
基于清晰有理数均值的新匹配聚类算法
2018-03-27 09:14尚靖博左万利
吉林大学学报(理学版) 2018年2期
尚靖博, 左万利
(1. 吉林大学 软件学院, 长春 130012; 2. 吉林大学 计算机科学与技术学院, 长春 130012)
聚类的本质是将本属于同类而因某种原因分离的事物, 按照某种逻辑和方法重新聚合的过程. 聚类主要分为层次聚类、 划分式聚类、 网格聚类和密度聚类. 层次聚类以倒树形结构排列, 通过从根节点层层向下不断聚合和分裂, 最终完成聚类. 由于倒树形结构的特性, 所以更适用于小型数据集[1]. 文献[2]的方法为典型层次聚类方法, 它先基于HTML特征和层次聚类实现Web接口查询, 再利用Web中的各种关系和相关特性建立倒树形结构, 最后通过层次聚类的方式完成聚类, 该方法在实验室的准确率可达90%以上. 划分式聚类通过预先设置好聚类的中心或数目, 经过一系列的计算最终收敛完成聚类过程. 划分式聚类在使用频率上有K均值聚类和模糊聚类等类型[1]. 文献[3]的方法为典型的划分式聚类, 它将样本数据集高维化处理, 并结合K均值聚类的方法划分出各时段的负荷差异, 实验结果表明, 该方法可以在一个长周期内稳定运行. 网格聚类和密度聚类都是基于观察样本空间中各组成部分的疏密程度完成聚类[1], 因此更适用于图像与视频的聚类. 该聚类方法最典型的是文献[4]中方法, 它利用图像由像素点组成, 且不同图像各部分的疏密程度必不同的原理聚类, 实验结果表明, 该方法对噪声数据过滤效果较好, 执行效率较高, 能更好地识别出不同类别的簇. 此外, 文献[5]利用匹配程度的量度决定隶属, 利用主成分分析决定纵向压缩, 该方法压缩率也较高. 本文通过改进文献[6]的清晰有理数均值方法, 提出一种针对人工标注型数据的聚类算法, 称为新匹配聚类算法.
1 算法描述
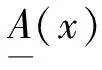
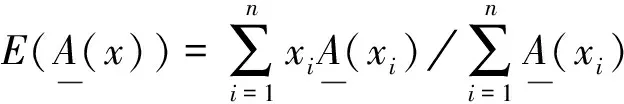
本文对清晰有理数均值方法进行如下改进: 对于论域U=(x1,x2,…,xn)(n∈), 其中x1,x2,…,xn是一组有若干重复项的自然数, 将其删除重复项后, 论域U变为论域V=(x1,x2,…,xm}(m≤n,m∈), 其中x1,x2,…,xm称为匹配项. 计算x1,x2,…,xm分别在论域U中的个数, 记作c1,c2,…,cm, 则x1,x2,…,xm在论域U中的概率记作p1,p2,…,pm. 计算有理数的均值计算结果仅取其整数位, 与匹配项匹配后, 标记与匹配项相关的信息, 标记结果即为聚类结果. 算法过程伪代码描述如下:
U={以矩阵形式表示的数据集}, //导入数据集, 其行数为i, 列数为j;
forkin range (i) { //遍历矩阵的每一行;
V=U[k].drop_duplicates( ); //删除重复项得到匹配项;
m=V.count( ); //计算匹配值的总数目;
forsin range(m) {c[s]=U[k].count(′V[s]′)}; //计算每个匹配项的数目;
forqin range (m) {sumc=sumc([q]);} //计算所有匹配项数目总和;
forbin range (m) {p(b)=c[b]/sumc;} //计算每个匹配项的概率;
fortin range (m) {
E1+=V[t]*p[t]; //计算清晰有理数的均值分子;
E2+=p[t]; //计算清晰有理数的均值分母;
E=E1/E2; } //计算清晰有理数的均值;
if (E==V[ ]) { //计算结果依次与匹配项比较, 匹配到哪项就将目标数据名加入对应的集合, 完成聚类.
A.append( );
else:
B.append( ); }}
2 实验结果与分析
为验证本文新匹配聚类算法的效果, 将其应用于非欺诈网页检测实验. 互联网的飞速发展推动了搜索引擎的提升, 但由于利益的驱使, 大批量的欺诈网页混杂于互联网中. 欺诈者采取非正常方法, 人工干预搜索引擎的排序策略, 以获取与其地位不相符的高排名, 扰乱用户对信息的获取, 甚至侵害用户利益. 所以要将非欺诈网页通过聚类的方式提取出来. 本文采用Webspam-uk2007数据集(http://chato.cl/webspam/datasets/), 其为一组由人工合作完成, 对UK域上的114 529个主机的105 896 555个页面人工标记(包括S: 欺诈网页;N: 非欺诈网页;B: 无法确定;U: 未知)所形成的数据集, 在实验中选取其中最终可确定是欺诈网页或非欺诈网页的6 053个页面作为数据集.
首先产生原始矩阵U, 对数据集中的两种标注情况(“欺诈网页”、 “非欺诈网页”)分别使用1和2替换, 缺位的用0补全, 保证数据的每一行列数相同. 然后取每一行, 删除重复元素后确定最终的匹配项x1,x2,…,xm, 计算每个匹配项的数目, 记作c1,c2,…,cm, 计算每个匹配项的概率, 记作p1,p2,…,pm, 利用匹配项和概率计算清晰有理数均值, 记作E. 若E=1, 则标记为欺诈网页; 若E=2, 则标记为非欺诈网页, 其他情况则标记为未知.
为评估其性能, 本文采用准确率、 召回率和F值作为评价标准, 公式如下:
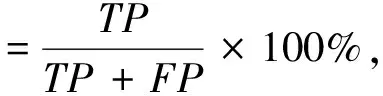
其中:TP表示非欺诈网页样本集中被标记正确的数量;TN表示非欺诈网页样本集中被标记错误的数量;FP表示欺诈网页样本集中被标记错误的数量;FN表示欺诈网页样本集中被标记正确的数量.
新匹配聚类算法在非欺诈网页检测问题的实验结果: 非欺诈网页样本集中被标记正确的数量为5 596, 非欺诈网页样本集中被标记错误的数量为113, 欺诈网页样本集中被标记错误的数量为0, 欺诈网页样本集中被标记正确的数量为334, 准确率为100%, 召回率为98.02%. 由准确率为100%和召回率为98.02%, 可计算出F值为0.99, 实验结果较好, 因此验证了本文提出的新匹配聚类算法在反欺诈网页领域的有效性及在人工标注型数据聚类的合理性. 使用传统的K最近邻算法[7]与本文算法在同一名称但不同类型的数据集上进行对比实验, 实验结果如图1所示. 由图1可见, 本文算法在反欺诈网页检测问题上具有更好的效果.
[1] 孙吉贵, 刘杰, 赵连宇. 聚类算法研究 [J]. 软件学报, 2008, 19(1): 48-61. (SUN Jigui, LIU Jie, ZHAO Lianyu. Clustering Algorithms Research [J]. Journal of Software, 2008, 19(1): 48-61.)
[2] 魏佳欣, 叶飞跃. 基于HTML特征与层次聚类的Web查询接口发现 [J]. 计算机工程, 2016, 42(2): 56-61. (WEI Jiaxin, YE Feiyue. Discovery of Web Query Interface Based on HTML Features and Hierarchical Clustering [J]. Computer Engineering, 2016, 42(2): 56-61.)
[3] 李娜, 王磊, 张文月, 等. 基于高维数据优化聚类的长周期峰谷时段划分模型研究 [J]. 现代电力, 2016, 33(4): 67-71. (LI Na, WANG Lei, ZHANG Wenyue, et al. Reasearch on the Partition Model of Long Period Peak and Valley Time Based on High Dimensional Data Clustering [J]. Modern Electric Power, 2016, 33(4): 67-71.)
[4] 田宇, 罗辛. 一种基于图像去噪的多密度网格聚类算法 [J]. 智能计算机与应用, 2016, 6(1): 44-47. (TIAN Yu, LUO Xin. A Multi Mesh Density Clustering Algorithm Based on Image Denoising [J]. Intelligent Computer and Applications, 2016, 6(1): 44-47.)
[5] 冯静, 金远平, 冯欣. 基于主成分分析及匹配聚类分析的数据表语义压缩方法 [J]. 东南大学学报(自然科学版), 2006, 36(6): 927-930. (FENG Jing, JIN Yuanping, FENG Xin. Semantic Compression for Data Tables Based on Principal Component and Matching Clustering Analysis [J]. Journal of Southeast University (Natural Science Edition), 2006, 36(6): 927-930.)
[6] 苏发慧. 清晰理论基础 [M]. 合肥: 合肥工业大学出版社, 2012: 123-126. (SU Fahui. Clear Theoretical Basis [M]. Hefei: Hefei University of Technology Press, 2012: 123-126.)
[7] Ali H, Behrouz M B. Multi-view Learning for Web Spam Detection [J]. Journal of Emerging Technologies in Web Intelligence, 2013, 5(4): 395-400.
猜你喜欢
眼科新进展(2022年12期)2022-12-29
计算机仿真(2022年2期)2022-03-15
哈尔滨工程大学学报(2021年7期)2021-07-13
成都信息工程大学学报(2021年6期)2021-02-12
成都信息工程大学学报(2021年6期)2021-02-12
汽车维修与保养(2019年7期)2020-01-06
中国外汇(2019年16期)2019-11-16
中国外汇(2019年10期)2019-08-27
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
