
协同移动数据同步的公平优化
2018-03-22 11:44董灿吴峻峰
电子技术与软件工程 2018年3期
董灿 吴峻峰

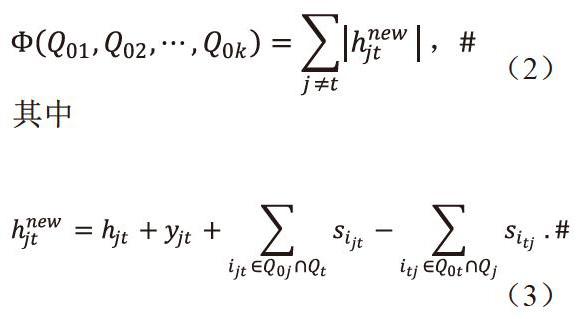

摘 要 对于员工经常到外面执行任务的大公司或大机构来说,员工通过移动设备来同步任务数据要消耗很多数据流量和造成服务器很大的负载开销。通过利用P2P技术,本文的分布式数据同步协议可以让组队外出的员工减少数据流量的消耗和服务器负载开销,主要原理包括两层:一层是相同部分的数据不需要所有员工的移动设备都和服务器同步,只要部分员工有同步,其他人就可以用P2P技術在便携式热点建立的局域网内同步;第二层是通过积分奖励来鼓励员工避开服务器负载高峰期进行提前的数据同步,让服务器在负载高峰期可以减少负担。本文还对提出的协议给出了数学算法,并分析了其算法复杂度。
【关键词】移动数据同步 优化 分布式 协议
1 导言
考虑下述应用场景:假设某公司或机构经常派员工到城郊各地去执行工作任务,并且外部的工作环境无法提供无线网络,使得外出的员工只能通过移动网络来同步工作表单数据和任务资料。在这种应用场景中,如果这些员工是组队外出的,那么他们就可以用根据本文的数据同步优化协议实现的APP来减少在移动网络中耗费的数据流量。这对公司或机构的数据服务器端也是好事,原因是前述员工们在移动网络中耗费的数据流量都对应着服务器要承担的数据同步任务,而流量的减少意味着服务器负载的下降。这使得服务器因为负载过高而产生卡顿甚至宕机的机率大为减少。
为了解决该场景中的移动端数据流量和服务器负载优化问题,我们可以使用P2P技术。P2P是peer-to-peer的缩写,又称对等网络,可以简单的定义成通过直接交换来共享计算机资源和服务,而对等计算模型应用层形成的网络通常称为对等网络。在P2P网络环境中,彼此连接的计算机处于对等的地位。网络中的每一台计算机既能充当网络服务的请求者,又对其它计算机的请求作出响应,提供资源和服务。对等网络又称工作组,网上各台计算机有相同的功能,无主从之分,一台计算机都是既可作为服务器,设定共享资源供网络中其他计算机所使用,又可以作为工作站,没有专用的服务器,也没有专用的工作站。
近年来,移动对等网络的关键技术成为研究的热点。其中,由于移动网络的流量限制,对等网络中的自私节点的检测和激励机制成为一个重要问题。在本文所提到的问题的求解中,我们通过一些任务分配和激励机制来防止自私节点的出现,从而保证减少移动端数据流量和服务器负载的目标能够合理地实现。
利用P2P技术,本文提出数据同步优化协议称为移动网络局部协同数据同步优化协议,其原理基于下述基本思想:
(1)移动设备,包括手机和支持SIM卡的平板,可以通过建立便携式网络热点来组建临时的局域网;
(2)数据同步时,去同一个地方的员工很可能需要同步若干相同的数据,而一份相同的数据没必要每台移动设备都和服务器同步一遍,完全可以一台移动设备同步之后,其它移动设备通过临时的局域网来局部同步,从而减少移动网络数据流量;
(3)去同一地点执行任务的某些员工可能已经在其移动设备上有部分的最新数据,这些最新数据有可能是员工在外出前就利用无线网或数据线同步到移动设备上的,而其他员工如果也需要这些数据但没有提前同步的话,可以利用临时的局域网内的数据分享来免流量同步;
(4)为了合理地分配远程数据同步的任务,这些移动设备可以在临时的局域网内交换数据供求信息,然后按照需求协商分配消费移动数据流量的远程数据同步任务,原则包括:
1.对于每一份不同的数据,只有对这份数据有需求的移动设备才需要承担相应的远程数据同步任务;
2.在前一条原则的基础上,远程数据同步任务尽可能均匀,使流量的消费尽可能平均的平摊到不同的移动设备上;
3.对于当次无法完全平摊的流量消费,可以做历史记录,在以后的局部协同数据优化中,可根据历史记录来为前面承担较多远程数据同步任务的移动设备适当减少任务;
(5)对于外出前提前进行部分数据同步的员工,应根据以下原则给予数据同步上的奖励:
1.提前数据同步时越是避开服务器的负载高峰期,得到的奖励就越多;
2.在用便携式热点组建临时局域网时,为其他人提供的有效数据共享越多,得到的奖励就越多;
3.上述两种奖励都是积分制的,提前同步过程加分,奖励兑换过程减分,其中奖励的兑换是让相应的移动设备在平摊远程同步任务时可以用分数来兑换承担量。
根据上述基本思想,本文剩余部分将按如下结构来细述协议的规则和数学模型:第二节解释提前进行同步的积分加分规则,并且给出分析规则加分量的数学模型;第三节描述在平摊远程同步任务时的积分兑换规则;第四节阐述远程同步任务的分摊过程数学模型,并且为该数学模型设计一套计算机算法;第五节分析前面三节中的算法的计算复杂度;最后一节是本文的总结,给出本文的结论。
2 提前同步加分规则
如果一位员工在执行外出任务前提前同步部分相关的数据,那么在执行任务时通过移动网络局部协同数据同步优化协议来和其他员工一起同步数据时,就可以得到减少平摊远程同步任务的奖励。该奖励有以下规则:
(1)只有在进行协同数据同步时其他员工有需求的那些提前同步数据,其提前同步者才能获得加分。如果其他员工没有对某份数据的需求,那么即使该员工提前同步了该数据,他也不能从这份数据的提前同步中获得加分。
(2)在进行协同数据同步时,如果有很多参与在其中的员工对某份数据都有需求,那么对该份数据的提前同步就可以获得较高的分数;反之,如果只有少数参与者对该份数据有需求,那么对该份数据的提前同步就只能获得较低的分数。
(3)在进行协同数据同步时,如果有多名参与者都提前同步了某份数据,那么他们共享这份数据时的加分倍数变小。一份数据提前同步的参与者越多,意味着这份数据的需求越易预测,因此分摊到单名提前同步该数据的参与者上时,加的分数会变少。
(4)提前同步的时机会影响加分的分数。如果提前同步的时间处于公司或机构的服务器的低负载时段,那么提前同步加分的倍数就可以得到较大的奖励加成;反之如果提前同步的时间处于服务器的高负载时段,那么提前同步的加分倍数就会较少。
(5)协同数据同步时服务器的当前负载率也会影响加分的分数。当前负载率高则表示要同步数据很困难,因此提前同步加分的倍數就应该大;反之当前负载率低则提前同步加分的倍数应该小。
(6)一份数据的提前同步加分,还和这份数据的大小有关。数据量大,表明为协同数据同步参与者节省的流量多,同时也为公司或机构的服务器节省了较多的占用带宽。因此,数据量较大的数据提前同步,可以得到的加分的倍数就会较大;反之数据量小的加分倍数也小。
(7)尽管不同数据的提前同步所得的加分是分开计算的,这些加分最终会按照员工与员工之间的互助关系合并在一起来兑换平摊远程同步任务时的奖励。换句话说,这些分数会按员工a为员工b提供了多少提前同步的帮助的分数形式来兑换,而兑换方法是员工b要通过远程同步任务来反过来帮助员工a。
根据上述规则,我们可以知道为了用一个数学函数来描述一次协同数据同步过程中的加分,我们需要与这次协同数据同步相关的以下输入数据:
1.这次协同数据同步中被至少一位参与者需求的数据的集合D1,D2,…,Dn;
2.参与这次协同数据同步的员工u1,u2,…, uk;
3.每份数据Di的需求者人数mi,以及每位员工uj需要的数据的编号集合Qj={ij1,ij2,…, };
4.每份数据Di的提前同步供应者人数ki;
5.对于每份数据Di,上述每位员工uj在同步该数据过程的服务器平均负载率rij;如果uj没有提前同步Di,则rij=+∞;
6.协同数据同步过程中当前的服务器负载率r;
7.每份数据Di的大小si。
假设用xij来表示数据供应者uj从提前同步数据Di中获得的分数,用yjt来表示员工uj通过提前同步数据帮助员工ut所得的加分(称为uj对ut的帮助分),那么规则1表示xij>0仅当mi>0且rij<+∞;规则2表示xij关于mi单调递增;规则3表示xij关于ki单调递减;规则4表示rij越大会使xij越小,并且rij=+∞时xij=0;规则5表示r越大会使xij越大;规则6表示xij关于si单调递增;规则7表示
显然xij的具体表达式可以有很多不同的方案。考虑到移动设备主要不是用来计算的,我们尽可能地让xij的表达式容易计算。我们采用如下的式子:
其中数据编号i=1,…,n,员工编号j=1,…,k.容易验证这条式子满足前述加分规则的要求。另外,由帮助分yjt的表达式可以知道yjt=-ytj。
3 积分兑换规则
如前所述,对于外出执行任务前提前同步数据的员工,在协同数据同步过程中可以获得积分的奖励。这些奖励按照如下的规则进行:
(1)如果前述的员工uj对员工ut的帮助分为负分,则员工uj可以通过承担远程数据同步任务来填补这个负分,而员工ut则可以获得部分减免远程数据同步任务的奖励。
(2)并不是所有远程数据同步任务都可以填补负帮助分。对于数据Di,只有当它同时是员工uj和ut需要的数据(亦即i同时在集合Qj和Qt内)时,员工uj才可以通过承担数据Di的远程同步任务来填补他对员工ut的负帮助分。
(3)员工uj通过承担数据Di的远程同步任务,可以获得用来填补负帮助分的兑换分=mi si. 该况换分将在Di的需求者之间平均分摊来兑换帮助分,因此这mi个需求者中的每一个都得到该数据si的兑换分。
(4)兑换分和帮助分的地位是平等的。这些分数在执行这次协同数据同步后可能还有剩余,剩余部分将记入历史记录。这些记录都是按员工与员工之间的互助关系来记录的。
4 远程同步任务分摊规则
远程任务的分摊,有两大规则:
(1)剩余的自由兑换分尽可能少,从而提前同步数据所得的帮助分可以得到最大程度的兑换;
(2)自由兑换分要尽可能地均匀分布到参与协同数据同步的员工上。
这两条规则可能会冲突。在发生冲突时,优先按第一条规则来实施。
为了建立这些任务分摊规则的数学模型,我们使用以下的符号:
1.协同数据同步中相关的数据集合D1,D2,…,Dn;
2.每份数据Di的大小si;
3.参与这次协同数据同步的员工u1,u2,…, uk;
4.每份数据Di的需求者人数mi,以及每位员工uj需要的数据的编号集合Qj={ij1,ij2,…, };
5.由第二节的规则计算,根据公式(1)所得的uj对ut的当次帮助分yjt;
6.第三节的规则5和规则6所提到的uj对ut的历史数据记录的过往累积分数hjt(hjt=-htj);
7.没有人提前同步的数据Di的序号i的集合Q0;
8.在员工u1,u2,…,uk之间对集合Q0的分划,其中对每个j=1,…,k,都要求, 并且当j≠t时,有.
利用以上的符号,可以把任务分摊规则的目标定义为帮助分得到尽可能多的兑换,其需要最小化的目标函数的数学表示为
由此可知该任务分摊的最优化是一个组合优化问题。这种问题求最优解的计算复杂度太高,不太适合在不是以计算为主要目的的移动设备上计算。因此,我们退而求其次地设计一种贪心算法,用较少的计算量来取得一个比较好的结果就可以了。
我们设计的贪心算法有三层循环:外层循环如图1中的流程图所示,每循环一次从Q0中选出一个i,加入到已分配的数据编号集合中;中层循环负责为当次的外层循环从Q0选择新的i,因此中层循环遍历的Q0中还未被分配的i;内层循环则负责为中层循环当前的i遍历所有分配的可能,计算出该i对目标函数的贡献。具体来说,如果外层循环先后选择了Q0中的数据编号
内层循环通过比较,为这i0个编号分别分配了编号为
的用户来负责该数据的远程同步任务,则如果记
argmin部分是中层循环,min部分是内层循环。
5 算法的计算复杂度
第二节中的算法要对每一对j和t来计算xjt,而j和t的取值范围为1到k,因此第二节的算法的复杂度为O(k2)。
第四节的算法有三层循环:外层循环总共n0次;在第t次外层循环中,中层循环共有n0-t+1次;在每次中层循环中,内层循环的次数都是O(k),但每次内层循环都要对每一对j和t来计算近似目标函数,而j和t的取值范围为1到k,因此每次中层循环的复杂度为O(k3)。 综上可知,第四节的算法的复杂度为O(n02k3)。
6 结论
本文给出了一种基于便携式热点的移动通信协同数据同步协议。该协议通过两种方法来为用户减少移动网络的数据流量,为服务器端减少负载压力:
(1)利用热点局域网络进行数据共享,尽可能地避免多位用户重复下载他们共同需要的数据;
(2)利用积分制来鼓励避开服务器负载高峰期提前同步数据,避免用户的数据同步集中在一起,造成服务器的负载过高。
同时,本文还根据给出的协议建立了数学模型和计算机算法,使该协议能够在实际应用中使用。
参考文献
[1]黄桂敏,周娅,武小年.对等网络[M].北京:科学出版社,2011.
[2]欧中洪,宋美娜,战晓苏等.移动对等网络关键技术[J].软件学报,2008,19(02):404-418.
[3]牛新征.移动对等网络若干关键技术的研究[D].电子科技大学,2008.
[4]秦娣.移动对等网络关键技术分析[J]. 技术与市场,2015,22(12):207-207.
[5]曲大鵬,王兴伟,黄敏.移动对等网络中自私节点的检测和激励机制[J].软件学报,2013,24(04):887-899.
作者简介
董灿(1981-),男,云南省楚雄市人。毕业于南开大学,现任中国南方电网有限责任公司信息部规划建设处主管,工程师。研究方向为企业信息系统建设及技术管控,数据质量治理及信息系统实用化研究。
吴峻峰(1980-),男,广东省广州市人。中山大学博士,中山大学讲师。研究方向为高性能计算、大数据、分布式计算。
作者单位
1.中国南方电网有限责任公司 广东省广州市 510530
2.中山大学 广东省广州市 510275
猜你喜欢
房地产导刊(2022年5期)2022-06-01
中学生数理化(高中版.高二数学)(2021年12期)2021-04-26
科技创新与应用(2016年34期)2016-12-23
雷达与对抗(2015年3期)2015-12-09
自动化博览(2014年12期)2014-02-28
