
智能化网格电信系统的故障预测方法
2018-07-03 10:37蔡珩戈磊
电信科学 2018年6期
蔡珩,戈磊
智能化网格电信系统的故障预测方法
蔡珩,戈磊
(中国电信股份有限公司上海分公司,上海 200042)
尝试用基于深度学习的相关人工智能技术,分析服务器集群上的进程和端口网络,并对网络节点进行状态预测。具体地,结合运维过程中的先验知识对网络节点的特征进行细致选择,预测网络中各个进程和端口的异常(崩溃)状态。实验结果表明,进程节点的运行信息(如CPU和内存使用率)、进程间的通信情况以及进程节点在整个网络中的结构特征对于判断该节点的状态具有一定的指导价值,而这些特征在时间维度上的变化量同样反映了进程/端口的状态。
故障预测;深度学习;二分类
1 引言
随着信息技术的发展,大规模服务器集群和网络设备的部署和使用日益广泛,在集群上运行各种服务[1]逐渐成为大型企业的选择。同时,对集群上各种资源的监视和管理也得到学术界和工业界的大量关注。
人们总是希望部署一个可靠稳定的服务器集群,然而事与愿违,大部分集群上还是会出现如进程崩溃[2]、端口流量过大、端口阻塞[3]等异常情况。人们往往采取人工查看服务器日志的方式,通过各个进程和端口的状态判断哪些进程或端口可能会发生异常并采取相应的措施,但是这种方式耗时耗力,并且人工查看具有时限性和一定的误差。
本文将采用一些基于深度学习的方法,对服务器集群上的进程和端口网络进行分析,并对该网络上的节点即某个进程或端口的状态进行预测。
本文首先对服务器集群上的进程网络进行建模,而和被广泛关注的社交网络[4-8]不同的是,缺乏对该进程网络上节点的了解,比如一个进程何时会与周围的进程产生通信、为什么会产生通信以及本文的预测目标:一个进程是否会发生崩溃,因为进程间的通信通常依赖于某个进程的具体功能和实际服务的使用情况。即便如此,本文还是可以类比社交网络中节点的相关性质,对该进程网络中的节点做出如下分析。
•将某个进程的占用CPU、内存情况看作进程节点的“固有属性”。
•进程之间的通信看作进程网络中的边,那么,节点在网络中的中心度[9-10]可以衡量节点的活跃程度以及与外界联系的紧密程度。
•把进程崩溃视作一个进程的行为,那么进程崩溃这一现象可以类比为社交网络中信息的扩散[11-12]。
基于以上分析,本文把一个进程或端口发生崩溃、阻塞等异常的现象定义为网络中一个节点的状态;在给定的时间戳下,网络中的节点可以被分为两类:处于异常状态的节点和处于正常状态的节点。因此,预测网络中节点的异常[13]可以转化为针对网络节点的二分类问题[14]。本文仔细地选取节点的相关属性作为节点分类的特征,用卷积神经网络(convolutional neural network,CNN)[15]对该模型进行分类,并得到了较为可信的结果。
2 相关定义
2.1 进程网络
本文对服务器集群上的进程网络以及该网络中的节点、边和节点状态做出如下定义。
定义1 (进程标识符)用一个进程的如下信息作为其标识符:本地IP地址、本地主机名、本地进程组、进程描述以及进程号。换句话说,上述5个字段可以唯一地确定一个进程。
如果两条日志记录中进程的标识符完全一致,则认为是同一进程的记录。
定义5 (远端进程)把在日志记录中本地IP地址或本地主机名为空的进程定义为远端进程。由于日志记录是由本地probe(探针)对正在运行的进程进行遍历得到的,因此,日志记录中本地IP地址或主机名为空可以视作该进程不在这个服务器集群上,将这类进程称为远端进程。
2.2 端口网络
定义6 (端口标识符)用一个端口的如下信息作为其标识符:主机名、端口名。如果两条日志记录中主机名和端口名一致,认为这是同一端口的记录。
3 数据观察
在对进程和端口状态进行预测前,先从整体上对数据做一些基本的分析。
3.1 进程网络
3.1.1 数据量
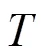
3.1.2 静态特征分布
•CPU占用率;
•内存使用量;
•与之存在通信的进程数量(即进程网络中节点的度);
•与其他进程的通信总量(即进程网络中节点的边权之和);
•存在通信的远端进程数量;
如图1所示,正负样本在CPU这一“固有属性”上存在一定的差异:对于负样本即正常进程,它们的CPU使用率集中在20%以下和100%以上;而正样本(异常进程)的CPU使用率分布较为分散。根据经验,这种分布是可以理解的,因为对于正在运行的进程,如果是计算密集型的,CPU使用量会较高,否则一般不会太多地占用CPU资源。
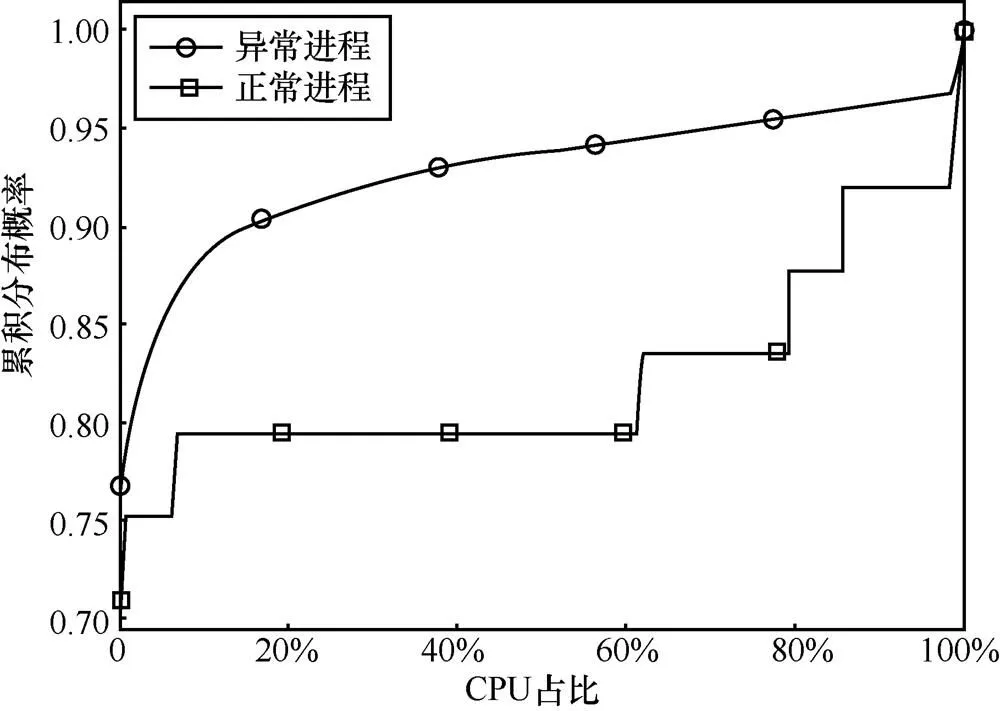
图1 CPU占比的整体分布
图2为存在通信的进程数量这一非结构特征的整体分布。可以看到,存在通信的进程数量在正负样本之间没有显著区别(进程网络中节点的度大多为1);进程节点的带权重的度以及远端通信进程数量这两个特征的结果也和图2类似。也就是说,正负样本在这3个非结构特征上没有明显差异。

图2 存在通信的进程数量的整体分布
对该进程网络中的结构特征的分布情况进行考察。再次回到本文的目标:对于给定的进程,其是否为崩溃状态。对于较大规模的服务器集群,其上运行着大量进程,不难想象,一个进程关联的其他进程越多,该进程就越重要,其对服务器的负载就越重,崩溃的可能性就越大。
因此,选择进程网络图上的结构特征来衡量一个进程的重要性或者核心程度,希望通过进程节点的中心度[9-10]来帮助对进程状态进行分析。图3给出了进程节点的中心度的分布情况。其中,横坐标为中心度的十进对数,纵坐标为累积分布概率。
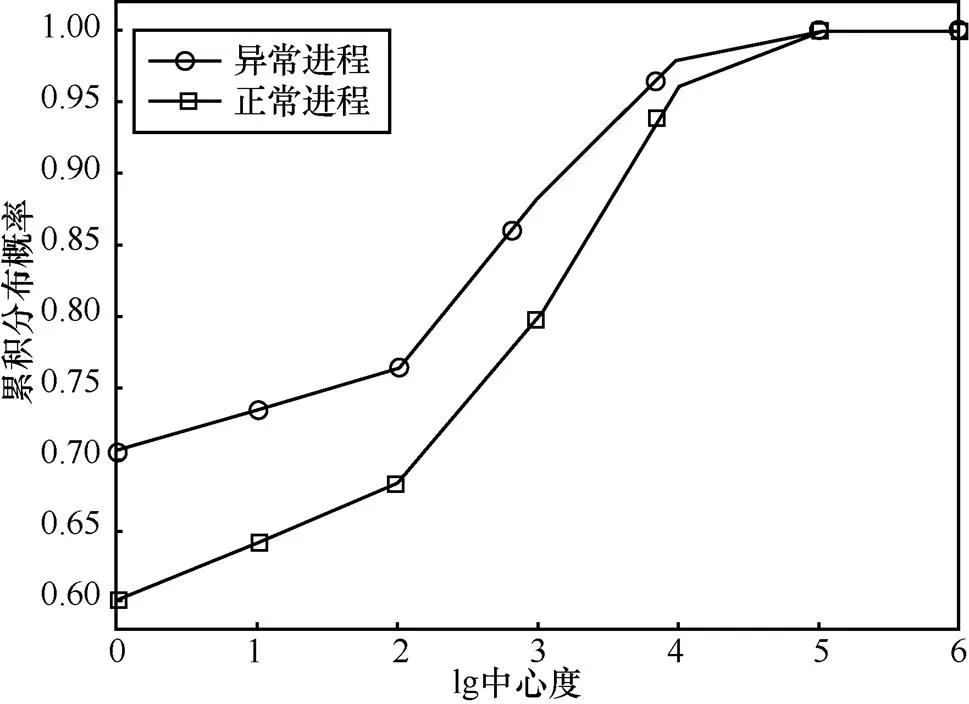
图3 中心度的整体分布
可以看到,相对于正常进程,正样本(异常进程)的中心度偏小,但整体分布是相似的,紧密性也是类似的结果。但这并不意味着“中心度高的重要进程更容易崩溃”这一假设不正确,因为往往一个中心进程崩溃会导致与其存在通信的其他进程或者该进程的子进程产生异常,而日志记录是在某个特定的时间点通过探针生成的,因此很有可能在生成日志记录的时候,以该中心进程为核心的进程组都进行了重启,因此正样本的中心度分布和样本的整体分布没有较大区别。
值得注意的是,中心度和紧密性具有一定的相关性,二者作为特征训练分类器的效果也许会有意想不到的效果,在实验中也将看到这一点。
3.1.3 时间间隔分布
前文对进程的静态特征做了整体分析,但是还应当注意到,进程的崩溃是一个过程,时间维度上的特征也许会较好地反映进程的状态。
本文考虑进程从正常状态到崩溃状态的时间间隔,体现在日志记录中即同一进程的进程号两条不同的连续日志记录的时间戳的差。如果进程一直保持着正常状态(没有崩溃),则倾向于认为其在日志记录中出现的时间戳应当是比较稳定的,即不会突然在一段时间内没有日志记录。而对于发生崩溃的进程,由于其重启等因素,可能会有较长时间间隔没有日志记录的现象。
图4为正负样本的时间间隔的整体分布。其中,横坐标为进程距离上次出现在探针日志中的时间间隔(分钟),纵坐标为累积分布概率。
再一次地,可以发现在时间间隔这一特征上没有显著区别。由于探针每3 min采样一次,因此时间戳的差集中在3、6或9等数值上。

图4 时间间隔的整体分布
3.2 端口网络
3.2.1 数据量
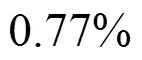
3.2.2 端口特征
对具体某个端口,定义以下特征:
图5为端口在前一天各个小时中的平均入口流量分布。可以看到异常端口和正常端口的差距是较为明显的:相对于正常端口,异常端口各个小时的平均流量有明显的下降,可以猜测发生了端口阻塞,导致异常端口在同时段内流量较少。
同样地,如图6所示,异常端口和正常端口在前3天的出口流量方差这一指标上也是区别显著:相对于正常端口,异常端口的出口流量在一天内的方差很大(很可能是因为异常端口时断时续地进行工作,出入流量的方差相比正常端口自然要大一些)。图7是端口在前3天出现告警次数的平均值。可以看到,如果当天端口出现异常情况,那么在前3天这个端口也很有可能已经出现了异常情况。

图5 前一天平均入口流量分布

图6 前3天出口流量方差
值得注意的是,图5和图6的结果是在2017年4月份的数据集上得出的,不同时间段内异常端口的表现可能不一致,如异常端口可能会出现出入口流量方差较小的情况(和图6恰恰相反),这有可能是因为异常端口被阻塞,流量在一天的大部分时间内恒定地处于较低水平,表现出方差较小的情况。但经过大量数据的测试,发现异常端口和正常端口在出入口流量方差和小时总量这两个指标上总是有较为显著的区别。
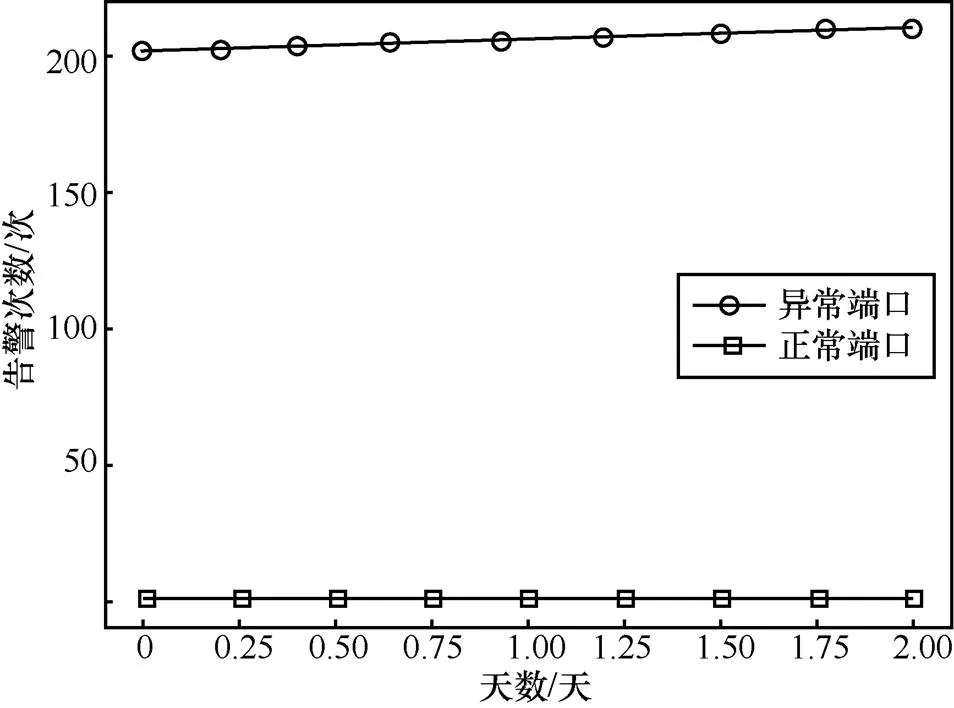
图7 前3天告警次数分布
4 实验方法
将用分类问题的思路判断给定进程或端口的状态。进一步地,由于状态只有异常和正常两种,因此目标简化为二分类[14-18]问题:给定一个进程/端口的相关描述,输出该进程/端口所处的状态(异常与否)。
4.1 训练方法
4.1.1 进程网络

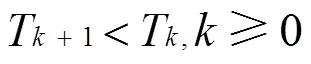

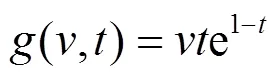
根据样本的输入特征,在训练集上训练得到CNN,对测试集中的每个进程或输出判断结果,用准确率、召回率和F1得分来衡量分类器的优劣。
其中,由于正负样本比过小(正样本过少),本文采用过采样(over-sampling)[20]的方法生成训练集,用交叉验证(cross-validation)[21-22]的方式对分类器进行训练,然后对正样本极少的原始数据集进行测试。
4.1.2 端口网络
类似地,对于端口的异常预测这一问题,人工提取第3.2节中提及的各个特征作为输入,通过训练集得到一个CNN分类器,对测试集中的每个进程或输出判断结果,用准确率、召回率和F1得分来衡量分类器的优劣。
同样,由于正负样本比过小(正样本过少),本文采用部分随机采样(partly-random sampling)的方法对负样本进行采样,以平衡正负样本比生成训练集,然后用交叉验证的方式对分类器进行训练,对正样本极少的原始数据集进行测试。
4.2 标签的提取
对于进程网络,按照定义4给出的方式,人工从原始数据集中提取进程标签(正负样本)。即首先过滤日志得到常驻进程,对每个常驻进程,判断其上一条时间戳的日志记录的进程号是否与当前时间戳的进程号一致。若不一致,则认为在当前时间戳该进程发生崩溃,采集为正样本,否则为负样本。
而端口网络数据集中含有标签信息,直接提取即可。
5 实验结果
5.1 进程网络
本数据集(上海电信CSB服务器集群的进程日志)时间跨度为2016年8月30日14—18时,共2 858 063条日志记录。其中,常驻进程973个,进程崩溃次数为25次,正负样本比为0.16‰。
本文随机地对正负样本进行分割,使训练集和测试集的大小一致。由于正负样本比过低,本文采用正样本过采样和交叉验证的方式进行训练,每次训练和测试过程重复10次,结果取平均值。
首先考虑具体的某个基本特征对分类效果的影响。
图8给出了不同特征对分类结果的影响的比较。横向地和没有剔除任何特征的分类器相比,可以发现,CPU、内存使用量以及远端进程数量这3个特征对区分正负样本的作用是显著的,剔除其中任何一个都会使F1得分有明显的下降。这个结果和特征的分布具有一致性,因为正负样本的CPU占用率和内存使用量的分布有着明显的区别;而对于剔除节点的度、边权和以及图的结构化特征中心度和紧密性,可以发现随着正负样本比的降低,F1得分反而在增加。

图8 单个特征对结果的影响
进一步地,为了考虑不同特征之间的相关性的影响,把上述的特征分为3类:进程的运行信息,即CPU和内存使用情况;进程的通信情况,体现为进程网络中节点的度(或带权重的边权和)以及存在通信的远端进程数量;进程网络中节点的结构特征,即中心度和紧密性。
图9展示了不同特征对分类结果的影响。可以看到,第二类特征即进程的通信情况,极大地提高了分类器的召回率,但是准确率很低,这是因为有大量的负样本在该特征上和正样本具有相同的值,在只有第二类特征的条件下,分类器倾向于认为大部分样本都是正样本。因而崩溃预测在没有第二类特征的分类器上达到了最好的效果。

图9 单组特征和组合特征对分类的影响
而第一类和第三类特征都可以在一定程度上反映进程的状态。这是因为正如在图9中,正负样本的CPU和内存使用情况的分布不同,而第三类特征即进程节点的中心度,尽管分布相似,但二者具有紧密的相关性,结合在一起考虑便可以作为崩溃检测的指标之一。


图10 不同特征变化量对应的F1得分
这说明进程的崩溃不是突然的,一个进程在发生崩溃的前后,其CPU、内存使用情况以及和其他进程的通信等属性往往会有突出的变化:比如在PC(个人计算机)上,往往一个进程占用内存过大会出现崩溃,崩溃前内存使用量增加的趋势则反映了其崩溃的可能性。
实验结果表明,将时间信息加入进程的特征进行训练,得到了效果更好的分类器以对进程的崩溃进行检测。
5.2 端口网络
本文选取了上海电信IDC的2017年4月份的端口流量监控记录,日活跃端口数量均值为6 175.5。
本文将4月1—13日的数据作为训练集训练分类器,用4月14—20日的数据作为测试集。
如表1所示,训练得到的分类器对测试集的预测是较为准确的,平均F1得分可以达到0.8左右。
表1 端口网络实验结果

6 结束语
本文针对上海电信的进程网络和网络端口,分析了网络中节点的有关属性,选取节点的特征进行训练以对节点的异常状态进行预测。
通过仔细地选取特征和相应的预测结果,可以得到如下结论。
•由于数据集上正样本的稀疏性,训练数据的正负样本比对训练结果有显著的影响。
•相比于进程的通信情况,进程节点的结构特征以及进程运行信息(如CPU占用率、内存使用量等)对于判断一个进程是否会崩溃更具参考价值。
•从时间的维度看,进程的运行和通信信息的变化量更能反映该进程的状态。
•从时间的维度看,端口过去3天的告警次数和出入流量方差更能区分其是否异常。
针对进程故障预测这一问题,未来还可以从以下两方面着手考虑。
•类比社交网络中的信息扩散[11-12],可以把进程崩溃看作进程的一种行为,通过对进程节点之间的影响力进行建模,可以预测进程的崩溃情况。同样的,对于网络端口来说,对网络上的边进行建模(如端口的通信),也可以将端口出现异常视作在端口网络中扩散的一种行为。
•除了人工地选取进程特征进行训练,还可以运用图表示[23]的方法对进程和端口网络进行建模,用embedding的结果作为特征训练分类器。
[1] DAMANI O P, CHUNG P E, HUANG Y, et al. ONE-IP: techniques for hosting a service on a cluster of machines[J]. Computer Networks and ISDN Systems, 1997, 29(8-13): 1019-1027.
[2] MOOLENBROEK D V C, APPUSWAMY R, TANENBAUM A S. Integrated system and process crash recovery in the loris storage stack[C]//Networking, Architecture and Storage(NAS), 2012 IEEE 7th International Conference, October 14-17, 2012, Seoul, Korea (South). Piscataway: IEEE Press, 2012: 1-10.
[3] MOHAMED E, ABDEL-WAHAB H, SALAMA I. Multicast address management in the internet: a study of the port blocking problem[R]. 1999.
[4] NEWMAN M, BARABASI A L, WATTS D J. The structure and dynamics of networks[M]. Princeton: Princeton University Press, 2006: 419-421.
[5] GRANOVETTER M. The strength of weak ties[J]. American Journal of Sociology, 1973, 78(6): 1360-1380.
[6] ONNELA J P, SARAMAKI J, HYVONEN J, et al. Structure and tie strengths in mobile communication networks[J]. The National Academy of Sciences, 2007, 104(18): 7332-7336.
[7] CHORMANSKI K, MATUSZAK M, MIEKISZ J. Scale-free graph with preferential attachment and evolving internal vertex structure[J]. Journal of Statistical Physics, 2013, 151(6): 1175- 1183.
[8] MILGRAM S. The small world problem[J]. Psychology Today, 1967, 2(1): 185-195.
[9] FREEMAN L. A set of measures of centrality based on betweenness[J]. Sociometry, 1977, 40(1): 35-41.
[10] NEWMAN M. Networks: an introduction[M]. Oxford: Oxford University Press, 2010.
[11] GOMEZ-RODRIGUEZ M, LESKOVEC J, KRAUSE A. Inferring networks of diffusion and influence[J]. ACM Transactions on Knowledge Discovery from Data, 2010, 5(4): 1-37.
[12] RODRIGUEZ M G, BALDUZZI D, SCHOLKOPF B. Uncovering the temporal dynamics of diffusion networks[C]//The 28th International Conference on Machine Learning (ICML), June 28-July 2, 2011, Bellevue, Washington, USA. [S.l.:s.n.], 2011: 561-568.
[13] LIBEN-NOWELL D, KLEINBERG J. The link prediction problem for social networks[J]. Journal of the Association for Information Science & Technology, 2007, 58(7): 1019-1031.
[14] LAST M. Kernel methods for pattern analysis[M]. Beijing: China Machine Press, 2005.
[15] KIM I. Convolutional neural networks for sentence classification[J]. arXiv: 1408.5882, 2014.
[16] CONKLIN J D. Applied logistic regression[J]. Technometrics, 2013, 44(1): 81-82.
[17] BRANDES U. A faster algorithm for betweenness centrality[J]. Journal of Mathematical Sociology, 2001, 25(2): 163- 177.
[18] SABIDUSSI G.The centrality index of a graph[J]. Psychometrika, 1966, 31(4): 581-603.
[19] JAPKOWICZ N. The class imbalance problem: significance and strategies[C]//The 2000 International Conference on Artificial Intelligence(IC-AI’2000), June 26-29, 2000, Las Vegas, USA. [S.l.:s.n.], 2000.
[20] GEISSER S. Predictive inference: an introduction [M]. New York: Chapman and Hall, 1993.
[21] KOHAVI R. A study of cross-validation and bootstrap for accuracy estimation and model selection[C]//The Fourteenth International Joint Conference on Artificial Intelligence, August 20-25, 1995, Montreal, Quebee, Canada. New York: ACM Press, 1995: 1137-1143.
[22] LEIKE, A. Demonstration of the exponential decay law using beer froth[J]. European Journal of Physics, 2002, 23(1): 21.
[23] MOHAR B. A linear time algorithm for embedding graphs in an arbitrary surface[J]. SIAM Journal on Discrete Mathematics, 2006, 12(1): 6-26.
Intelligent fault prediction method of telecom system
CAI Heng, GE Lei
Shanghai Branch of China Telecom Co., Ltd., Shanghai 200042, China
Some approaches based on deep learning would be used to analyze the process and port network on a server cluster. Specifically, the features of nodes were carefully selected in server cluster network, by combining the prior knowledge from actual operations, and the abnormal state of processes or ports on the cluster was predicted. According to the research, the running information such as loads of CPU and memory, communications between processes and the structural features in the process network was valuable in predicting the states of processes and ports; furthermore, the changes of features mentioned above in the time dimension reflected the states of processes or ports, too.
fault prediction, deep learning, binary classification
TP391.1
A
10.11959/j.issn.1000−0801.2018118
蔡珩(1976−),女,中国电信股份有限公司上海分公司工程师,主要研究方向为IT智慧运营、利用大数据技术提升系统运维的智能化。

戈磊(1973−),男,中国电信股份有限公司上海分公司企业信息化部高级项目经理,主要研究方向为云计算、开源架构、大数据分析、Devops运营、流程生命周期管控等。
2017−10−17;
2018−02−05
猜你喜欢
华人时刊(2021年13期)2021-11-27
心声歌刊(2020年4期)2020-09-07
中国外汇(2019年20期)2019-11-25
电子测试(2018年1期)2018-04-18
小学生(看图说画)(2017年6期)2017-11-06
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
电测与仪表(2014年15期)2014-04-04
民主与科学(2014年3期)2014-02-28
电子设计工程(2014年19期)2014-02-27
