
卡尔曼滤波算法在我国钢产量预测中的运用
2018-06-29 01:37舒服华马勇军
徐州工程学院学报(自然科学版) 2018年2期
舒服华,马勇军
(1.武汉理工大学,机电工程学院,湖北 武汉 430070;2.武汉科技大学,材料与冶金学院,湖北 武汉 430081)
随着国家供给侧结构性改革政策的实施,在去产能、去库存、去杠杆等一系列方针的指引下,我国钢铁行业淘汰落后产能,压缩过剩产量的大幕已经开启.目前钢铁行业的颓势正在逐步退去,各地基本完成削减产能的目标,钢铁产量基本保持相对稳定,钢铁价格也开始逐步回升,大部分企业扭亏为盈.科学预测我国钢铁的产量,是制定钢铁行业战略发展规划的基础,对指导钢铁企业有序生产经营、保持我国钢铁行业平衡发展具有重要的现实意义.对于钢产量的预测问题,国内学者研究的方法主要有自回归平均移动法、灰色预测方法等[1-2],预测精度都不够理想.卡尔曼滤波算法是一种最优自回归估计技术,它以最小均方误差为估计准则,构造一套递推估计算法,实现对状态变量的发展趋势的估计,即利用状态变量前一时刻的估计值与现时刻的观测值来更新对状态变量的估计,以获得状态变量现时刻的最佳估计值,预测精度高,计算简便,在许多工程领域得到了应用[3-10].本文运用卡尔曼滤波算法预测我国月度粗钢产量,以提高预测的准确性.
1 卡尔曼滤波算法基本原理
卡尔曼滤波算法本质上属于一种递推反馈算法.基本原理是以k-1时刻变量的最优估计为基准,预测k时刻变量的状况,同时对该状态进行观测,通过分析观测值和预测量的差异,采用观测值和预测量相结合办法对预测值进行修正,从而得到变量k时刻的最优状态估计.卡尔曼滤波算法可分为二个部分构成:即时间更新方程与测量状态更新方程.前者的功能是递推,后者的功能是反馈.反馈在整个算法中显得极其关键,它将先前的状态和新的测量值相结合,经过比较分析后,以二者为基础构造改进规则,以得到其最后的最佳估计.即根据测量值和估计值这两个量之前的表现,各自给它们们分配一个权重,之前表现越好的量其权重就越高,否则,权重就越低,分配的权重即所谓的卡尔曼增益.表现好即测量值或估计值方差很小,表现不好就是测量值或估计值方差较大.通过逐步修正估计值,使其达到最佳状况.卡尔曼滤波算法的时间更新方程即为预测方程,测量更新方程即为校正方程,它们分别可表示为
预估方程
(1)
校正方程
(2)

运用卡尔曼滤波算法预测时间序列时,就是将时间序列视为时间状态变量,借鉴卡尔曼滤波算法的特点对其发展趋势进行估计.在工程应用上状态变量有3个值:实际值、观察值(测量值)、估计值,预测时间序列时,可将实际值、观察值合二为一,时间序列的实际值即为观测值.这样,公式中的参数A=1,uk=0,H=1,B也就无意义.可见,运用卡尔曼滤波算法预测时间序列比较容易实现,所要确定的参数仅为P0,Q,R;P0一般可以任意选取,因为算法能自动更正不合理的取值,但注意P0不能为0,否则,滤波器会认为已经没有误差了,认定初始值就是系统最优估计,而停止寻优过程,故只需选择合适的Q,R二个参数即可.卡尔曼滤波算法流程如图1所示.
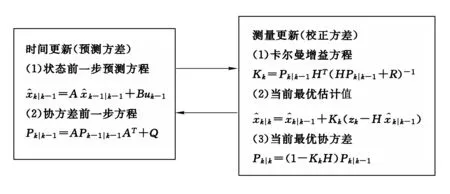
图1 卡尔曼滤波算法原理图
2 我国粗钢产量预测

图2 我国粗钢产量统计数据
图2为2016年7月—2017年12月我国粗钢产量统计数据(数据来源于中国钢铁协会),近18个月来我国粗钢产量虽整体来看基本稳定,但也有一定的波动.2017年11月跌入谷底,仅为6 615.1万t,2017年8月达到峰值,为7 459万t,振幅为12.76%.这与我国正在实施钢铁行业的改革直接有关.众所周知,钢铁行业在我国是属于产能严重过剩的产业,且能耗高、污染大,也是资源消耗性产业.为了提高经济发展的质量,推进生态文明建设,走绿色发展道路,钢铁行业正在加快推进淘汰落后产能,优化产业升级的步伐.产量的波动也暗示这一过程还没有结束,仍将继续.只有通过兼并重组,优化资源配置,促进产业转型升级,才能使我国从钢铁大国向钢铁强国迈进.
以2016年7月—2017年12月我国粗钢产量统计数据为观测值,建立卡尔曼滤波模型,模型参数设定P0=1,经尝试,Q=0.000 05,R=0.000 1,预测效果最佳.通过MATLAB 2014软件运算,得到了2016年7月—2017年12月我国粗钢产量预测值,结果见表1.从表1知,模型具有很高的预测精度,平均预测误差仅为0.034 37%.说明了运用卡尔曼滤波算法预测我国粗钢产量切实可行,效果显著.

表1 我国粗钢产量预测结果及比较
为了检验模型的性能,以上述数据建立自回归平均移动模型 (ARMA)对我国粗钢产量进行预测,设我国最近18个月粗钢产量为时间序列xt,经检验xt为非平稳时间序列,不符合建模要求,对xt进行一次差分后仍然不平稳,进行二次差分后时间序列(用d(xt,2)表示)变为平稳序列,d(xt,2)满足建模要求.经分析比对,模型的最佳阶数为ARMA(1,1),运用EVIEWS 8.0软件,得到模型的参数估计,结果如图3所示.
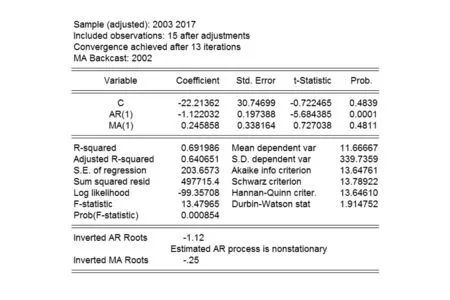
图3 ARMA(1,1)模型参数估计结果
根据估计参数得到的预测方程为
xt=-22.213 62-1.122 032xt-1+εt+0.245 858εt-1,
(3)
式中εt为白噪声序列.
根据式(3)得到2016年7月—2017年12月我国粗钢产量预测值(由于原始数据经过了差分处理,并且后期的预测与前期数据有关,故前几期的值不能预测),结果见表1.从表1知,ARMA模型的平均预测误差为2.173 4%,卡尔曼滤波模型比ARMA模型的平均误差减小了98.418 6%.可见卡尔曼滤波的优势,模型可谓高效、实用、可靠.两种模型的预测曲线如图4所示.从图4可见,卡尔曼滤波法的预测曲线与实际值的曲线几乎重合.

图4 预测曲线及比较
至于对2018年1月我国粗钢产量的预测,由于没有观测值,卡尔曼滤波无法独立实现.此时可以借助ARMA模型预测后一期的值,可将ARMA模型预测得到的2018年1月的值作为观测值,再利用卡尔曼滤波预测2018年1月的值.由ARMA(1,1)预测得到2018年1月我国粗钢产量为6 017.638万t,考虑到ARMA模型的预测误差,还需对这一值进行修正.取ARMA模型平均误差的50%来修正2018年1月的预测值,并结合2017年12月实际产量处于上升趋势,修正方向应为正,得到修正后ARMA模型预测的2018年1月粗钢产量值为6 083.75万t.将这一数值加入到原时间序列,通过卡尔曼滤波模型运算,最终得到2018年1月我国粗钢产量预测值为6 096.52万t.这一结果显然比ARMA预测结果合理,2017年12月我国粗钢产量处于回升状态,按照这样的态势,2018年1月的粗钢产量应该有所增加,卡尔曼滤波法预测的结果与变化趋势一致,粗钢产量有小幅增加,而ARMA预测结果为产量下降,且降幅偏大,显然不太合理.可见,卡尔曼滤波法预测结果比较可靠.
3 结语
钢铁工业在国民经济和国防建设中的战略性地位不言自喻,钢铁产量和储备保持在一个合理的水平十分必要.卡尔曼滤波算法是一种挖掘数据内部隐含的信息,并通过不断改进和不断完善算法而处理不确定信息的先进技术,它以线性最小方差估计方法给出状态的最优估计值,能够得到最接近状态真值的估计值,计算方便,预测精度高,在工程领域得到了广泛的应用.本文运用卡尔曼滤波算法预测我国钢铁产量,效果显著,平均预测误差仅为0.034 37%,比ARMA模型的预测误差2.173 4%减小了98.148 6%.预测得到2018年1月我国粗钢产量为6 096.52万t.
参考文献:
[1] 廖冰清.基于SARMA模型的我国粗钢产量时间序列分析与预测[J].企业导报,2012(24):105-106.
[2] 吴国锐,郑红.灰色GM(1,1)模型在预测钢产量中的应用[J].长沙航空职业技术学院学报,2007,7(3):58-60.
[3] 修春波,任晓,李艳晴,等.基于卡尔曼滤波的风速序列短期预测方法[J].电工技术学报,2014,29(20):253-257.
[4] 赵攀,戴义平,夏俊荣,等.卡尔曼滤波修正的风电场短期功率预测模型[J].西安交通大学学报,2011,45(5):47-51.
[5] 谢合亮,张砣.卡尔曼滤波在高频金融时间序列模型预测中的应用[J].统计与决策,2017(13):82-84.
[6] 南亚翔,李红利,修春波,等.基于卡尔曼滤波的空气质量指数预测方法[J].环境科学导刊,2016,35(3):80-84.
[7] 许哲明.基于卡尔曼滤波的地表移动变形预测[J].沈阳工业大学学报,2017,39(5):557-561.
[8] 张恒德,咸云浩,谢永华,等.基于时间序列分析和卡尔曼滤波的霆预报技术[J].计算机应用,2017,37(11):3311-3316.
[9] 张智勇,张丹丹,贾建,等.基于改进卡尔曼滤波的轨道交通站台短时客流预测[J].武汉理工大学学报(交通科学与工程版),2017,41(6);974-977.
[10] 彭湃,程汉湘,陈杏灿,等.基于自适应卡尔曼滤波的锂电池SOC估计[J].电源技术,2017,41(11):1541-1544.
猜你喜欢
中国钢铁业(2022年2期)2022-05-11
数字技术与应用(2021年2期)2021-04-22
湖南大学学报·自然科学版(2021年1期)2021-02-21
中国钢铁业(2020年9期)2020-12-16
中国钢铁业(2020年4期)2020-06-28
智能计算机与应用(2020年10期)2020-03-18
中学生数理化·高一版(2019年12期)2019-12-31
中国钢铁业(2019年10期)2019-06-11
中国钢铁业(2018年6期)2018-07-26
导弹与航天运载技术(2016年2期)2016-10-14
