
面向知乎的个性化推荐模型研究
2018-05-22 07:18王振海李晓昀
计算机应用与软件 2018年5期
王振海 李晓昀
(南华大学计算机科学与技术学院软件工程系 湖南 衡阳 421001)
0 引 言
知乎连接着各行业精英,用户分享彼此的专业知识、经验和见解,持续产生着高质量、可沉淀的信息。然而有价值的信息和用户之间并未紧密关联,系统化、组织化的高质量信息仍存在于不同个体大脑之中,尚未得到有效的挖掘、利用和分享。而优秀的推荐系统能够有效根据用户的信息需求、兴趣等进行个性化信息推荐,达到有效挖掘、高效利用和分享资源的目的。
本文从用户、问答、推荐算法三方面提出一种基于混合算法的推荐模型,以契合用户需求,达到用户与有价值信息紧密关联的目的。
1 相关研究工作
为满足用户高效寻找问题答案的需求,近年来出现了如百度知道、新浪爱问、腾讯搜搜等问答型网站。张蕊[1]将知乎定义为“问答型社交网站”,其信息具有多维度、客观性、易分享的特点。陆地[2]和刘婉婷等[3]研究了知乎用户类型和信息传播模式,指出知乎用户出现井喷式增长,面临“噪音”信息增多和“水化”的危险。王国霞等[4]指出用户对信息的需求是多元化和个性化的,个性化推荐系统能够根据用户需求和兴趣推荐信息。文献[5-7]研究了用户兴趣建模和个性化推荐系统的设计。陈景年[8]研究了选择性贝叶斯分类算法在信息分类和信息推荐中的应用。单京晶[9]和荣辉桂等[10]研究了基于内容推荐和基于用户相似度的协同过滤推荐算法在个性化推荐系统中的应用。
文献[4]研究了现有推荐算法原理及其优缺点,探讨不同推荐算法策略的适用平台。针对微博而言其信息具有时效性,因此高明等[11]综合微博的主题分布、微博内容特征以及微博受欢迎程度为用户提供实时推荐。针对豆瓣而言其信息具有情感性,因此姜霖等[12]针对豆瓣用户的文章情感为用户推荐相似的电影或文章。而知乎作为问答型社交网站,不同于微博和豆瓣平台以社交和兴趣来进行推荐,其根本目的是解决用户问答需求。知乎推荐信息以问答为主要影响因素,结合用户兴趣和社交来满足用户的个性化需求,因此采用混合推荐算法模型为用户推荐个性化信息。
2 基于混合算法的个性化推荐模型
2.1 推荐模型架构
面向知乎的个性化推荐模型包括三个核心模块,即用户模型、问答模型、推荐算法模型,如图1所示。根据知乎用户信息提出Person Rank(PrsRank)迭代算法,结合其兴趣标签构建用户模型。根据问答信息提出Problem Rank(PrbRank)算法,将问答信息标签化处理后构建问答模型。然后采用基于标签推荐、相似用户等推荐方法来构建排名算法,结合多维滑动窗口分阶段结合的方法来构建推荐算法模型,最终得到推荐信息列表。
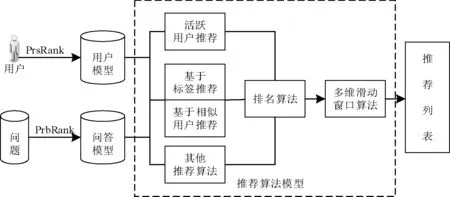
图1 个性化推荐模型
2.2 数据的获取和分析
分析知乎主页和用户特点,获取用户ID、关注人数、被关注人数、问题回答数、获得同意数、获得感谢数、关注标签等信息来构建用户模型。获取问题提问时间、问题被赞量、问题回答量、问题标题、问题标签等信息来构建问答模型。处理噪音数据,最终获取2.6万个知乎用户、461万条关注链接、72万个问题数据。
知乎作为网络问答平台,用户活跃度可在问答方面得到体现。实验数据集分析表明,多数用户不参与问答互动,即知乎整体用户活跃度较低且表现为长尾效应,如表1所示。
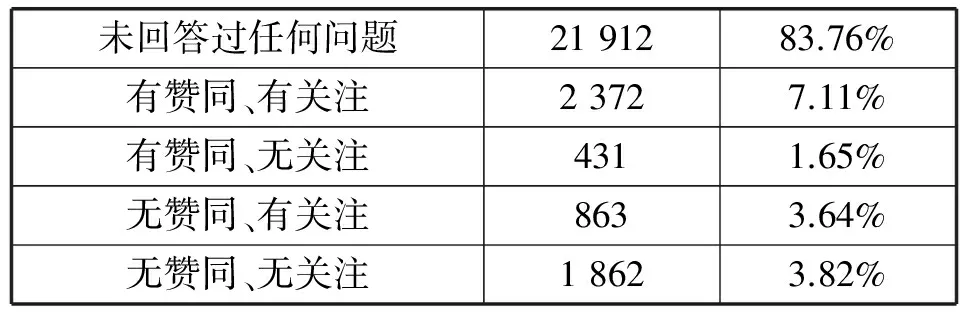
表1 知乎用户问答反映
知乎平台具有社交性质,用户与用户间的关注关系构成图结构中的点和边。由表1可知,多达83.76%的用户未回答过问题,知乎问题的解决由16.24%的用户承担,其中更是少部分答案被接受,因此研究图结构中活跃用户群体能够提升知乎整体用户活跃度。
面向活跃用户,取赞同数大于1万(Net10k,1 885人)和赞同数大于5万(Net50k,395人)的用户来量化知乎活跃群体特征。图密度表示图结构的紧密程度,能够反映用户间的关联程度,计算得到Net10k与Net50k图密度分别为0.064与0.195,表明获得赞同数越多的用户其关注关系也越为紧密。
知乎用户间相互关注关系可表示为强连通图,强连通分量能够有效表明群体间关注关系。结果表明来自不同领域间的活跃用户聚集在相同群体,形成紧密社交圈。因此扩大知乎活跃用户的社交圈,增强活跃用户影响力,将有效提升知乎整体用户活跃度。通过计算强连通图的平均路径长度、半径、直径,将活跃用户推荐给非活跃用户能够有效提升用户整体活跃度,如表2所示。
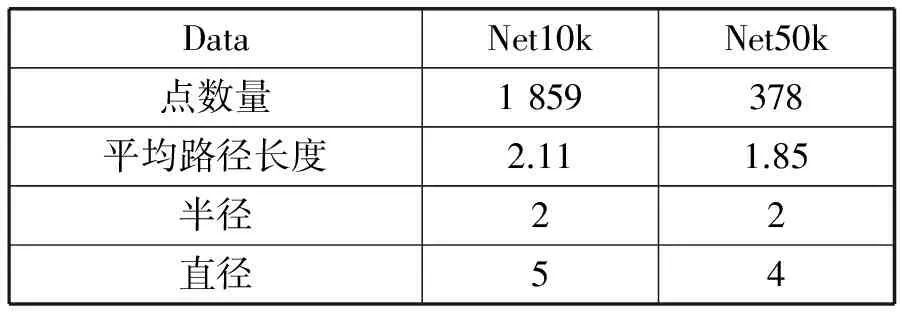
表2 强连通图指标数据
2.3 用户模型的构建
2.3.1 PrsRank函数
为计算知乎用户排名(PrsRank),经主成分分析后引入用户关注人数m1、被关注人数m2、回答数m3、收到赞同数m4、收到感谢数m5作为PrsRank函数影响因子,其中wi表示各个影响因子的权重。
(1)
2.3.2 迭代PrsRank函数
结合知乎用户间强连通关系引入PageRank排名算法,即用户自身的排名由关注者的排名重新决定。知乎用户关注关系相对复杂,强连通图中含有一些孤立点(出链为0的点),即用户u0不关注其他用户,为此增加阻尼系数q,q一般取值为0.85。
(2)
用户初始排名由式(1)得到,经过式(2)的迭代后得到最终用户排名。其中PageRank(uj)为用户uj更新后的排名值,L(uj)为用户uj的被关注人数。
2.3.3 用户数据集
根据用户在所关注的问题标签下回答数量、回答被赞量、用户排名引入用户在关注标签下排名。最终得出用户数据集(见表3)包含用户个人基本信息、知乎用户PrsRank排名、个人关注标签下排名。
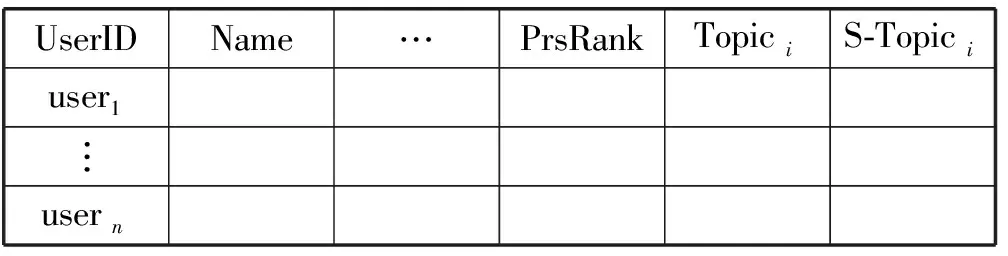
表3 用户数据集
2.4 问答模型的构建
2.4.1 PrbRank函数
为计算知乎各标签下问题排名,经主成分分析后引入问题回答数量n1,问题被赞量n2,回答用户排名n3,回答时间n4作为PrbRank函数影响因子,其中wi表示各个影响因子的权重。
(3)
2.4.2 问答数据集
问答数据集(见表4)包含问题标题、问题所属标签、问题回答用户ID、用户回答时间、问题排名等信息。
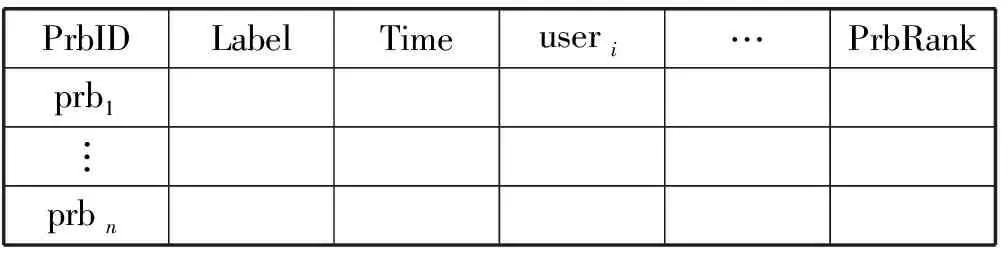
表4 问答数据集
2.5 混合推荐算法模型的构建
采用基于标签推荐、基于相似用户等推荐方法构建排名算法。利用多维滑动窗口动态更新,维持推荐信息的时效性,最终得到推荐信息列表。
2.5.1 基于标签的推荐算法
基于标签的推荐算法首先提取用户所关注的标签信息,将关注标签传至标签集。从已关注标签中选择Top k的问答话题,同时根据贝叶斯分类器选择在已关注标签集中可能关注其他标签的Top k问答话题。
以学科类为例,建立用户在关注某一标签下可能会关注其他标签的概率表。分析整体用户的偏好特征后,利用贝叶斯分类器计算用户可能关注的标签。即整体学科标签集L{L1,L2,…,Ln},用户已关注学科标签集L0{Lp,…,Lq}的情况下,其可能会关注其他学科标签Li的概率。利用式(4)选择排名为Top k的推荐信息,输出至待推荐数据集中,其中l为集合L-L0大小。
(4)
2.5.2 基于相似用户的推荐算法
基于相似用户的推荐算法是寻找与用户u0相似的用户ui,推荐ui关注而用户u0未关注的标签。基于相似用户的推荐算法核心是寻找相似用户,通过构建user-label权重矩阵寻找相似用户并产生推荐信息。如表5表示用户i的第j个标签权重值,每个用户对推荐对象的权重可看做是一个m维向量,用户间相似度就可以用m维向量间的相似度来衡量。

表5 用户-标签权重
余弦函数相似性未考虑用户权重尺度问题,如对用户u0来说权重值在w0以上会关注标签labelk,而对用户u1来说权重值在w1以上才会关注标签labelk,为保证推荐准确性,因此采用修正余弦函数相似性计算用户相似度。
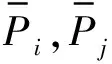
(5)
设集合U{u1,u2,…,un}表示与目标用户u0相似的所有用户,那么对用户u0的推荐信息可以通过集合U中用户ui关注的其他标签得到,Ru0,k表示对用户u0推荐标签labelk。通过式(6)计算排名为Top k的推荐信息,输出至待推荐数据集中。
(6)
2.5.3 其他信息推荐
用户会浏览最新动态的热点话题,关注已关注标签内最新话题,根据许少华等[14]提出维持新近最热门k条信息的方法得到问题标签数据集中排名为Top k的最新动态信息。据2.1节数据分析得到知乎用户间存在长尾效应,为此通过平衡信息关注度,挖掘部分冷门回答信息来提高整体用户活跃度。
2.6 最终推荐处理
因信息被赞量、被转发量、时间等因素影响,用户及问题排名不断变化。各推荐信息具有本质差异性,如基于标签推荐、基于相似用户推荐。因此对推荐信息采用多维度滑动窗口来维持区间内最优值。判断用户对不同推荐方法的满意度sati来动态调整不同类别推荐信息reci,以此来进一步修正推荐列表。
recommendation=∑sati×reci
(7)
3 实验设计与结果分析
3.1 实验数据集
利用基于所抓取2.6万条知乎用户数据、461万条关注链接、72万问题数据作为训练数据集,问题数据信息均来自于用户主页下已回答、点赞、关注、收藏的问题。利用Python Sklearn中K折交叉验证对训练集和验证集进行划分,分为75%训练数据集Sd和25%验证数据集Sp。定义测试数据集合St{历史,英语,数学,物理,经济学,化学,生物学,电工,电气工程,马克思经济学},在知乎平台上抓取数据集合St中各学科的100个用户和100个问题作为测试数据集,另选择100位志愿者参与调查问卷。训练数据集训练混合推荐模型,验证数据集验证模型的准确性,测试数据集测试推荐模型的性能。
3.2 推荐模型评价标准
评价推荐模型质量标准可从预测准确度、覆盖率、多样性、新颖性等方面考虑[13]。本文目的为提高用户与信息间的关联度,为此实验以预测准确度作为推荐模型评价标准。通过采用推荐模型衡量中常用的Area Under ROC Curve(AUC)用来评价推荐模型的质量。表6为ROS分类标准。

表6 ROS分类标准
Receiver Operating Characteristic Curve(ROC)是预测模型的特征曲线,ROC曲线的横纵坐标利用伪阳性率FPR=TP/(TP+FN))和真阳性率TPR=FP/(FP+TN)表示。A点越接近左上角则代表预测准确性越高;B点表示随机预测;C点越接近右下角表示预测准确性越低。曲线以下面积表示整体预测的正确率,即AUC值。
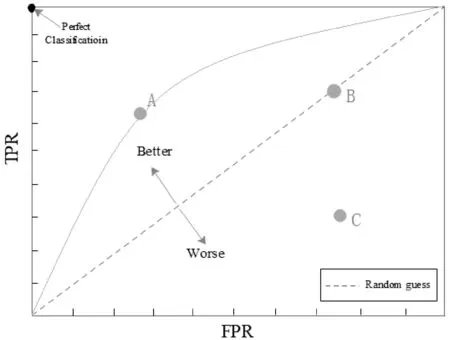
图2 模型优劣判断标准
本文选用知乎现有推荐算法和全局最优算法做为对比算法。知乎现有推荐算法根据用户关注的问题、回答过的问题、关注的用户、关注的话题构建推荐模型。全局最优算法将知乎文章按照全局被浏览次数进行排序,此算法基于用户倾向于关注最热门话题的原理。
3.3 实验设计
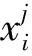
(8)
(9)
(10)
利用训练好后的模型为用户推荐个性化信息,分别计算混合推荐算法(HRA)、现有推荐算法(NRA)、全局推荐算法(GRA)的AUC值来评价模型的准确性。将测试数据集整理成调查问卷,匹配和用户相似的志愿者,让志愿者自主选择10条信息。将志愿者选择的信息当作真实集,HRA、NRA、GRA算法推荐结果当作测试集,计算相应AUC值来验证推荐模型准确性。
3.4 结果分析
利用Sklearn 选择出6 500个用户作为验证集,经训练模型输出推荐信息后,分别计算1 000、2 000、3 000、4 000、5 000、6 000、6 500个用户的平均AUC值,即推荐模型对不同数量用户时推荐的效率。如图3所示为HRA、NRA、GRA的推荐效率。当用户数量多于3 000时,HRA算法比NRA算法高9个百分点,比GRA算法最多高12个百分点。当用户数量达到3 200左右时AUC值稳定在0.78左右,实验结果表明基于混合算法的个性化推荐模型具有明显优势。
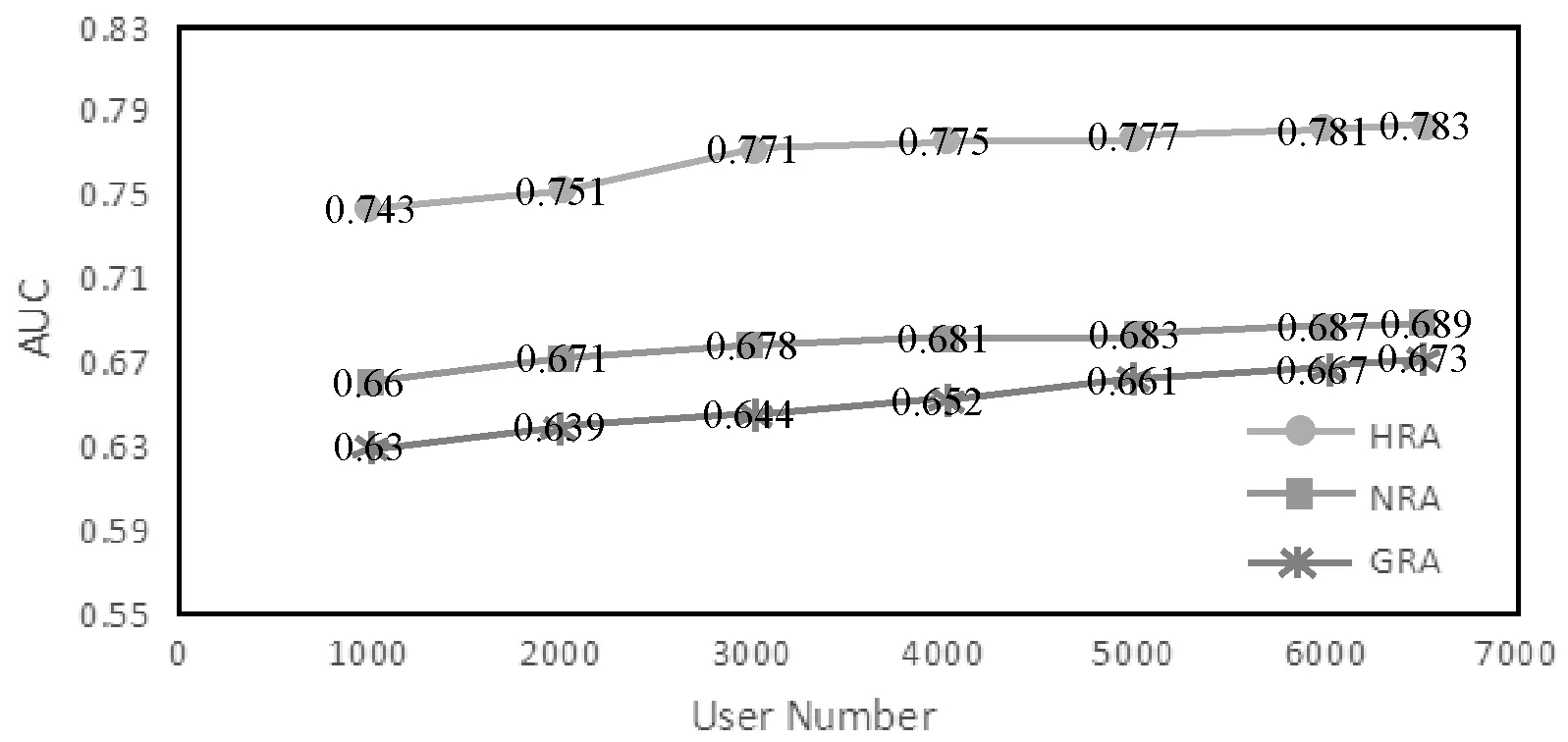
图3 不同推荐算法AUC值对比
为测试模型的准确率,以志愿者所选择信息为真实值,算法模型推荐为预测值,HRA、NRA、GRA算法的AUC预测值如图4所示。通过数据验证得到,在用户量多于60的情况下HRA算法比NRA算法高7个百分点,比GRA算法平均高8个百分点。表明面向知乎的个性化推荐模型能够有效推荐用户感兴趣的信息,模型所推荐的信息在一定程度上能够满足用户需求,个性化推荐效果得以提高,能够使有价值的信息和用户之间紧密关联。
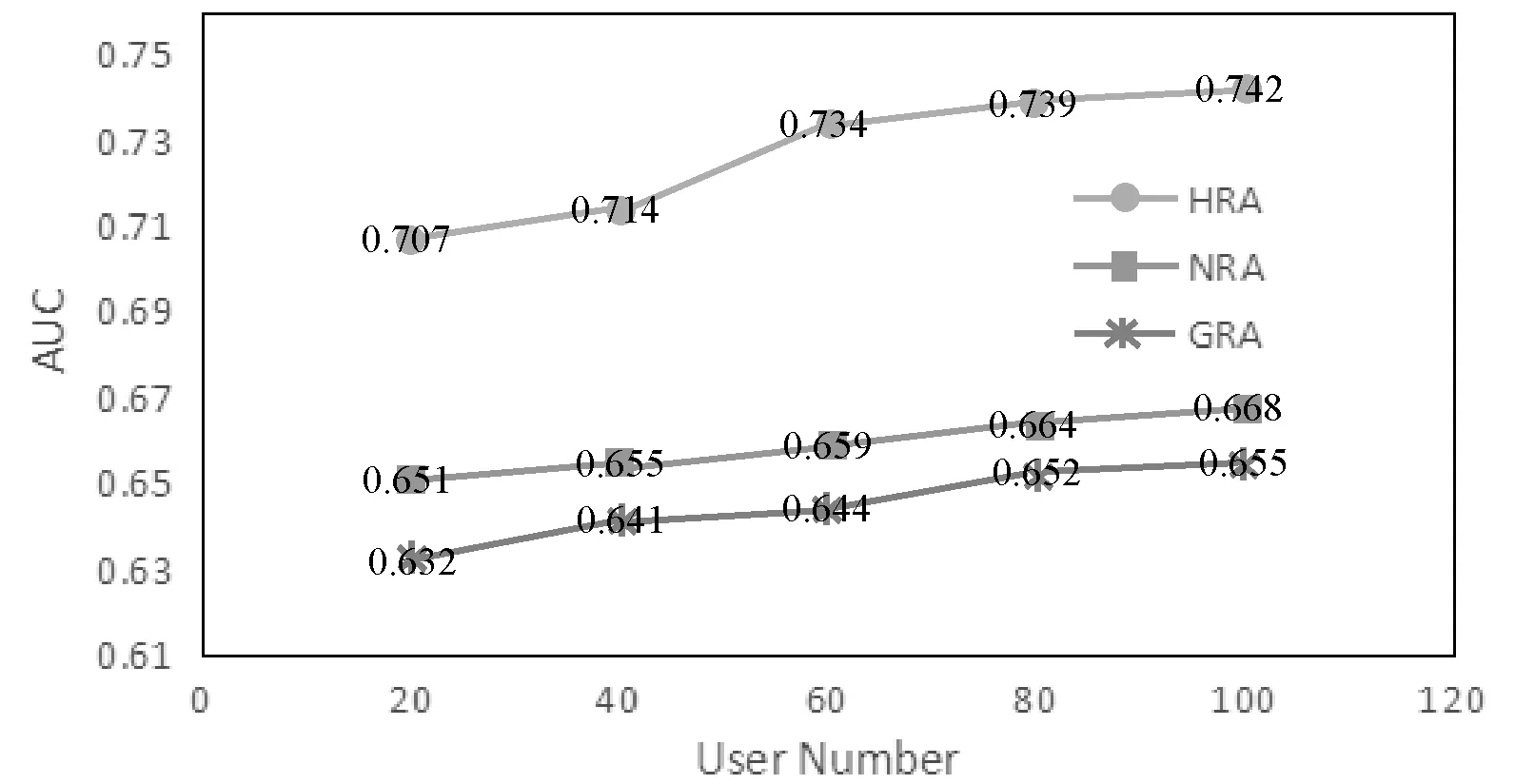
图4 推荐算法模型验证
4 结 语
在信息冗余的时代 ,用户应和有价值的信息更紧密地关联,为此改进知乎传统的信息推荐算法,构建基于混合算法的个性化推荐模型,对知乎传统的推荐方式改革创新。在构建面向知乎的个性化推荐模型时,注重用户个性、用户与知识间喜好关系,强调发挥用户的主体作用。把基于标签推荐、基于相似用户推荐等推荐算法引入至推荐模型中,达到增强用户之间联系、提高信息利用率、用户与有价值信息紧密结合的目的。提出的面向知乎的个性化推荐模型对随机选取的学科标签和用户进行测试,结果表明该模型能够有效根据用户兴趣偏好推荐个性化信息,推荐质量得到明显提高,信息利用率得到改善。
参 考 文 献
[1] 张蕊.“异军”知乎的突起——浅析知乎的发展现状[J].视听,2015(6):147-148.
[2] 陆地.“知乎”的知识生态圈分析与探究[D].北京印刷学院,2017.
[3] 刘婉婷,章杨.“知乎”的传播模式和未来发展[J].新闻世界,2015(8):150-151.
[4] 王国霞,刘贺平.个性化推荐系统综述[J].计算机工程与应用,2012,48(7):66-76.
[5] 花青松.个性化推荐系统用户兴趣建模研究与实现[D].北京邮电大学,2013.
[6] 单明.基于个性化推荐的电子商务推荐系统的设计与实现[D].吉林大学,2014.
[7] 李晓昀,余颖.基于隐性反馈的自适应推荐系统研究[J].计算机工程,2010,36(16):270-272,275.
[8] 陈景年.选择性贝叶斯分类算法研究[D].北京交通大学,2008.
[9] 单京晶.基于内容的个性化推荐系统研究[D].东北师范大学,2015.
[10] 荣辉桂,火生旭,胡春华,等.基于用户相似度的协同过滤推荐算法[J].通信学报,2014(2):16-24.
[11] 高明,金澈清,钱卫宁,等.面向微博系统的实时个性化推荐[J].计算机学报,2014(4):963-975.
[12] 姜霖,张麒麟.基于评论情感分析的个性化推荐策略研究——以豆瓣影评为例[J].情报理论与实践,2017,40(8):99-104.
[13] 陈佳慧.基于综合评价的个性化推荐算法研究[D].东北大学,2013.
[14] 许少华,宋美玲,许辰,等.一种基于混合误差梯度下降算法的过程神经网络训练[J].东北石油大学学报,2014,38(4):92-96.
[15] Cui C,Hu M,Weir J D,et al.A recommendation system for meta-modeling[J].Expert Systems with Applications,2016,46(C):33-44.
猜你喜欢
小学生学习指导(低年级)(2021年12期)2021-12-31
成都信息工程大学学报(2021年3期)2021-11-22
文苑(2020年4期)2020-05-30
阅读与作文(英语初中版)(2019年8期)2019-08-27
小学生学习指导(低年级)(2018年11期)2018-12-03
小学生学习指导(低年级)(2018年11期)2018-12-03
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
汽车与新动力(2016年6期)2017-01-04
Coco薇(2015年11期)2015-11-09
