
基于Hadoop平台下日志分析系统的研究
2018-06-27 02:38陈小龙丁祥武
无线互联科技 2018年5期
陈小龙 丁祥武
摘要:在信息系统当中,日志数据也就是用户对系统的操作记录以及系统自身的运行状7兄记录,对日志数据的有效分析,有利于排除系统故障、明确用户访问规律等。基于此,文章就Hadoop平台下日志分析系统展开研究,首先介绍了系统的总体框架,进一步对其设计与实现过程中,日志分析处理流程设计、日志数据预处理两个操作环节进行了重点介绍,并进一步提出了针对此类系统的检测方法。
关键词:Hadoop平台;日志分析系统;数据预处理
Hadoop是Apache软件基金会的一个开源项目,在并行处理大数据的研究与应用领域,属于一款极具代表性的产品。Hadoop平台提供的是一种分布式系统基础框架,适用于多种分布式应用的开发,且能够支持海量数据的高效运算与存储。由此可见,在进行日志分析系统的设计时,Hadoop是首选的支持平台,对实现日志分析系统的高效运行目标,具有极大的支持与推动作用。
1 基于Hadoop平台下日志分析系统的总体构架
Hadoop平台下日志分析系统的总体构架可以从以下几个方面进行阐述。
(1)日志收集的方式,传统的Web服务器在接收到用户访问HTTP请求后会对此行为做出记录,并且按照需求返还给用户正常的网页内容;此外还有页面标记法、爬虫或者扫描网站等方式产生的PV,不会被直接统计,一个页面的请求只会形成一个PV,对日志的收集和汇总也十分简单便捷。
(2)可以采用流量分析统计、来源分析统计、访客分析统计和订单分析统计等方法对日志的功能需求进行详细分析。對于数据的输出,因为客户的不同,输出展现形式也不一样,使用Web图表的形式进行合理展示十分必要。
(3)日志处理的流程分析,首先对作业进行合理配置,根据输入的日期时间和报表的类型,读取所有符合要求的记录,随后将作业提交到集群中进行统一处理,处理后的相关记录都会被保存到HDFS当中。最后作业完成执行,连接数据库,将最后的结果再一次存储到数据库当中。
(4)作业的详细设计,系统中包含输入输出包、工具包和业务包,其中输入输出包也就是IQ包,负责日志信息记录到数据库中,工具包,简称Util包,主要负责将字符串的模式解析和错误信息进行记录排除错误,业务包指的是Service包,是系统中最重要的组成部分,由一些mappreduce作业组成,有各种统计的功能作用。
2 基于Hadoop平台下日志分析系统的设计与实现策略
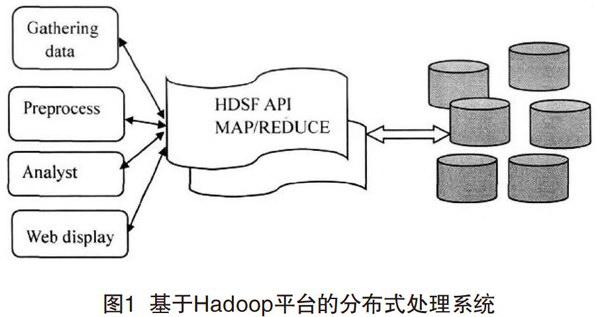
基于Hadoop平台设计日志分析系统,完成后的系统如图1所示,主要包括日志信息收集、日志预处理流程设计、作业详细设计以及统计结果呈现,共4个阶段。
2.1 日志数据预处理
基于Hadoop平台的日志分析系统当中,数据的预处理是系统功能实现的关键环节,整个阶段需要实现数据清洗、用户识别以及会话识别功能。以某电子商务网站系统的Web日志分析系统为例,日志数据,主要记录了用户对网站的所有访问行为,但后台检测时发现,所记录的日志信息当中,包含大量的冗余信息;且有部分信息受到了一定损害,呈现为不完整的状态;还有部分日志记录是错误的或者无效的。对于日志分析系统来说,这些信息数据的存在,增加了日志分析与处理的复杂性,当这些信息的量达到一定程度时,将会对分析结果造成影响,降低分析结果的准确度[1]。所以,有必要进行一系列的数据预处理操作,对记录中不完整的、不一致的数据信息进行清除,从而提升系统分析结果的准确度。
在某一网站系统运行过程中,用户发送了一个服务请求,此时,日志系统会自动记录与这一服务相关的所有信息,包括音频、视频、图片、文字等,一般情况下,这些日志信息的作用并不明显,但当需要进行某一图片、视频等的访问量时,这些记录就能够成为可靠的统计数据来源。但若要统计网站的日访问量与访客访问间隔分布,那么这些具体的音频、视频、图片等数据信息,就都成了冗余信息,删除之后,能够极大地提高日志分析处理效率。
基于Hadoop平台下的日志分析系统中,数据预处理阶段,能够有效进行数据清洗,操作过程中,应以相关统计需求、日志数据格式为依据,对日志记录进行分析处理,清除记录当中的不完整的、冗余的或无效的数据信息;若发现存在错误的记录,可对其进行适当的处理。其次,基于Hadoop平台的日志分析系统,能够利用userid字段表示访问用户,从而实现用户识别。当顺利识别访客之后,通过分析访客的点击序列,可以实现会话识别。会话识别的功能原理,就是先将访客的访问记录进行分类处理,形成一个个独立的会话;主要的识别方法就是超时识别,可通过对所有访客设置同一个超时阈值,或对相邻的请求设置超时阈值的方式,完成识别操作。需要注意的是,设置超时阈值,对预处理日志的输出会产生一定的影响,所以要尽量保证阈值的合理性,在30 min左右即可。
2.2 日志分析处理流程
基于Hadoop平台的日志分析系统中,日志分析处理流程模块的核心,是MapReduce计算模型,该模块的主要作用,就是完成事物逻辑规则设计与计算功能。利用MapReduce计算模型,能够实现对Web日志的高效处理,且当需要进行相关统计事务时,也能极大地降低统计工作的难度,提升工作效率。在进行数据预处理之前,日志记录中往往存在诸多无价值的数据信息,而日志处理模块的主要作用.就是将具有分析价值的信息筛选出来[2]。利用MapReduce计算模型,其Map阶段的主要作用,就是对所有的日志记录进行清洗,筛选出需要的信息,同时转化原始日志的形式成为
对于不同的网站系统来说,出入业务需求的差异,名相关统计规则也不尽相同,但对于统计功能及效果的实现原理是一致的,具体的流程如下。
(1)明确数输入路径,并依此对输入文件进行分割;并利用读入数据格式(InputFormat)中的RecordReader将数据读成
(2) Mapper接收到键值对之后,要进行Map操作,操作流程:Map
(3)由Redueer进行Reduee操作。
(4)由输出数据的格式(OutputFormat)中的RecordWriter输出结果。
3 基于Hadoop平台下日志分析系统测试
基于Hadoop平台下的日志分析系统,在完成初步设计之后,要对系统的可靠性与稳定性进行测试。整个测试流程,应从原始日志数据开始,依据数据处理流程,完整进行数据处理与分析。获得日志数据之后,通过系统的计算分析,能够得到时间分布示意图,通过对曲线图的分析,能够明确访问峰值出现的时间段,以及访问量的整体变化趋势‘3]。获得最终的统计结果之后,将其与以往总结的用户访问习惯、日常生活中人们的行为习惯等进行对比分析,进一步验证系统流程的正确性,以及分析结果的可靠性。
以某搜索网站为例,通过独立了访客统计需求实现,对基于Hadoop平台下日志分析系统进行测试,数据统计过程中,时间分布示意图,由UV统计组件计算获得,图像显示,该网站的用户在每天的10:00~18:00这一时段,每个时间点的访问量能够达到25 000~31 000次;10:00之前的访问量变化没有明显规律;18:00之后的訪问量则呈现为逐渐降低的变化趋势。这与人们的工作、学习时间的总体分布规律相符,由此证明了系统流程的正确性。
4 结语
探究基于Hadoop平台下日志分析系统,有利于更加深入地挖掘日志系统,获得更多有价值的信息,为相关统计决策提供更加可靠的支持。通过相关分析,基于Hadoop平台下的日志分析系统,能够实现对海量数据的高效分析与处理,能够充分满足当前及未来一段时间内的数据处理需求,具有较高的实践意义。
[参考文献]
[1]严春景.基于Hadoop平台和查询日志的用户行为分析系统设计与实现[D]广州:广东工业大学,2016.
[2]何健伟.基于Hadoop的数据挖掘算法研究与实现[D].北京:北京邮电大学,2015.
[3]陈娜.基于Hadoop平台的海量数据处理应用[D].长春:吉林大学,2012.
