
基于知识点层次图的个性化习题推荐算法
2018-05-21 06:20蒋昌猛冯宏伟
计算机工程与应用 2018年10期
蒋昌猛,冯 筠,孙 霞,陈 静,张 蕾,冯宏伟
西北大学 信息科学与技术学院,西安 710127
1 引言
随着Web2.0和互联网教育的快速发展,简便灵活、可定制化的网络在线习题已经普及,如慕课网[1]、智能辅助教育系统[2]等。面对网络及考试系统中海量的习题数据,如何弥补知识漏洞以及针对性地选择习题已成为当前教学资源个性化推荐研究领域的热点。因此,高效可靠的习题推荐算法既是互联网教育背景下对个性化学习新的要求,也是用户对个性化学习的新的诉求。
目前,基于认知诊断理论(Cognitive Diagnostic Theory,CDT)[3]的个性化习题推荐理论被研究者广泛应用。许多研究者提出了对学生进行建模和分析的多种认知诊断模型(Cognitive Diagnosis Model,CDM)[4]。其中,文献[5-6]提出了一种项目反应理论(Item Response Theory,IRT)模型,IRT是通过统计学的方法对学生和习题答题情况建立平均分、得分率、排名等数学理论模型,来预测学生的综合能力和习题的难度、区分度等参数,但IRT局限在学生对习题的答题情况,未深入分析学生对知识点掌握程度。文献[7-8]提出了传统DINA模型(Deterministic Inputs,Noisy“And”gate model),该方法引入了习题知识点关联Q矩阵[9],通过学生知识点掌握程度向目标学生推荐习题,但DINA模型局限是Q矩阵仅通过已考察的知识点忽略了相关联但未考察的知识点来进行习题推荐,使得向学生推荐习题存在一定的误差。已有一些研究学者将协同过滤推荐方法应用在习题推荐方面。文献[10-11]提出了基于近邻的协同过滤方法,该方法首先根据学生的习题答题行为记录计算学生之间的相似度,其次根据相似度的大小找到最相似的学生,最后依据相似学生对目标学生进行习题推荐。但该方法忽略了不同的学生对知识点掌握程度的差异,难以保证推荐的习题是否属于目标学生想要的习题,即没有从学生对认知属性的角度出发对学生建模,进行基于知识认知的个性化推荐。
IRT模型、DINA模型和协同过滤方法虽然在习题推荐方面都有一定研究和应用,在一定程度上提高了学生的自主学习效率,但是都存在一定的局限性。如IRT模型未引入习题的特点(知识点);DINA模型虽然引用了习题知识点,但是未考虑习题知识点之间存在一定的关系且对知识点的掌握程度属于掌握或未掌握[12];协同过滤方法虽然运用相似学生来预测目标学生对候选习题的得分预测情况,在一定程度上提高了推荐质量,但是忽略了学生之间对习题的掌握程度差异,难以保证推荐的习题是否满足学生对加强薄弱知识点的需求。在绝大多数课程中,知识点是最直接反映学习者掌握目标知识程度的衡量标准,也能直接反映学习者在学习过程中存在的知识漏洞,因此知识点在达到推荐的个性化和准确性目标上起到关键作用。同时,知识点在结构上具有天然的层次关系,利用专家知识对知识点结构进行建模,形成具有知识点间复杂的层次关系,即知识点层次图结构。知识点层次图结构更能全面衡量学生对知识点掌握情况,从而提高在线用户学习的效率。因此,本文将知识点层次图关系和知识点掌握程度(属于[0,1]区间的一个值)运用在习题推荐,提出了基于知识点层次图的个性化习题推荐算法(a personalized exercises Recommendation algorithm based on Knowledge Hierarchical Graph,ReKHG)。主要思想是:首先根据课程知识点结构、习题知识点矩阵、学生习题答题记录计算知识点之间权重图和学生在每个知识点上的失分率;其次用知识点间权重更新知识点失分率,与阈值比较初步选出掌握薄弱的知识点集合;从掌握薄弱知识点集合和未做的习题中得到候选习题;最后预测目标学生对候选习题的失分,选出失分大于设定值的习题作为目标学生推荐的习题。
由于目前暂无基于层次结构的知识点的习题公开数据集,构建1 653道《C语言程序设计》习题的237个知识点和85位学生1 069道答题记录的习题数据集,称为exercise(习题数据:http://nwu-ipmi.cn/ctag/stutreeTags.aspx)。在该数据集上实验结果表明,本文提出的ReKHG算法具有较高的知识点针对性及习题推荐准确性。
2 问题描述
在教育领域中,有众多学者认为习题是由若干个相关联知识点组成,知识点能反映学生掌握程度。文献[13]提出知识点存在一定的结构关系,结构关系包括知识点的层次关系、依赖关系、蕴含关系,本文主要以知识点的层次关系为主来体现课程知识点体系。
由于知识点反映学生掌握程度和知识点层次关系体现知识点的关联关系,本章引入了习题知识点和知识点层次结构关系。首先定义习题,其次定义知识点层次关系,最后定义习题得分比。习题知识点层次关系是求解知识点之间的权重图,习题得分比运用统计学方法得到知识点掌握程度,知识点掌握程度属于[0,1]区间的一个值,而不再是一个知识点掌握或未掌握的两种情况。
定义1(习题)由一个或多个互不相同的知识点组成,知识点是习题的最小单位。
给定M道习题都是由N个知识点构成,则习题集合D={d1,d2,…,dM},知识点集合K={k1,k2,…,kN} ,习题知识点集合矩阵R=[rmn]M×N,其中,rmn=1∙表示习题M考察知识点N,rmn=0表示习题M未考察知识点N。如表1是一个简单的习题知识点集合矩阵,其中,行代表一道习题,列代表一个知识点,从表1可知R1N至少是由k2和kN两个知识点组成。
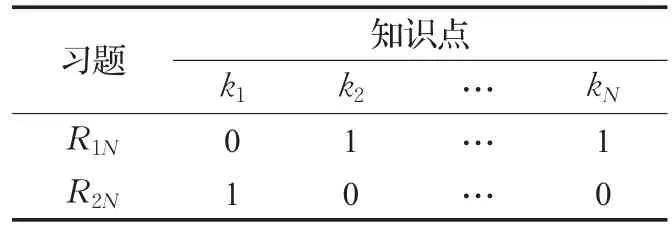
表1 习题知识点集合矩阵
定义2(知识点的层次关系)指知识点的包含关系,可以建立起具有树状结构的层次结构。领域知识通常具有树状层次结构,文献[14]给出了一个关于数学领域知识层次结构的例子。数学领域知识包含了广泛的知识点,且这些知识点之间相互关联,一个知识点的构建通常依赖另一个知识点。同样,本文涉及的C语言程序设计领域知识同样具有树状层次关系,这也反映了学生对领域知识的认知是一个层次递进的过程。在构建C语言程序设计领域知识时,本文借鉴文献[15]的思想,首先确定C语言程序设计这门课程领域知识构建的目标和知识范围,然后对所有知识点进行分类,采用自顶向下的设计原则,通过反复迭代构建最终形成一个具有父子关系的层次树结构。图1是根据上述思想和原则构建的一个简单的C语言程序设计知识点层次树结构。树的根结点是整个领域知识的父结点,树的上层具有宽泛的知识点概念,树下层具有粒度较细的知识点概念,直到粒度不能再细分为知识点。这种树的层次构建过程符合学生对领域知识的认知过程。从图1中可以很明显看出知识点之间具有包含关系和并列关系。如果知识点kp(p =1,2,…,N )包含知识点kb(b=1,2,…,N),则记为:kp⊇kb,说明 kp比 kb宽泛,同理 kb比 kp的粒度细。如果知识点kp不包含知识点kb(b=1,2,…,N),则记为:kp~kb。

图1 C语言程序设计知识点体系
定义3(习题得分比)习题得分比是指这道题的实际得分与题满分之比,其值属于[0,1]之间。
给定u个学生的集合:S=(s1,s2,…,su);u个学生的习题得分比集合:G=(Gs1,Gs2,…,Gsu),其中,Gsi=(g1,g2,…,gM) ,gy=0(y =1,2,…,M )表示学生 si未做过习题dy或者得分比是0。
假设学生si做过v(v =1,2,…,M )道习题的集合为
由定义3知,学生si做过的习题dy失分比,记为-g,则学生s所有习题失分比向量为:yi

由式(1)知,学生si对第n个知识点的失分比,即学生s的N个知识点失分比向量为:i

又由于学生si做过v道习题,而习题是由知识点组成,则可以从学生si做过v道习题中统计出知识点n的出现比,记为那么学生s的N个知识点出
i现比向量为:

由式(2)和式(3)知,求得学生si的 N 个知识点的失分率=/,则u个学生N个知识点失分率矩阵为:

其中,表示学生si对知识点n的失分率大小,值越大,表示学生si对该知识点掌握程度越小,换句话说学生si对该知识点n掌握得不好。在习题推荐的时候,需要根据知识点失分率大小进行推荐。
根据以上的定义,学生知识点掌握程度掌握或未掌握问题得到解决,即知识点掌握程度属于[0,1]区间的值,定义2描述了知识点的层次关系,为第三章求解知识点之间权重图做准备。
3 基于知识点层次图的习题推荐算法
3.1 ReKHG整体框架
本节介绍了ReKHG算法技术路线方案,ReKHG算法整体框架如图2所示。从图2中可以看出ReKHG算法主要由四部分组成。
(1)输入:习题知识点集合R=[rmn]M×N、学生习题得分比集合G=(Gs1,Gs2,…,Gsu)、知识点层次结构K(知识点标注由领域内专家标注)。
(2)知识点失分率和权重图:运用统计概率学方法对学生习题答题记录建模,得到学生-知识点失分率的知识点掌握程度。根据专家构造的知识点层次关系,利用文献[16]计算知识点之间的权重,得到知识点权重是一个层次图的关系,即每个知识点与其他知识点都有权重,权重值越大,表示两个知识点关联越强。
(3)更新后学生知识点失分率矩阵:由步骤(2)可知,知识点失分率的知识点之间是相互独立的。现在用知识点权重图更新学生-知识点失分率,得到更新后的学生-知识点失分率的知识点掌握程度,从而得到知识点之间是具有层次图关系的。
(4)根据学生对候选习题的失分预测进行习题推荐(输出):提取学生掌握薄弱的知识点,并选出带有薄弱的知识点习题作为候选习题。预测候选习题的失分并作出推荐。
3.2 ReKHG算法
3.1节描述ReKHG算法整体框架,下面分别详细介绍知识点权重图,更新学生-知识点失分率,以及学生对候选习题的失分预测进行习题推荐。
3.2.1 知识点权重图
从图1的知识点层次关系中可以看出,每一个结点代表一个知识点,并且结点与结点之间是存在上下位关系的,即父子关系,用箭头连接起来,每一对用箭头连接的结点的上位是父亲结点,箭头所指向的下位是孩子结点,父亲结点所代表的知识点包含孩子结点所代表的知识点,第一个父亲结点是所有知识点的根结点。
在这种由父子关系所表达的层次树中,可以得出越靠近根结点,结点所代表的知识点范围越广,离根结点越远,结点所代表的知识点在专家领域知识划分中越细分,知识点粒度越细,而针对具体的习题,细分、粒度小的知识点更能反映习题的特点,可以更好地辅助学生明确哪些具体的知识点还没有完全掌握。因此,本文基于这种思想提出了知识点关系权重指标,来反映知识点在习题中的权重。结点kp,kb的权重定义[16]如下:
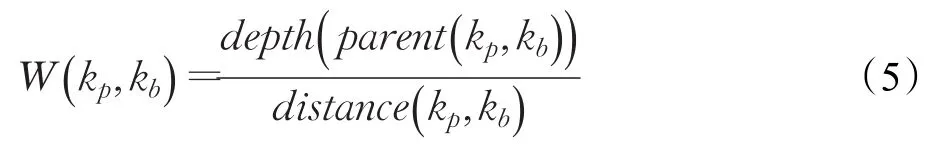
其中,parent(kp,kb)表示结点kp,kb最近共同父结点。例如,如图1所示:字符串(115)是字符串存储方式(116)和字符串输入输出(119)最近共同父结点,那么depth(p arent(kp,kb) )表示最近共同父结点到树根路径长度。distance(kp,kb)表示结点kp,kb到树根结点的平均距离。即:
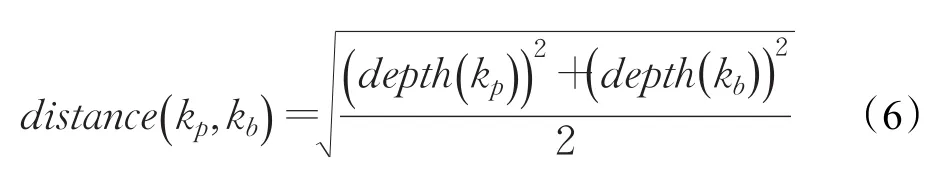
图3描述了一个简单的字符串知识点权重图,是从237个知识点中选取了字符串的知识点并且画出知识点权重图。
从图3可以看出,字符串(115)知识点与其他4个知识点都有一个权重值,权重值越大,代表这两个知识点关联越强,否则这两个知识点关联越弱。
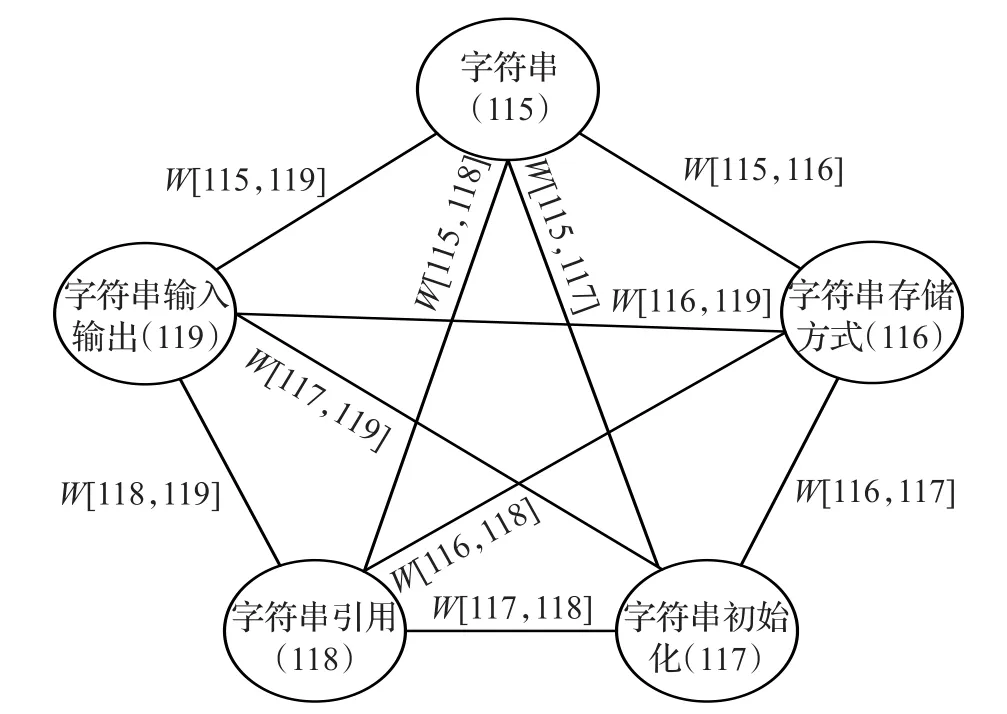
图3 字符串知识点权重图
3.2.2 基于知识点权重图的学生-知识点失分率
由第2章的问题描述的式(1)~(3)是统计概率学方法建立的数学模型知,知识点之间始终是相互独立的,所以学生-知识点失分率F的知识点不具有层次关系,为了使得知识点之间具有层次图关系,运用3.2.1节知识点权重图更新式(4),得到学生-知识点失分率的知识点具有层次图关系。又由于学生si的N个知识点失分么得到学生s更新后的第kb个知识点如下:
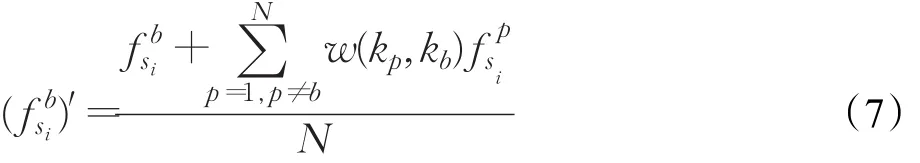
那么F′是更新后的学生-知识点失分率矩阵如下所示:
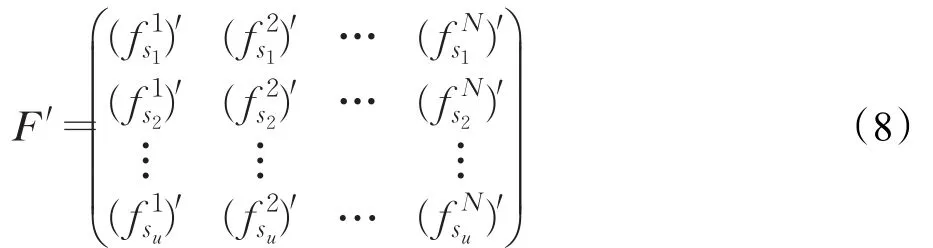
依据知识点权重图更新学生-知识点失分率矩阵F,更新后的学生-知识点失分率矩阵F′的知识点之间具有层次图关系,与式(4)比较,更新后的失分率表达了知识点层次图关系。′表达学生si对知识点n掌握程度,值范围属于[0,1],知识点掌握程度不再是0和1两种情况。比如当值′属于[0,0.3]时,表示学生si对知识点n掌握得很好,当值′属于[0.3,0.5]时,表示学生si对知识点n掌握比较薄弱,当值属于[0.5,1]时,表示学生si对知识点n掌握得较差。在习题推荐的时候,不是推荐掌握较差的知识点就越好,应当推荐对学生有提升帮助的知识点,如可以向学生推荐掌握薄弱的知识点,从而进行习题推荐。
3.2.3 预测候选习题的失分进行习题推荐(输出)
将阈值α与学生-知识点失分率比较,若学生si知识点n的失分率′大于阈值α,则将知识点n加入到学生si的掌握不好的知识点集合,也叫薄弱的知识点集合。
要从薄弱的知识点集合中找到学生候选知识点集合。将掌握不好的知识点集合和学生未做的习题dR-v知识点交集运算,得到的知识点是学生si候选知识点,从带有候选知识点的习题选出候选习题并加入到候选习题集合中。
预测目标学生si对候选习题dR-v的推荐程度p(si,dR-v),如式(9)所示。

其中,表示学生si对候选知识点kp出现的次数,表示候选知识点k在候选习题d出现的次数,pR-v表示候选知识点k被多少个学生做过。lb(2 +p是借鉴了TF-IDF的思想,消除了学生对热门的知识点过大权重,这样更能反映学生的个性化,增加了推荐结果的新颖性。
推荐程度表示学生对习题失分预测的情况,选出推荐程度较高的习题加入到目标学生si的习题推荐列表。
4 实验结果与分析
4.1 数据集描述
为了验证ReKHG算法的可行性和准确性,本文采用exercise数据集,该数据集是西北大学《C语言程序设计》课程习题和近5年该课程考试答题记录。
exercise数据集由以下几项数据组成:(1)根据专家知识标注知识点的《C语言程序设计》课程习题库,一共包含选择题、填空题、判断题、程序题和编程题5种题型在内的1 653道习题,涉及237个知识点,每道题由1~6个知识点标注;(2)西北大学近5年该课程考试答题记录,共包含1 069条答题数据。本文将答题数据进行归一化预处理,将客观题和主观题的答题分数映射到[0,1]之间,也叫得分比,并将1 069条答题记录随机平均分成3份,任取两份作为训练集,剩余一份作为测试集,采用交叉验证的方式进行10次实验,取平均值作为实验结果。exercise数据集用表格描述,其结果如表2所示。

表2 数据及统计信息
实验使用Windows7 64位操作系统,CPU是Intel®CoreTMi7-4700MQ,内存大小是16 GB,硬盘大小是2TB,实验语言是matlabR2012a版本。
4.2 评价方法
在推荐系统中,准确率(precision)和召回率(recall)是最为常用的两个评价指标,和常见电子商务的推荐系统不同,习题推荐侧重挖掘学生对知识点掌握情况,根据文献[17-18]对评价指标的描述,提出了知识点推荐的准确率和知识点预测的召回率评价指标。f1-score是precision和recall综合评价指标。评价指标定义如下所示:
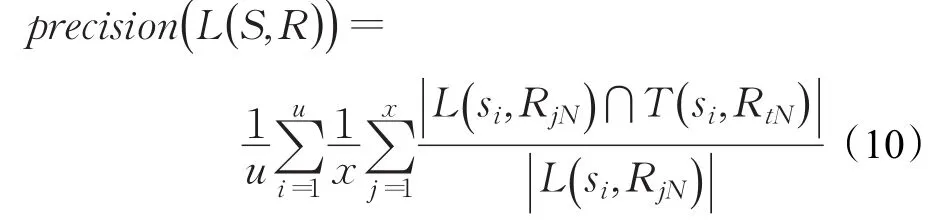
precision(L (S ,R ) )表示正确推荐的知识点占推荐知识点总数的百分比。

recall(L (S ,R ) )表示正确推荐知识点占知识点总数的百分比。
由precision和recall,得f1-score为:
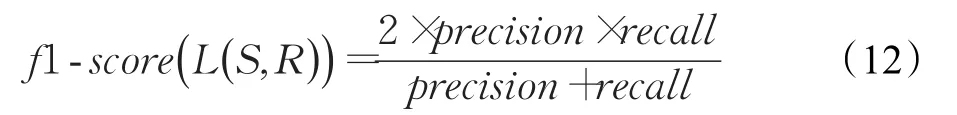
其中,| L (si,RjN) |表示向学生si推荐习题RjN的知识点个数;|T (si,RtN) |表示学生si在习题测试集RtN中知识点个数,(x =1,2,…,M )表示向学生si推荐的习题列表。
4.3 实验结果和分析
实验中将SeTB[17]算法、TBTFIDF[17]算法作为本文的对比算法。用式(4)求解得到的知识点失分率进行习题推荐,即基于知识点无层次图的个性化习题推荐算法。ReKWHG算法知识点之间是相互独立的,也将作为ReKHG算法的对比实验。
根据3.2.1节知识点权重图可以得到知识点之间的权重。表3是一个简单的字符串知识点之间权重图上三角示例,结果如表3所示。

表3 字符串知识点权重
从表3可以看出,字符串115知识点编号与其他知识点权重值大于其他知识点之间的权重,说明该知识点与其他知识点关联越强。
根据第2章问题描述式(4)学生-知识点失分率和3.2.2节更新后的学生-知识点失分率结果如表4所示。

表4 学生-知识点失分率/更新后学生-知识点失分率
其中,纵坐标115~119表示与字符串有关的知识点,横坐标1~5表示抽取了5位学生。它们的值分别表示更新前和更新后的学生-知识点失分率,用“/”区分开。0.00表示学生未做过的知识点,值0.83表示学生对知识点掌握得较差。从表4可以看出利用知识点层次图关系,不仅改善了矩阵的稀疏性,而且反映学生未做过的习题知识点,从而改善习题推荐质量。
根据3.2.3节,向目标学生推荐习题,利用知识点推荐的准确率、知识点预测的召回率、综合评价指标,得到对比实验结果。其实验结果如表5所示。

表5 实验结果 %
从实验结果可以看出,无论是本文提出的基于知识点层次图ReKHG算法还是对比算法,算法的准确率、召回率、f1-score都比较低,这是因为学生习题答题记录很少,使得推荐行为记录数据稀疏,导致所有的算法在准确率、召回率、f1-score都很低。文献[19]指出在推荐算法方面,经常面临用户行为数据稀疏问题,这将严重降低个性化推荐的准确度、召回率、f1-score。虽然这些算法在准确率、召回率和f1-score都较低,但是面对网上海量的习题在线数据,依然能够提高学生更有针对性的学习和自主学习效率。
从表5实验结果可以看出,当阈值α=0.4时,本文提出的ReKHG算法在exercise数据集上进行个性化推荐具有最好的效果,较ReKWHG算法在准确率方面提高了12.35%,召回率方面提高了5.49%,f1-score方面提高了11.91%,这是因为ReKHG算法考虑了知识点的层次结构。从表4可以看出知识点层次图关系,不仅改善了知识点失分率矩阵的稀疏性,而且反映学生未做过的习题知识点,从而改善习题推荐质量,这种知识点层次结构更能全面衡量学生对知识点的掌握情况,因此其性能更好。ReKHG较SeTB算法、TBTFIDF算法在准确率方面分别提高2.57%和1.85%,在召回率方面是相当的,在f1-score方面分别提高2.07%和1.09%,这是因为ReKHG算法不仅考虑了知识点的层次结构,而且考虑掌握薄弱的知识点进行个性化推荐,薄弱知识点失分率属于[0.3,0.5]区间,而SeTB算法和TBTFIDF算法仅仅是根据用户知识点进行推荐的,即掌握知识点和未掌握知识点两种情况做推荐的。利用薄弱知识点和知识点层次图关系在习题推荐方面表现更优。
阈值α对ReKHG算法和ReKWHG准确度、召回率和综合评价f1-score的影响如图4所示。
从图4结果可以看出,在薄弱的知识点上,即阈值α取值0.34到0.46之间,ReKHG算法在准确率、召回率和综合评价指标一直要优于ReKWHG算法,这是因为ReKHG算法考虑了知识点的层次图关系,不仅改善了知识点失分率矩阵的稀疏性,而且反映学生未做过的习题知识点,从而改善习题推荐质量,验证了ReKHG算法具有较高的知识点针对性及习题推荐的准确性。
5 结束语
针对海量习题带来的信息过载问题,根据习题由知识点反映其本质的特点,本文提出了一种基于知识点层次图的个性化习题推荐算法。首先利用专家知识构建知识点层次关系,并根据层次结构中上下位即父子关系的特点计算知识点的权重。其次根据学生答题记录,求解学生知识点失分率矩阵,利用权重图更新学生知识点失分率矩阵,最后求目标学生对候选习题的失分预测,从而得到习题推荐列表。与目前流行习题推荐方法相比,本文提出的算法在三个指标上是最好的,具有重要研究意义。
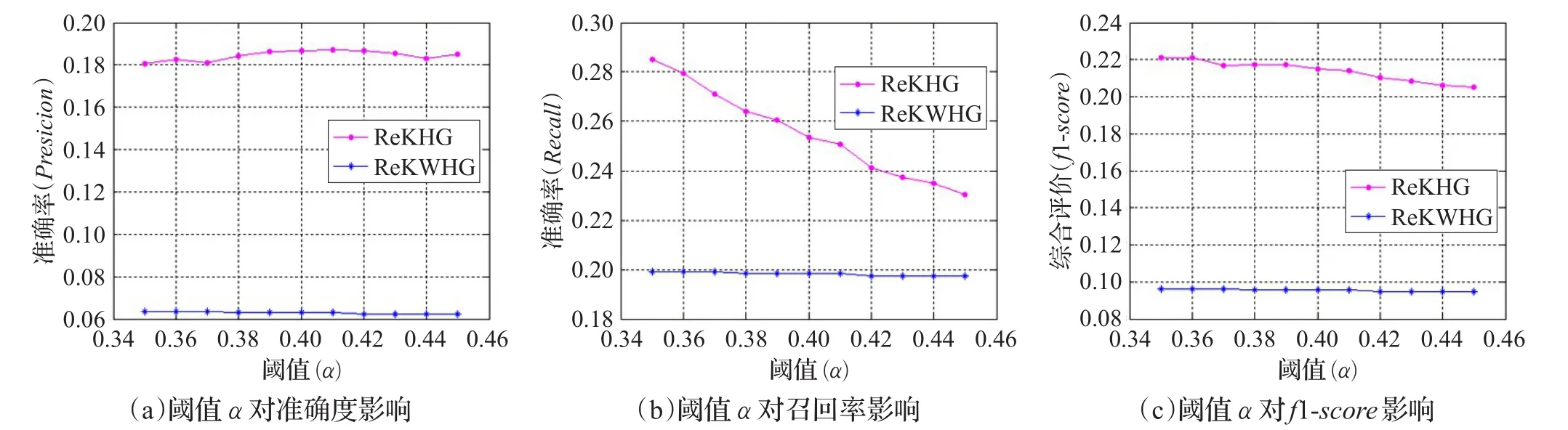
图4 阈值α对ReKHG算法和ReKWHG算法的效果影响
习题推荐是教育资源推荐的一个研究方向,也是目前研究和应用的热门领域,还有很多研究内容值得挖掘。首先本文的知识点层次图是利用专家知识进行半自动标注的,下一步研究工作可以围绕习题知识点的自动化标注展开,进一步完善个性化习题推荐的整个流程;其次本文的知识点阈值是根据经验手动设置的,今后将考虑知识点阈值函数,进一步改进个性化习题推荐算法;最后为了提高推荐算法的准确率,未来的工作可从两方面入手:(1)对用户访问但未给出评分数据进行预测并填充,降低数据稀疏性问题,从而提高个性化推荐算法的准确率等。(2)目前收集的学生习题答题记录和习题得分是一种显性反馈数据,为了可以收集学生的隐性反馈数据记录,如学生是否优等生,学生是否高年级等隐性反馈数据,获得更多的先验知识来提高算法的准确率等。
:
[1]Anderson A,Huttenlocher D,Kleinberg J,et al.Engaging with massive online courses[J].Computer Science,2014:687-698.
[2]Burns H,Luckhardt C A,Parlett J W,et al.Intelligent tutoring systems:evolutionsin design[M].[S.l.]:Psychology Press,2014.
[3]Nichols P D,Chipman S F,Brennan R L.Cognitively diagnostic assessment[M].[S.l.]:Routledge,1995.
[4]Dibello L V,Roussos L A,Stout W.Review of cognitively diagnostic assessment and a summary of psychometric models[J].Handbook of Statistics,2006,26(6):979-1030.
[5]Embretson S E,Reise S P.Item response theory[M].[S.l.]:Psyhology Press,2013.
[6]Harwell M R,Zwarts M.Item parameter estimation via marginal maximum likelihood and an EM algorithm:a didactic[J].Journal of Educational& Behavioral Statistics,1988,13(3):243-271.
[7]Torre J D L.DINA model and parameter estimation:a didactic[J].Journal of Educational& Behavioral Statistics,2009,34(1):115-130.
[8]Ozaki K.DINA models for multiple-choice items with few parameters:considering incorrect answers[J].Applied Psychological Measurement,2015,39(6).
[9]Rupp A A,Templin J.The effects of q-matrix misspecification on parameter estimates and classification accuracy in the DINA model[J].Educational and Psychological Measurement,2008,68(1):78-96.
[10]Resnick P,Iacovou N,Suchak M,et al.GroupLens:an open architecture for collaborative filtering of netnews[C]//Proceedings of the 1994 ACM Conference on Computer Supported Cooperative Work,1994:175-186.
[11]Greg L,Brent S,Jeremy Y.Amazon.com recommendations:item-to-item collaborative filtering[J].Internet Computing,2003,7(1):76-80.
[12]朱天宇,黄振亚,陈恩红,等.基于认知诊断的个性化试题推荐方法[J].计算机学报,2017(1).
[13]贾巍,瞿堃.知识表示视野下网络课程知识点关系研究[J].继续教育研究,2008(5):62-64.
[14]Sternberg R J,Ben-Zeev T.The nature of mathematical thinking[M].[S.l.]:L Erlbaum Associates,1996.
[15]马捷,刘小乐,黄岚,等.教育领域本体构建研究[J].情报理论与实践,2012,35(7):104-108.
[16]张瑜.一种基于知识分类树的个性化推荐方法[D].河北保定:河北大学,2007.
[17]项亮.推荐系统实践[M].北京:人民邮电出版社,2012.
[18]Zhang M L,Zhou Z H.A review on multi-label learning algorithms[J].IEEE Transactions on Knowledge&Data Engineering,2014,26(8):1819-1837.
[19]黄永锋,覃罗春.一种有效缓解协同过滤推荐评价数据稀疏问题的算法[J].东华大学学报:自然科学版,2013,39(1):83-87.
猜你喜欢
中学生数理化·七年级数学人教版(2022年9期)2022-10-24
数学小灵通(1-2年级)(2022年6期)2022-06-17
数学小灵通(1-2年级)(2022年5期)2022-06-01
数学小灵通(1-2年级)(2022年3期)2022-03-17
电子制作(2022年1期)2022-01-28
中学生数理化·中考版(2021年12期)2021-12-31
中学生数理化·七年级数学人教版(2021年6期)2021-11-22
电子制作(2021年14期)2021-08-21
数学小灵通(1-2年级)(2021年3期)2021-04-13
福建基础教育研究(2019年9期)2019-05-28
