
一种基于GPU的高性能稀疏卷积神经网络优化*
2018-02-26 10:12邢座程陈顼颢
计算机工程与科学 2018年12期
方 程,邢座程,陈顼颢,张 洋
(国防科技大学计算机学院,湖南长沙410073)
1 引言
CNN(Convolutional Neural Network)目前作为深度学习领域中的一个重要模型,在计算机图像[1]、语音识别[2]、游戏比赛[3]以及机器人[4]等方面都扮演着越来越重要的角色。但是,随着CNN的发展,CNN网络规模和网络层数不断增加,参数规模也变得越来越庞大。1990年,早期的卷积神经网络模型用于手写识别使用的参数数量不到100M[5]。20 年后,AlexNet[1]和 VGG[6]分别使用了61M和138M个参数来对1 000个图像进行分类。显而易见,这对CNN实现过程中的硬件资源、网络结构、算法优化等各方面都会产生诸多的挑战。CNN 加速[7]、CNN 参数的量化分析与研究[8]、参数规模的缩小与权重删减[9-12]都将成为热门的研究方向。
为了应对CNN对计算需求量的不断增加,采用高性能的 GPU 已经成为加速 CNN[13,14]的一项重要措施。此外还有研究给出了压缩CNN的解决方案。压缩CNN方法主要分为两类:一类是基于分解[15,16],另一类是基于删减[17,18]。基于删减的方法是在保证网络训练和测试结果精确度[8]没有损失的前提下减少参数数量。权重删减下的深度压缩[9,10]方式能够使 AlexNet和 VGG-16 的参数规模分别缩小9倍和13倍,在CPU和GPU的架构下实现了3~4倍的加速。但是,权重删减的性能提升远远落后于实际减少乘累加操作的性能提升,特别是在GPU的硬件设备上,这一类似的性能损失经常发生。同时,有研究提出了全新的直接稀疏卷积算法[19],它在CPU的架构下相比原有的稠密算法在AlexNet卷积层上实现了3.1×~7.3×的加速。对于训练好的CNN来说,卷积层的卷积运算是测试过程运行时间最主要的部分。所以,对卷积层的卷积运算优化成为解决该加速优化问题中的关键路径。
由于权重删减的方式牺牲了数据的规则性,SCNN(Sparse Convolutional Neural Network)内部产生了大量的稀疏计算成分。稀疏数据处理与GPU体系结构特性不匹配[20]。原有GPU架构下对卷积核提供卷积数学运算的cuBLAS和cuSPARSE并不能很好地应对这种不匹配。同时,GPU和CPU在体系结构上存在的差异使得很多针对CPU优化的稀疏卷积算法并不能在GPU上适用。我们采用了一个高效的直接稀疏卷积算法,对其在GPU的平台上进行优化,从而解决权重删减产生稀疏数据所带来的性能损失。
本篇论文主要贡献在以下几点:
(1)针对卷积层关键优化路径上完成直接稀疏卷积算法[19]在GPU架构上的并行化实现,打破GPU上采用传统稠密算法的局限性,给出了一种可行且高效的GPU加速SCNN方案。
(2)采用最大限度的线程映射,充分利用GPU的硬件计算资源,防止产生稀疏结构运算对GPU计算资源的浪费。
(3)采用最优的任务调度,合理安排每个单线程的任务工作,减少线程同步过程中某一部分线程等待时间,提高资源利用率。
(4)充分利用直接稀疏卷积算法数据处理过程中的数据局部性,增加数据复用,对于同一block下的所有线程,采用共享内存来减少数据访存时间。
最终我们在CAFFE(Convolutional Architecture for Fast Feature Embedding)架构下所实现的稀疏卷积神经网络,对同一训练好的 AlexNet、GoogleNet、ResNet,在 GPU GTX1060 上,与 CAFFE本身搭建的由cuBLAS和cuSPARSE所提供的数学库支持的卷积层进行测试对比。相比cuBLAS的实现,我们在 AlexNet、GoogleNet、ResNet上性能提升分别达到1.07 × ~1.23 ×、1.17 × ~3.51 ×、1.32×~5.00×的加速比。相比cuSPARSE的实现,在 AlexNet、GoogleNet、ResNet上性能提升分别达到1.31 × ~1.42 ×、1.09 × ~2.00 ×、1.07 × ~3.22×的加速比。
2 背景
这一节介绍实现卷积运算的几种方式,并说明了它们各自的局限性,从而阐述本文的研究意义和研究背景。
2.1 降维方式
目前很多CNN卷积层的卷积操作都是通过降维方式实现的[18]。图1所示是一个简单的用降维方式实现卷积的例子,图中参数可参考表1。
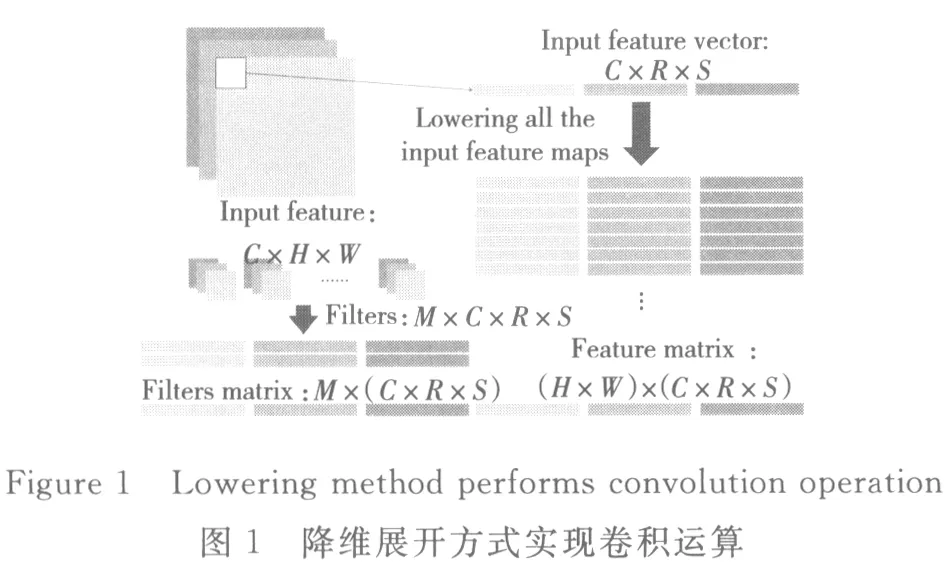
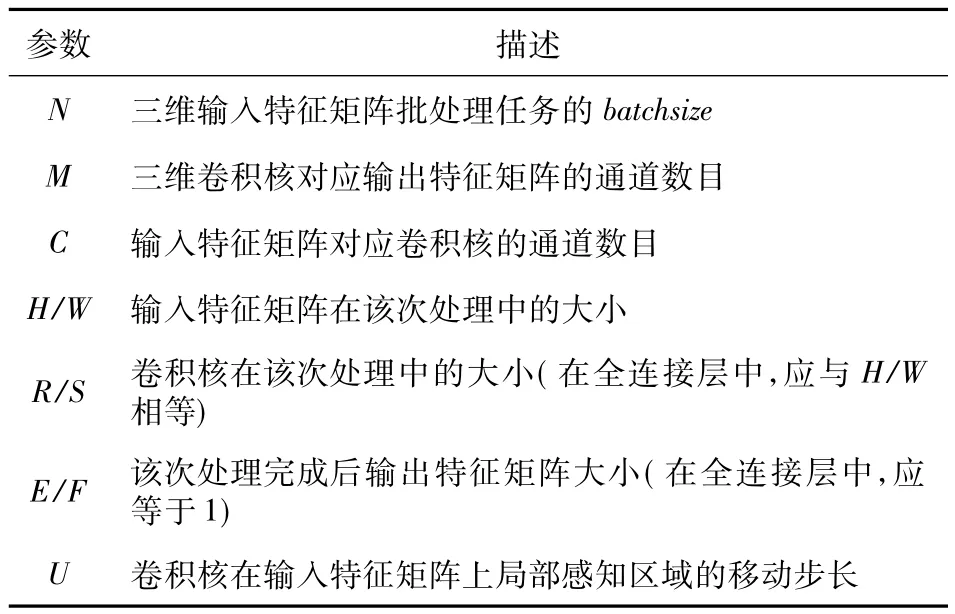
Table 1 Description of convolution parameters表1 卷积参数描述
假设输入特征矩阵的batchsize为1,其输入通道数为C,输入特征矩阵大小为H×W,预输出通道数为M,每一个卷积核的实际大小为R×S(在实际应用中,可以通过设置步长U来控制卷积核在输入特征矩阵上的局部感知区域的位置,后文我们假设U默认为1)。那么一共有M个卷积核,每个卷积核包含C个通道。降维方式通过将输入特征矩阵和卷积核分别以行展开的方式生成新的特征矩阵Ilowering和卷积核矩阵Wlowering。那么,最终卷积的计算过程可以表示为:
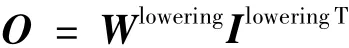
降维方式将卷积运算转换为矩阵乘法。在基础线性代数子程序库BLAS(Basic Linear Algebra Subprograms)中,GEMM(GEneralized Matrix Multiplication)的函数接口实现了两个稠密矩阵的乘法运算。在CAFFE的框架下,CNN卷积层中卷积运算所采用的方式也是降维方式,具体是通过im2col函数和GEMM函数实现。此外,CAFFE还支持了CUDA版本下由cuBLAS所提供的GPU架构下并行实现的降维方式。
在降维方式展开生成新的特征矩阵Ilowering的过程中,卷积核所感知的局部区域重叠部分的元素都进行了多次重复复制,增加了存储开销。特别是在SCNN中,这种大量的数据重复复制浪费了大量的存储资源。此外,GEMM是针对稠密矩阵实现的矩阵乘法,对于处理稀疏矩阵浪费了GPU大量的计算资源。所以,我们需要一个针对GPU实现的稀疏卷积运算。
2.2 直接稀疏卷积
直接稀疏卷积(Direct Sparse Convolutions)作为一种全新的卷积方式在2017年的ICLR会议上被首次提出[19]。该算法在CPU的架构下相比原有的算法在AlexNet卷积层上实现了3.1×~7.3×的加速。
相比降维方式,直接稀疏卷积去除了输入特征矩阵中的数据重复复制。该算法将卷积核矩阵的规模扩展到输入矩阵的相同大小。对于延展后的卷积核行展开生成向量Wm,其长度为C×H×W。由于有M个卷积核,对每一个卷积核进行延展后得到了M×(C×H×W)的权重矩阵。对于该批次任务下的输入矩阵以行展开的方式形成列向量I,其长度为C×H×W。那么,在计算卷积的过程中,对于不同感知区域的元素可以通过调整向量I的起始指针,使得卷积核映射到正确的局部区域。其具体算法如图2所示。
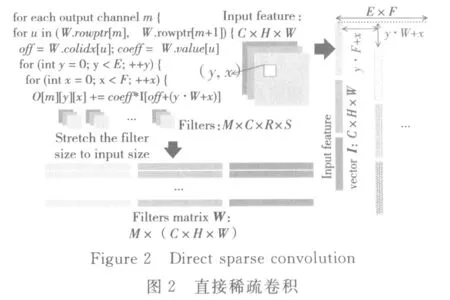
该批次任务下,直接稀疏卷积结果可以表示为:Om=Wm·Ivirtual。其中矩阵Ivirtual是由列向量I调整起始指针所得到的。那么,我们可以进一步简化结果为:Om,y,x=Wm·Iy·W+x。所有输出通道下的稀疏向量Wm构成稀疏矩阵WSparse,采用行压缩存储CSR(Compressed Spares Row)格式,存储如图3所示。数组value记录矩阵Wsparse中的非零元素。数组colidx记录每个非零元素在矩阵Wsparse中的列指针。数组rowptr记录矩阵Wsparse中每一行起始元素在value中的指针。
直接稀疏卷积将卷积运算抽象成稀疏向量Wm对稠密向量Iy·W+x的内积。此外,由于 SCNN采用CSR或CSC(Compressed Sparse Column)的稀疏数据存储格式,对于运算过程中的延展实际上并没有增加存储开销,只是调整了矩阵中非零元素的行列指针。相比降维方式,直接稀疏卷积更适合在GPU上实现SCNN。

3 设计与实现
本节介绍本文所提方法的具体实现和优化。由于权重删减后SCNN产生了大量稀疏数据结构,而传统的降维方式并不能保证稀疏矩阵卷积的计算性能,本文采用全新的直接稀疏卷积来替代降维方式,弥补性能损失。除此以外,GPU的体系结构特征需要在实现过程中对线程映射、任务分配以及内存管理进行更多的考虑和优化。
3.1 概述
直接稀疏卷积的实现主要由两部分组成:(1)数据预处理,主要完成对卷积核矩阵的延展,生成稀疏向量Wm和稠密向量I;(2)计算过程,主要完成所有的MAC操作,并准确更新计算过程中的指针。
第(1)部分如图4所示。在这里,权重矩阵为M×(C×R×S)的稀疏矩阵,按照CSR格式存储于物理内存中。对于输出通道m中的第j个非零元素(c,y,x)有:

其中col=colidx[j]。那么,延展后的权重矩阵大小为M ×(C ×H ×W),同一个非零元素(c,y,x)的CSR格式存储下的列指针更新为:colidx[j]=(c*H+y)*W+x。
直接稀疏卷积的计算过程可以表示为:Om,y,x=Wm·Iy·W+x。其核心在于实现稀疏向量Wm与稠密向量Iy·W+x的内积运算。对于计算输出矩阵中的点(m,y,x),需要完成的MAC操作数取决于稀疏向量Wm的非零元素数目。由于对同一输出通道m中的所有点,稀疏向量Wm是恒定不变的,所以计算这些输出节点所需要的MAC操作数相等。在直接稀疏卷积算法中矩阵Ivirtual是由向量I生成,其中每一个列向量Iy·W+x的起始指针所指向的元素为I[y·W+x]。根据这一特点,我们仅将向量I的元素常驻内存,而不是存储整个稠密矩阵Ivirtual。

考虑到实际的CNN模型中,所有卷积层经过权重删减后的稀疏度存在差异,我们通过下列方式来计算当前卷积层的稀疏度:

其中,Nnonzero为当前卷积层的所有非零元素数目,M为当前卷积层输出通道数,kernel_size为卷积核规模大小。
对于不同稀疏度的卷积层,我们设置一个阈值。稀疏度大于该阈值的卷积层采用优化后的直接稀疏卷积方式,小于该阈值的卷积层则仍采用原有的降维方式。对于稠密数据和稀疏数据的分别处理,使得对于任意稀疏度的卷积层都能够实现最佳的计算性能,可以最大限度提高整个网络的运行性能。由于在最终实验过程中采用了IntelSkimcaffe开源项目(https://github.com/IntelLabs/Skim-Caffe)中的稀疏CNN网络结构,CNN中的卷积层的稀疏度集中在0和0.7~0.96这两个区域,所以设置阈值仅仅是排除了稀疏度为0的稠密层。
3.2 并行策略
相比CPU,GPU拥有更多的处理核心,如何合理分配和充分利用这些处理核心是本文设计的关键。接下来我们将分别介绍直接稀疏卷积两个过程的并行策略。
对于过程一,即图5中所示oc=m时所有非零元素的列指针更新。
将整个权重矩阵进行延展就是更新权重矩阵内所有非零元素的列指针colidx。那么,我们设置线程Threadm完成稀疏向量Wm内所有非零元素的列指针更新。

对于过程二,每一个线程计算输出特征矩阵中的一个点(m,y,x),如图5所示。由于输入特征矩阵Ivirtual中每一列向量是由稠密列向量I移动初始指针得到的,那么我们将稠密列向量I的所有数据常驻内存。当需要计算不同的输出点(m,y,x)时,计算其对应列向量 Iy·W+x相对向量 I的偏移量pos,其计算公式为:pos=y·W+x。通过对向量I的初始指针增加pos偏移量得到对应向量Iy·W+x:*inputptr=input+pos。该过程避免了数据的重复复制,仅通过调整指针来完成当前输出通道的全部计算。由于Wsparse作为稀疏矩阵采用CSR的格式存储在物理内存中,第m个卷积核下所有非零元素对应存储在rowptr[m]行。该行元素在物理内存中存储非零元素的一维数组value中的起始位置为 row_strat(row_start=rowptr[m]),结束位置为row_end(row_end=rowptr[m+1])。那么,对于线程 Thread(z,y,x),需要完成下列计算:
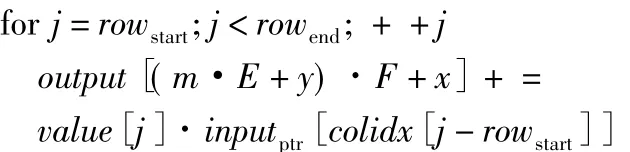
输出点(m,y,x)与线程 Thread(z,y,x)一一对应。
通过分别对过程一和过程二实现并行化,我们在GPU的架构下实现了直接稀疏卷积。在实际的测试中,这一实现的具体性能并没有达到预期效果(这一点将在第4节具体说明)。所以,接下来增加了对数据局部性的考虑,对实现的并行策略进行了进一步优化。
3.3 局部性优化
由于输入特征向量的数据复用,我们采用了Ivirtual的方式来减小带宽需求。通过更改访存指针来读取向量I中的值。同样地,为了增加Cache块的命中率,希望优先计算同一输出通道的值。由于实际测试性能达不到预期效果,我们增加了共享内存优化的版本,其具体映射规则如图6所示。
对于输出通道m,需要E×F个线程来完成计算任务。但是在实际情况中,GPU所能设置的最大block_size小于E×F,所以对于同一个block内的所有线程会在短时间内经常访问向量Wm,直到该block内的所有线程完成计算。此时内存常驻的数据仅仅只有向量I和向量Wm。

由于同一个block下的所有线程都要求对Wm进行数据访问,我们将Wm放入共享内存中,以减少Wm的数据访存时间。共享内存对于同一block块下的线程是共同可见的。考虑到GPU内共享内存大小的限制,将Wm分块化,块Tilei为特定长度的一维数组。将Tilei的长度设定为block下的线程总数,并使Tilei包含的数据能够常驻共享内存。由于Wm采用CSR格式存储,那么仅需将对应数组value和数组colidx的值存入共享内存。在计算输出结果前,需要将Tilei对应的value和colidx写入共享内存中的数组valueshared和数组colidxshared。由于 Tilei长度与线程数相等,那么对于线程Thread(z,y,x)需要完成的读写工作如下所示:
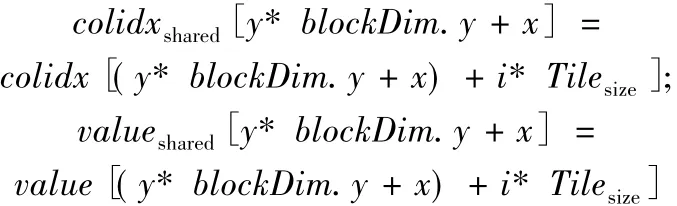
每个线程只需要将Tilei块内一个元素的value和colidx数组值写入共享内存。其中,blockDim.y为GPU线程设置中block块在y方向上的维度大小,Tilesize为设置的Tile块的长度。
为了防止读后写,为同一block下的所有线程增加同步操作。线程 Thread(z,y,x)将 Tilei数据写入共享内存后进行等待,直到所有线程完成操作。当block 块内所有线程完成同步后,线程 Thread(z,y,x)需要完成共享内存内向量Tilei与向量Iy·W+x的内积运算。其具体计算如下所示:
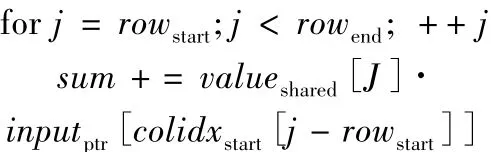
每一次累加操作后同步线程,当访问共享内存未命中时,替换下一个Tile块到共享内存。将每个块替换下来的部分和保存在寄存器sum中,这样当下一个块被换进共享内存时,线程能够正常工作。当输出通道m所有Tile块都被替换过后,将部分和sum输出:output[(m·E+y)·F+x]=sum。输出点(m,y,x)与线程 Thread(z,y,x)的映射关系与之前的一样。
通过增加共享内存以及对数据局部性的考虑,实验结果最终达到了预期性能。相比未优化的直接稀疏卷积,本文在GPU上实现了更为高效的性能。
4 性能评估
4.1 总体性能
实验采用的GPU型号为GTX 1060 3 GB。设置稀疏度阈值为0.6,batchsize为128。训练好的AlexNet模型包含5层卷积层,每层的稀疏度根据公式计算的结果如表2所示。

Table 2 Parameters of AlexNet convolution layers表2 AlexNet卷积层参数
对稀疏度大于0.6 的 CONV2、CONV3、CONV4和CONV5四个卷积层采用直接稀疏卷积的方式。设置一个block块下的总线程数为1 024,那么每次替换进共享内存的Tile块长度为1 024。实验结果记录了50 000次迭代中每一次迭代完成Forward过程所需的时间,每100次迭代的Forward执行时间取平均值,具体结果如图7所示。其中Base为未优化初始版本的执行时间曲线,Tiled为增加共享内存优化后版本的执行时间曲线。

Tiled版本相比Base版本在各层上都有较大的性能提升。在各层上Tiled版本的性能分别提升了 46.7%、41.1%、41.5%、42.6%。这说明本文的优化在GPU架构上起到了实质性作用。通过增加共享内存,合理分配线程,增加数据复用,在GPU架构上实现直接稀疏卷积,实现了高效的稀疏卷积神经网络优化。本文采用的直接稀疏卷积并行方式适应了GPU的体系结构特征,充分利用了硬件计算资源。为了进一步说明本文设计性能的优越性,将在4.2小节与现有的CNN卷积层实现进行性能对比。
4.2 执行时间分析
为了进一步说明优化后的性能提升,在Alex-Net模型基础上对比本文的设计与原有CAFFE框架下所实现的卷积神经网络。CAFFE通过cu-BLAS提供的函数接口在GPU上主要实现了降维。cuBLAS是在GPU上实现的CUDA数学函数库。此外,CAFFE还采用了cuSPARSE库来优化处理稀疏卷积。给出了batchsize为64时的AlexNet模型各层执行时间对比,如图8所示。

同样地,只列出了AlexNet中稀疏度大于0.6的四个卷积层以及它们的总执行时间。从图8可以看到,相比cuBLAS实现方法,本文的优化方法仅在CONV2上有略微的性能损失,而在CONV3、CONV4、CONV5上的性能分别提升了41.1%、26.2%、40.1%,且总体性能提升了10%;相比 cuSPARSE实现方法,本文的优化方法在 CONV2、CONV3、CONV4、CONV5上的性能分别提升了29.6%、39.2%、47.1%、67.4%,且总体性能提升了41.1%。通过分析表2给出了未删减前AlexNet各层结构参数,包括输入特征矩阵大小、卷积核大小以及稀疏度。而对于 CONV3、CONV4、CONV5这三层来说,其稀疏度均高于CONV2的稀疏度,从而证明了本文的设计针对大规模高稀疏度数据有显著优化效果。此外,图9给出了不同batchsize下AlexNet各层的加速比。相比cuBLAS,本文的优化方法在batchsize为192时得到了最佳的加速比;相比cuSPARSE,当batchsize在32~64时性能最佳,从网络整体性能来看,batchsize为64时加速性能最佳。这是由于batchsize过小或过大都会使在线负载任务过轻或过重,不能合理利用硬件计算资源。

本文还对GoogleNet和ResNet模型进行了测试,同样也只给出了稀疏度大于0.6的卷积层的加速比,如图10所示。
对于 GoogleNet,相比 cuBLAS,本文优化方法仅在低维度有1层性能有略微的损失,其余高维度稀疏层实现了 1.17× ~3.51×加速;相比 cuSPARSE,本文优化方法仅在高维度和低维度各出现了1层性能损失,其余各层实现了1.09×~2.00×加速;在总体性能上,相比cuBLAS和cuSPARSE的方式分别实现了1.34×和1.21×加速。对于ResNet,相比cuBLAS,本文优化方法在所有稀疏层实现了1.32× ~5.00×加速;相比 cuSPARSE,本文优化方法仅在高维度出现了2层性能损失,其余各层实现了1.07×~3.22×加速;在总体性能上,相比cuBLAS和cuSPARSE的方式分别实现了2.43×和1.97×加速。
移动学习中学习评价是在网络课程学习的过程中对学生的学习过程和学习结果进行价值判断的过程[5]。移动学习评价设计的缺失和无效已经成为制约网络课程发挥实际效力的关键因素。54.5%的学生希望针对移动学习进行学习评价。移动学习可以通过在线反馈获取学生的学习评价,Bb平台提供给学生多种学习反馈方式,学生反映不一。58.6%的学生希望可以看到每题得分和总成绩,通过每题的得分状况,对自己掌握的知识进行针对性的学习;33.8%的学生需要教师评语,教师评语可以更加直观、深入的评价学生测试中的问题,便于学生理解与反思。
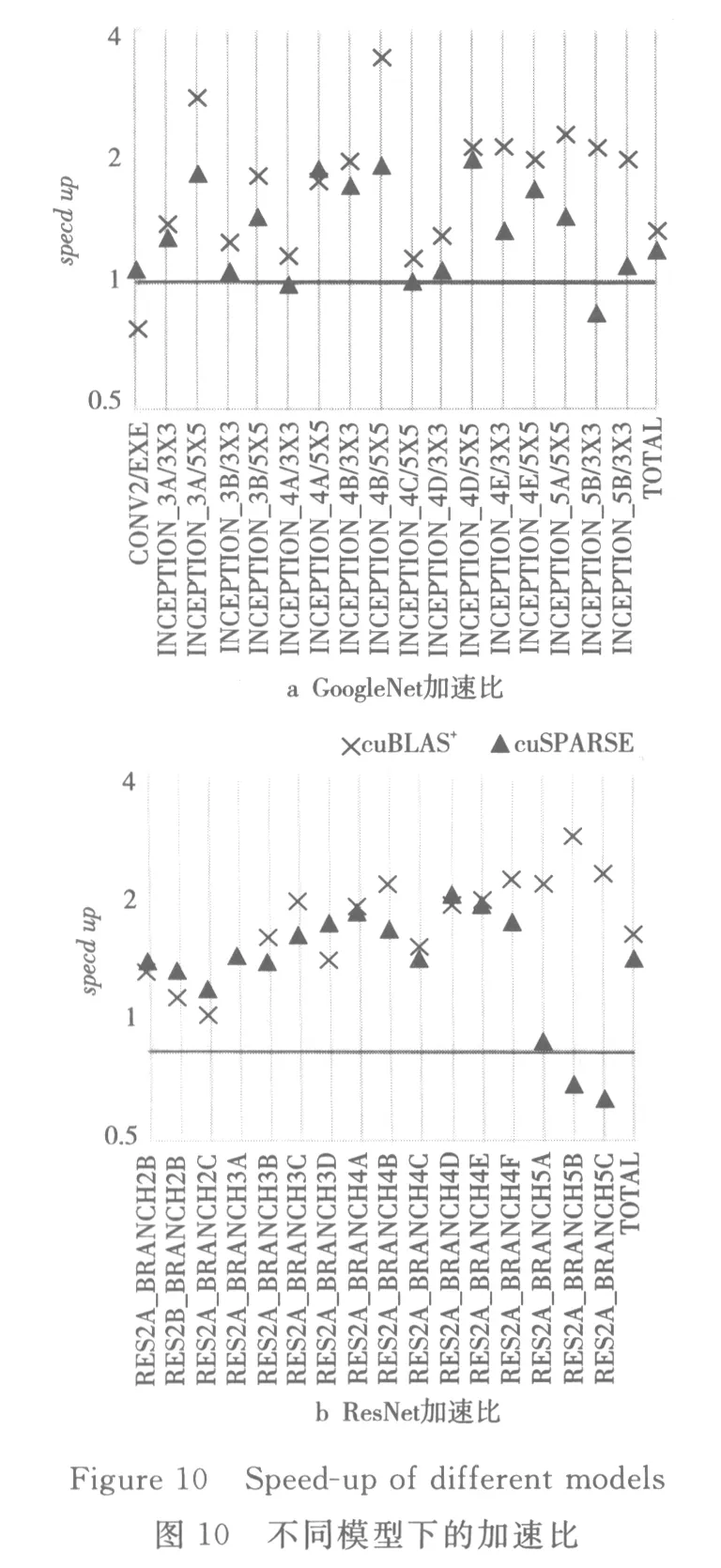
由于各层删减后的数据规则性也会对实验结果产生一定的影响,所以在本文优化方案的测试结果中也出现了某些层的性能损失。但是,相比cu-BLAS和cuSPARSE,本文方法对高稀疏度层的优化加速效果显著。总体来说,本文优化方法实现了基于GPU架构的SCNN加速优化。
5 相关工作
相比传统意义上GPU加速CNN的实现方案[13,14],本文采用更优的数学内核和卷积运算算法,提高了整个系统的可优化程度。相比其他采用更合理的删减方式来切合GPU硬件特性[20]的加速方案,本文所提供的加速方案具有更好的可移植性和可靠性,对数据预处理的消耗小。此外,在文献[21]所提出的Escort优化版本上,本文改进了并行策略和映射规则,取得了更高的加速比。
6 结束语
本文通过在GPU上实现直接稀疏卷积算法,打破了GPU架构下传统稠密算法对于稀疏结构处理的局限性,有效解决了权重删减后SCNN在GPU上运行出现性能损失的问题。对于高稀疏度,甚至是GPU所不擅长处理的不规则数据,本文的设计仍然有着极大的优势。相比CAFEE下cuBLAS的实现,本文方法在 AlexNet、GoogleNet、ResNet上的性能提升分别达到 1.07× ~1.23 ×、1.17× ~3.51×、1.32 × ~ 5.00 ×。相比 cuSPARSE 的实现,本文方法在 AlexNet、GoogleNet、ResNet上的性能提升分别达到1.31× ~1.42×、1.09 × ~2.00 ×、1.07 × ~3.22 ×。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
山西电子技术(2021年3期)2021-06-28
软件学报(2020年6期)2020-09-23
电子制作(2019年13期)2020-01-14
网络安全技术与应用(2020年1期)2020-01-07
通信技术(2019年9期)2019-10-09
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
广东第二课堂·小学(2017年9期)2017-09-28
软件工程(2014年3期)2014-03-15
