为min时较为简单,需求解到查询点集合的最小障碍距离最小的k个数据点。由定理1可知,给定某一查询点,确定它所在的不确定Voronoi区域,则它的k近邻点一定在此区域的生成点及其k级邻接生成点中,因此在过滤阶段利用不确定Voronoi图的性质将查询点集的生成点及邻接生成点加入候选集合Min_Candidate。f=min情况下的剪枝规则由定理1给出,首先找到查询点集中心q在不确定Voronoi图中的位置,确定其所在的不确定Voronoi区域,将该不确定Voronoi区域的生成点及其k级邻接生成点放入候选集合。
算法4 Min_Can(P,Q,O,k)

4.3 精炼阶段
本文通过前两个阶段,对数据点集进行了剪枝,移除了不可能成为查询结果的数据点,并得到了候选集合。接下来在精炼阶段,要对候选集合中的数据点进行概率值求解,并与给定阈值进行比较,得到结果集合。给出算法5。
算法5 POkANN(P,Q,O,k)


5 实验与分析
通过实验验证本文提出的POkANN方法的性能。由于本文首次对概率障碍k聚集最近邻查询问题进行研究,且现有的聚集最近邻查询算法没有考虑障碍物存在对结果的影响,返回的查询结果也只有一个,无法直接用于概率障碍k聚集最近邻查询,不能直接进行比较,从而基于基本查询技术,设计了两个基本算法与本文算法进行比较。第一个算法直接计算各个数据点到查询点集的障碍聚集距离,计算其成为结果的概率值,返回形如{s,prob(s)}的查询结果。其中s为数据点集合的子集,由到查询点集的障碍聚集距离最小的k个数据点组成,prob(s)为该集合成为查询点集Q的障碍k聚集最近邻集合的概率值且满足prob(s)>T,将该算法称为POkANN_Basic算法。第二个算法称为POANN*算法,POANN*算法的主要思想是对文献[12]中经过改进的POANN*算法加入障碍后重复调用k次来完成概率障碍k聚集最近邻查询任务。
实验硬件环境为AMD双核2.2 GHz处理器,2 GB内存,Windows 7操作系统,使用Visual C++6.0实现。不确定数据点集P来自真实数据集Long Beach Road(http://www.rtreeportal.org),由53 144个矩形表示数据点,对于每个不确定数据,其不确定区域由矩形的中心为圆心,对角线的一半为半径形成的区域圆来表示。查询点集Q为随机生成的点,并随机生成障碍集合,采用UV-index对不确定Voronoi图进行索引,障碍集由线段表示。本实验主要从k值、障碍物规模、查询点集规模对查询时间的影响及剪枝比率进行验证,并将POkANN_Basic算法和POANN*算法与本文提出的POkANN算法进行对比实验。实验结果为执行100次查询结果取平均值得到。
图3和图4分别验证了聚集函数sum和max情况下k值对查询时间的影响。从图中可以看出,在其他条件不变的情况下,随着k值的增加,由于3种算法对于障碍聚集距离和概率值的计算量增加,导致查询时间逐渐增长。但由于本文POkANN算法具有剪枝策略,去除了不可能成为结果的数据点,有效地减少了计算量,查询时间优于另外两种算法。

Fig.3 Effect ofkon query time(f=sum)图3 k值对查询时间的影响(f=sum)
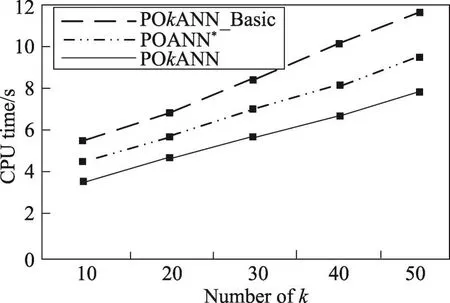
Fig.4 Effect ofkon query time(f=max)图4 k值对查询时间的影响(f=max)
图5和图6分别验证了聚集函数sum和max情况下障碍物个数对查询时间的影响。从图中可以看出,在其他条件不变的情况下,随着障碍物个数的增加,查询时间也随之增加,这是由于大量的障碍聚集距离计算量所导致的。随着障碍物的增加,另两种算法的查询时间显著增长,而本文POkANN算法优势在于过滤阶段的剪枝策略将不可能成为查询结果的数据点剪枝,有效减少了障碍聚集距离的计算量,因此POkANN算法略好于另两种算法。

Fig.5 Effect of the number of obstacles on query time(f=sum)图5 障碍物个数对查询时间的影响(f=sum)

Fig.6 Effect of the number of obstacles on query time(f=max)图6 障碍物个数对查询时间的影响(f=max)
图7和图8分别验证了聚集函数sum和max情况下查询点集规模的变化对查询时间的影响。从图中可以看出,在其他条件不变的情况下,随着查询点数量的增加,3种算法的查询时间都有所增加,这是由于查询点的增加,导致了障碍聚集距离的计算量增大,数据点要分别计算到各个查询点的障碍聚集距离。本文POkANN算法在查询点集处理阶段需要计算查询点集的最小覆盖圆,需要消耗一部分的查询时间,因此在查询点较少时,查询时间多于POANN*算法,但随着查询点数量的增加,其优势逐渐显现出来,在过滤阶段,通过剪枝策略将不可能成为结果的数据点剪枝,因此会有效地减少障碍聚集距离的计算量。
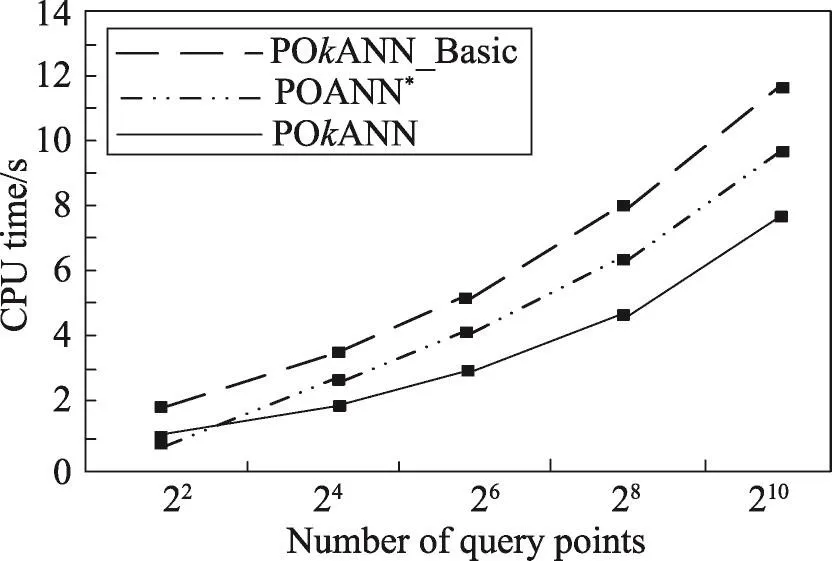
Fig.7 Effect of query data set size on query time(f=sum)图7 查询点集规模对查询时间的影响(f=sum)
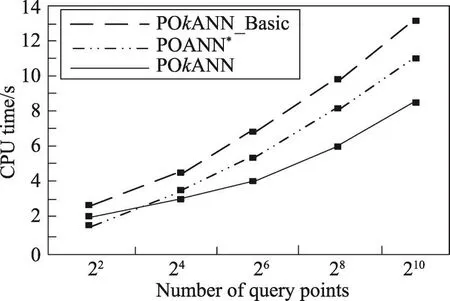
Fig.8 Effect of query data set size on query time(f=max)图8 查询点集规模对查询时间的影响(f=max)
6 结束语
本文提出了基于不确定Voronoi图的概率障碍k聚集最近邻查询算法(POkANN)。结合聚集最近邻查询的特点,本文算法分为3个阶段:首先通过求解最小覆盖圆处理查询点集;再通过不同的剪枝策略处理相应聚集函数下的数据点集,得到候选集合;最后对候选集合中的数据进行精炼,并与给定阈值进行比较,返回结果集。通过实验进行验证,本文算法具有较好的性能。未来的研究重点主要集中在以下两点:
(1)存在级不确定数据k聚集最近邻查询问题;(2)不确定数据的可视聚集最近邻查询问题。
[1]Ling Ping,Rong Xiangsheng,Dong Yongquan.Clusteringbased nearest neighbor searching[J].Journal of Computers,2013,8(8):2085-2092.
[2]Kim H I,Chang J W.k-nearest neighbor query processing algorithms for a query region in road networks[J].Journal of Computer Science and Technology,2013,28(4):585-596.
[3]Papadias D,Shen Qiongmao,Tao Yufei,et al.Group nearest neighbor queries[C]//Proceedings of the 20th International Conference on Data Engineering,Boston,Mar 30-Apr 2,2004.Washington:IEEE Computer Society,2004:301-312.
[4]Yang Zexue,Hao Zhongxiao.Group obstacle nearest neighbor query in spatial database[J].Journal of Computer Research and Development,2013,50(11):2455-2462.
[5]Gu Yu,Yu Ge,Yu Xiaonan.Efficient method forknearest neighbor searching in obstructed spatial databases[J].Journal of Information Science&Engineering,2014,30(5):1569-1583.
[6]Yu Xiaonan,Gu Yu,Zhang Tiancheng,et al.A method forknearest-neighbor queries obstructed spaces[J].Chinese Journal of Computers,2011,34(10):1917-1925.
[7]Safar M,Ibrahimi D,Taniar D.Voronoi-based reverse nearest neighbor query processing on spatial networks[J].Multimedia Systems,2009,15(5):295-308.
[8]Papadias D,Tao Yufei,Mouratidis K,et al.Aggregate nearest neighbor queries in spatial databases[J].ACM Transactions on Database Systems,2005,30(2):529-576.
[9]Nutanong S,Tanin E,Zhang Rui.Incremental evaluation of visible nearest neighbor queries[J].IEEE Transactions on Knowledge and Data Engineering,2010,22(5):665-681.
[10]Liu Wenyuan,Du Ying,Chen Zijun.Nearest neighbor queries with range constrained on uncertain data[J].Journal of Chinese Computer Systems,2012,33(6):1189-1194.
[11]Lian Xiang,Chen Lei.Efficient processing of probabilistic reverse nearest neighbor queries over uncertain data[J].The VLDB Journal,2009,18(3):787-808.
[12]Lian Xiang,Chen Lei.Probabilistic group nearest neighbor queries in uncertain databases[J].IEEE Transactions on Knowledge and Data Engineering,2008,20(6):809-824.
[13]Zhou Aoying,Jin Cheqing,Wang Guoren,et al.A survey on the management of uncertain data[J].Chinese Journal of Computers,2009,32(1):1-16.
[14]Chen Wen.K-aggregate nearest neighbor query method of moving objects in road networks[J].International Journal of Database Theory andApplication,2016,9(4):151-160.
[15]Li Hongga,Lu Hua,Huang Bo,et al.Two ellipse-based pruning methods for group nearest neighbor queries[C]//Proceedings of the 13th International Workshop on Geographic Information System,Bremen,Nov 4-5,2005.New York:ACM,2005:192-199.
[16]Luo Yanmin,Chen Hanxiong,Furuse K,et al.Efficient mthods in finding aggregate nearest neighbor by projectionbased filtering[C]//LNCS 4707:Proceedings of the 2007 International Conference on Computational Science and Its Applications,Kuala Lumpur,Aug 26-29,2007.Berlin,Heidelberg:Springer,2007:821-833.
[17]Lian Xiang,Chen Lei.Probabilistic group nearest neighbor queries in uncertain databases[J].IEEE Transactions on Knowledge and Data Engineering,2008,20(6):809-824.
[18]Yiu M L,Mamoulis N,Dai Xiangyuan,et al.Efficient evaluation of probabilistic advanced spatial queries on existentially uncertain data[J].IEEE Transactions on Knowledge and Data Engineering,2009,21(1):108-122.
[19]Sun Dongpu,Hao Xiaohong,Gao Shuang,et al.Probabilistic group nearest neighbor queries based on uncertain Voronoi diagram[J].Journal of Beijing University of Agriculture,2013,28(4):73-75.
[20]Chen Mo,Jia Zixi,Gu Yu,et al.Group nearest neighbor queries over existentially uncertain data[J].Journal of Chinese Computer Systems,2012,33(4):684-687.
[21]Chen R,Xie Xike,Yiu M L,et al.UV-diagram:a Voronoi diagram for uncertain data[C]//Proceedings of the 26th International Conference on Data Engineering,Long Beach,Mar 1-6,2010.Washington:IEEE Computer Society,2010:796-807.
[22]Zhang Liping,Liu Lei,Li Song.Group reverseknearest neighbor query based on voronoi diagram in spatial databases[J].Journal of Frontiers of Computer Science and Technology,2016,10(10):1365-1375.
附中文参考文献:
[4]杨泽雪,郝忠孝.空间数据库中的组障碍最近邻查询研究[J].计算机研究与发展,2013,50(11):2455-2462.
[6]于晓楠,谷峪,张天成,等.一种障碍空间中的反k最近邻查询方法[J].计算机学报,2011,34(10):1917-1925.
[10]刘文远,杜颖,陈子军.不确定数据上范围受限的最近邻查询算法[J].小型微型计算机系统,2012,33(6):1189-1194.
[13]周傲英,金澈清,王国仁,等.不确定性数据管理技术研究综述[J].计算机学报,2009,32(1):1-16.
[19]孙冬璞,郝晓红,高爽,等.基于不确定Voronoi图的概率组最近邻查询[J].北京农学院学报,2013,28(4):73-75.
[20]陈默,贾子熙,谷峪,等.面向存在不确定对象的组最近邻查询方法[J].小型微型计算机系统,2012,33(4):684-687.
[22]张丽平,刘蕾,李松,等.空间数据库中基于Voronoi图的组反k最近邻查询[J].计算机科学与探索,2016,10(10):1365-1375.
猜你喜欢
中等数学(2022年6期)2022-08-29
保健医苑(2022年5期)2022-06-10
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
中学生数理化(高中版.高考数学)(2021年11期)2021-12-21
中学生数理化·高三版(2021年3期)2021-05-14
中学生数理化·高三版(2021年3期)2021-05-14
成都信息工程大学学报(2021年6期)2021-02-12
计算机应用(2020年5期)2020-06-07
校园英语·上旬(2019年6期)2019-10-09
