
采用多样性选择的量子粒子群双向聚类算法
2018-05-08 07:51陈佳瑜
计算机工程与应用 2018年9期
陈佳瑜,李 梁,罗 云
CHEN Jiayu,LI Liang,LUO Yun
重庆理工大学 计算机科学与工程学院,重庆 400054
College of Computer and Engineering,Chongqing University of Technology,Chongqing 400054,China
1 引言
随着生物技术的迅速发展,出现了基因芯片和DNA微阵列等高通量检测技术,人们已经可以对某一特定状态下的组织或细胞进行基因表达谱的测序,而具有相似表达谱的基因之间很有可能存在某种联系。目前,基因表达数据分析最常用的方法是聚类,将表达水平相近的基因聚在同一个类中,从而可以发现未知基因的功能和具有生物科学价值的基因信息。但是传统的聚类在分析基因数据时会受到很大的限制,于是Cheng和Church[1]首次提出了双向聚类的概念,并通过贪婪策略逐步增删使得双向聚类的均方残差达到最优。但算法中使用随机数替换已找到的双向聚类,这样会改变原来的数据造成误差,并且容易陷入局部最优。2003年时被提出的FLOC[2]算法先产生一定数量的种子,再通过增加或删除行列的方式提高双向聚类的质量。此后又产生了耦合双向聚类[3]、结合模糊C均值的双向聚类算法[4]、贝叶斯双向聚类模型[5]、并行双向聚类算法[6]、基于格子模型的双向聚类[7]、SAMBA算法[8]、使用模拟退火模型寻找双向聚类[9]等双向聚类算法。
双向聚类算法实际上是一种多目标优化的局部搜索算法,对于繁杂的基因数据矩阵,如果直接对其进行双向聚类,显然是不合理的。本文采用的方法是先对整个基因矩阵全局寻优,将找到包含最优解的子矩阵作为种子,在对其进行双向聚类。
2 量子粒子群优化算法
粒子群(PSO)算法[10]是Kennedy和Eberhart于1995年提出的一种智能优化算法,自被提出以来就受到了广泛的关注,并在解决实际问题中显示了其优越性。但是在目前已有的PSO算法中,粒子只能沿着特定的轨迹搜索,从而不能保证以概率1收敛到全局最优,甚至不能收敛到局部最优[11]。文献[12]根据人类群体自组织性和协同性等特点,认为每个个体都可以用量子空间中的一个粒子来描述,建立量子的δ势阱模型,开发了一种新的群体智能算法——具有量子行为的粒子群优化(Quantum-behaved Particle Swarm Optimization,QPSO)算法。
在QPSO基因聚类问题中,给定一个M×N的基因矩阵A,将M条基因划分到K个聚类中去。通过粒子在搜索空间中的飞行搜索,选出代表问题解决方案的最优粒子。每一个粒子 Xi=(Mi1,…,Mij,…MiK)代表K个聚类的质心向量,Mij表示第i个粒子中第 j个聚类的中心向量。Pi(t)为个体最好位置,G(t)为全局最好位置,且G(t)=Pg(t),g为处于全局最好位置的粒子的下标。
在QPSO算法中,粒子的更新方程为:

QPSO算法不需要粒子的速度信息,β为收敛-发散因子,是除了群体规模和迭代次数外唯一的一个参数,相对于PSO算法,QPSO具有进化方程简单,控制参数少,收速度快,运算简单等优点。
3 双向聚类与FLOC算法
如图1所示,双向聚类抛弃了传统聚类只从单方向上寻找相似特征,而是同时从行和列两个方向进行聚类,这样可以找到隐藏在局部数据中的生物信息。
对于一个m行n列的矩阵A,AIJ为A的一个子矩阵,其中I为行(基因)的子集,J为列(条件)的子集,若AIJ的均方残差[1]值满足一定的条件,则称AIJ为一个双向聚类;其中,均方残差的计算公式为:
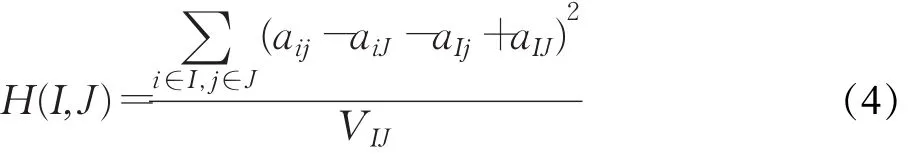

图1 传统聚类和双向聚类
其中,aij为AIJ的有效元素,aiJ、aIj和aIJ分别为行平均值、列平均值和矩阵平均值。
FLOC(Flexible Overlapped Biclustering)算法是一种经典的双向聚类算法。该算法定义了一个收益函数衡量插入或删除某行(列)后矩阵质量的变化,通过插入或删除具有最高收益的行(列)的方式来提高双向聚类的质量,进而改进整个双向聚类种群的质量,最终得到最优双向聚类集。它可以在避免随机干涉的情况下,同时产生多个可能相互重叠的双向聚类。
FLOC算法的流程为:
步骤1计算基因矩阵各行(列)的收益值。
步骤2对各行(列)的最高收益进行排序。
步骤3按顺序插入或者删除这些行(列)。
步骤4判断执行动作后,双向聚类的平均容量是否增大,若增大则保存最优双向聚类作为下一次迭代的初始值,回到步骤1继续迭代;否则,算法结束,输出当前最优双向聚类。
4 基于多样性选择的QPSO双向聚类算法
4.1 基于多样性选择的QPSO算法
QPSO算法在搜索开始时,多样性相对比较高。但是在随后的搜索过程中,由于粒子的逐渐收敛,群体的多样性不断下降,导致大部分粒子都在做局部搜索,而全局搜索能力越来越弱。此时,如果全局最好位置位于局部最优区域或次优区域,算法就会陷入早熟。2002年,Ursem[13]提出了一个多样性引导的进化算法(DGEA)。同年,Riget等人[14]在PSO中引入Ursem多样性控制的思想,提出了吸引-排斥粒子群算法(ARPSO)。受其启发,提出了一种多样性选择的量子粒子群双向聚类算法(Diversify-Optional QPSO,DOQPSO)。
4.1.1 相似性度量
DOQPSO算法中已知基因表达矩阵A=(X,Y),包含M条基因和N个样本条件,在使用欧几里德距离作为相似性度量的基础上,将该数据集合划分为指定的K类,使所得到的聚类划分能使总体类间差异[15](TWCV)最小。
用Ak表示第k个基因聚类,xin表示在当前聚类中第i个基因在第n个样本条件下的表达水平;ZK为Ak中质心向量的个数,则 Ak的质心向量为Ck=(ck1,ck2,…,ckn),且。定义聚类Ak中类内适应度函数WCV为:
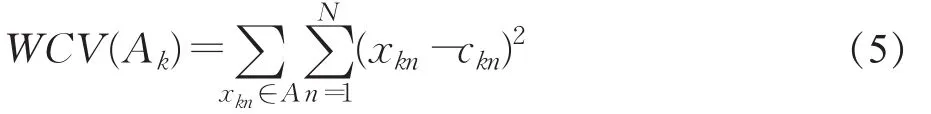
则TWCV可以表示为:

该适应度函数是每种聚类的类内适应度函数WCV的和,WCV的值越小说明类内各个对象彼此更紧密,聚类质量越好。
4.1.2 多样性度量
ARPSO算法根据粒子的多样性,可以在全局搜索和局部搜索之间进行切换,增强了在多峰优化问题中寻找全局最优解的概率。粒子多样性度量的公式如下[13-14]:

其中,S表示粒子群,||L表示求解空间最长对角线的长度,N表示问题的维数。
在DOQPSO算法中,单个粒子的收敛性是受收敛-发散因子β控制的。粒子进入收敛状态,种群的多样性减小,粒子进入发散状态,种群的多样性增多。粒子群在初始化后会进入收敛状态,这时β会从1.0线性减小到 0.5,如公式(9)所示:

文献[16]中已证明,以公式(1)为进化方程的QPSO算法中,单个粒子收敛的充分必要条件是β<1.782。所以存在 β0=1.782,当 β<β0时,粒子收敛;当 β≥β0时,粒子进入发散状态。
所以算法中另外定义了一个多样性下限值d_low,如果粒子群的diversity(S)低于d_low,说明粒子的多样性过少,需进入发散状态,此时重新设置β的值,且β>1.782,这样可以增加粒子的多样性,直到diversity(S)大于d_low,粒子重新进入收敛状态。
算法流程为:
输入:聚类的个数K,基因表达数据集A,最大迭代次数GMAX,d_low和微粒数N。
输出:最后的聚类质心向量,K个聚类。
步骤1初始化每个粒子,使每个微粒中包含K个聚类质心。
步骤2初始化粒子群的局部最优位置pbest和全局最优位置gbest。
步骤3当迭代次数小于GMAX时,计算粒子群的平均最好位置C和多样性函数diversity(S)。
步骤4粒子群进入收敛状态,根据公式(9)计算β值。
步骤5如果diversity(S)小于d_low,则设置β>1.782。
步骤6根据公式(6)计算适应度函数TWCV;由公式(1)更新粒子的 pbest和种群的gbest。
步骤7回到步骤3,直到达到最大迭代次数。
步骤8将全局最优位置gbest映射为K个聚类质心,对数据进行划分,得到K个聚类。
4.2 多目标优化的FLOC算法
FLOC算法有两个目标,一是双向聚类的剩余值尽可能小,二是双向聚类的容量尽可能大,这是一个多目标优化问题[17-18]。但是FLOC算法判断进步的依据仅为容量是否增大,只要有一组的双向聚类的平均容量比初始化的要大,则认为这一次的执行序列执行是有进步的,迭代继续,这明显是不合理的。
多目标优化算法本质上是通过某种方式将复杂的多目标问题转化成容易处理的单目标问题[19],然后利用单目标优化技术进行求解。常用的多目标优化算法有多种求解方法,这里采用评价函数法[20]。
用评价函数F(k,A)来计算FLOC算法在一次迭代中产生的双向聚类的质量,F(k,A)的计算公式如下:

F(k,A)表示原基因矩阵A的第k个双向聚类矩阵的质量,rk是它的平均平方残差,vk是它的容量,λ1和λ2分别是均方残差和容量的权值。F(k,A)越小,就表示这个双向聚类矩阵的质量越好,相反,F(k,A)的值越大就表示这个双向聚类矩阵的质量越差。
4.3 基于DOQPSO的FLOC算法思想
算法首先使用DOQPSO算法对原矩阵进行划分;然后对划分后的子矩阵进行FLOC聚类,使用公式(10)作为评价函数。其算法流程如图2所示。
基于DOQPSO的FLOC算法流程:
步骤1数据初始化,使用多样性选择的QPSO算法产生k个初始矩阵。
步骤2分别计算这k个双向聚类矩阵每一行和每一列的动作收益。

图2 DOQPSO双向聚类算法执行流程图
步骤3比较收益值的大小,得到各行各列的最优动作。
步骤4对这些最优动作排序,并按顺序依次执行。
步骤5执行动作后,根据公式(10)判断双向聚类的质量是否有所提高,若有,则保存最优双向聚类作为下一次迭代的初始值,回到步骤1继续迭代;否则,算法结束,输出当前最优双向聚类。
5 实验及讨论
5.1 实验数据与环境
为了评价双向聚类的质量,采用均方残差(MSR)、矩阵规模(V)和行变动值(Var)作为基因矩阵表达一致性的度量标准[1]。目标是找到的双向聚类均方残差要尽可能小,规模和行变动值要尽可能大。行变动值(Var)的计算方法如公式(11)所示:
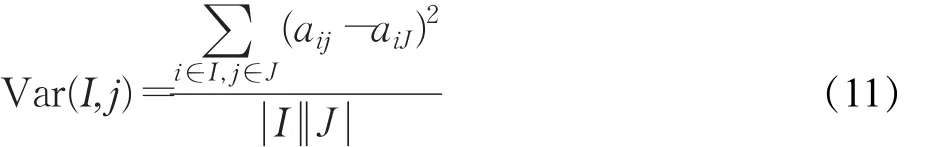
实验使用急性白血病基因表达[21](Leukaemia)数据集和酵母菌基因表达数据集[22](yeast)。
急性白血病数据集共有38个急性白血病样本和7 129个基因,其中,27个被诊断为急性淋巴性白血病(ALL),11个被诊断为急性骨髓性白血病(AML),所以聚类数为两类。
酵母菌数据集包含2 884个基因,17个样本。标准类的划分是根据基因表达水平达到峰值的时相进行的,这些基因都是在单个时相达到峰值,细胞周期共分为5个时相,所以将这些基因划分为5个标准类。
实验在装有Win10系统的PC机上运行,CPU为Intel酷睿i5,4 GB内存,实验环境为MATLAB R2014a。
5.2 实验结果及分析
算法将与QPSO、多目标优化的FLOC算法,以及未改进的FLOC算法进行比较。粒子群规模为40,迭代次数300次;将急性白血病数据集聚为两类,酵母菌数据集聚为5类;通过实验确定公式(10)中参数 λ1取1,λ2取1.8;d_low 设置为0.000 5[16]。
表1、表2分别是FLOC算法、多目标优化的FLOC算法(FLOC2)、QPSO算法和DOQPSO双向聚类算法在两个数据集上10次实验的平均值。
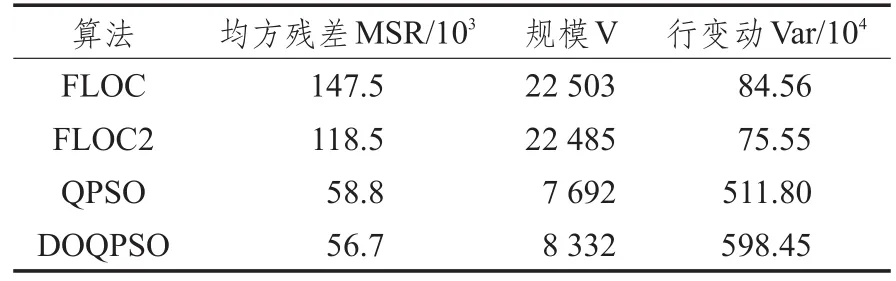
表1 四种算法在Leukaemia上的实验结果

表2 四种算法在yeast上的实验结果
从表中前两行可以看出,多目标优化的FLOC算法的均方残差值比FLOC算法分别减小了19%和6%,改进后的FLOC算法虽然在规模上略有减小,但相差不大,所以用了多目标优化的FLOC算法表现结果更佳;从表中后两行可以看出DOQPSO和QPSO算法的均方残差值相较于FLOC算法有明显减小,这是因为算法先对数据集进行了划分,从繁杂的基因数据划分为若干个表达波动相似的块,剔除了不相关甚至会产生干扰的数据,当然这也导致了在第二阶段得到的聚类矩阵的容量有所减少,但是和FLOC算法相比,得到的聚类矩阵相似性更集中,总体上质量有很大幅度提高;DOQPSO和QPSO算法相比,虽然规模相差不大,但是DOQPSO均方残差明显减小。说明DOQPSO相较于QPSO算法在性能上有所提高,聚类效果更佳。
6 总结
基因表达数据繁杂且没有规律,对其进行聚类分析,得到表达波动行一致的子基因矩阵又是一个多目标优化问题,针对这些问题,本文提出了一种DOQPSO双向聚类算法。算法先利用有多样性控制的量子粒子群算法处理基因数据,根据多样性度量函数的值判断粒子的状态,以提高算法的全局搜索能力;再结合FLOC算法,修改其迭代目标函数,弥补了FLOC算法在处理多目标优化问题时的不足。经过实验证明,本文提出的算法具有较好的全局寻优能力,且聚类效果更佳。
参考文献:
[1]Cheng Y,Church G M.Biclustering of expression data[C]//Proceeding of the 8th International Conference on Intelligent Systems for Molecular Biology.[S.l.]:ACM Press,2000:93-103.
[2]Yang Jiong,Wang Wei.Enhanced biclustering on gene expression data[C]//Proceedings of the 3rd IEEE Conference on Bioinformatics and Bioengineering,2003:321-327.
[3]Getz G,Levine E,Domany E.Coupled two-way clustering analysis of gene microarray data[C]//Proceedings of the Natural Academy of Sciences of the United States of America,2000,97(22):12079-12084.
[4]Qu Jinbin,Michael N,Chen Luonan.Constrained subspace clustering for time series gene expression data[C]//4th InternationalConferenceon ComputationalSystems Biology,2010:9-11.
[5]Gu Jiajun,Lee J S.Bayesian biclustering of gene expression data[C]//International Conference on Bioinformatics and Computational Biology,2007:25-28.
[6]刘维,陈崚.基因表达数据的并行双向聚类算法[J].小型微型计算机系统,2009,30(4):683-689.
[7]Lazzeroni L,Qwen A.Plaid models for gene expression data[J].Statistica Sinica,2002(12):61-86.
[8]Tanay A,Sharan R,Kupiec M,et al.Revealing modularity and organization in the yeast molecular network by integrated analysis of highly heterogeneous genomewide data[C]//Proceedings of the National Academy of Sciences of the United States of America,2004,101(9):2981-2986.
[9]Bryan K,Cunningham P,Bolshakova N.Biclustering of expression data using simulated annealing[C]//18th IEEE Symposium on Computer-based Medical Systems,2005:383-388.
[10]Kennedy J,Eberhart R.Particle swarm optimization[C]//IEEE International Conference on Neural Networks,1995,4:1942-1948.
[11]周崸,孙俊,须文波.具有量子行为的协同粒子群优化算法[J].控制与决策,2011,26(4):582-586.
[12]Sun J,Feng B,Xu W B.Particle swarm optimization with particles having quantum behavior[C]//Proceedings of the Congress on Evolutionary Computation,2004:325-331.
[13]Ursem R K.Diversity-guided evolutionary algorithms[C]//Proceedings of the 7th International Conference on Parallel Problem Solving from Nature.Berlin Heidelberg:Springer,2002:462-471.
[14]Riget J,Vesterstrøm J S.A diversity-guided particle swarm optimizer-the ARPSO,Technical Report no.2002-02[R].EVALife,2002.
[15]高倩倩,须文波.量子行为粒子群算法在基因聚类中的应用[J].计算机工程与应用,2010,46(21):152-155.
[16]孙俊.量子行为粒子群优化算法研究[D].江苏无锡:江南大学,2009.
[17]刘文华,梁永全,冯政.基于加权均方残差的改进双聚类算法[J].模式识别与人工智能,2016,29(6):519-526.
[18]Das C,Maji P.Possibilistic biclustering algorithm for discovering value-coherent overlapping δ-biclusters[J].International Journal of Machine Learning&Cybernetics,2015,6(1):95-107.
[19]郭红,蔡莉.采用多目标微分进化算的基因表达数据双向聚类算法[J].小型微型计算机系统,2010(10):1997-2001.
[20]Cunningham S W,van der Lei T E.Decision-making for new technology:A multi-actor,multi-objective method[J].Technological Forecasting&Social Change,2009,76(1):26-38.
[21]Golub T R,Slonim D K,Tamayo P,et al.Molecular classification of cancer:Class discovery and class prediction by gene expression monitoring[J].Science,1999,286(12):205-214.
[22]Cho R J,Campbell M J,Winzeler E A,et al.A genomewide transcriptional analysis of the mitotic cell cycle[J].Molecular Cell,1998,2(1):65-73
猜你喜欢
出版人(2022年11期)2022-11-15
网络安全与数据管理(2022年3期)2022-05-23
今日农业(2021年19期)2021-11-27
数学小灵通(1-2年级)(2021年10期)2021-11-05
北京航空航天大学学报(2020年10期)2020-11-14
铁道通信信号(2019年6期)2019-10-08
自动化学报(2019年6期)2019-07-23
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
通信电源技术(2016年5期)2016-03-22
