
RPRU:一种面向处理器的比特抽取与移位统一架构
2018-03-13 05:00戴紫彬南龙梅
计算机研究与发展 2018年2期
马 超 戴紫彬 李 伟 南龙梅 金 羽
1(国家高性能集成电路(上海)设计中心 上海 201204)2(解放军信息工程大学 郑州 450001)3(集成电路国家重点实验室(复旦大学) 上海 200433)(wenlu_ma@163.com)

Fig. 1 8-bit Inverse Butterfly network图1 8-bit Inverse Butterfly网络
循环移位与比特抽取这2种操作被广泛应用于密码编码学、图像处理、多媒体应用以及生物统计学[1-4]等众多领域.如在密码学中,为了增加明文的“扩散”程度,AES(advanced encryption standard),LED(light encryption device)等大多数密码算法均使用到了这2种细粒度位级操作,以提升密码算法的安全性[5-6].然而,目前它们在通用处理器中的硬件设计策略大多采用孤立的方式,构造各自专用的硬件单元[7].其中循环移位操作多基于桶型移位器、对数移位器实现[8],比特抽取操作多基于组合排序网络[9]、多级动态互连网络Inverse Butterfly实现[10].
然而循环移位与比特抽取操作都涉及到数据位置的重新排列,能够利用位级置换实现.若将它们彼此孤立设计,必将造成硬件资源的重复开销[11].因此Hilewitz等人[12]提出了一种基于Inverse Butterfly网络的移位-抽取单元,该单元首次将循环移位和复杂比特抽取这2种不同操作,统一在了同一网络架构下.其中比特抽取操作由于实际应用的广泛性,而被Intel在2013年发布的Haswell处理器指令集所支持[13].Chang等人[14]在Lee等人的基础上对循环移位路由信息生成算法进行了改进,提出了具有高度并行化特征的路由信息生成算法,大幅提升了循环移位操作在Inverse Butterfly网络中的实现性能.然而,尽管Hilewitz等人将循环移位和比特抽取操作统一在了一个架构下,但针对这2种操作却设计了各自独立的路由算法.因此该单元在硬件实现时,就必须对应2套完全不同的路由算法生成电路,这在一定程度上增加了硬件设计的复杂性,消耗了处理器中宝贵的硬件资源.Chang等人虽然在一定程度上提升了循环移位操作的处理性能,但其并行化的路由算法只针对循环移位操作,其实质是对文献[12]中循环移位路由算法的一种改进,该单元若要支持比特抽取操作,则必须在硬件中增加相应地路由算法电路,这仍然需要消耗额外的硬件资源.
因此,本文通过深入分析Inverse Butterfly网络的拓扑结构及数据流特征,提出了一种能够同时支持循环移位和比特抽取的统一路由信息生成算法.该算法不仅并行度高,硬件实现简洁,而且它还将这2种不同位级操作实现了从架构统一到路由算法统一的跨越.
1 相关研究
图1描述了一个8-bit位宽的Inverse Butterfly动态互连网络(N=8),它可以通过改变各级开关状态实现不同结点之间的连接,使系统具有自重构能力,从而灵活地完成数据的重新排列[15].该网络有lgN级从上到下依次为第1级、第2级、第3级,每一级由N2个2输入交叉开关构成.每一个交叉开关由2个2选1数据选择器组成,网络一共有2N2×lg N种置换结果.数据在进入Inverse Butterfly网络各级前以2i-1-bit(i为级数)为间距进行两两分组,形成2-bit数据对.然后将分组后的数据对输入到2输入交叉开关中,再通过适当的路由算法来配置各交叉开关状态,从而完成某些特定置换操作.从图1左边的数据流图中还可以看出,网络第i级有N/2i个位宽为2i-bit的子蝶网络,从左至右依次为Subi-ibfly1~Subi-ibflyN/2i,且各子蝶网络中数据不发生任何交互.例如当i=1时,网络第1级有4个位宽为2-bit的子蝶网络,从左至右依次为Sub1-ibfly1~Sub1-ifbly4,各子蝶网络中数据没有交互通路.若把该网络最后1级舍弃,剩下的部分可以看成2个独立的以N/2-bit为位宽的Inverse Butterfly,它与N-bit位宽的Inverse Butterfly结构相似只是规模较小,因此该网络拓扑结构具有迭代和递归特性.
比特抽取操作(parallel bit extract, PEX)是将控制序列R3中为“1”的控制位对应在序列R2中的数据并行地抽取出来依次排在目的序列R1的最右侧,同时将无关数据置“0”,从而并行地提取出后续操作所需的比特数据,如图2所示.由于控制序列R3(假设为N-bit)取值范围广泛,共有2N种,因此并行抽取操作硬件实现较为复杂.Lee等人[16]最早提出了基于组合逻辑实现比特抽取的方案,该方案硬件实现资源消耗极高,且电路延迟较大.Dimitrakopoulos等人[17]随后又基于增强型归并排序网络提出了一种硬件资源消耗较低的比特抽取硬件单元,但该单元仅能够实现比特抽取操作,不具有功能扩展性.Hilewitz等人[18]通过研究比特抽取在Inverse Butterfly网络的实现原理,提出了基于该网络的比特抽取路由信息生成算法,并构建了基于该网络的比特抽取硬件单元.该单元与ALU的延迟和面积相差无几,且操作数类型为“2源1目的”形式,因此使其具备集成于通用处理器内部的条件,如图2中右半部分所示.

Fig. 2 Functions and implementation of PEX instruction图2 PEX指令功能及硬件实现

Fig. 3 Evolution of traditional rotation shifter图3 传统移位器的发展趋势
循环移位操作(rotation)主要基于对数移位器实现,其结构如图3(a)所示.一个N-bit输入的数据,共有lgN级每级有N个2选1数据器,数据在每一级可以按照2的幂指数进行移位或保持不变.该结构的优点是移位位数S的二进制数(slg N-1,slg N-2,…,s0)可直接作为lgN级开关的控制信号,电路面积小且移位处理速率高;缺点是移位模式单一,只能实现固定位宽的循环左移或右移操作.Hilewitz等人在文献[12]中首次提出了基于Inverse Butterfly网络的循环移位路由信息生成算法,将传统移位操作与复杂比特抽取操作的硬件功能单元统一在了一个架构下,为可重构复杂移位器的发展提供一条新思路,如图3(b)所示.
由上述分析可知,比特抽取和循环移位这2种不同位操作,已经从以往孤立的设计方法过度到统一架构下的可重构实现方案,这种研究思路的转变有效地降低了原架构的资源消耗.然而,该方案在硬件设计时仍然需要2套不同的路由算法生成电路,硬件电路开销具有可减少的可能.下面,本文将重点研究这2种操作在Inverse Butterfly网络中数据在网络各级的流动特点,进而提取出它们之间的共性逻辑.使这2种操作不仅能够在一个架构下实现,而且路由算法也能共享,以达到进一步节省资源的目的.

Fig. 4 Shift rules of special pairs under switch state “through”图4 直通状态下特殊对移位规律
2 统一路由算法研究
2.1 循环移位与比特抽取操作实现原理
性质1. 在Butterfly网络的第i级,有2i-1个位宽为w=N/2i-1的子蝶网络,若将各子蝶网络中初始输入数据(位宽为w=N/2i-1)循环左移S-bit,那么通过调整初始路由控制信息,其相应的初始输出数据能够以左、右2个部分(位宽为w/2-bit)分别完成S-bit循环左移位.
证明. 选取任意一个在第i级的子蝶网络为例,如图4(a)所示.该子蝶网络数据位宽为w-bit,且初始由信息为全“0”即所有开关为直通状态.当初始输入数据以w为位宽循环左移1位时,图4(b)中左半部分的初始输入数据(上层灰色方块部分)中最高位(w-1)将被移位到右半部分的最低位,同时右半部分中的最高位数据(w2-1)将越过子蝶网络的中线到左半部分的最低位,其余数据仅左移1位并没有改变其初始所属的部分.本文将左、右2部分中最高位bit数据组成1个特殊对,如图4(b)中虚线圆框所示.它们不仅被同一个路由信息控制且在循环移位时它们都将跨越网络边界,到达对方初始所属的部分中.若初始控制信息序列也随着初始输入数据循环左移1位从“00…00”→“0…000”,那么特殊对的输出数据将对调彼此原属的部分,如图4(c)所示.与图4(b)的初始输出数据相比,仅有特殊对彼此调换了原有所属的部分,其余的初始输出数据仅仅是左移1位.处于i级的输入数据对,能够在相应路由控制信息的作用下,完成彼此原有位置的互换或者保持原状.若将图4(b)中特殊对所对应的路由控制信息取反即“0001”,那么该特殊对将重新回到原来所属的部分中的最低位,且输出序列相当于初始输出序列从中间分成左右2个部分,各部分内数据循环左移1位的结果,如图4(d)所示.
若该网络再完成1次1-bit循环左移,初始输入的下一对数据将成为特殊对即(w-2)与(w2-2).当输入数据序列循环左移S-bit时,特殊对依次向后传递.相应地需要将初始路由控制序列循环移S位,同时保证每1次移位后末位路由控制信息取反,那么其输出数据的结果相当于初始输出数据分别以左、右2个部分各自循环左移S位的结果.当特殊对初始路由状态为“1”时,与“0”情况相似,将其数值取反即可.
证毕.
性质2. 若N-bit数据M={aN-1,aN-2,…,a0}1次通过Butterfly网络实现了初始置换P:M→F,其中F={a0,aN-1,…,aN-2},记
那么通过调整该网络的初始路由控制信息,它还能够实现置换P′:M′→F,其中M′是数据序列M循环左移位S-bit(0≤S≤N)的结果.
证明. 根据性质1可知,若将图5(a)中N-bit初始输入数据(initial inputs)循环左移S位,那么通过调整网络第1级的初始路由信息,其初始输出数据能够分别以左、右2个部分(位宽为N2-bit)完成S-bit循环左移位,如图5(b)中第1级输出数据所示.Butterfly网络是一种迭代递归网络,若分别将初始置换网络第2级的2个以N2-bit为位宽的子蝶网络初始输入数据(相当于第1级的输出数据)循环左移S位.根据性质1可知,其相应的初始输出数据则能够以左、右2个部分(位宽为N4-bit)分别完成S-bit循环左移,如图5(b)中第2级所示.依此类推,直到Butterfly网络最后1级(第lgN级),该级共有N2个子蝶网络(位宽为2-bit).当初始输入数据循环移位S-bit时,根据性质1可知,其输出数据将以1-bit为位宽进行循环左移S位,这恒等于初始输出数据,如图5(b)中最后1级输出所示.因此一个能够基于Butterfly网络实现初始置换P(M→F)的M序列,其循环移位S后所得的序列M′能够实现置换P′:M′→F.
证毕.

Fig. 5 Implementation principles of permutation-rotation operations图5 置换-移位实现原理
1) 循环移位原理
Inverse Butterfly网络是Butterfly网络的逆结构,若数据序列(input data)从图5(b)中Butterfly网络最后1级向第1级流动,则可得出:
推论1. 若N-bit数据M={aN-1,aN-2,…,a0}1次通过Inverse Butterfly网络实现置换P:M→F,其中F={a0,aN-1,…,aN-2},记
那么通过调整初始路由信息该网络还能够实现置换结果的移位操作记P′:M→F′,其中F′是数据序列F循环移位S-bit(0≤S≤N)的结果.
特别地,当初始置换P为恒等置换时(各级初始控制信息全为0),则初始输入数据与初始输出数据相等(M=F).且根据推论1可知,通过调整网络初始路由控制信息,它还能够实现从M到M′的移位置换,其中M′是M循环移位S的结果.因此,Inverse Butterfly网络能够支持循环移位操作.
2) 比特抽取原理
比特抽取操作是根据序列R3中“1”的位置,完成对序列R2中比特数据的并行抽取操作,本文将分析基于Inverse Butterfly网络实现比特抽取操作的原理,并提取出与循环移位操作在该网络实现时的共性环节,为统一路由算法的设计提供理论依据.
推论2.N-bit数据的并行比特抽取操作能够1次通过Inverse Butterfly网络实现.
证明. 本文以Inverse Butterfly网络的拓扑迭代结构作为研究基础,采用数学归纳法对推论2进行证明.
设i为N-bit Inverse Butterfly 网络的级数(1≤i≤n,n=lgN).
① 当i=1时,N-bit(N=8)数据被分成独立的N2个以1-bit为间隔的数据对,如图6所示.相邻的2-bit数据对(A,B)进行比特抽取操作时共有4种情况:图6(a)表明2-bit数据A,B都需要被抽取,对应的控制序列R3为“11”;图6(b) 表明2-bit数据A,B仅高位数据需要被抽取,对应的控制序列R3为“10”;图6(c)表明2-bit数据A,B仅低位需要被抽取,对应的控制序列R3为“01”;图6(d)表明2-bit数据A,B都不需要被抽取,对应的控制序列R3为“00”.从图6各交叉开关中控制信息Sel可以看出,通过合理配置各开关的状态,该级网络即可完成比特抽取操作.因此,当i=1时,N-bit Inverse Butterfly网络的第1级能够并行地完成N2个比特抽取操作;

Fig. 6 PEX operations map to stage 1图6 PEX指令在网络第1级的映射情况
② 假设当i=lgN-1时,2个以N/2-bit为位宽的前lgN-1级子蝶网络已经完成了比特抽取操作;
③ 那么,需要证明当i=lgN时,该网络能够完成以N-bit为位宽的比特抽取操作即可.
根据假设②,将图7中左边lgN-1级子蝶网络最终输出的抽取序列用X代替.同时,将右边lgN-1级子蝶网络输出的抽取序列用Y代替.为了在网络最后1级完成2个在第lgN-1级中被抽取序列X,Y的合并,并将合并后的序列置于输出序列的末位.那么该网络必须能够同时完成2种操作:i)对左边子蝶网络的输出序列X,进行循环左移Y位的调整操作.这样调整后左边子蝶网络的数据块X,才能与右边子蝶网络被抽取的数据块Y不处在同一个分组内即不会出现路由控制信息冲突.因为在该网络第lgN级,数据将以N/2-bit为间距构成数据对.ii)当左边子蝶网络完成循环移位调整后,需要与右边子蝶网络中的无关数据块I(位宽与X相等,且与Y相邻)进行交叉换位操作,以完成整个N-bit抽取操作.
下面,对这2种操作在Inverse Butterfly网络实现的可行性进行详细分析:第1个操作中的移位位数Y可以根据右边子蝶网络中控制序列R3中“1”的个数确定.同时根据推论1可知,Inverse Butterfly网络中对结果序列的循环移位操作,能够通过调整各级初始控制信息实现.也就是说只要适当调整左边子蝶网络(共lgN-1级)的初始控制信息,那么第1个操作就能够实现,如图7中第1步所示;第2个操作完成的是对第1个操作结果序列中的数据块X与右边子蝶网络中无关数据块I的交叉换位操作.该过程仅需要将第lgN级初始控制信息的最后Y部分置“0”,其余保持不变(假设默认初始控制信息为“1”)即可完成,如图7中第2步所示.因此,这2个操作能够1次通过N-bit Inverse Butterfly网络实现.那么假设③成立.

Fig. 7 Implementation principles of N-bit PEX operation based on two N2-bit sub-networks图7 N2-N2子蝶网络完成N-bit抽取操作原理
证毕.
2.2 共性原理提取与统一路由算法设计
循环移位操作是推论1的一种特例,当N-bit Inverse Butterfly网络完成恒等置换时,输入序列与输出序列相等且各级初始控制信息全为“0”.该网络若要完成循环移位S的操作,就需要将各级子蝶网络中的初始控制信息2i-1-bit “0”进行循环左移后末尾取反S次,其中i为级数,S为循环移位位数.当该网络完成比特抽取操作时,则首先需要计算右边子蝶网络中控制序列R2中“1”的个数,记为Y.然后左边子蝶网络(共lgN-1级)对应的各级控制信息,按照各级子蝶网络对应的位宽(为2i-1-bit)进行循环左移后末尾取反Y次,以完成该级输出序列循环左移Y-bit的调整操作(图7中的Step1).同时,最后1级网络(第lgN级)假设初始控制信息为“1”,也需要进行循环左移后末位取反Y次,以完成与无关数据块I(左相邻于Y)的交叉换位操作(图7中的Step2),进而完成比特抽取操作.因此,无论是循环移位操作还是比特抽取操作都用到了性质1中的循环移位后末位取反操作.基于此,本文提出了针对循环移位和比特抽取2种不同操作的统一路由算法:
算法1. 循环移位与比特抽取操作统一路由算法.
输入:C_pex,S_rot;
输出:Control_bits. /*路由控制信息共有N×N/2-bit*/
① forl=1,2,…,N-2
②Sum_pc[l]=Popcnt(C_pex[l:0]);
/*统计C_pex中各比特位到0位的1的个数*/
③ end for
④ for (i=1,i≤lgN,i++)*/i表示级数*/
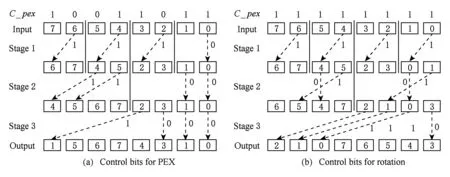
Fig. 8 Examples of the PEX and rotation operations图8 比特抽取与循环移位操作示例
⑤k=2i-1; /*第i级子蝶网络位宽*/
⑥ for (j=1,j≤N/2i-1-1,j=j+2)
⑦q=j×k-1;
⑧Control_bits(i)=RLTR(1k,Sum_pc[q]+S_rot);
⑨ end for
⑩ end for
以8-bit Inverse Butterfly网络为例,对算法1进行详细分析:
当该网络完成比特抽取操作时,S_rot必须为固定值0,设C_pex=1001_1011.根据算法1有:
若i=1时,k=1,j=1,3,5,7.因此q=0,2,4,6.且由于S_rot恒为0,第1级从右到左各子蝶网络控制信息分别为:
Control_bit(1)=RLTR(11,Sum_pc[0]+0)=RLTR(1,1)=0; /*C_pex[0]中1的个数*/
Control_bit(1)=RLTR(11,Sum_pc[2]+0)=RLTR(1,2)=1; /*C_pex[2:0]中1的个数*/
Control_bit(1)=RLTR(11,Sum_pc[4]+0)=RLTR(1,4)=1; /*C_pex[4:0]中1的个数*/
Control_bit(1)=RLTR(11,Sum_pc[6]+0)=RLTR(1,2)=1. /*C_pex[6:0]中1的个数*/
若i=2时,k=2,j=1,3.因此q=1,5.且由于S_rot恒为0,第2级从右到左各子蝶网络控制信息分别为:
Control_bit(2)=RLTR(12,Sum_pc[1]+0)=RLTR(11,2)=00; /*C_pex[1:0]中1的个数*/
Control_bit(2)=RLTR(12,Sum_pc[5]+0)=RLTR(11,4)=11. /*C_pex[4:0]中1的个数*/
若i=3时,k=4,j=1.因此q=3.且由于S_rot恒为0,第3级控制信息为:
Control_bit(3)=RLTR(14,Sum_pc[3]+0)=RLTR(1111,3)=1000. /*C_pex[3:0]中1的个数*/
比特抽取操作路由信息在网络各级的适配情况,如图8(a)所示.图8(a)中第1级有4个子蝶网络控制信息从左到右依次为“1”“1”“1”“0”;第2级有2个子蝶网络,控制信息从左到右依次为“11”“00”;第3级仅有1个子蝶网络,控制信息为“1000”.
当该网络完成循环移位操作时,C_pex必须为恒定值全1,设S_rot=5.根据算法1有:
若i=1时,k=1,j=1,3,5,7.因此q=0,2,4,6.且由于S_rot恒为5,第1级从右到左各子蝶网络控制信息分别为:
Control_bit(1)=RLTR(11,Sum_pc[0]+5)=RLTR(1,6)=1; /*C_pex[0]中1的个数*/
Control_bit(1)=RLTR(11,Sum_pc[2]+5)=RLTR(1,8)=1; /*C_pex[2:0]中1的个数*/
Control_bit(1)=RLTR(11,Sum_pc[4]+5)=RLTR(1,10)=1; /*C_pex[4:0]中1的个数*/
Control_bit(1)=RLTR(11,Sum_pc[6]+5)=RLTR(1,12)=1. /*C_pex[6:0]中1的个数*/
若i=2时,k=2,j=1,3.因此q=1,5.且由于S_rot恒为5,第2级从右到左各子蝶网络控制信息分别为:
Control_bit(1)=RLTR(12,Sum_pc[1]+5)=RLTR(11,7)=01; /*C_pex[1:0]中1的个数*/
Control_bit(1)=RLTR(12,Sum_pc[5]+5)=RLTR(11,11)=01. /*C_pex[4:0]中1的个数*/

Fig. 9 Architecture of the RPRU图9 可重构比特抽取-移位单元架构
若i=3时,k=4,j=1.因此q=3.且由于S_rot恒为0,第3级控制信息分别为:
Control_bit(1)=RLTR(14,Sum_pc[3]+5)=RLTR(1111,9)=1110. /*C_pex[3:0]中1的个数*/
循环移位操作路由信息在网络各级的适配情况,如图8(b)所示.图8(b)中第1级有4个子蝶网络控制信息从左到右依次为“1”“1”“1”“1”;第2级有2个子蝶网络,控制信息从左到右依次为“01”“01”;第3级仅有1个子蝶网络,控制信息为“1110”.
根据上述分析可知,当该网络完成比特抽取操作时,仅需将循环移位的参数S_rot设置为0.当该网络完成循环移位操作时,仅需要将抽取控制序列C_pex设置成全1.同时需要指出的是,当网络执行循环移位操作时,处于同一级子蝶网络的路由控制信息是相等的.如图8(b)中,当循环左移5位时,网络第1级4个子蝶网络中控制信息均为“1”,第2级2个子蝶网络中的控制信息均为“01”.这是因为当Inverse Butterfly网络完成循环移位时,各级子蝶网络初始路由控制信息均为“0”.且根据性质2可知,各子蝶网络的初始路由控制信息的变化方式均相同,因此其最终路由信息也完全相同.
3 统一硬件架构设计
本节根据算法1,设计了一种基于Inverse Butterfly网络的可重构比特抽取-移位单元 (recon-figurable parallel bit extraction-rotation hardware unit, RPRU),如图9所示.其中左边为N-bit Inverse Butterfly网络电路,由lgN级组成,各级有N2个2输入交叉开关,需要N2-bit路由控制信息.右边为可重构路由信息生成电路,它是整个架构的核心,共由2个部分构成:可重构比特连加电路(reconfigurable bit prefix population count circuit, RBPPC)和RLTR函数电路.RBPPC的作用是计算出控制序列C_pex从0位开始到各个位置的“1”的个数并记为Sum_pc[l],0≤l≤N-2.而后将每一个计算值与循环移位位数S_rot相加,从而得到用于各级子蝶网络进行RLTR函数运算的操作数M.由Inverse Butterfly网络的拓扑结构可知,第1级有N2个独立的子蝶网络,需要N2个1-bit位宽的RLTR函数电路.第i级有N2i个独立的子蝶网络,需要N2i个2i-1-bit位宽的RLTR函数电路.
由算法1的①~⑩步可知,控制序列C_pex中除了最高位以外的每一位都需要计算从0位开始到该位截止的加和值Sum_pc[l].若采用串行加法器的方式按位逐级相加,那么当C_pex序列较长时如32-bit或者64-bit,该电路的延迟开销将非常巨大.因此,本文通过借鉴先行进位加法器的设计思想[19],提出了一种基于“树”的并行连加结构,如图10所示.图10中设计了(N=32)-bit的高速并行连加电路,其中上层数字(30~0)代表的是C_pex序列中各个比特的位置,下层数字(5~1)代表的是该比特位置对应的加和值将被应用的网络级数i,黑色实心圆点代表的是全加电路,S_rot代表的是移位位数.例如,当上层数字为15时,其在下层输出值是C_pex序列从0位到第15位的和再加上S_rot的值,且该位的输出值将被用于网络第i=5级的RLTR函数运算,如图10中粗虚线所示.经过树形压缩后的连加电路最长仅有6级加法器的延迟,与原先30级串行加法延迟相比大幅下降.
算法1中RLTR函数操作,根据连加电路各个位的加和值M=Sum_pc[q]+S_rot,进行固定输入为“1”的序列循环左移后末尾取反M次操作.通过研究发现一个长度为L(L=2i)个“1”的初始序列进行RLTR操作时,周期为2L且结果序列为1x‖0y或为1x‖0y,x+y=2i.这与将该序列后拼接长度为L的“0”序列,并进行联合循环移M位,取其高L位输出的结果相同.因此本文首先将RLTR函数用对数移位器进行实现,如图11(a)所示.而后,由于其初始输入为恒定值“1”,因此再对其进行布尔逻辑优化以精简冗余逻辑,其优化后结构如图11(b)所示.与传统结构相比,经过优化后的电路面积大幅减少且速度有所提升.
4 功能与性能分析
本文将设计的RPRU位宽设定为(N=64)-bit,进行了硬件代码编写,并使用NC-Verilog对其功能进行了覆盖性测试,部分仿真结果如图12所示.
图12中前2行信号BP_LoacalA_Datain和BP_LoacalB_Datain一起组成64-bit输入数据.第3行为移位位数S_rot用6-bitBP_Shift表示.第4行为比特抽取控制序列C_Pex用64-bitBP_Mode_ibfly_config表示.第5行为RPRU的输出结果用64-bitBP_DataOut表示.第6行为64-bittb_out是基准测试程序生成的正确结果,它基于C语言编写用来模拟RPRU的功能.最后1行error是64-bit判别信号,它是tb_out与BP_DataOut的“异或”值,该值为“0”说明仿真数据与基准测试结果一致,RPRU功能正确.
从图12(a)中可以发现,当BP_Mode_ibfly_config为64-bit全“1”时,移位位数BP_Shift从0到63依次改变,覆盖所有移位可能.此时,error值恒为“0”,表明RPRU的循环移位功能正确.
从图12(b)中可以发现,当移位位数BP_Shift为恒定值“0”时,BP_Mode_ibfly_config为64-bit随机值.此时,电路完成比特抽取操作,从error为“0”可以判定RPRU的比特抽取操作功能正确.
在功能正确的基础上,基于CMOS 90 nm工艺对RPRU进行了逻辑综合,综合时采用flatten的优化策略(T=125℃,V=0.9V,P=slow)并设置时序优先,其结果如表1所示:

Table 1 Comparison of Area and Latency of the RPRU表1 抽取-移位单元面积和延迟对比
表1中第1行描述的是Hilewitz等人设计的64-bit动态比特抽取单元,该单元在TSMC 90 nm工艺下进行综合,其面积为8 500 gate,延迟为1.74 ns[18].第2行和第3行分别描述的是Hilewitz等人设计的64-bit静态比特抽取单元和64-bit静态比特抽取+循环移位单元[12].其中第3行的静态抽取+移位单元的设计思想是首先将文献[12]中提出的基于Inverse Butterfly网络的循环移位算法进行硬件设计,并与提前配置好的各级比特抽取路由控制信息进行选择,来实现同一架构下的不同操作.若用第3行静态比特抽取+移位单元的面积减去第2行静态比特抽取单元的面积,剩余部分面积=8 200-3 600=4 600 gate为循环移位路由算法硬件实现所消耗的面积.当该部分面积与第1行动态比特抽取单元相加后的面积=4 600+8 500=13 100 gate则应为Hilewitz等人的动态比特抽取+移位单元的总面积.该单元的延迟应仍然与动态比特抽取单元延迟一致为1.74 ns,这是因为循环移位算法实现的复杂度远低于比特抽取算法.第4行和第5行是本文设计的动态比特抽取单元和动态比特抽取+移位单元(RPRU)的面积和延迟值,它们基于CMOS 90 nm工艺综合,不同之处在于前者将算法1的S_rot设定为恒定值0,而后者将S_rot设定为任意输入数据.
经过上述分析可知,Lee等人设计的动态比特抽取+循环移位单元的面积为13 100 gate,延迟为1.74 ns.本文设计的RPRU面积为9 300 gate,为前者面积的70%;延迟为1.4 ns,为前者延迟的80%.从绝对数值上看,无论是面积还是延迟本文设计的RPRU均有所降低.但是,这并不能有效衡量出循环移位与比特抽取算法的融合程度.因此,为了更加客观地进行性能对比,本文提出了相对面积比(percent of relative area,PRA)这一参数:
PRA越高,说明动态比特抽取单元面积占总面积(动态比特抽取+移位单元)的比重就越大,同时循环移位路由算法硬件电路面积占总比重就越小(1-PRA).若循环移位路由算法硬件电路面积占总比重就越小,则表明其与比特抽取算法融合度就越高,那么该单元的结构也更优.本文将该参数应用于2个不同设计后有:Hilewitz的PRA=8 500/13 100=76.33%,本文的PRA=8 900/9 300=95.70%.从PRA的结果来看,Hilewitz等人设计的单元循环移位算法电路面积占总面积的近1-76.33%=34%.而本文设计的单元循环移位算法电路仅占总面积的4%左右.因此本文提出的算法能够有效地将循环移位和比特抽取2种不同操作高度统一在一个算法架构下,使它们能够最大限度地共享硬件资源,从而大幅提升硬件资源的复用率.
5 结束语
本文深入研究了循环移位和比特抽取2种位级操作在Inverse Butterfly网络中的实现原理,并提取出原理中所需的共性逻辑运算,进而提出了一种基于该网络的统一路由算法.该算法的提出首次在理论层面证明了这2种操作在硬件路由算法实现策略上统一的可行性,为硬件融合架构的设计提供理论支撑.同时,实验结果证明,利用本文算法设计的RPRU与同类设计相比,能够大幅提升硬件复用率,从而有效降低资源消耗.同时,需要指出的是,比特抽取操作已经集成于Intel处理器指令集中,若利用本文提出的统一路由算法,仅需增加不到4%的资源消耗即可实现传统循环移位操作,而无需再设计专门硬件单元.因此,我们希望未来能将该路由算法进行全定制设计,并与Intel处理器中的比特抽取操作充分融合.
[1]Bansod G, Raval N, Pisharoty N. Implementation of a new lightweight encryption design for embedded security[J]. IEEE Trans on Information Forensics and Security, 2015, 10(1): 142-151
[2]Jolfaei A, Wu Xinwen, Muthukkumarasamy V. On the security of permutation-only image encryption schemes[J]. IEEE Trans on Information Forensics & Security, 2015, 11(2): 235-246
[3]Zhang Jiyu, Liu Xianhua, Tan Mingxing, et al. Automatic instruction-set extension for bitwise operation-intensive applications[J]. Acta Electronica Sinica, 2012, 40(2): 209-214 (in Chinese)(张吉豫, 刘先华, 谭明星, 等. 一种针对位操作密集应用的扩展指令自动选择方法[J]. 电子学报, 2012, 40(2): 209-214)
[4]Schwartz S, Kent J, Smit A, et al. Human-mouse alignments with BLASTZ[J]. Genome Research, 2003, 13(1): 103-107
[5]Bansod G, Gupta A, Ghosh A, et al. Experimental analysis and implementation of bit level permutation instructions for embedded security[J]. Wseas Trans on Information Science & Applications, 2013, 10(9): 303-312
[6]Guo Jian, Peyrin T, Poschmann A, et al. The LED block cipher[C] //Proc of Int Conf on Cryptographic Hardware and Embedded Systems. Berlin: Springer, 2011: 326-341
[7] Sayilar G, Chiou D. Cryptoraptor: High throughput reconfigurable cryptographic processor[C] //Proc of IEEE Int Conf on Computer-Aided Design. Piscataway, NJ: IEEE, 2014: 155-161
[8]Neto C, Vestias P. Architectural tradeoffs in the design of barrel shifters for reconfigurable computing[C] //Proc of IEEE Conf on Programmable Logic. Piscataway, NJ: IEEE, 2008: 31-36
[9]Dimitrakopoulos G, Mavrokefalidis C, Galanopoulos K, et al. Sorter based permutation units for media-enhanced microprocessors[J]. IEEE Trans on Very Large Scale Integration Systems, 2007, 15(6): 711-715
[10]Cardarilli C, Nunzio D, Fazzolari R, et al. Butterfly and inverse butterfly nets integration on altera NIOS-II embedded processor[C] //Proc of the 44th Int Symp on Signals, Systems and Computers. Piscataway, NJ: IEEE, 2010: 1279-128
[11]Hilewitz Y, Lee B. Performing advanced bit manipulations efficiently in general-purpose processors[C] //Proc of IEEE Symp on Computer Arithmetic. Piscataway, NJ: IEEE, 2007: 251-260
[12]Hilewitz Y, Lee B. A new basis for shifters in general-purpose processors for existing and advanced bit manipulations[J]. IEEE Trans on Computers, 2009, 58(8): 1035-1048
[13]Intel Corporation. Intel®64 and IA-32 Architectures Software Developer’s Manual[S/OL]. 2013 (2015-12-03) [2017-02-10]. http://www.intel.com/content/www/us/en/architecture-and-technology/64- ia-32-architectures-software-developer-manual-325462.html
[14]Chang Zhongxiang, Hu Jinshan, Ma Chao. Research on shifter based on ibutterfly network[C] //Proc of the 17th National Conf on Computer Engineering and Technology. Berlin: Springer, 2013: 92-100
[15]Jahanshahi M, Bistouni F. A new approach to improve reliability of the multistage interconnection networks[J]. Computers & Electrical Engineering, 2014, 40(8): 348-374
[16]Lee B, Shi J, Yin L, et al. On permutation operations in cipher design[C] //Proc of Int Conf on Information Technology: Coding and Computing. Piscataway, NJ: IEEE, 2004: 569-577
[17]Dimitrakopoulos G, Mavrokefalidis C, Galanopoulos K, et al. Sorter based permutation units for media-enhanced microprocessors[J]. IEEE Trans on Very Large Scale Integration Systems, 2007, 15(6): 711-715
[18]Hilewitz Y, Lee B. Fast bit gather, bit scatter and bit permutation instructions for commodity microprocessors[J]. Journal of Signal Processing Systems, 2008, 53(1/2): 145-169
[19]Johri R, Akashe S, Sharma S. High performance 8 bit cascaded carry look ahead adder with precise power consumption[J]. International Journal of Communication Systems, 2015, 28(8): 1475-1483
猜你喜欢
昆明医科大学学报(2022年4期)2022-05-23
计算机与网络(2020年9期)2020-07-29
数学学习与研究(2020年22期)2020-01-11
网络安全和信息化(2019年11期)2019-11-25
传播力研究(2019年24期)2019-10-21
船舶标准化工程师(2019年4期)2019-07-24
科技与创新(2018年1期)2018-12-23
海峡姐妹(2017年10期)2017-12-19
三联生活周刊(2017年33期)2017-08-11
银行家(2017年1期)2017-02-15
