
基于ARIMA-SVR的水文时间序列异常值检测∗
2018-03-20 07:08孙建树娄渊胜陈裕俊
计算机与数字工程 2018年2期
孙建树 娄渊胜 陈裕俊
(河海大学计算机与信息学院 南京 211100)
1 引言
时间序列作为数据挖掘技术在实际应用中的一个重要方面,已经受到广泛的关注,但是目前大多数的研究都集中在相似性挖掘、时间序列预测等方面,异常值检测通常被忽略。异常值检测作为数据预处理中一个必不可少的环节,而预处理又在整个数据挖掘过程中占据了40%左右,应当引起关注。水文时间序列表示某种水文数据(如水文、流量等)随时间变化的实测值,对水文时间序列来说,异常值通常是与一般规律相差较大的数值。通过检测出这些异常值,可以分析出更多隐藏在数据背后的信息,对分析决策有着重要帮助,所以异常值检测显得尤为重要。
本文采用基于自回归积分滑动平均模型[1](ARIMA)和支持向量回归[2](Support Vector Regres⁃sion)的组合预测方法检测水文时间序列中的异常值。算法采用ARIMA模型预测水文时间序列中的线性部分,使用SVR预测残差部分即非线性部分,然后判断实际数据是否在预测值的置信区间内从而确定异常值。并以六合实测数据作为验证,实验表明本文所提出的算法比单一模型算法更加有效,为水文时间序列分析提供理论基础。
2 相关研究
异常检测也叫做异常挖掘[3],是指从大量数据中找出其行为明显不同于预期对象的过程。一般将时间序列中的异常分为三种:点异常、序列异常和模式异常。在本文中主要研究的是点异常,它表示序列上和大部分对象存在明显差异的点。
当前对时间序列的异常值检测主要有以下几种:
1)基于模型的异常检测。牛丽肖[4]等使用ARIMA模型对短期电价进行拟合,同时可以检测到其中的突变点,但该算法没有考虑到序列的非线性部分。单伟等[5]采用自相关系数和偏自相关系数的拖尾建立AIRMA模型,并用于网络流量的预测和异常检测。基于模型的方法主要缺陷是事先要假定数据集符合特定的分布模型,针对大量分布特征未知数据时,这种先验假设存在很大的局限性。
2)基于支持向量机的异常检测。任勋益[6]等先用主元分析对初始数据进行降维,再使用SVM建模并检测出异常数据,但当数据中异常种类较多时,效果不佳。张昭[7]等提出一种基于特征选择和SVM的异常检测算法,能准确地检测出异常数据。基于SVM方法对非线性数据有较好的拟合效果,但依赖于不敏感损失函数和核函数的选择,对操作人员的专业知识要求较高。
3)基于距离的异常值检测[8~9]。该方法优点是便于用户使用,时间复杂度相对较小,但对局部异常点不敏感。
4)基于密度的异常值检测[10]。从密度的角度来说,密度较低的区域出现异常值的可能性较大。该算法的检测准确率较高,对局部异常点有不错效果,但总体时间复杂度过高。
5)基于聚类的异常值检测[11]。异常值的概念和簇的概念高度相关,基于聚类的方法通过考察对象与簇之间的关系检测异常值。因此,使用聚类算法检测异常点严重依赖于生成簇的质量,在实际应用中不太容易控制聚类产生的簇。
水文时间序列受多种因素影响其中存在较多异常值,刘千[12]等提出一种基于扩展符号聚集近似的水文时间序列异常检测方法,该方法效率较高,但它只能对指定的时间段数据进行检测。余宇峰[13]等提出用基于滑动窗口预测的水文时间序列异常检测,但计算复杂度高。综上所述,水文序列其中既含有线性自相关部分又含有非线性部分的问题,使用单一方法都会导致异常检测的结果不全面。受到基于模型的方法和支持向量机方法的启发,本文提出了使用ARIMA-SVR组合模型来预测置信区间,再判断实际值是否落在置信区间内进行异常值检测,不仅保证了挖掘结果的全面,还有效提升了异常值检测的灵敏度。
3 基于ARIMA-SVR的时间序列异常值检测
3.1 ARIMA模型
ARIMA模型全称为自回归积分滑动平均模型(Autoregressive Integrated Moving Average Model)。ARIMA模型的基本思想是用过去和现在的值去预测将来,它将时间序列看成一个随机序列,并寻找最优的函数去拟合它。以p,d,q为参数的ARIMA模型可以表示为
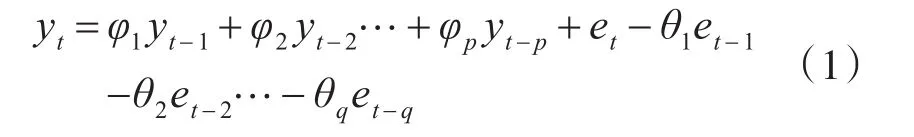
其中p是自回归的阶数,d是序列差分的阶数,q为移动平均阶数,yt为时间t时的观测值,et为白噪声序列,φi、θi分别为 yt-i和 et-i的系数。
水文时间序列的ARIMA模型建立流程如下:
1)首先对水文时间序列进行平稳性检验,如果通过,进入下一步;如果不通过,对序列持续差分直到差分后的序列满足平稳性检验;
2)确定模型的差分阶数d;以AIC信息准则为准,限定p和q的范围,将(p,q)组合遍历,找出具有最小AIC值的(p,q)组合;
3)将上述步骤中确定的最优p,d,q应用于ARIMA模型进行预测,得到置信度为α的置信区间。
3.2 支持向量回归
支持向量回归是将传统线性方程中的线性项替换为核函数,并在高维空间中构建一个线性决策函数,达到预测的目的。SVR的核心是ε-不敏感损失函数和核函数,不同的函数组合对模型的鲁棒性有较大影响。
给定训练样本:
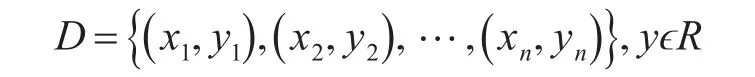
针对非线性回归问题,先使用非线性函数把训练数据映射到一个高维特征空间,并在这个高维特征空间进行线性回归。训练样本xi满足如下条件
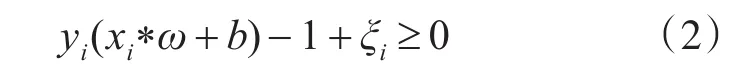
其中ξi称为松弛变量,且满足ξi≥0 ,i=1,2,3…n。
定义ε-不敏感损失函数如下
它表示对偏差小于ϵ的项不进行任何惩罚,对回归的容错性有所提升。
求最大化支持向量回归的边界等价于如下问题
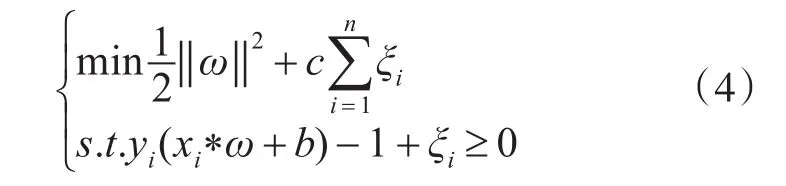
其中 ξi≥0,i=1,2,3…n ,c是惩罚参数又称作正则化参数,其主要作用是用来调节优化松弛变量和分类准确度的偏好权重。通过上述推导得到最终的SVR函数:
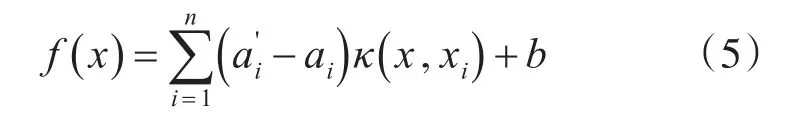
其中κ(x,xi)是满足Mercer条件的核函数,因为经过ARIMA函数拟合的残差序列总体平稳且线性不可分。因此本文选用径向基函数为核函数,与其他核函数相比,参数较少,易于使用。
水文序列中残差序列的支持向量回归步骤如下:
1)得到ARIMA模型的残差,作为训练集输入到SVR;
2)采用10折交叉验证的方法,寻找出最佳的gamma、cost和核函数的组合。
3)利用第二步中得到的最佳参数构建SVR模型,然后预测出残差。
3.3 基于ARIMA-SVR的时间序列异常值检测
在检测水文时间序列中的异常值时,首先要给出定义,什么样的值是异常值。借助于离群点的定义,下面给出了水文时间序列中异常值的定义。
定义1 水文时间序列中的异常值。在一维水文时间序列 X=<(y1,t1) ,(y2,t2),…,(yn,tn)> 中,(yi,ti)代表ti时刻的观测值,使用ti时刻前的m个连续实际值来预测ti时刻的值。如果实际值不在预测的范围内,那么该时刻的值为异常值。
水文时间数据受到季节、地形、天气等自然条件的影响,这种关系很难依靠单一的线性或者非线性关系来解释,其既有时间维度上的相关性,又有非线性关系的存在。ARIMA适用于平稳或差分后平稳的时间序列,但当序列不平稳时,拟合误差较大,实际预测效果较差。SVR是一种面向小样本的机器学习算法,其泛化能力强,对非线性时间序列预测有不错的效果。
因此,本文将ARIMA模型和SVR模型组合进行预测,再判断实际值与置信区间的关系,达到异常检测的目的。本文把水文时间序列看作线性自相关部分Li与非线性部分Ni组成,即yi=Li+Ni。首先通过ARIMA对水文时间序列建立初始模型,用于对数据中线性自相关部分的预测,得到置信度为α的置信区间;其次通过支持向量回归对初始模型中产生的残差序列进行训练,并将支持向量回归的预测结果对ARIMA模型进行修正,最后得到最终的置信区间;判断实际值与置信区间的关系,若实际值不在置信区间内,那么该值为异常值。
算法具体步骤如下:
输入:水文时间序列X、置信度 p和训练数据大小m。
输出:水文时间序列中的异常值。
步骤1:使用ti时刻前m个连续值建立ARIMA模型,并预测ti时刻的值,得到预测值,同时计算出预测值的置信度为α的置信区间,即±ε。
步骤2:计算步骤1中模型拟合的残差,残差序列{ei}为水文时间序列中的非线性部分,其中ei=f(ei-1,ei-2,…,ei-m)+ε,使用 SVR 对残差序列{ei}进行预测,得到预测残差值。
步骤3:将步骤1和步骤2中的预测值相加得到最终的预测值,结果是。同时得到置信度为α的置信区间±ε。
步骤4:比较ti时刻的实际值 yi与置信区间的关系,如果实际值 yi在置信区间±ε之外,那么点(yi,ti)为异常值,否则的话为正常值。
步骤5:循环步骤1~4直至序列结束,最终输出所有的异常值。
算法的总体流程如图1所示。
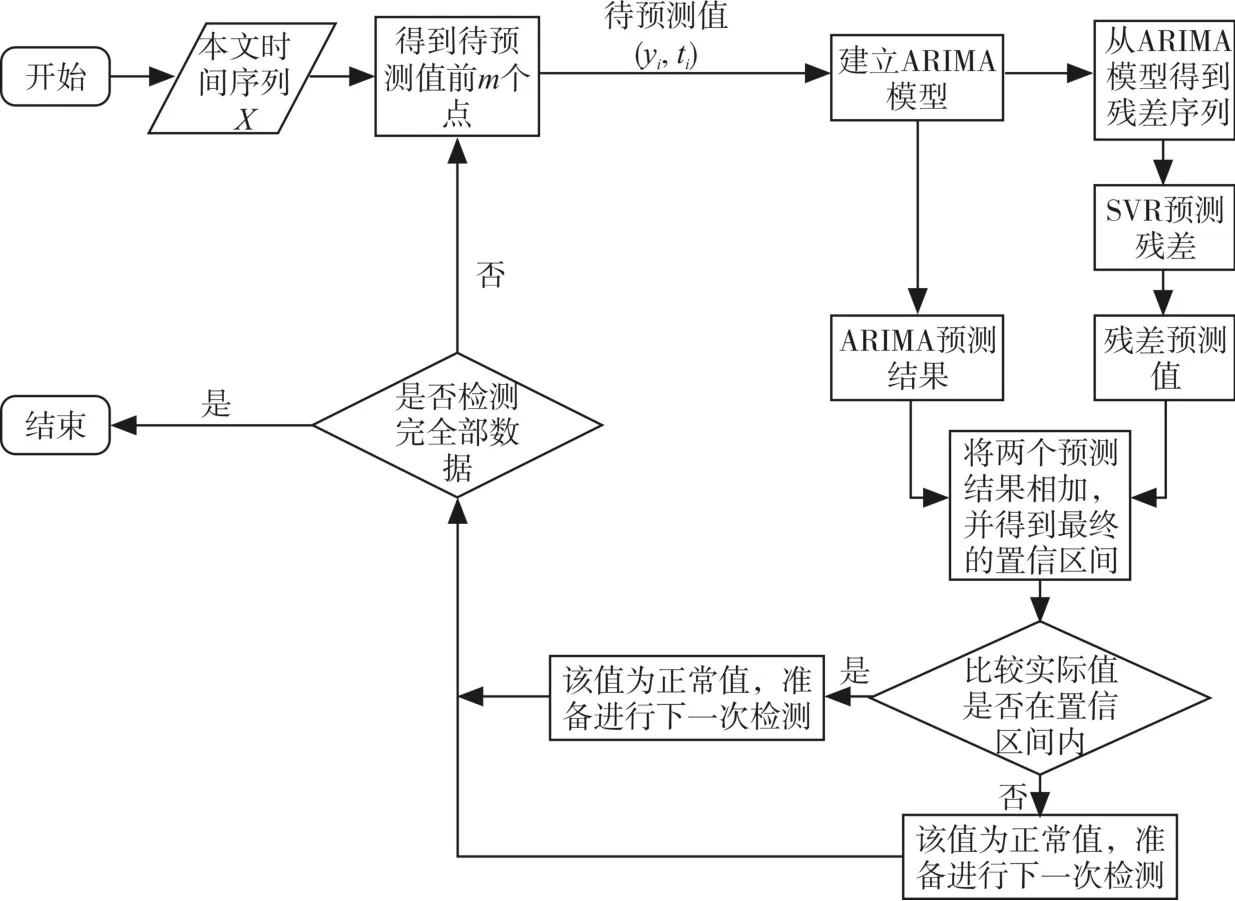
图1 算法的总体流程
4 实验分析
4.1 实验准备
本文所采用的数据集是滁河流域六合测站点从2013年1月1日至2014年12月22日的日平均水位实测数据,该站点为滁河流域上的重要水文站点,对滁河的防洪调度、生态环境调节有着重要作用。实验的软件环境为R 3.2.3,Windows 10旗舰版操作系统,硬件环境为2.6GHz CPU、8GB内存的笔记本电脑。图2为六合水文站的日平均水位图,从图中可以看出数据存在一定的周期性,但也明显存在一些异常点。

图2 六合水文站日平均水位图

图3 一阶差分图
4.2 结果分析
首先本文对数据进行一阶差分,其结果如图3所示。从图中可以看出差分后的数据大体平稳,使用adf检验一阶差分后的数据得到p-value=0.01<0.05,通过检验,确定ARIMA模型中d的值(d=1)。在本文中选用待测点之前的90个数据进行预测,使用R语言forecast包中的auto.Arima函数来自适应计算出最优的p和q,从而预测出待测点置信度α=95%的置信区间。然后用SVR对残差序列进行预测,其中核函数为径向基函数,cost=100,gamma=0.1。将两部分预测值相加并得到最终的置信区间。图4给出了异常检测的结果。

图4 异常检测结果
图4中给出了水文时间序列的实际值和服从置信度为95%的置信区间以及检测出的异常值。从图中可以发现,大部分的实际值都在置信区间内,仅有小部分的值不在范围内。检测出的异常值多出现在序列发生“剧烈”变化的地方,与实际情况相符。
4.3 实验评价与对比
为了验证算法的有效性与准确性,下面给出在分类和异常值检测方面常用的评价标准,本文将实验结果分为四类,如表1所示。从表中可以看出,数据都被归为TP(True Positive),即异常值都被检测出来是最理想的情况,同时尽量少的误判。本文还定义了算法的灵敏度(Sensitivity)和特异度(Specificity),灵敏度表示正确检测出的异常样本比例,即Sensitivity=。特异度为正确检测出的正常样本比例,即Specificity=。

表1 异常检测结果分类
本文使用ARIMA、SVR与ARIMA-SVR组合模型分别在六合实测数据上进行异常检测,得到的灵敏度和特异度对比如表2所示。其中使用基于ARIMA-SVR的水文时间序列异常值检测算法共检测出60个异常数据,53个为TP,7个FP,另外还有5个异常值未能检测出来。
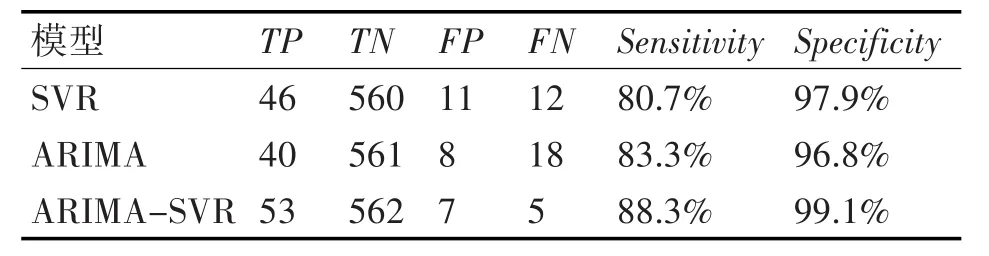
表2 不同模型的灵敏度和特异度
从上述对比发现,本文算法的灵敏度和特异度均显著高于使用单个预测模型进行异常检测,这表明本文算法具有较高的可靠性,同时能有效地检测出水文时间序列中的异常值。
在统计学中,常用接受者操作特性曲线[14](re⁃ceiver operating characteristic curve,ROC)也称为感受性曲线(sensitivity curve)来评价异常检测算法的性能。图5比较了本文算法、ARIMA算法和k-近邻算法[15]在本文数据集上的ROC曲线,并绘制出接受者操作特性曲线,横轴表示误报率,纵轴表检测率。判断某个算法的优劣主要是看ROC曲线下方的面积大小,面积越大,异常检测效果越好。从ROC曲线对比图可知,本文所提算法的明显优于其他两种算法,且较为稳定。
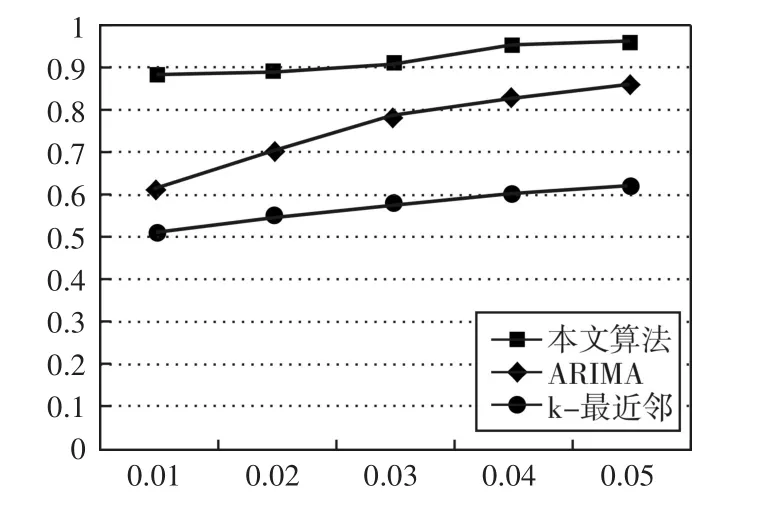
图5 3种算法ROC曲线对比图
5 结语
为了解决水文时间序列中存在较多异常值的问题,本文提出了基于ARIMA-SVR组合模型的异常值检测算法。由于水文时间序列受多种复合因素的影响,既有线性自相关部分也有非线性部分。首先,使用ARIMA-SVR组合模型预测出95%的置信区间,然后判断实际值是否在置信区间内,从而确定水文序列中的异常值。本文采用滁河流域六合测站点的实测数据进行实验,实验结果表明该算法能有效的检测出异常值。与其他算法对比,本文算法的灵敏度和特异度均保持较高水平,达到在实际水文数据中应用的要求。
[1]Contreras J,Espinola R,Nogales F J,et al.ARIMA mod⁃els to predict next-day electricity prices[J].IEEE Trans⁃actions on Power Systems,2002,18(3):1014-1020.
[2]Vapnik V N.The nature of statistical learning theory[J].Technometrics,1996,8(4):1564.
[3]Jiawei Han,Micheline Kamber,Jian Pei.数据挖掘概念与艺术[M].北京:机械工业出版社,2012:351.
Jiawei Han,Micheline Kamber,Jian Pei.Data Mining:Concepts and Techniques[M].Beijing:China Machine Press,2012:351.
[4]牛丽肖,王正方,臧传治,等.一种基于小波变换和ARI⁃MA的短期电价混合预测模型[J].计算机应用研究,2014,31(3):688-691.
NIU Lixiao,WANG Zhengfang,ZANG Chuanzhi,et al.Hy⁃brid model based on wavelet and ARIMA for short-term electricity price forecasting[J].Application Research of Computers,2014,31(3):688-691.
[5]单伟,何群.基于非线性时间序列的预测模型检验与优化的研究[J].电子学报,2008,36(12):2485-2489.
SHAN Wei,HE Qun.Research of the Optimizing and Test⁃ing of Forecasting Model Based on the Non-linear Time Series[J].Chinese Journal of Electronics,2008,36(12):2485-2489.
[6]任勋益,王汝传,孔强.基于主元分析和支持向量机的异 常 检 测[J].计 算 机 应 用 研 究 ,2009,26(7):2719-2721.
REN Xunyi,WANG Ruchuan,KONG Qiang.Principal component analysis and support vector machine based on anomaly detection[J].Application Research of Comput⁃ers,2009,26(7):2719-2721.
[7]张昭,张润莲,蒋晓鸽,等.基于特征选择和支持向量机的异常检测方法[J].计算机工程与设计,2013,34(9):3046-3049.
ZHANG Zhao,ZHANG Runlian,JIANG Xiaoge,et al.Anomaly detection method based on feature selection and support vector machine[J].Computer Engineering and De⁃sign,2013,34(9):3046-3049.
[8]Knorr E M,Ng R T.A Unified Notion of Outliers:Proper⁃ties and Computation[C]//International Conference on Knowledge Discovery&Data Mining.1997:219-222.
[9]Vy N D K,Anh D T.Detecting Variable Length Anomaly Patterns in Time Series Data[C]//International Conference on Data Mining and Big Data.Springer,Cham,2016:279-287.
[10]Breunig M M,Kriegel H P,Ng R T,et al.LOF:identi⁃fying density-based local outliers[J].Acm Sigmod Re⁃cord,2000,29(2):93-104.
[11]Truong C D,Anh D T.An efficient method for motif and anomaly detection in time series based on clustering[J].International Journal of Business Intelligence&Data Mining,2015,10(4):356-377.
[12]刘千,朱跃龙,张鹏程.基于扩展符号聚集近似的水文时间序列异常挖掘[J].计算机应用研究,2012,29(12):4479-4481.
LIU Qian,ZHU Yuelong,ZHANG Pengcheng.Extended symbolic aggregate approximation based anomaly mining of hydrological time series[J].Application Research of Computers,2012,29(12):4479-4481.
[13]余宇峰,朱跃龙,万定生,等.基于滑动窗口预测的水文时间序列异常检测[J].计算机应用,2014,34(8):2217-2220.
YU Yufeng,ZHU Yuelong,WAN Dingsheng.Time series outlier detection based on sliding window prediction[J].Journal of Computer Applications,2014,34(8):2217-2220.
[14]邹洪侠,秦锋,程泽凯,等.二类分类器的ROC曲线生成算法[J].计算机技术与发展,2009,19(6):109-112.
ZOU Hongxia,QIN Feng,CHENG Zekai,et al.Algo⁃rithm for Generating ROC Curve of Two-Classifier[J].Computer Technology and Development,2009,19(6):109-112.
[15]Pokrajac D,Lazarevic A,Latecki L J.Incremental Local Outlier Detection for Data Streams[C].Computational In⁃telligence and Data Mining,2007.CIDM 2007.IEEE Symposium on.IEEE,2007:504-515.
猜你喜欢
江西师范大学学报(自然科学版)(2022年4期)2022-10-18
新世纪智能(数学备考)(2021年9期)2021-11-24
现代经济信息(2021年3期)2021-11-23
陕西档案(2021年2期)2021-05-21
新世纪智能(数学备考)(2020年9期)2021-01-04
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28
计算机与网络(2020年13期)2020-07-29
心理技术与应用(2019年5期)2019-05-24
黄河黄土黄种人·水与中国(2017年2期)2017-03-16
中学生数理化·八年级数学人教版(2016年4期)2016-08-23
