
序列模式挖掘在车流量预测上的应用研究
2018-03-23 03:44李红星
西安文理学院学报(自然科学版) 2018年2期
李红星
(安徽新华学院 电子通信工程学院,合肥 230088)
随着城市化的进展和汽车的日益普及,交通拥堵更加严重.出行者迫切需要了解未来某段时间内某一路段的车流量情况,从而避开拥塞路段,选择最快路径.但交通广播等形式的交通信息服务只能提供某些重点路段的实时车流量情况.依据实时的道路交通信息采用适当的方法滚动预测未来某一段时间内道路的车流量状况,向出行者提供最佳行车路线,不仅可以帮助出行者避开拥塞路段,选择最快路径,又能均衡交通流.
交通流量预测存在多种方法.1960年Kalman[1]提出了卡尔曼滤波模型.1993年Vythotkaspc[2]提出了基于卡尔曼滤波理论的车流量预测模型[2],计算结果较为令人满意.1974年,Box和Jenkins提出了差分自回归滑动平均模型ARIMA[3].1984年,Okutani等人[4]将ARIMA模型应用到城市交通控制系统中.1999年,Williams等人[5]将ARIMA模型应用在路段单点交通流量预测中.2017年,Yang等人[6]采用运用指数平滑法和多元回归模型组合进行交通预测,得到了较好的预测效果.
人工神经元网络诞生于20世纪40年代.2017年Kang等人[7]提出了改进的布谷鸟搜索(cuckoo search,CS)算法优化BP神经网络的高速公路流量预测模型,预测结果较为令人满意,但神经网络算法需要大量的训练数据集,当训练数据集不足时,预测效果会很差.
2004年Sun等人[8]研究了在实际交通流数据有缺失的情况下,采用马尔可夫链模型方法,把交通流看成是马尔可夫链,转移概率近似采用高斯混合模型,参数估计采用Competitive Expectation Maximum算法.2006年Simmons等人[9]提出了基于马尔可夫概率模型的车辆路径预测模型.2011年Jing Yuan等人[10]根据实时和历史交通情况以及驾驶员驾驶行为,采用马尔可夫链模型方法,提出了为驾驶员提供最快行车路径的系统.基于马尔可夫链的预测一般为短距离的预测,这种预测的准确率很高,但这种短距离预测难以更早地将信息发送给驾驶员,让其有足够的时间做出调整,并不适用于交通信息服务.
目前,智能交通系统利用大量的先进的数据收集技术,采集到了大量的交通数据[11].这些海量的数据为建立车流量预测模型和使用车流量预测模型滚动预测车流量提供了数据基础.将交叉路口电子眼采集的数据转换为车辆行驶路径序列,对车辆行驶路径序列进行序列模式挖掘,挖掘出车辆行驶路径序列模式并生成路径关联规则库.再将车辆当前行驶路径与关联规则库中的模式匹配,预测车辆将以多大概率到达下一路段,从而对路段的车流量进行合理预测与分析.
基于序列模式挖掘的车流量预测方法通过对多用户的车辆行驶路径序列进行挖掘,挖掘出车辆规律性的行驶路径并生成普遍适用性的行驶路径关联规则,能有效地发现数据间的联系,根据已有的数据预测未来发展趋势.
1 相关定义
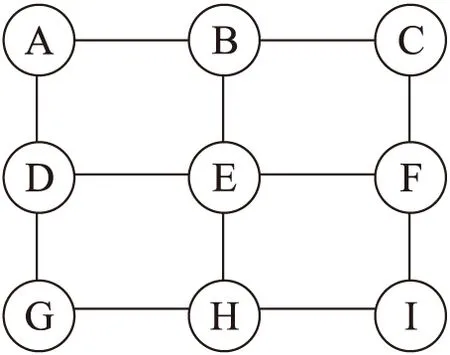
图1 模拟交通路网
假设以一系列安装了电子眼的交叉路口为节点构成交通网络,那么车辆行驶路径可以用节点顺序排列来表示.设计如图1所示的模拟交通路网,在A-I的9个交叉路口均有电子眼采集数据.
将电子眼采集的每条数据,以时间区间T为阈值划分成多个行驶记录,即如果同一辆车被相邻两路口电子眼检测到的时间间隔超过了设定的时间阈值T,则认为是该车的两次行驶记录.将车辆的行驶记录存入车辆行驶路径序列数据库中,如表1所示.

表1 车辆行驶路径序列数据库
定义1 设I={ik,k=1,2,…,n}是一个项目集合,项目ik表示道路节点即道路上安装有电子眼的交叉路口.路径序列是不同项目的有序排列,路径序列S可以表示成S=〈I1,I2,…,In〉,Ij⊂I.
性质1 路径序列不存在同位项.即车辆不可能在同一时间经过不同的两个节点.
性质2 路径序列所含每两个相邻项目为道路相邻两节点.即不可能出现类似于〈B H〉这样的车辆行驶路径,因为车辆不可能经过B节点后不经过E节点而直接到达H节点.
定义2 一个路径序列中任意个连续项目组成的序列称为该路径序列的子路径序列.若路径序列α为路径序列β的子路径序列,则称路径序列β包含路径序列α.
定义3 路径序列S在路径序列数据库的支持度为路径序列数据库中包含S的序列个数,记为Support(S).给定最小支持度ξ,如果路径序列S在路径序列数据库中的支持度不低于ξ,则称路径序列S为路径序列模式.
2 GSP算法改进
序列模式挖掘算法是由R.Agrawal和R.Srikant在文献[12]中提出的.对序列模式的挖掘一般采用GSP算法[13]或者PrefixSpan算法[14].研究表明PrefixSpan算法在时间和空间上的执行性能比GSP算法更优,但GSP算法对于有约束条件的序列模式挖掘更适用[15],车辆行驶路径序列是典型的时间特征约束下的序列,所以GSP算法对车辆行驶路径序列的序列模式挖掘更有效.
GSP算法的基本思想是首先第一次扫描序列数据库中的所有序列得到1-序列模式L1,然后由k-序列模式Lk通过产生候选序列模式函数GenCandidate()产生候选k+1-序列Ck+1,然后再一次扫描序列数据库中所有序列,统计候选k+1-序列Ck+1的支持度,满足用户设定的最小支持度的候选k+1-序列Ck+1即为k+1序列模式Lk+1,然后循环这几步,直至产生不了新的序列模式.其中,产生候选序列模式函数GenCandidate()包含如下两个步骤:
(1)连接:如果删去某一个序列模式S1所包含的第一项与删去某一个序列模式S2所包含的最后一项所得到的子序列是一样的,则将S1与S2进行连接,即将S1的第一项添加到S2的最前面.
(2)修剪:如果某一个候选序列模式的所有子序列中有一个子序列不为序列模式,则这一个候选序列模式不可能是序列模式,将其删掉.
从以上的描述可知,当序列数据库中包含的序列很多时或者用户设定的最小支持度较小时,容易产生大量的候选2-序列[16].因此,如果能减少2-序列模式的生成个数进而减少数据库扫描时间,则算法的性能将有所提高.本文依据性质2改进原始GSP算法产生候选序列模式子过程GenCandidate(),对候选2-序列模式的生成方式进行限定,减少候选2-序列模式的个数.产生候选序列模式子过程伪代码如下:
GenCandidate(L)
参数L:被连接路径序列模式长度
if(L==1)
如果1-路径序列模式S1中的项目与1-路径序列模式S2中的项目是相邻节点,则可以将S1与S2进行连接,即将S2中的项目添加到S1中.
else
执行原始GSP算法的产生候选序列模式函数中的连接步和修剪步.
returnCk+1;
以表1中的数据为例,令最小支持度为3.满足最小支持度的1-序列模式为:〈A〉:3,〈B〉:4,〈C〉:4,〈D〉:6,〈E〉:13,〈F〉:6〈H〉:9,〈I〉:3.由1-路径序列模式生成候选2-路径序列模式时,只对相邻交叉路口的1-路径序列模式进行连接.如〈B〉路径序列模式只和〈A〉、〈C〉、〈E〉相连接,形成候选2-路径序列模式〈B A〉、〈B C〉、〈B E〉.这样既可以减少候选2-路径序列模式的个数,又可以产生具有实际意义的序列模式.
3 车流量预测模型
路径序列模式反映的是车辆规律性的路线选择.由路径序列模式产生具有方向性的路径关联规则,规则的前件表示车辆已行驶的路径序列,规则后件表示车辆将要行驶的路径序列.
定义4 〈B E〉→〈H〉这条路径关联规则的置信度定义为路径序列数据库中包含路径序列〈B E H〉的个数与包含路径序列〈B E〉的个数之比.即conf(〈B E〉→〈H〉)=sup(〈B E〉 ∪〈H〉)/sup(〈B E〉)=3/4=75%.〈B E〉→〈H〉这条关联规则的置信度表示正在BE路段上行驶的车辆到达EH路段的概率为75%.
当最小支持度为3时,对表1的路径序列数据库采用改进的GSP算法进行序列模式挖掘得到路径序列模式集,包含的序列模式有:〈A〉:3,〈B〉:4,〈C〉:4,〈D〉:6,〈E〉:13,〈F〉:6,〈H〉:9,〈I〉:3,〈B E〉:4,〈C F〉:3,〈D E〉:5,〈E H〉:9,〈F E〉:4,〈B E H〉:3,〈D E H〉:3,〈F E H〉:3,.
对路径序列模式集中的每个长度不小于3的路径序列模式生成路径关联规则并计算路径关联规则置信度,存入路径关联规则数据库中.
假设交通流为自由流.在长度为L的路段上有连续行进的N辆车,其速度为V,由车流量的定义可知:
L路段上的车流量
(1)
由于本文研究对象为城市交通路网,可假设车辆在任意两个相邻交叉路口间的路段上匀速行驶,则可假设任意两个相邻交叉路口间的路段的任意截面的车流量相等.本文研究的车流量指的均为单向车流量.由车流量历史数据得到如下函数:
t=f(Q1,Q2,…,Qn)
(2)
其中,t为L路段上车辆从路段起点到路段终点所需时间,Q1,Q2,…,Qn为与该路段相邻路段上车流量.
假设T1时刻BE、DE、FE路段车流量为Q1BE、Q1DE、Q1FE,BE路段有m辆车,由公式(2)得当BE、DE、FE路段车流量为Q1BE、Q1DE、Q1FE时,车辆从E点到H点所需时间为t1,查询路径关联规则数据库conf(〈B E〉→〈H〉)=C1=75%,由定义4知T1+t1时刻将有75%m辆车到达EH路段.
假设T2时刻BE、DE、FE路段车流量为Q2BE、Q2DE、Q2FE,DE路段有n辆车,由公式(2)得当BE、DE、FE路段车流量为Q2BE、Q2DE、Q2FE时,车辆从E点到H点所需时间为t2,查询路径关联规则数据库conf(〈D E〉→〈H〉)=C2=60%,由定义4知T2+t2时刻将有60%n辆车到达EH路段.
假设T3时刻BE、DE、FE路段车流量为Q3BE、Q3DE、Q3FE,DE路段有q辆车,由公式(2)得当BE、DE、FE路段车流量为Q3BE、Q3DE、Q3FE时,车辆从E点到H点所需时间为t3,查询路径关联规则数据库conf(〈F E〉→〈H〉)=C3=75%,由定义知T3+t3时刻将有75%q辆车到达EH路段.
则T=T1+t1=T2+t2=T3+t3时刻EH路段车流量
4 应用实例
以图1中模拟交通路网为例,假设当前时刻BE路段车流量为50辆/分钟,DE路段车流量为40辆/分钟,FE路段车流量为30辆/min.〈B E〉→〈H〉这条路径关联规则的置信度conf(〈B E〉→〈H〉)=75%,conf〈D E〉→〈H〉这条路径关联规则的置信度conf(〈D E〉→〈H〉)=60%,〈F E〉→〈H〉这条路径关联规则的置信度conf(〈F E〉→〈H〉)=75%.则EH路段的车流量为QEH=50×75%+40×60%+30×75%=84辆/min.
5 结语
在深入研究GSP算法和车辆行驶路径序列特点的基础下,对传统GSP算法的候选序列模式产生方式进行了改进,挖掘出车辆行驶路径序列模式,并形成路径序列关联规则.在此基础上,结合车流量历史数据,建立了车流量预测模型.
[1] KALMAN R E,BUCY S.New results in linear filtering and prediction theory[J].Transaction of the ASME,Journal of Basic Engineering,1960,82(1):35-45.
[2] VYTHOULKASPC.Alternative approaches to short term traffic forecasting foruse in driver information systems[M].Transportation and Traffic Theory.Else-vier Science Publishers,1993.
[3] BOX G E P,JENKINS G M,MACGREGOR J F.Some recent advances in forecasting and control-2[J].Journal of Applied Statistics,1974,23(2):158-179.
[4] OKUTANI,LWAO,STEPHANEDES,et al.Dynamic prediction of traffic volume through kalman filtering theory[J].Transportation Research,1984,18(1):1-11.
[5] WILLIAMS B M.Modeling and forecasting vehicular traffic flow as a seasonal stochastic time series process[D].Department of Civil Engineering University of Virginia,Charlottesville,1999.
[6] 杨亚杰,韩印,YANG Y J.基于组合模型的交通流量预测研究[J].物流工程与管理,2017(1):80-82.
[7] 康亚男.CS优化BP神经网络的高速公路流量预测[J].公路,2017(5):194-198.
[8] SUN S L,YU G Q,ZHANG C S.Short-term traffic flow forecast using sample Markov Chain method with incomplete data[C]∥IEEE Intelligent Vehicles Symposium,Proceedings,2004:437-441.
[9] SIMMONS R,BROWNING B,ZHANG Y,et al.Learning to predict driver route anddestination intent[C]∥proceedings of Intelligent Transportation Systems Conferencee,2006:127-132.
[10] JING Y,YU Z,XING X,et al.Driving with knowledge from the physical world[C]∥proceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining.New York,USA,2011:316-324.
[11] LIU J,YU X,XU Z,et al.A cloud-based taxi trace mining framework for smart city[J].Software:Practice and Experience,2017,47(8):1081-1094.
[12] AGRAWAL R,SRIKANT R.Mining sequential patterns[C]∥proceedings of 1994 International Conference of Very Large Data Bases.Santiago,Chile,1994:487-499.
[13] SRIKANT R,AGRAWAL R.Mining sequential pattern:Generations and performance improvement[C]∥proceedings of the 5th International Conference Extending Database Technology.Avignon,France,1996:3-17.
[14] PEI J,HAN J,PINTO H.PrefixSpan mining sequential patterns efficiently by prefix-projected pattern growth[J].IEEE Transactions on Knowledge & Data Engineering,2004,16(1):1424-1440.
[15] YU X,LIU J,LIU X,et al.A MapReduce reinforced distributed sequential pattern mining algorithm[C]∥International Conference on Algorithms and Architectures for Parallel Processing.Springer,Cham,2015:183-197.
[16] 余啸,马传香,李伟亮,等.基于 MapReduce 的序列模式挖掘算法[J].计算机应用研究,2015(11):3312-3314.
猜你喜欢
工会博览(2022年5期)2022-06-30
小猕猴智力画刊(2022年3期)2022-03-29
数学小灵通(1-2年级)(2021年4期)2021-06-09
建材发展导向(2019年11期)2019-08-24
中国交通信息化(2019年12期)2019-08-13
智富时代(2018年5期)2018-07-18
智富时代(2018年5期)2018-07-18
Coco薇(2017年11期)2018-01-03
中国交通信息化(2017年9期)2017-06-06
暨南学报(哲学社会科学版)(2016年9期)2017-01-15
