
基于后缀树算法的地区微博摘要技术研究
2018-05-08 07:51高永兵张贵娟胡文江马占飞
计算机工程与应用 2018年9期
高永兵,张贵娟,胡文江,马占飞
GAO Yongbing1,ZHANG Guijuan1,HU Wenjiang1,MAZhanfei2
1.内蒙古科技大学 信息工程学院,内蒙古 包头 014010
2.包头师范学院 计算机系,内蒙古 包头 014010
1.School of Information Engineering,Inner Mongolia University of Science and Technology,Baotou,Inner Mongolia 014010,China
2.Department of Computer,Baotou Teachers College,Baotou,Inner Mongolia 014010,China
1 引言
随着大量组织机构平台微博的开通,官方微博开始进入人们的视野,官方微博是经过官方认证后的微博,即真实性已通过验证。其博文信息不但具有权威性、组织性、真实性,而且还具有地区性。通过观察发现官方微博中包含地区性相关事件的微博数据量很多,用户想从中获取有价值的地区事件信息,逐条阅读微博数据造成时间浪费,若针对官方微博中的地区微博进行聚类形成事件摘要,将大大提高用户获取地区事件信息的效率,且地区官方微博数据很容易从新浪微博提供的应用程序接口(Application Programming Interface,API)中爬取,因此对地区官方微博数据进行自动摘要技术研究具有重要意义。目前针对地区官方微博摘要研究还很少,地区官方微博在形成摘要时有如下挑战:(1)地名别称及地区不同层级划分;(2)混杂了除本地区外的事件信息;(3)地区标签属性突显等特征,因此进行事件摘要时要充分考虑这些特征。
例如张家口地区官方微博的3条博文信息:
W1:#河北张家口涿鹿县3.2级地震#…张垣涿鹿县发生3.2级地震,震源深度15千米…。
W2:#地震快讯#…广州省汕尾市陆丰市…发生3.8级地震,震源深度16千米…。
W3:#涿鹿县地震 北京多地有震感#…河北省张家口市涿鹿县发生3.2级地震。多名北京网友表示石景山、门头沟有震感… 。
从以上例子可以看出张家口地区微博信息中有广州省汕尾市陆丰市地震事件信息,当进行事件聚类时,可能将与本地区的地震事件聚类一起提取出来。同时张家口地区微博信息中存在着地区别称(如:张家口别称张垣)和地区不同层级划分(如:张家口下的涿鹿县)的特征。此外还存在相似事件或同一个事件所强调突出的不同如何进行描述的选择(如涿鹿县地震、北京多地有震感),这需要进一步从微博的社会特征、地区标签属性上来判断。因此如何将不是本地区事件信息过滤掉提取出重要的不同层级的本地区事件摘要信息是本文的重点。
针对微博的事件聚类的研究,目前国内外也已经取得了很多成果。如下:童薇等[1]提出了基于主题模型的微博事件检测方法,充分利用了数据语义相似度、时序相似度和社交关系相似度。Long Rui等[2]提出了4个基准选取话题关键字,从而建立图模型进行聚类。Phuvipadawat S等[3]提出了基于命名实体加权的改进TF-IDF(Term Frequency-Inverse Document Frequency,词频和逆向文件频率)方法。Weng Jianshu等[4]提出了一种基于小波分析的图模型。而Sakaki T等[5]提出了基于概率的时空模型来提取主题事件。以上所述主要针对是公众微博的聚类,并没有考虑地区别称特征,对于语义上相关、相同地区的微博内容聚类效果不好。
聚类是帮助用户在浩如烟海的微博数据中快速、有效地找出有价值的事件,但针对事件的详细信息,需要进一步研究形成事件摘要,即聚类是事件摘要的一个前提,它们之间有着密切的联系。
目前关于自动摘要技术的研究,大多数主要关注如何选取句子,比较有代表性的研究如下:Sharifi B等[6-7]提出面对微博自动摘要Hybrid TF-IDF和词语加强方法。Wang Peng等[8]使用隐马尔科夫模型描述事件的发展过程从而对该事件进行摘要。Duan Yajuan等[9]提出了使用相互增强式图模型同时考虑文本内容、作者社会影响力对文本质量的影响,抽取高质量的摘要。彭敏等[10]提出了基于时频转换的信息提取方法,获得高质量的微博摘要。以上所述都是针对公众微博进行研究的,对于微博中的地区层次区别并没有考虑。
为此,本文针对地区官方微博数据,提出了一种基于后缀树算法的地区微博摘要技术研究。充分考虑地区微博的特征,首先把地区微博数据进行预处理,将不是本地区的微博信息过滤掉,并应用知网HowNet[11-12]、地区权值树,进行语义相似度及地名替换,使其更好地实现事件聚类;然后,应用后缀树聚类(Suffix Tree Clustering,STC)方法、奇异值分解(Singular Value Decomposition,SVD)来进行事件聚类;最后,对地区微博计算标签属性、地区名称、社会特征的权值得分,选取权值较高的微博句子作为事件摘要。
本文第2章介绍针对本文地区微博中地区别称、地区不同层级区分问题提出的地区权值树,第3章介绍本文事件聚类算法,第4章介绍本文进行提取事件摘要的方法,第5章介绍实验过程及对实验结果进行的分析,最后对工作进行总结展望。
2 地区权值树
本文的研究目标是从地区历史微博中挖掘出与本地区相关的重要事件。而对于本地区这个名词存在着地区别称、地区不同层级区分问题,因此本文综合地区微博的特征提出了应用地区权值树来解决以上两个问题。
定义1(地区权值树)根据地区不同层级建立的一棵树,最高级别的地区名称为根节点,其下的子树为其下一级别地区名称节点,并以此类推。并且树中的节点包含地区别称和地区不同层级的权值。
地区权值为了能够区分用户主要想了解的地区事件。某地区微博中也包括了其所属省及其下许多县乡等事件信息,如何区别主次事件信息,需要地区权值树中的权值设定来区分。
如:主要想了解张家口地区近两年的事件信息时,出现张家口下县乡的事件信息,把张家口的权值以某种缓慢递减的方式赋给县乡,出现河北省的事件信息时,把张家口的地区权值以某种快速递减的方式赋给河北省,并以此类推,这样保证提取出的事件信息与张家口市最大相关。
地区别称为了解决地区微博中出现的地区名称不统一的情况,同时为了得到更好、更精准的事件聚类信息,所以本文选择在进行事件聚类之前应用地区权值树将地区名称统一。
如:河北-冀,张家口-张垣、山城等。
如图1所示为河北省地区权值树。
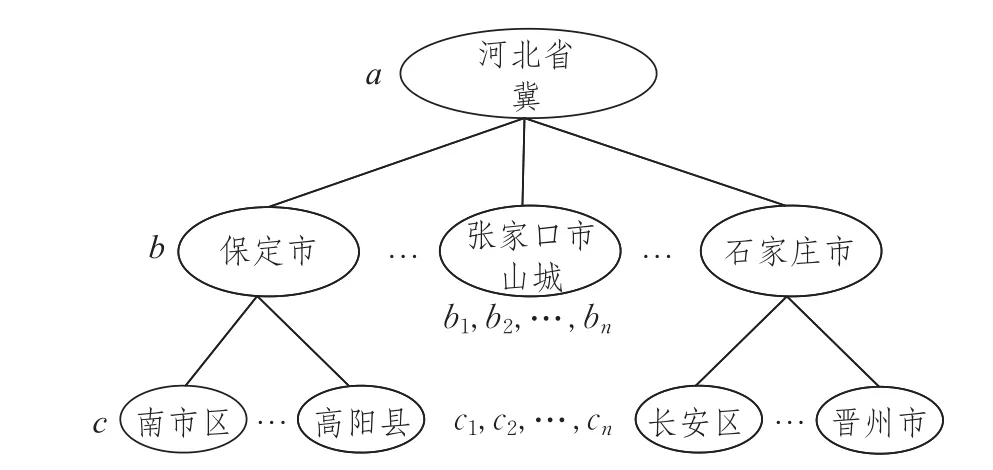
图1 河北省地区权值树图
3 事件聚类
在进行好数据预处理(去除本地区外的事件信息和地区别称、语义相似度替换)之后,本文针对事件聚类首先采用STC算法发现频繁短词束,并通过SVD提取抽象概念和聚类标签,最后应用Jaccard[13]相似系数进行聚类合并。这个部分分为:后缀树建立、基本类选取、聚类标签选取、聚类合并。
3.1 后缀树建立
STC算法是一种直观的聚类算法,它将文本聚类为一组的依据是文本含有共同的短语。实际上是将文本看成词的序列,充分利用了词与词之间的距离信息,在寻找文本共同的最大短语的过程中使用了后缀树这种数据结构,其聚类效果很好。
后缀树的特征:后缀树中的每一个内部节点v都代表着一组文档,并且从根节点到该内部节点vp的标识为这组文档所共享的短语。所有从v开始的节点对应的叶子都是字符串vp的后缀,所以包含vp的文档集能由这些叶子的标志信息得到。
因此,可以利用后缀树的特征快速获得最大短语束。
如下是针对张家口地区“2022年冬奥会”事件进行建立后缀树数据结构的例子。
首先,在对微博数据进行预处理(其中包括语义相似度替换、地区别称的统一),STC算法为每一条微博构造所有的词语后缀,每一条微博用D={D1,D2,…,Dn}表示。如下是4条经过预处理后的微博信息。
D1.成功 冬奥会
D2.山城 获得 举办 2022年 冬奥会(“山城”替换成“张家口”)
D3.张家口 2022年 冬奥会 主办 城市(“主办”替换成“举办”)
D4.北京 携手 张家口 冬奥会 申办 成功
针对微博D1到D4的后缀树数据结构如图2所示。
3.2 基本类选取
使用后缀树数据结构识别基本类。在后缀树中每一个节点代表一个基本类,框节点表示从根节点到当前节点词项串联的连贯短语在哪些微博中出现过。从节点到节点的边标记的是词语,并且这些词语是作为聚类标签使用。基本类是从图中的节点中选取,每一个节点至少包含了来自两条不同的微博中才可以选择作为基本类,其他形式除外。如表1所示为上述图2进行选取基本类的结果。
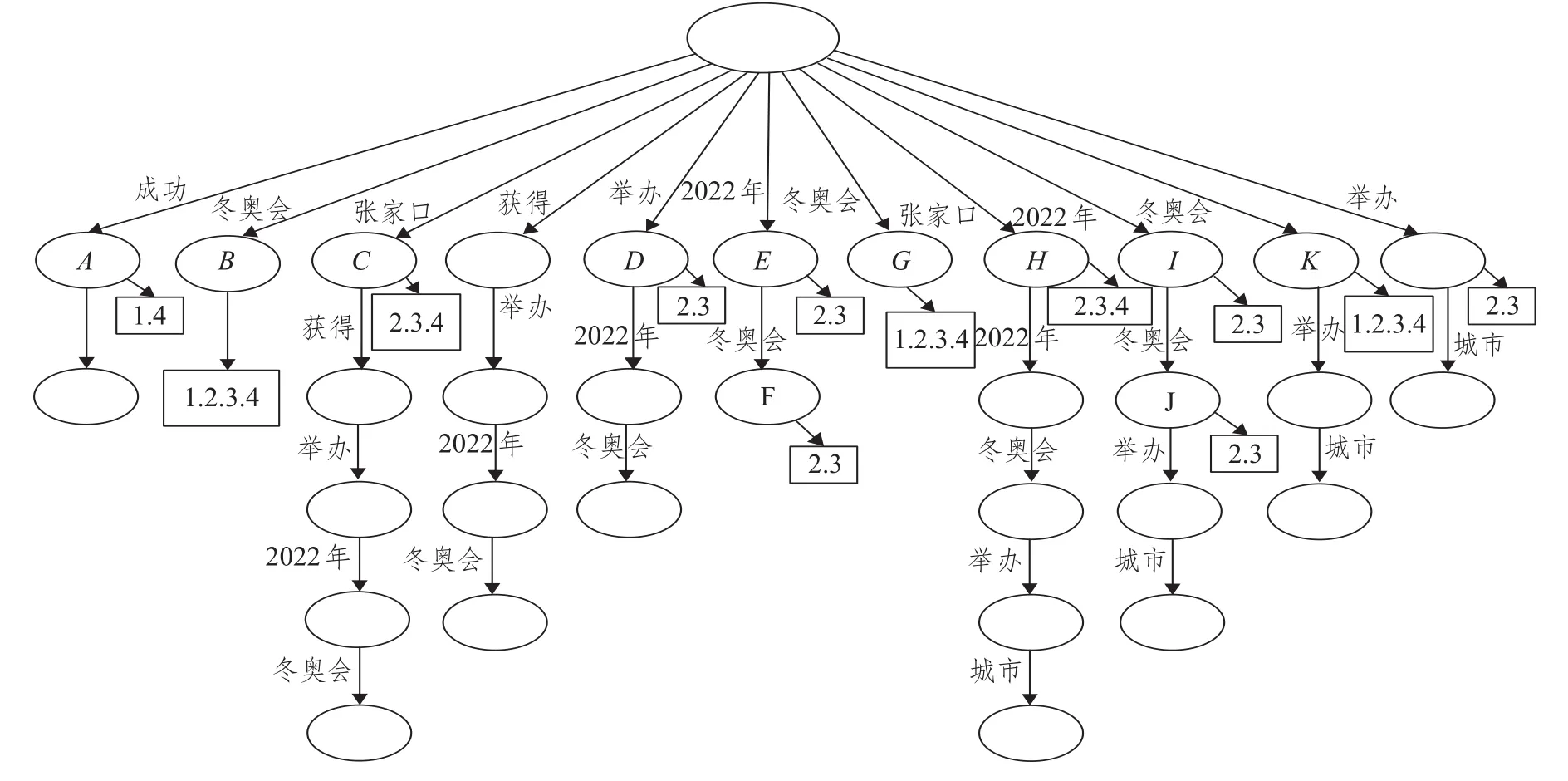
图2 后缀树数据结构
3.3 聚类标签选取
针对原有的STC方法,它主要包括3个步骤:(1)文档的准备;(2)基本类的发现;(3)基本类的合并。但是STC算法不能很好地控制重叠聚类的缺陷,并且不能去选取聚类数量。所以本文提出应用一种改进的聚类算法,在其构建后缀树结构找到完整短语后,结合SVD产生候选聚类标签,选取更为有效的聚类标签,并且应用SVD能够选取聚类的数量。应用SVD获取聚类标签具体步骤如下:
(1)在去除重复词语的基本类后(如表1中B、G、K,C、H,F、J和 D、C重复),通过计算词项TF-IDF值建立词项-微博矩阵 At×d;其中 A的秩 rank(A)=r。 λ1≥λ2≥…≥λr是AAT及ATA的r个非负特征值,对应的正交特征向量分别为x1,x2,…,xt和y1,y2,…,yd。
(2)利用奇异值分解A将分解成A=USVT形式,其中矩阵U是由词语间关系矩阵AAT导出的特征向量矩阵,VT是由微博文档间关联矩阵ATA导出的特征向量矩阵,S是r×r阶奇异值对角矩阵,S=diag(δ1,δ2,…,δr),而 δi=√λi(i=1,2,…,r)被称为矩阵 A的奇异值。
(3)应用矩阵F-范数(如式(1)所示),选取适应的k值,将S中最大的k个奇异值及其相应的行、列保存,其他的奇异值及其相对应的行、列删除;再取U、V最前面的k个列向量,由此得到Ak=UkSkVTk,其中k(k<r)是降维后的概念空间的维度。

表1 基本类

其中q是一个控制集群个数的参数,本文设定q的值为0.9[14]。
(4)抽象概念及短语匹配,由于特征提取过程中,无论是抽象概念还是词组的发现都表示在同样的空间即原始词语-微博矩阵的列向量空间,因此,本文定义一个t×(p+t)的矩阵P,其中t是去除重后词项的个数,p是其短语的个数,p中将词项和短语(p+t)看作伪微博,用TD-IDF值表示其权重;然后计算M=UTkP将能产生所有抽象概念-词组对的夹角余弦,然后根据M挑选出候选聚类标签。
(5)聚类内容发现,定义一个矩阵Q,其中Q中列向量是每一个聚类标签。计算C=QTA,得到聚类内容的分配。其中A是原始的词语-微博矩阵。矩阵C的元素Cij表示第 j条微博属于第i的聚类的程度。对于每一个候选聚类标签,对C中元素根据聚类分配阈值进行筛选,最后,将所有未被分类的微博文档信息放入其他类。
3.4 聚类合并
为了更好地得到聚类结果,本文利用Jaccard相似系数,进一步合并聚类标签及相应的聚类内容。如式(2)所示:
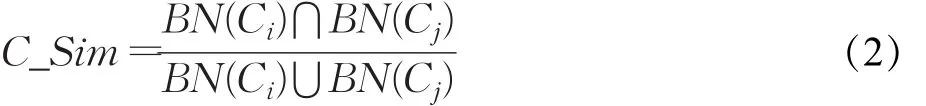
其中,C_Sim(Ci,Cj)表示Ci,Cj两个聚类之间的相似度,BN(Ci)表示Ci聚类对应的微博编号集合;BN(Cj)表示Cj聚类对应的微博编号集合。如果其值大于一定的阈值就将其聚类标签进行合并,并将其内容也进行合并。
4 摘要提取
在进行事件聚类完成之后,需要对子事件进行摘要抽取。本文结合地区微博特征计算微博综合得分来进行摘要提取。进行聚类完成后,针对每一个聚类标签中的内容,首先计算每条微博句子的综合得分,然后按照得分将每个聚类中的微博句子进行排序,最后在每个聚类中抽取出排名前一条微博句子作为摘要。微博的综合得分是分别计算微博地区名称、社会特征和标签属性的权值。
4.1 微博地区名称
为了区分用户想主要了解的地区事件,根据地区权值树,先查找主要了解的地区名称的权值,然后按照它的上一级别权值快递递减,下一级别权值缓慢递减,并以此类推,进行地区权值计算。主要了解的地区名称权值如式(3)所示:

其中,lf_weight(fij)表示在第 j条微博中i地区名称的权值,N表示进行预处理后所有微博中地区名称的总数量,Ni表示所有微博中主要了解的地区名称的数量。
4.2 微博社会特征
微博消息的质量高低不仅与文本内容有关,还和一些社会特征有关。在微博中这些社会特征表现为对微博文本信息的评论数、转发数还有微博用户的权威性即粉丝数。微博的社会特征权值表达式如式(4)所示:

其中,sf_weight(fj)表示第 j条微博的社会特征权值。Cj表示第 j条微博的评论量,Rj表示第 j条微博的转发量,Fj表示第 j条微博所属用户的粉丝量。C表示微博 j所属聚类中所有微博的评论量。R表示微博 j所属聚类中所有微博的转发量。F表示微博 j所属聚类中所有用户的粉丝数。 α1、β1、γ1为3个可变系数,且相加为1。
4.3 微博标签属性
根据观察地区微博历史数据特征,发现地区微博大部分带有标签特征,而微博标签是微博主题的体现,所以标签在地区微博中很重要。标签在地区微博中分为3种情况,一种是有标签且包含候选聚类词项,有标签但是不包含候选聚类词项,还有就是没有标签的。针对这3种情况,计算微博标签属性的权值如式(5)所示:

第一个表达式表示标签词项在候选聚类标签中出现的情况,第二个表示是其他的两种情况,其中,htfij表示标签中的相对词频,hN代表的是带有标签微博的个数,hni代表的是标签中包含词i的微博个数,θ是一个常数。
因此,地区微博的综合得分的公式如式(6)所示:
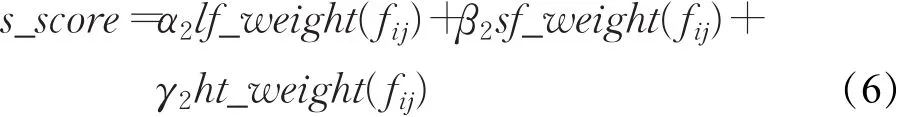
其中,lf_weight(fij)是微博地区权值得分,sf_weight(fij)是微博社会特征得分,ht_weight(fij)是微博标签属性权值得分,α2、β2、γ2是3个可变系数,作用为平衡每个权重因子,且相加为1。
计算地区微博的综合权值之后,对子事件中的微博进行排序,然后按比例从中提取出排名前一条微博句子作为子事件的摘要。并做进一步地处理,按时间顺序将它们排序,这样做的目的是为了使得到摘要文本具有连贯性和一致性;最终生成包含事件各个方面且按时间顺序排序的地区事件摘要。
5 实验与分析
实验的目的是验证本文提出的基于后缀树算法的地区微博摘要技术研究方法的效果。
5.1 实验环境与数据
实验硬件环境:CPU Inter®Core™i5(3.20 GHz),RAM为8 GB,操作系统为64位的Windows 8;实验软件:编程软件为Eclipse,数据库为SQL Server。
本文使用的数据集来源于新浪微博,是利用程序获取河北省张家口市、沧州市、邢台市,内蒙古呼和浩特市、包头市这5个地区每个地区20个官方认证微博账户数据,获取数据时间范围是为2015年5月1日至2016年9月1日,总计160 481条微博数据。
由于获取的地区微博数据内容混杂,如:除5个地区外的微博数据信息、地名的别称、表情、英文字符、其他对地区事件信息分析无意义的符号等,故需对数据进行预处理以提高模型预测的精度。预处理分成宏观与微观两个层次进行。
(1)宏观:过滤掉5个地区外的地区微博数据(如江苏、辽宁等),而针对地区别称的微博数据将进行保留(如张家口-张垣、山城,河北-冀,包头-鹿城等)。
(2)微观:对剩余的微博数据,进行逐条处理,删除每条微博中的英文、表情符号,删除非文本微博,如图片、视频等,然后对处理后的地区微博文本进行分词、去除停用词、低频词,最后再应用HowNet和地区权值树进行语义相似度和地区别称的替换。
5.2 参数设定
先通过实验对相关的阈值、参数进行设定。针对式(2)设定聚类合并的阈值,当式(2)的值大于0.5时,则进行聚类的合并。
针对式(3)地区上下级别权值的设定,不同的权值对于提取的地区事件摘要有不同的效果,通过对获取的地区官方微博数据信息进行实验,上一级别设定为lf_weight(fij)/3,下一级别设定为lf_weight(fij)/2时获得主要了解的地区事件摘要效果最佳,并以此类推。
此对于式(4),α1、β1、γ1这3个可变系数,当 α1的值为0.5,β1、γ1均为0.25时,最能反映出评论数是最能体现微博包含有用信息的程度。
对于θ,当θ=1时,式(5)退化为传统的TF-IDF公式,θ过大时,忽略微博文本Hashtag话题词之外的词,由于带有Hashtag的微博文本占文本总数量的50.2%,但是存在一些没有意义的标签,如“早安张家口、邢台播报”等,这些标签并不能代表本地发生的事件,因此话题词内容不能完全决定微博的主题,故而导致一些不处于Hashtag中的词语的权重过低,造成形成事件摘要准确率下降。通过对本文的数据反复实验,发现当θ=1.6时的正确率最高。所以本文选择θ=1.6。
对于式(6)中 α2,β2,γ2这3个可变系数,当 α2的值为0.4,β2,γ2均为0.3时,最能反映地区权值对地区摘要提取的价值。
对于变量l,通过对实验的分析,当l为10%~15%时,提取的有代表微博能够最大限度地包含事件有用信息,且在生成摘要时,不会造成事件摘要的冗余。当l值太大会造成一定的信息冗余现象,而l值太小会造成信息的缺失,生成的摘要无法为读者提供事件的有用信息。
5.3 地区事件聚类
由于地区微博事件没有公开的评测数据集,因此本文选择3位不同研究人员通过网易客户端观测当地事件来提取这5个地区发生的事件作为本文的测评数据集。
表2是3位不同研究人员针对张家口、沧州、邢台市通过网易客户端提取的事件。

表2 人工提取事件
表3是应用本文事件聚类算法对这3个城市进行事件聚类的结果。

表3 本文算法提取事件
从以上两个表格上可以看出,应用本文提取的事件更全面,能够将本地区所发生的较少谈论到的小事件提取出来,这更能突出在查询时间内想了解地区所发生的详细的一系列事件。
5.4 地区事件摘要
由于地区微博自动事件摘要没有公开的评测数据集,因此同时让其3位不同研究人员分别对从微博中提取出的5个地区事件进行人工提取摘要并作为摘要的评测数据集。
本文以张家口“2022年冬奥会”事件为例,提取其摘要。并将该方法生成的事件摘要信息与改进的LexRank[15]方法、改进的TextRank[16-17]方法、人工产生的摘要进行对比,如表4所示。
虽然改进的LexRank、TextRank方法在针对公众微博提取事件摘要时取得了很好的效果,但是针对地区微博摘要的提取由于这两种方法缺少考虑地区微博的特征,从表4可以看出,本文形成的摘要较其两种方法生成的摘要更全面,子话题覆盖性更强,且能够准确表达当地事件信息。
5.5 测评标准
为了验证本文提取算法的有效性,本文采用文档摘要研究中的通用评价标准ROUGE[18]对地区事件摘要的质量进行测评。在ROUGE测评指标中有很多子指标,其中每一项测评指标中都能产生3个得分(召回率、准确率、F1值)。下面对ROUGE-N进行说明。
N元语言模型的召回率ROUGE-N-R为:

以上两者的F1值为:

其中,N是N元语言模型的长度,N-gram∈G表示在标准答案摘要G中出现的N元语言模型,N-gram∈S表示在系统自动生成的摘要中出现的N元语言模型。Cm(N-gram)是在候选文档摘要中和标准答案中都出现的N元语言模型数量,C(N-gram)则表示仅出现在标准答案摘要或是系统自动生成的摘要中的N元语言模型数量。考虑本文针对的是微博短文本数据,所以本文选择ROUGE-2。
用ROUGE-2-F对本文方法、改进LexRank方法、改进TextRank方法提取的张家口市、邢台市、沧州市事件摘要进行对比评测,结果如图3~5所示。

表4 张家口“2022年冬奥会”事件摘要

图3 张家口市ROUGE-2-F对比结果

图4 邢台市ROUGE-2-F对比结果

图5 沧州市ROUGE-2-F对比结果
通过图3~5显示表明本文算法提取摘要判别能力是最强的,且生成摘要优于其他两种方法,其次是TextRank、LexRank最弱。这是因为改进TextRank方法在进行摘要提取时比LexRank方法多考虑了微博的标题和句子位置等信息,而本文方法充分考虑了地区微博的特征。
实验结果表明,利用采用后缀树和奇异值分解来进行事件聚类并综合考虑地区微博的特征生成的摘要表现出较大信息的覆盖率、更准确的更好的可读性和更全面性地区事件摘要信息的特征,这也充分的证明了本文算法的有效性。
6 结束语
本文以地区微博的事件为研究对象,它涉及了文本的聚类、文本内容质量的计算、文本的相关性的计算等。在分析了传统的提取摘要的算法的基础上,考虑了摘要的可读性、全面性和有用性,提出了一种基于后缀树算法的地区微博摘要技术研究方法,首先在对地区微博进行预处理时结合其本身的特征点使用HowNet、地区权值树进行语义相似度替换和地区别称的统一;接着应用STC算法、SVD来进行地区微博事件的聚类;然后综合考虑地区微博的特征,计算微博总权值;最后通过对微博进行排序选择、加工,得到最终摘要。对比实验结果表明,本文方法生成的摘要效果更加合理有效,地区相关性事件更准确。
目前关于地区微博信息的事件聚类和摘要进行了初步的研究,今后需要在句法方面对微博文本进行研究,使摘要的可读性更高、信息更丰富、内容更全面,更好地让用户快速阅读和了解地区事件。
参考文献:
[1]童薇,陈威,孟小峰.EDM:高效的微博事件检测算法[J].计算机科学与探索,2012,6(12):1076-1086.
[2]Long R,Wang H,Chen Y,et al.Towards effective event detection,tracking and summarization on microblog data[J].Web-Age Information Management,2011:652-663.
[3]Phuvipadawat S,Murata T.Breaking news detection and tracking in Twitter[C]//International Conference on Web Intelligence and International Conference on Intelligent Agent Technology.Washington D C:IEEE Computer Society,2010:120-123.
[4]Weng J,Lee B S.Event detection in twitter[C]//International Conference on Weblogs and Social Media,Barcelona,Catalonia,Spain,2011:311-312.
[5]Sakaki T,Okazaki M,Matsuo Y.Earthquake shakes twitter users:Real-time event detection by social sensors[C]//Proceedings of the 19th International Conference on World Wide Web,2010:851-860.
[6]Sharifi B,Hutton M A,Kalita J K.Summarizing microblogs automatically[C]//Human Language Technologies:the 2010 Conference of the North American Chapter of the ACL,Los Angeles,USA,2010:685-688.
[7]Sharifi B,Hutton M A,Kalita J K.Experiments in microblog summarization[C]//Proceedings of IEEE Second International Conference on Social Computing(ICSC2010),Minneapolis,USA,2010:49-56.
[8]Wang Peng,Wang Haixun,Liu Majin,et al.An algorithmic approach to event summarization[C]//ACM SIGMOD International Conference on Management of Data,Indianapolis,Indiana,USA,2010:183-194.
[9]Duan Yajuan,Chen Zhumin,Wei Furu,et al.Twitter topic summarization by ranking tweets using social influence and content quality[C]//Proceedings of the 24th International Conference on Computational Linguistics,New York,2012:763-780.
[10]彭敏,高斌龙,黄济民,等.基于高质量信息提取的微博自动摘要[J].计算机工程,2015,41(7):36-42.
[11]Dong Z D,Dong Q,Hao C.HowNet and its computation of meaning[C]//Proceedings of the 23rd International Conference on Computational.Linguistics(COLING’10),New York,2010:53-56.
[12]刘杰,郭宇,汤世平.基于知网2008的词语相似度计算[J].小型微型计算机系统,2015,36(8):1729-1734.
[13]Parikh R,Karlapalem K.ET:Events from tweets[C]//International Conference on World Wide Web Companion.New York:ACM,2013:613-620.
[14]Poomagal S,Visalakshi P,Hamsapriya T.A novel method for clustering tweets in Twitter[J].International Journal of Web Based Communities,2015,11(2):170-187.
[15]朱明峰,叶施仁,叶仁明.基于Lex-PageRank的微博摘要优化方法[J].计算机科学,2016,43(9):261-265.
[16]Milhalces R,Tarau P.TextRank:Bringing order into texts[C]//Association for Computational Linguistics,Barcelona,Spain,2004:118-126.
[17]余珊珊,苏锦钿,李鹏飞.基于改进的TextRank的自动摘要提取方法[J].计算机科学,2016,43(6):240-247.
[18]席耀一,李弼程,李天彩,等.基于词语对狄利克雷过程的时序摘要[J].自动化学报,2015(8):1452-1460.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
河北金融年鉴(2021年0期)2021-08-25
河北金融年鉴(2021年0期)2021-08-25
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
河北金融年鉴(2020年0期)2021-01-21
江苏通信(2018年4期)2018-12-04
自动化学报(2017年7期)2017-04-18
中国新通信(2016年17期)2016-11-17
现代语文(2016年21期)2016-05-25
现代语文(2016年21期)2016-05-25
