
基于概率潜在语义分析模型的分类融合图像标注
2018-02-25 02:39吕海峰蔡明
电子技术与软件工程 2018年7期
吕海峰 蔡明


摘要 图像自动标注作为计算机视觉领域重要的研究课题,近年来取得了巨大的成果,但由于语义鸿沟的存在,仍然存在巨大的挑战。本文提出一种基于概率潜在语义分析模型的分类融合图像标注方法。首先,该方法分别提取图像的形状和视觉特征,聚类生成词袋;然后利用融合概率潜在语义分析模型计算得出图像标注词的概率,并利用支持向量机依据图像颜色特征分类得到分类标签的类别杈重;最后在得到的标注词概率中融入类别权重,最终得到图像的标签。并且使用Corel图像数据集进行标注模型的训练和图像的标注。实验结果表明,对比几种前沿的标注方法,本文获得了良好的性能。
【关键词】图像自动标注 词袋 支持向量机概率潜语义分析 分类
1 引言
图像自动标注就是计算机系统根据已经标注的图像和标签的关系,去预测未标注图像的标签并标注图像。但由于存在语义鸿沟,视觉特征相似的图像很可能在语义上是不相关的。为了获得语义相关的检索结果,同时避免大量的手工标注,图像自动标注成为目前关键的具有挑战性的课题。Duygulu等[3]将对象识别模型描述为机器翻译,在这个模型中,图像被分割成区域,这些区域使用各种特征被分类为区域类型;然后使用基于EM的方法来学习与图像一起提供的区域类型和关键字之间的映射。李志欣等[5]在PLSA模型和PLSA-WORDS模型的基础上提出了PLSA-FUSION标注方法,该方法分别从文本模态和视觉模态中学习两组潜在主题,然后把这两种潜在主题融合成一个潜在主题空间,有较好的性能,但特征数据在量化过程中仍会丢失重要信息。邱泽宇等[6]结合区域之间的位置关系及其标签之间的共生关系辅助标注图像,提出两种模型对标签共生关系建模辅助修正标签集,标注效果和性能有了较好的改善。Wu等[7]提出了一种称为弱标签的半监督深度学习方法,一个新的弱加权两两排序损失被有效地用来处理弱标记的图像,而三重相似性丢失被用来处理未标记的图像。
由于支持向量机(Support Vector Machine,SVM)是基于学习理论产生的,支持向量机通常具有很好的分类性能,可以用来解决局部极值问题和高维问题。用SVM解决多分类问题的方式是训练多个分类器,使每一类都可以通过SVM分类器与其它类分开。在图像标注问题中,可以将图像的类别看成是语义标签,进而把该问题转换成图像分类问题。
所以本文提出一种基于概率潜在语义分析模型的分类融合图像标注方法,该方法首先利用PLSA-FUSION模型计算出图像和标签之间的概率关系;然后利用支持向量机对图像的颜色特征进行分类得到分类标签的类别权重;最后在图像语义传播的过程中融合到概率中,作为最终的标注关键词概率集。
2 基于概率潜在语义分析模型的分类融合图像标注
2.1 图像表示
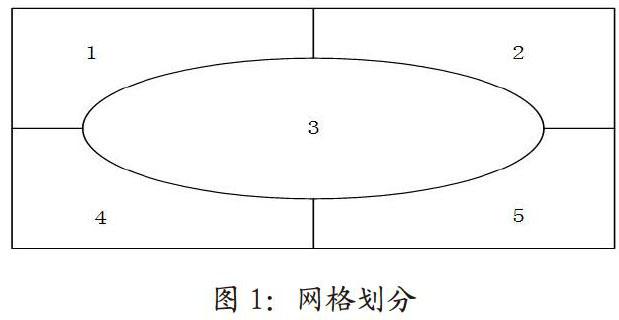
本文的图像的视觉特征表示采用图像的稠密的尺度不变描述子SIFT(scale-invariantfeature transform)和HSV颜色特征。首先对于每幅图像利用SIFT描述子提取固定網格的大量局部特征,生成128维的特征向量,通过k-means聚类生成SIFT词袋 BOW(bag-of-words);然后按图1所示的5个区域提取其HSV颜色直方图并合并成288维的直方图,并通过k-means聚类生成HSV词袋;通过实验发现当k取1000时聚类效果最佳,最后对这两类词袋词袋进行简单的连接生成最终的词袋。
2.2 建立特征数据库
在标注图像之前,需要建立一个数据库。这里,从图像中提取特征描述子,利用k-means聚类将这些描述子转换视觉单词,并保存图像的视觉单词和对应的单词直方图。进而对图像进行分类,标注和检索,并获得图像的相似性作为中间结果。
2.3 支持向量机分类模型的选取
2.4 概率潜在语义分析模型
如图2所示,PLSA-FUSION(融合的概率潜语义分析)是在PLSA的基础上采用了两个PLSA模型分别建模视觉模态和文本模态的数据,然后再以自适应的方式不对称地融合两个PLSA模型,使得它们共享同样的潜在空间(即对于每幅训练图像具有相同的主题分布),然后利用PLSA模型得到图像标注词的概率。
2.5 融合分类信息的概率语义分析模型的图像标注
因为PLSA-Fusion模型需要对图像的特征进行聚类处理,所以标注的精度局限于聚类的效果。由于图像分类不需要聚类,故不会受到底层特征聚类的影响,将图像的分类信息作为权重融合入概率语义分析模型中,有效的提高了概率语义分析模型的标注精度。
对于概率语义分析模型中图像特征数据在量化过程中仍会丢失重要信息问题,本文通过融合图像的分类信息,使图像标注有了更好的标注性能。标注模型如图3所示。
利用支持向量机对图像的区块颜色特征进行分类,获得图像的类别信息。根据分类过程中类别出现的次数作为评价类别重要性的标准。
利用融合的概率语义分析模型可以计算得到文本标签和图像之间的概率关系,通过前面分类得到的类别权重,在图像语义传播过程中将权重融合到文本标签的概率中,得到了融合了类别权重的标注词概率。用P(wIF)表示类别在分类结果中的权重,融合后得出的图像文本标签的概率为:
3 实验及分析
本文在Core15K图像集上进行仿真实验,本实验首先提取图片的视觉特征,然后使用k-means方法聚类生成视觉词汇表,通过实验得出k为1000时聚类效果最佳。图像标注的评价标准为精度preclsion和召回率recall。对于一个给定的语义关键词w,precision(w)=B/A,recall(w)=B/C。其中,A表示所有自动标注了关键词w的图像个数,B表示正确标注了关键词w的图像个数,C表示原始标注中包含关键词w的图像个数。本文采用所有标注词的平均精度和平均召回率评价图像的标注性能。标注结果比较如表1和表2所示。
在表l中给出了各种图像自动标注模型的性能比较,在两个关键词集合上的标注结果最佳49个关键字和全部260个关键字,本文算法基本上不仅优于PLSA-FUSION,而且优于PLSA-WORDS。在这两个关键词集合上,平均精度比PLSA-WORDS分别提高了17%和10%,平均召回率比PLSA-WORDS提高了分别提高了11%和6%。
在表2中给出了4张图片的在几种标注模型下标注结果对比,由表2可以得出在大部分情况下本文算法要优于PLSA-FUSION和PLSA-WORDS。
4 结束语
本文提出的一种概率潜在语义分析模型的分类融合图像标注方法,通过实验得出本文算法与几种比较前沿的标注方法相比具有更好的性能。SVM分類权重的加入对图像语义标注有很大的正向作用。由于PLSA Fusion模型采用的是PLSA和EM算法,所以收敛速度较慢,导致训练算法比较耗费时间资源,下一步的工作为寻找新的方法以优化本文的标注模型,进而提高图像标注的效率和精度。
参考文献
[1] Smeulders A W M,Worring M, Santini S, etal.Content-Based image retrieval atthe end of the early years[J].IEEETrans.on Pattern Analysis and MachineIntelligence, 2000, 22 (12) : 1349-138 0.
[2] Dat to R, Joshi D, Li J, et al. Imageretrieval: Ideas, influences, and trendsof the new age[J].ACM ComputingSurveys,2008,40(02):1-60.
[3]Duygulu P,Barnard K,Freitas J F G D,et al.Object Recognition as MachineTranslation: Learning a Lexiconfor a Fixed Image Vocabulary[C].European Conference on ComputerVision, 2002, 2353 (06): 97-112.
[4]Dempster A P,Laird N M,Rubin D B.Maximum-likelihood from in completedata via the EM algorithm[J].Journal of the Royal StatisticalSociety,1977,39(01):1-38.
[5]LI Zhi-Xin,SHI Zhi-PING,LI Zhi-Qing,et al.Automatic Image Annotation byFusing Semantic Topics [J]. Journal ofSoftware, 2011, 22 (04): 801-812.
[6] QIU Ze-Yu, FANG Quan, SANG Ji-Dao,et al.Regional Context-Aware ImageAnnotation [Jl.Chinese Journal of Computers, 2 014, 37 (06) : 139 0-13 9 7.
[7] Wu F,Wang Z, Zhang Z, et al. WeaklySemi-Supervised Deep Learning forMul t i-Label
Image Anno tation [J] .IEEE Transactions on BigData, 2017,1(03):109-122.
[8] Han J W, Kamber M, Pei J. DataMining: Concepts and Techniques [M].3rd ed. San Francisco: MorganKaufmann, 2011: 327-330.
[9]Lowe D G.Distinctive Image Featuresfrom Scale-Invariant Keypoints [J].International Journal of ComputerVision,2004,60(02):91-110.
[10] Bosch A, Munoz X, Mart i
R. Which isthe best way to organize/classifyimages by content?[J].Image & VisionComputing, 2007, 25 (06): 778-791
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
开放教育研究(2020年2期)2020-03-31
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
中国医学装备(2016年6期)2016-12-01
现代语文(2016年21期)2016-05-25
公民与法治(2016年10期)2016-05-17
燕山大学学报(2015年4期)2015-12-25
计算机工程(2015年8期)2015-07-03
大连民族大学学报(2015年2期)2015-02-27
