频率评估平台系统优化的研究
2018-04-13 03:47谭光林
数字通信世界 2018年2期
赵 哲,谭光林
(国家无线电监测中心,北京 100037)
1 引言
根据我中心现有的大数据平台技术架构,基于2016年频率使用评估工作中出现的系统响应速度较慢、存储空间不足等问题,我们希望通过对Hadoop 以及其他大数据生态环境中的最新技术进行研究,结合现存的体系架构,对系统就行改进,从而提高系统运行效率,改善系统计算性能。
2 目前架构
现有的频率使用评估平台主要采用了Hadoop2.0 大数据平台生态系统中的组件。数据存储方面采用HDFS+Kudu,系统管理和调度采用YARN,实时计算方面采用Spark+Kaf ka,数据查询采用Impala 等,相关的模块都是较为稳定的正式版本。随着Hadoop2.0的进一步发展,Hadoop3.0版本的推出,在数据的存储,资源调度等方面陆续出现了一些更加先进的模块,如用于进行数据存储的ORC和Parquet等。
除大数据平台的处理模块外,频率使用评估本身数据处理的过程中涉及到信道占用度、频段占用度、信号覆盖率等性能指标的计算和查询,涉及到大量和SQL相关的操作。从平台优化的角度出发,我们也在考虑是否可以对这些相关的数据操作进行一定程度的优化,从而提高系统的响应速度。
3 现状分析
鉴于本身平台的硬件构架方式和硬件采购成本已经决定了当前的硬件能够继续升级,但系统处理能力无法持续线性增加,所以平台优化的主要集中在对大数据平台的模块和相关指标算法方面。
对于大数据平台的模块,目前的工作思路是考虑对相关的模块进行替换,搭建实验环境,进行样本数据运算,得出实验结果,从而得出是否有更适合频率使用评估工作采用的数据处理模块。如当前的存储模块采用的是Kudu,可通过使用ORC和Parquet进行相应的替换。
对于相关性能指标的算法,可以考虑通过对SQL语句和优化,以及对于算法本身的相关研究,实现性能的提高,具体需要研究的算法,会在随后的工作中具体明确的提出。
4 最新技术
频谱使用评估分析与应用系统现由6台服务器组成计算机集群,提供共计84T的存储容量。通过2016年频谱评估专项活动,各省上报原始监测数据约31T,入库后数据量约为62T,大约2亿条记录。采用分布式存储技术、海量数据传输处理技术、海量数据交互式查询技术等构建系统的大数据支撑平台及各种业务应用。
通过数据校验、数据处理、数据分析以及数据应用及展示这四大子系统,实现原始监测数据从上报到入库,到计算、分析,再到数据展现全过程的信息化,同时根据专项活动中对公众移动通信频段的评估工作的要求,通过统计图表等方式,直观、准确地反映了频谱使用的实际情况,为频谱管理精细化提供决策支持。
综合频率评估平台软硬件构建方式,平台的优化可以从硬件配置、处理模块和相关算法等三个方面进行入手。
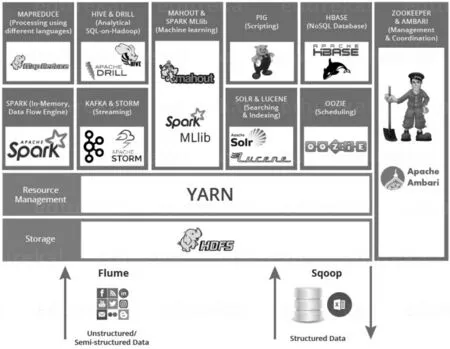
图1 Hadoop3.0生态系统
从数据存储和数据计算两个方面入手,我们对Hadoop3.0生态圈中的最新技术进行了筛选和考察,从中挑选出了部分适合现有平台采用的技术。接下来重点介绍我们实验环境中会用到的相关技术手段,并进行初步的对比。
⊙ 在Hadoop3.0中实现的Integrating Erasure Coding备份方式在实现了传统Erasure Coding 备份的基础上,提高了磁盘空间的利用率。例如:一个提供3倍冗余的的文件备份,假如每个文件需要6个数据块进行存储的话,那么需要6*3=18个磁盘块,而如果采用Interating EC的方式,实现相同3倍冗余备份,只需要9个磁盘块。
⊙ Kudu是Cloudera开发的存储系统,其整体应用模式和HBase比较接近,即支持行级别的随机读写,并支持批量顺序检索功能。
⊙ Parquet是面向分析型业务的列式存储格式。列存储可以跳过不符合条件的数据,只读取需要的数据,降低IO数据量。压缩编码可以降低磁盘存储空间。
⊙ ORC(OptimizedRC File)存储源自于RC(Record Columnar File)这种存储格式,RC是一种列式存储引擎,对schema演化(修改schema需要重新生成数据)支持较差,而ORC是对RC改进,但它仍对schema 演化支持较差,主要是在压缩编码,查询性能方面做了优化。
⊙ Storm是一个免费并开源的分布式实时计算系统。利用Storm可以很容易做到可靠地处理无限的数据流,像Hadoop批量处理大数据一样,Storm可以实时处理数据。
⊙ Spark是一个基于内存计算的开源的集群计算系统,目的是让数据分析更加快速。Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越。换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
5 优化实验
接下来我们进行了三次模拟环境下的数据存储和计算实验。实验环境和实验流程如下:
实验环境:
⊙ 主机数量 10台,其中台式电脑8台,笔记本2台。
⊙ 所有主机统一接入到一台路由器,配置相应的IP网段,进行互联互通。
实验流程:
⊙ 试验环境搭建。
⊙ 相应组件安装。
⊙ 测试数据导入。
⊙ 测试例执行。
⊙ 实验结果采集。
5.1 EC校验
目前我们的频率评估系统采用了主流的Hadoop2.0中RAID存储和备份方式,也就是在数据保护方面采取了传统的Erasure Coding的方式,我们希望通过本实验,可以达到未来能够将系统的存储备份方式升级提高到Integrat ing Erasure Coding的模式下,从而提高系统的存储备份率。
5.2 Parquet、Kudu和HBase等的对比实验
目前我们的频率评估系统采用了Kudu作为数据的存储系统,我们希望通过本实验,测试在相同数据条件下,是否可以通过ORC或者Parquet来进一步提高数据的查找和计算速度,从而提高系统的整体性能。
5.3 Impala,Kudu,Presto和Spark的计算和对比
目前我们的频率评估系统采用了Spark+Impala 的方式在进行上层的数据处理和任务分解。希望通过本实验,测试在相同数据条件下,未来如果数据的采集方式发生改变,是否可以通过Stream组件提供流式计算处理能力。
6 实验结果
6.1 EC实验分析
经过实验测试,我们得到实验结果见表1:
EC技术的优势确实明显,但是它的使用也是需要一些代价的,一旦数据需要恢复,EC会造成两大资源的消耗。
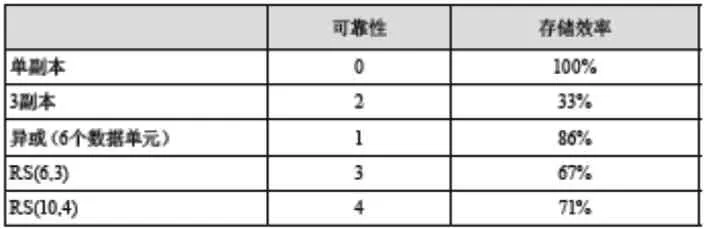
表1 存储实验
⊙ 网络带宽的消耗,因为数据恢复需要去读其他的数据块和校验块。
⊙ 进行编码,解码计算需要消耗CPU资源。
综合考虑,在需要进行数据恢复时,EC既耗网络又耗CPU,从实际环境部署的角度来分析,代价也较高。所以将此技术用于线上服务可能会不够稳定,最好的选择是用于冷数据集群:
⊙ 冷数据集群往往有大量的长期没有被访问的数据,体量确实很大,采用EC技术,可以大大减少副本数。
⊙ 冷数据集群基本稳定,耗资源量少,所以一旦进行数据恢复,将不会对集群造成大的影响。
出于上述二种原因,冷数据集群无非是一个很好的选择。
6.2 Parquet、Kudu和HBase等的对比实验
6.2.1 空间利用
根据测量结果,利用Kudu和Parquet编码的数据提供了最佳的压缩率。与使用MapFiles的原始数据集编码相比,使用类似Snappy或GZip之类的压缩算法可以进一步显著减少数据量达10倍。由于HBase存储数据的方式是一个空间效率较低的解决方案,虽然HBase块的压缩给出相当好的比率,但是与Kudu和Parquet相比差距仍然较大。
6.2.2 提取速度
由于Apache Impala执行数据重构以串行写入单个HDFS目录(Hive分区),因此对于HDFS格式和HBase或Kudu的格式,可以直接比较单个数据分区撷取效率。使用Avro或Parquet编码写入的HDFS 文件比存储引擎(如HBase和Kudu)提供了更好的结果(至少5倍)。
使用Avro或Parquet编码写入的HDFS文件比存储引擎(例如HBase和Kudu)提供了更好的结果(至少5倍)。由于Avro具有最轻量的编码器,因此其实现了最好的撷取性能。
另一方面,在这个测试中HBase非常慢(性能比Kudu差)。这很可能是由于行键的长度(6个并置列)引起的,其平均约为60个字节。HBase必须为一行中的每一列分别编码一个键,这对于长记录(包含许多列)可能不是最佳的方法。
6.2.3 随机数据查找延迟
当通过记录键访问数据时,因为使用了内置索引,Kudu和HBase的访问速度是最快的。图上的值都是基于冷缓存(cold cache)进行测量。
使用Apache Impala进行随机查找测试对于Kudu和HBase来说是次优选择,因为在真正执行查询(计划、代码生成等)之前耗费了大量的时间—通常大约是200ms。因此,对于低延迟数据访问,建议跳过Impala并使用专用API(我们也尝试过这种方法,Kudu和HBase的结果类似:冷缓存小于200ms,预热缓存小于80ms)。
与Kudu和HBase相反,检索以Avro格式存储的单个记录中的数据只能在对整个数据分区的强力扫描中完成(需要注意的是 – 数据由记录键的一部分进行分区,因此针对这种情况应用分区修剪技术)。平均分区的大小为GB级,因此获取所需的记录需要耗费几秒钟的时间(取决于IO吞吐量),并使用大量的集群资源。这最终减少了必须在集群上全速执行的并发查询的数量。
同样的问题也适用于Parquet,然而,Parquet格式的柱状特性允许相对快速地执行分区扫描。由于列投影和列谓词的下推,扫描输入集的大小最终从数GB减少到只有几MB(非常高效,56列经过扫描后只剩下3列)。
6.2.4 数据扫描速率
由于通过应用列投影输入集数量减少,Parquet 在此测试中胜过了Avro。Parquet不仅在每內核处理速率方面保持了最高效率,同时也在完成处理方面保持最快速度。在Parquet和Avro的情况下,数据访问并行化的单位是HDFS文件块,其很容易在Hadoop集群上的所有可用资源上均匀分布处理。
在扫描效率方面,Kudu(采用Snappy压缩)与Parquet相差不大。因为列投影,其受益匪浅。
由于数据访问并行化的单位是表分区,扫描存储在Kudu和HBase中的数据可能不平衡。因此,扫描中涉及的资源量取决于给定表分区的数量及其在集群中的分布。
在这个测试案例中,因为Kudu不支持谓词,所以不可能使用Kudu的本地谓词下推功能。附加测试结果证明,当使用支持的谓词时,Kudu扫描速度比Parquet更快。
在使用HBase进行测试之前,扫描的列在专用HBase列族中被分离,这就提高了5倍的扫描效率。但仍然与Parquet或Kudu存在较大差距。
6.3 Impala,Kudu,Presto和Spark的计算和对比实验分析
6.3.1 计算引擎速度对比

表2 计算速度实验一

表3 计算速度实验二

表4 计算速度实验三

表5 计算速度实验五

表6 计算速度实验六
6.3.2 存储格式速度对比

表7 存储速度实验一

表8 存储速度实验二

表9 存储速度实验三
[1] Zikopoulos,Paul,and Chris Eaton.Understanding big data:Analytics for enterprise class hadoop and streaming data.McGraw-Hill Osborne Media,2011.
[2] White,Tom.Hadoop :The definitive guide.” O’Reilly Media,Inc.”,2012.
[3] Gray,S.,et al.”IBM Big SQL 3.0 :SQL-on-Hadoop without compromise.”(2014).
[4] Masur,Rohit G.,and Suzanne K.Mcintosh.”Preliminary performance analysis of Hadoop 3.0.0-alpha3.” Scientific Data Summit(NYSDS),2017 New York.IEEE,2017.
[5] Vidhyavathi,P.“A Review On Hadoop :Privacy For A Multi-Skyline Queries With Map Reduce.” IJSEAT 5.10(2017):1004-1007.
猜你喜欢
大众科学(2022年5期)2022-05-18
环球时报(2022-03-29)2022-03-29
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
军事运筹与系统工程(2019年4期)2019-09-11
疯狂英语·新读写(2018年3期)2018-11-29
电子制作(2018年11期)2018-08-04
知识经济·中国直销(2018年7期)2018-07-27
中国交通信息化(2017年3期)2017-06-08