
基于模式注入的数据生成方法
2018-02-25 02:39易忱
电子技术与软件工程 2018年7期
关键词:数据挖掘
易忱


摘要 对于规律未知数据,利用数据挖掘算法对已拥有的少量真实数据进行模式探索,采用模式注入的方法,将探索得到的数据模式以一定的规范语言描述出来,按数据模式产生的数据约束关系转换为SDDL规范化语言,生成需要的数据,为设备性能评估提供数据支持。工程实例说明了模式注入数据生成方法的正确性和可行性。
【关键词】模式注入 数据挖掘 数据生成
很多设备的状态监控和性能评估,通常采用大数据和人工智能的方法,分析挖掘数据规律,对设备系统性能进行科学、准确的评价。但很多工况数据缺失,体量达不到大数据规模,大多是低价值密度的数据,原因主要有:
1)历史数据积累少;
2)样本少;
3)安全保密控制;
4)数据无法利用。
为了解决这一矛盾,根据数据特性和应用目的的不同,结合工程实践经验,尝试从数据的特性入手,研究模式注入或特性继承的数据挖掘方法,为性能评估提供数据支持。
1 模式注入方法研究
在具体应用中,普遍面对的是根据已有知识,无法判断数据对研究的意义,更不能明确数据蕴含知识的数据集,我们将这类数据称之为规律未知数据。通过少量历史数据,采用模式注入方法,生成这类数据。
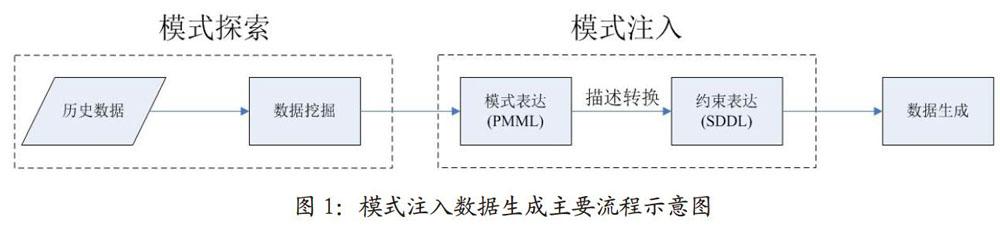
模式注入的数据生成基本思想是化规律未知为己知,然后通过规律己知数据类似的方式生成数据。在操作步骤上,首先利用数据挖掘算法对已拥有的少量真实数据进行模式探索,然后将探索得到的数据模式以一定的规范语言描述出来,如PMML (Predictive ModelMarkup Language);然后将数据模式产生的数据约束关系转换为数据生成工具的规范化语言描述, 如SDDL (Synthetic Data DefinitionLanguage),供数据生成工具使用。
PMML是由数据挖掘协会(The DataMining Group,DMG)组织开发的,主要目的是形成一种通用标准,允许应用程序和联机分析处理( OLAP)工具能从数据挖掘系统获得模型,而不用独自开发数据挖掘模块,为模型的跨平台、跨系统共享提供一种快速且简单的方式。同时,PMML还提供灵活的机制支持多个预言模型的选择和平衡,非常适合于全部学习,部分学习,分布式学习等多种应用场景。PMML基于XML格式,目前己发展到4 2版本,包括标题( header)、数据字典(data dictionary)、数据流(dataflow)、挖掘模式(mining schema)、数据转换( transformations)、预测模型、模型组合定义( ensembles of models)、异常处理规则(rules for exception handling)等内容。数据生成主要用到两个重要组成其一是数据字典,遵循一个或多个挖掘模型,包括name(描述数据集字段名),Optype(字段可操作类型),dataType attributes(重用W3C XML schemaatomic types中的名称和语法)等元素,描述字段类型、操作方式、数据范围等内容,不依赖于具体的挖掘模型其二是挖掘模式( Miningschema),储存字段的值分布规律等特殊信息,根据具体挖掘模型的不同存在区别。目前PMML标准支持决策树、关联规则、聚集、回归、nalve贝叶斯、神经网络、规则集、序列、文本模型、支持向量机等挖掘模型。一个精简了部分内容及格式后的决策树挖掘模式如图2的XML所示。
通过模式探索获得PMML描述的数据模式后,经过描述转换形成能够为数据生成工具直接使用的SDDL文档。SDDL同样基于XML文档格式,能够表达出最大/最小约束、分布约束、公式约束、字典约束、查询数据约束、迭代/重复约束等。这些约束间还能够通过组合形成比较复杂的约束,如迭代/重复约束可以和其它约束组合。图3的XML为这种约束的一个典型的示例。
数据生成工具按照SDDL表达的约束条件实现大量数据的生成。
2 工程实例
某设备管理综合信息系统是一个涉及业务广,功能十分复杂的大型信息系统。系统不仅管理设备终端自动采集数据、业务流转数据,还需要通过对这些数据的分析,为业务机关提供决策支持。在系统正式上线前,必须利用尽量真实的数据对系统进行充分的测试。在该系统中采用模式注入的数据生成方法进行了工程实践,取得了很好的应用效果。
主要步骤如下:
2.1 数据定义分析
根据数据模型分析该系统数据定义,确定数据生成的表范围。按照寿命周期等客观属性,该系统的数据表大致可分为基础数据、业务数据、自动采集数据等大类。其中基础数据主要包括单位、设备、器材等目录代码及一系列的枚举型应用字典,业务数据主要包括各类计划、业务流转过程数据等,自动采集数据主要包括设备、器材自动化测试、环境监控等终端采集的数据。该系统数据划分及部分表示例如图4所示。
2.2 准备真实历史数据
将能够得到的真实数据经预处理后加载到对应的数据表中,作为必要的基础。基础数据变化慢,寿命周期长,有少量的真实数据;业务流程数据变化快,历史积累多,有较多真实数据;自动采集数据同具体对象相关,重点设备及配备量大的设备数据多,一般设备及配备量小的数据少。
2.3 确定数据生成策略
具体分析数据表,在总体上确定各表数据生成的顺序(被引用父表必须在子表数据生成之前生成),确定单表数据生成方式,并通过规范化语言描述,供数据生成工具使用。
2.4 按策略描述生成数据
数据生成工具按照规范化语言描述策略生成数据。规律未知数据的代表如部分设备的测试数据。
2.5 效果分析
某型设备组成件的测试数据历史积累少,难以支撑系统分析测试要求,我们采用了模式注入的方法进行数据生成。该关键件测试数据分为4组22个,其中第一组为Po,第二组为P10~P16,第三组为P20—P26,第四组为P30-P36,表示例如表1所示。
原始数据仅有168条,经过特性继承的方法生成得到798条。原始数据和生成数据在分类及统计特性上具有很好的相似性,如图5所示。
由对比分析可見,通过上述方法生成的设备数据同真实数据具有很大的统计相似性,为某设备管理综合信息系统的用户试用和质量评测提供了很大帮助。
3 结论
本文理论方法和工程实践都表明,模式注入的数据生成方法,是正确的和可行的。通过数据生成能够较好的解决设备使用与保障研究中数据缺少的问题,在一定的场景下具备替换真实数据的能力。
参考文献
[1]J. White,“American Data Set GenerationProgram: Creat ion,
Applications, andSignicance” [D]. ComputerScience andComputer Engineering Dept., Univ. ofArkansas.2005.
[2]黎方正,罗大庸,谢东.一种海量数据生成方法[J]小型微型计算机系统,2009 (12): 2420-2423.
[3]魏伟杰,张斌,王波等,一种用于数据挖掘算法的数据生成方法[J],东北大学学报(自然科学版),2008 (03): 328-331.
猜你喜欢
中国交通信息化(2020年1期)2020-07-27
电力与能源(2017年6期)2017-05-14
信息通信技术(2015年6期)2015-12-26
河南科技(2014年23期)2014-02-27
河南科技(2014年19期)2014-02-27
电子设计工程(2014年18期)2014-02-27
电子设计工程(2014年18期)2014-02-27
智能系统学报(2013年1期)2013-01-28
智能系统学报(2013年2期)2013-01-28
