
哈希表和多比特Trie相结合的IPv6分阶段路由查找算法
2018-07-04 13:12闵玉涓赵晶晶
小型微型计算机系统 2018年5期
秦 怡,杨 云,闵玉涓,姚 明,赵晶晶
(扬州大学 信息工程学院计算机系,江苏 扬州 225127)
1 引 言
随着近几年物联网以及车联网等概念的大热,目前互联网上广泛使用的IPv4(Internet Protocol Version 4)技术已经很难支撑起网络的持续发展[1].IPv6作为IPv4的换代技术,能够很好的解决目前IPv4网络中存在的诸如:IPv4资源耗尽、路由表规模庞大、安全性和服务质量不高等问题,但是至今仍然在科研等领域内小范围使用[2].虽然为了缓解IPv4地址即将耗尽的问题,提出了在IPv4技术的基础上引入CIDR(无类型域间路由选择)技术[3]使其地址前缀分配更加灵活[4],但是由于IPv4本身设计的缺陷,已经无法支撑起互联网的进一步发展,而IPv6是由IETF设计的用来取代IPv4的下一代IP协议,无论是在安全性方面还是服务质量方面都有很明显的改进.根据IETF发布的RFC2460可知,IPv6与IPv4最大的变化在于IPv6地址长度达到了128比特,这个改变一劳永逸的解决了IPv4地址空间耗尽的问题.但是IPv6较长的地址长度,增加了最长前缀匹配的难度和复杂度,虽然现有许多基于IPv4的快速路由查找算法,但是这些路由查找算法很难移植到IPv6中去,或者移植之后性能低下,实用性较低.因此需要设计一种适用于IPv6的路由查找算法,推动IPv6的普及.本文的主要内容是提出一种适合在IPv6网络中的高速路由查找算法.
2 相关算法及研究
最长地址前缀匹配问题,是路由查找算法中最需要解决的问题,也是目前研究最多的部分.最长地址前缀匹配算法研究方向大致分为基于Trie、基于哈希表、以及基于硬件这三种[5].其中基于Trie树的算法中,最经典的是二进制Trie树.在这种数据结构中,下一跳路由信息被保存在叶子节点或分支节点中,在进行路由查找过程中,根据前缀的每一比特是0还是1来决定左右分支.通过这种数据结构,进行IPv6的路由查找最坏情况下需要进行128次存储器访问,性能较低.随后又有学者在二进制Trie树上进行改进,提出压缩、多bit等改进算法[6-9].
在早期的Linux系统中,路由查找算法采用的是哈希表结构,Linux为每个地址前缀长度都维护了一张哈希表,在路由查找时,将目的IP地址从最长的前缀长度开始哈希,根据哈希结果选择下一跳路由信息.哈希表具有查询速度快的特点,在理想状况下只需要一次存储器访问,然而基于哈希的算法大多数扩展性较差,随着路由表表项的增加,哈希表的冲突问题会越来越严重,这将导致路由查找时间不可控的问题[10-12].
基于硬件的查找算法具有查找速度快、实现简单和可并行访问的特点[13],但是基于硬件成本高昂,单位比特的TCAM比较昂贵,存储容量有限[14].同时,由于是基于硬件的算法,因此可扩展性较差[15].
3 算法设计
本节将从算法思想与依据、相关数据结构、哈希函数设计与冲突处理和算法的实现四个方面,对算法进行详细的解释分析.
3.1 算法思想与依据
在研究了IPv6地址前缀分布规律和当前主流算法的基础上,对LFT进行改进[16].如图1所示,根据potaroo提供的核心路由器路由表数据可以得出,IPv6的地址前缀长度主要集中在[32,48]区间中,其中以前缀长度为48的表项最多,占全部表项的4成以上.其次为前缀长度为32的表项,占全部表项五分之一,其余前缀长度的路由表项数量较少,不存在前缀长度小于16的表项.同时根据RFC3587规定,128比特的IPv6地址中,只有前64位参与路由寻址,后64比特为接口地址,因此路由表中不存在前缀长度大于64的表项.
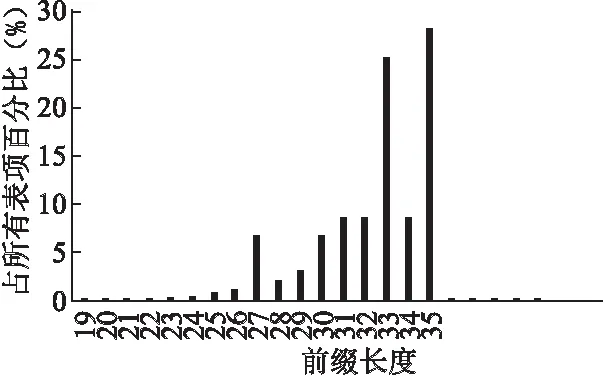
图1 核心路由器路由表IPv6地址前缀长度分布图Fig.1 IPv6 address prefix length distribution in core router
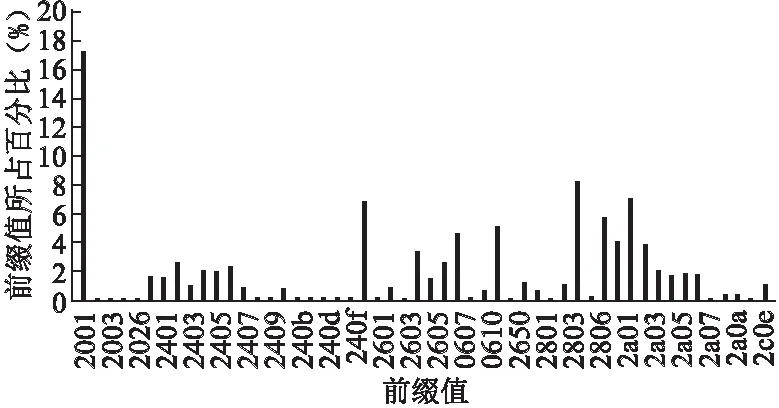
图2 前缀值所占百分比Fig.2 Percentage of prefix value
如图2所示,根据IPv6 网络的AS6939的核心路由器数据统计分析,核心路由器中路由表的表项大多以20、24、26、28和2a开头,以其他数值开头的表项很少或没有,且常用表项中,以2001开头的表项最多.
此外,IPv6经过十几年的发展逐渐走向成熟,其地址前缀长度的分布已趋向于稳定.如图3所示,根据potaroo对IPv6网络建网以来的统计,以地址前缀长度32和48为例,在IPv6网络成立初期,地址前缀长度为32的表项占路由表所有表项的65%,并且其数量一度领先于地址前缀长度为48的表项.从2009年开始,地址前缀长度为32的表项逐年下降,并慢慢稳定在了24%左右,而地址前缀长度为48的表项呈现平稳上升态势,并逐渐稳定在了45%左右.从2013年起,地址前缀长度为48的表项的数量,超越了地址前缀长度为32的表项,一直占据了大部分的路由表.
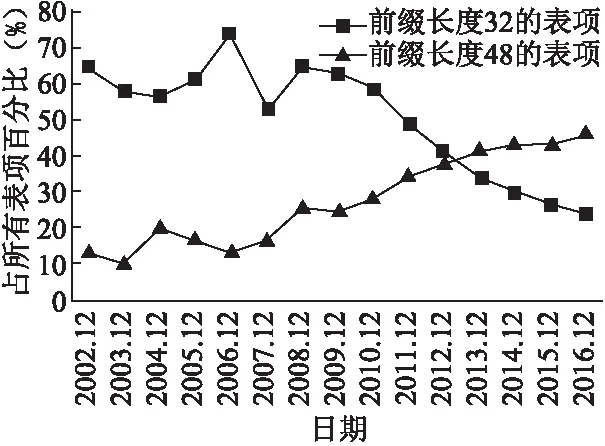
图3 32、48前缀长度表项数量历年趋势Fig.3 Trend of items in router table by prefix length (32 and 48)
根据上述IPv6地址前缀分布特点可知,在IPv6网络中,路由表中目前前缀长度为16倍数的路由表项最多,在这些表项中,前缀长度为48的表项最多,其次是前缀长度为32的表项.因此,如果算法在设计时考虑从48比特切入,优先查找48比特的表项,使路由查找操作在大部分情况下只需要访问一次存储器.同时与IPv4不同的是,IPv6的前缀值分布具有很明显的特点,即以20、24、26、28和2a开头的地址前缀占绝大部分.算法根据这个特性,将地址前缀值不以上述值开头的地址前缀直接用哈希表存储,由于这类地址很少,因此这类地址产生哈希冲突的概率较低.直接用哈希表存储,可以减少不必要的存储器访问次数,提升查找效率.算法将通过综合运用上述策略,提高IPv6网络中路由查找的效率.
3.2 相关数据结构设计
算法设计的数据结构包括哈希表和多比特树.
3.2.1 哈希表
算法共管理5种功能不同的哈希表,分别为HT、LFT0、LFT1、LFT2以及LFT3.其中HT用来存储地址前缀不以20、24、26、28和2a开头的地址前缀信息,而LFT0、LFT1、LFT2和LFT3用来存储以20、24、26、28和2a开头的地址前缀信息.

图4 HT结构Fig.4 Structure of HT
HT含有的表项数量有限,目前即使在核心路由器中也仅有数十项,因此HT的结构比较简单,其结构如图4所示.Prefix用来存储前缀信息,共64比特,NP为指针,占用16比特.考虑到HT表存储的信息比较少,发生哈希冲突的概率较低,因此当HT发生哈希冲突时,采用开放定址法来处理冲突.
LFT0存储前缀长度为48比特的前缀信息,并且存储前缀长度大于48且小于64的标志位信息.LFT1存储前缀长度为32比特的前缀信息,同时存储前缀长度大于32并小于48的标志位信息.LFT2存储前缀长度为16比特的前缀信息和前缀长度大于16且小于32的标志位信息,LFT3存储前缀长度为64比特的前缀信息,结构如图5所示.

图5 LFTx结构Fig.5 Structure of LFTx
LFT结构由5部分组成,分别为Prefix、cFlag、nFlag、NP和CP,其中Prefix用来存储地址前缀信息,在LFT0中占用48比特,在LFT1中占用32比特,在LFT2中占用16比特,LFT3中占用64比特,cFlag占用1比特为冲突标志位,nFlag占用1比特为是否有更长匹配项标志位,NP和CP为地址指针,各占16比特.根据标志位的不同,NP和CP的意义和指向也有所不同,如表1所示.

表1 标志位与指针关系Table 1 Relationship between flag and pointer
3.2.2 多比特树
除了哈希表外,算法还包括3棵6-5-4Trie.
6-5-4Trie属于多比特树,但与固定步宽的多比特树不同的是,6-5-4Trie的步宽不是不变的,因此相对于固定步宽的多比特树,6-5-4Trie能够更有效的利用存储空间.同时与可变步宽的多比特树不同的是,6-5-4Trie在每一层上是固定步宽的,因此在算法的实现上较为简单.
同时,6-5-4Trie是一颗最高高度为4的多比特树,其中第一层到第二层的步宽为6,第二层到第三层的步宽为5,第三层到第四层的步宽为4.根据IPv6地址前缀长度分布的特点可以知道,地址前缀长度主要集中在[32,48]的区间内,而在这个区间内,[33,38]、[39,43]和[43,47]这三个区间所包含的地址前缀项在数量上差不多,因此将步宽设为6、5和4能够使多比特树更加平衡易于优化.由于多比特树的特性,6-5-4Trie同样需要进行前缀扩展,分别需要将前缀长度不足6比特、大于6比特且小于12比特、大于12比特且小于16比特的前缀分别扩展至6比特、5比特和4比特.由于6-5-4Trie的高度最多只有4,因此在最坏的情况下,完成查找操作也只需要访问3次存储器,极大的提升了查找性能.
3.2.3 哈希函数设计与冲突处理
基于哈希表的路由查找算法的性能,主要由哈希函数的好坏决定.哈希函数的冲突是无法避免的,每一个性能优异的路由查找算法,离不开一个好的哈希函数,同时也离不开处理哈希冲突的策略.
根据IPv6地址前缀分析结果可知,LFT0与LFT1产生冲突的概率较高,LFT2和LFT3产生冲突的概率较低,因此针对不同的LFT,算法将采用不同的哈希函数和处理冲突的策略,如表2所示.

表2 哈希函数及冲突处理策略Table 2 Hash functions and conflict handling strategy
针对LFT0、LFT1、LFT2、LFT3、LFT0c和LFT1c,算法设计了H48、H32、H16、H64、H48c和H32c五个哈希函数.其中除了HT的哈希函数采用MD5以外,其余都采用XOR-Folding的方式来进行计算,各个哈希函数的具体设计如图6所示.
3.3 算法实现
算法流程如图7所示,查找过程分为哈希表查找阶段和6-5-4Trie查找阶段.由图可知,当nFlag=0,即存在更长匹配项时,需要进行6-5-4Trie查找.
3.3.1 哈希表查找
1)当IPv6数据包到达后,判断目的IP地址的前缀是否以20、24、26、28和2a开头,如果不是则经过Hash后与HT进行比对,匹配成功则按照NP指向的下一跳路由信息转发,若匹配失败则按照默认路由转发.
2)若目的IP地址以20、24、26、28和2a开头,则根据数据包中目的IP地址的前48比特进行哈希计算后与LFT0表进行比对,若匹配成功,且不存在冲突(cFlag=0)、不存在更长的匹配项(nFlag=0),此时数据包通过NP指向的下一跳路由信息进行转发,算法结束.若匹配成功且不存在冲突、但是存在更长的匹配项,此时NP指向T0进入下一阶段的查找.
3)当第二步中发现存在冲突(cFlag=1),匹配prefix与当前的地址前缀信息,若prefix和当前的地址前缀信息匹配成功,则此时仍然按照第二步中流程进行处理.如果prefix与当前的地址前缀信息不匹配,则进入LFT0c表查询,经过哈希后匹配,若匹配成功则转发,若匹配失败则进入LFT1.
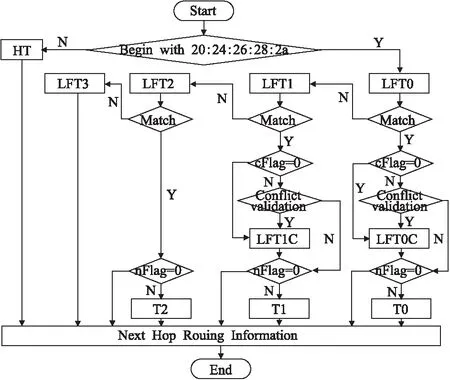
图7 算法流程图Fig.7 Flow chart of the algorithm
4)如果第二步中与LFT0匹配失败,则进入LFT1.根据数据包中目的IP地址的前32比特进行匹配后与LFT1进行比对,流程和第二步相似.
5)如果匹配到LFT3仍然失败,则按照默认路由转发数据包.
3.3.2 6-5-4Trie的查找
哈希表查找阶段中遇到有更长的匹配项时,则进入第二阶段:6-5-4Trie的查找阶段.
1)以T0为例,截取目的IP地址的第49到54比特与T0的第一层进行匹配,若匹配成功,且该叶子节点没有子节点,则根据叶子节点中的下一跳路由信息进行转发.
2)如果该叶子节点有叶子节点,则记录此时的下一跳路由信息NHP,将目的IP地址的第55到59比特进行匹配,若匹配成功则更新下一跳路由信息NHP,若匹配失败,则按照NHP转发.
3)如果第二步中匹配成功的节点仍然有叶子节点,则记录该叶子节点的下一跳路由信息NHP,将目的地址的第60到64比特进行匹配,若匹配成功则按照该节点的下一跳路由信息进行转发,若匹配失败,则按照NHP转发.
对于T1、T2,查找方法类似.
4 性能分析
从算法查找速度、路由表更新、转发表所需存储空间和哈希冲突解决等方面,对算法性能进行分析.
4.1 查找速度
算法将地址前缀长度为48比特、32比特、16比特和64比特的路由信息分别存储在LFT0、LFT1、LFT2和LFT3中,在哈希阶段查找过程中,分别需要访问存储器1次、2次、3次和4次.在最坏情况下,地址前缀信息在LFT2中未能匹配成功,此时算法需要进入6-5-4Trie进行第二阶段的查找,共需要访问存储器6次,因此算法查找的时间复杂度为O(6).如表3所示.根据IPv6地址前缀分布规律可知,针对当前的IPv6网络,70%的地址可以在算法的第一阶段内完成查找,其中45%的地址只需要访问1次存储器.

表3 前缀长度与访问存储器次数关系Table 3 Relationship between prefix length and number of memory access
4.2 路由表更新
IPv6正处于发展上升阶段,其路由表的更新频率较大,因此路由表的更新对路由查找算法性能的影响不可忽略.路由更新操作和查找过程类似,对于当前IPv6网络,大多数的更新操作只需要更新相应的LFT,对于地址前缀长度不是16倍数的地址前缀,除了需要更新对应的LFT,还需要更新对应的6-5-4Trie,最坏情况下需要访问存储器6次,因此路由更新复杂度为O(6).
4.3 转发表存储空间
算法的结构决定了算法所消耗的存储空间,算法包含哈希表和6-5-4Trie两种数据结构,对于哈希表结构中每一个表项所需要的存储空间如下:
LFT0:包含48比特 Prefix、1比特 cFlag、1比特 nFlag、16比特 NP和16比特 CP,共计82比特.
LFT1:包含32比特 Prefix、1比特 cFlag、1比特 nFlag、16比特 NP和16比特 CP,共计66比特.
LFT2:包含16比特 Prefix、1比特 cFlag、1比特 nFlag和16比特 NP,共计34比特.
LFT3:包含64比特 Prefix、1比特 cFlag、16比特 NP,共计81比特.
HT:包含64比特 Prefix和16比特 NP,共计80比特.
LFT0c:包含48比特 Prefix、1比特 nFlag和16比特 NP,共计65比特.
LFT1c:包含32比特 Prefix、1比特 nFlag和16比特 NP,共计49比特.
假如将AS6939中地址前缀长度为16的倍数的路由前缀信息加入哈希表,则共需要:
1*34bits+8349*66bits+29*49bits+15764*82bits+14*65bits+149*81bits=227KB.
对于6-5-4Trie结构来说,每个节点都包含指针和NHP,因此一颗满6-5-4Trie共需要:
(26*6bits)+(25*5bits+16bits)*26+(24*4bits+16bits)*25*26+16bits*24*25*26=854KB存储空间.在实际使用中,6-5-4Trie的节点都比较稀疏,因此可以采用压缩等手段来进一步降低存储空间的消耗.
4.4 哈希冲突
由图6可知,当LFT0和LFT1发生冲突时,LFT0c和LFT1c才会存在.AS6939是当前互联网中包含IPv6路由信息最多的自治系统,其包含前缀长度为16、32、48和64的路由前缀共计24306个.将这些地址前缀信息经过哈希函数处理后,LFT0c和LFT1c共含有43个表项,即将24306个表项存入LFT时,共计发生冲突43次,针对这43个表项,除了在哈希查找阶段需要访问LFT表以外,还需要访问一次相应的用来解决冲突的表.发生冲突的概率为0.17%,所以哈希函数性能优异.
5 实验仿真
本文收集了含有IPv6路由信息的AS174、AS3356和AS6939三个自治系统中路由表进行了统计,表4给出了它们的前缀长度分布情况.
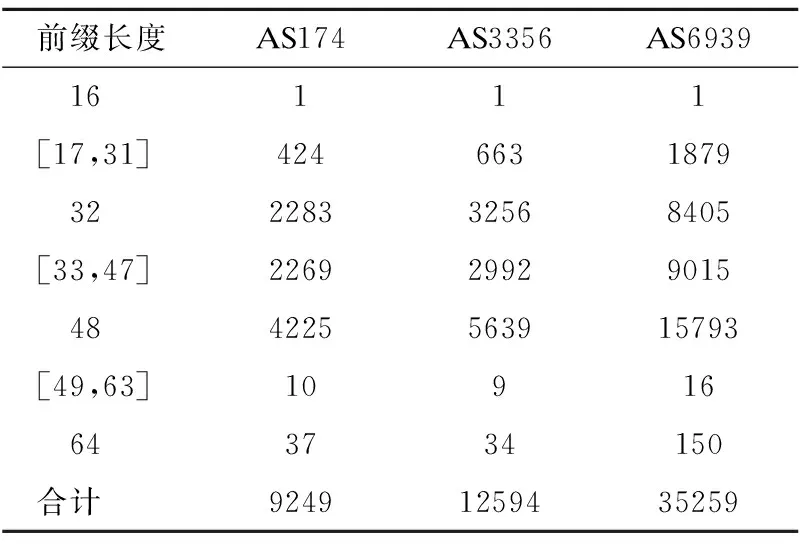
表4 地址前缀长度分布Table 4 Prefix length distribution
为了说明算法的效率,同时避免由于计算机性能差异、程序之间相互影响等因素而导致的误差,依据表4 的数据,对算法的哈希函数、查找速度、存储空间三个方面进行实验仿真,算法均采用Python实现.
5.1 哈希函数性能
首先是对提出的哈希函数进行测试,将AS6939、AS174和A3356分别建立数据结构,实验结果如表5所示.
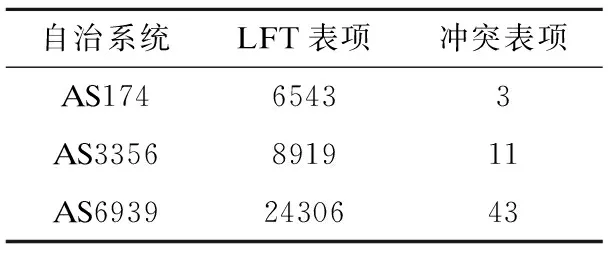
表5 哈希冲突次数Table 5 Number of hash collisions
通过实验仿真结果可以知道,哈希冲突的概率都在0.2%以内,结合提出的哈希冲突处理策略,LFT能够有效的存储地址前缀信息.
5.2 查找性能
在查找性能测试上,实验结果以算法对存储器的读取次数进行统计,实验结果如图8所示.
AS174、AS3356和AS6939虽然来自不同的自治系统,但是它们有着相似的地址前缀分布规律.相比Compressed Trie,本算法具有较大的优势.与同样采用了哈希表和Trie结构的文献[16]中的算法相比[16],本算法拥有更好的查找效率.

图8 查找性能实验结果Fig.8 Results of lookup speed
5.3 存储空间
在存储空间上,实验结果如图9所示.
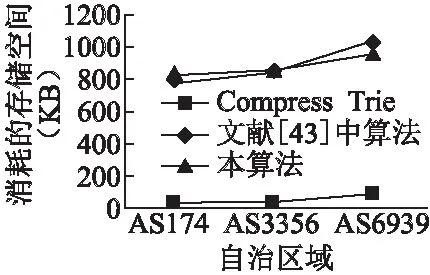
图9 存储空间实验结果Fig.9 Results of storage space
文献[16]中的算法为地址前缀长度为32的表项进行优化,使其为前缀长度为32的表项节省更多的存储空间,而本算法根据地址前缀长度为48的表项进行优化,使其为前缀长度为48的表项节省更多的存储空间.由IPv6地址前缀分布规律可知,随着IPv6网络逐渐成熟,地址前缀长度为48的表项的数量,将在路由表中长期处于领先地位,因此随着路由表项的增多,本算法在存储空间的消耗上将比文献[16]中的算法更少.
此外,算法使用多比特树降低树的高度,同时由于地址前缀长度扩展机制的存在,从而产生了大量的节点,因此在表项较少的情况下,其消耗的空间要比文献[16]中算法消耗的多,随着路由表项的增多,本算法中产生的这些节点,逐渐变为存有地址前缀信息和下一跳路由信息的节点,此时算法对存储空间的消耗是几乎不变的.因此,由图9可知,随着路由表项的增大,本算法在存储空间上的优势越来越明显.此外,由于6-5-4Trie比较稀疏,因此在存储空间的消耗上仍有优化空间.
从上述实验仿真结果来看,算法在哈希函数冲突避免、查找性能上和存储空间上都有优势,各项性能指标良好.
6 结 论
算法将哈希表与多比特树,分阶段进行结合,并在设计时充分将IPv6地址前缀长度的分布特点考虑在内,首先将极少使用的地址前缀和常用的地址前缀分开存储,其次针对常用的地址前缀,算法将前缀长度为48的表项优先匹配.算法在大多数情况下,只需要进行一次存储器访问,就可以查找到下一跳路由信息,即使在最坏情况下也只需要访问6次存储器.同时算法的更新复杂度与查找复杂度同为O(6),能够适应当前IPv6路由更新频繁的情况.算法消耗的存储空间较少,结合算法结构简单的特点,易于用硬件实现.
:
[1] Tang Hui,Lin Tao,Fan Dian,et al.Conducting pst IP rsearch,dveloping iternet′s nxt gneration [J].Bulletin of Chinese Academy of Sciences,2010,25(1):55-63.
[2] Zhang Ze-xin,Li Jun,Chang Xiang-qing.Longitudinal study on evolution of Internet traffic[J].Application Research of Computers,2015,32(11):3215-3221.
[3] Wang Rui-qing,Du Hui-min,Wang Ya-gang.IPv6 routing lookup algorithm based on hash and CAM[J].Computer Engineering,2012,38(8):50-53.
[4] Tang Ming-dong,Zhang Guo-qing,Yang Jing,et al.Scalable routing for the Internet [J].Journal of Software,2010,21(10):2524-2541.
[5] Xu Ke,Xu Ming-wei,Wu Jian-ping,et al.Survey on routing lookup algorithms[J].Journal of Software,2002,13(1):42-50.
[6] Bando M,Lin Y L,Chao H J.Flash trie:beyond 100-Gb/s IP route lookup using hash-based prefix-compressed trie[J].IEEE/ACM Transactions on Networking,2012,20(4):1262-1275.
[7] Lin C H,Hsu C Y,Hsieh S Y.A multi-index hybrid trie for lookup and updates[J].IEEE Transactions on Parallel & Distributed Systems,2014,25(10):2486-2498.
[8] Pao D,Lu Z,Poon Y H.IP address lookup using bit-shuffled trie[J].Computer Communications,2014,47(2):51-64.
[9] Huang Sheng,Zhang Wei,Wu Chuan-chuan,et al.IP address lookup algorithm based on multi-bit priority tries tree [J].Journal of Computer Applications,2014,34(3):615-618.
[10] Hsiao Y M,Chu Y S,Lee J F,et al.A high-throughput and high-capacity IPv6 routing lookup system[J].Computer Networks,2013,57(3):782-794.
[11] Xu Pan,Liu Sheng-li,Lan Jing-hong,et al.An improved segment hash algorithm[J].Computer Engineering,2015,41(1):266-269.
[12] Li Yuan,Ruan Jun-zhou.Research on router lookup algorithm based on hash and radix tree [J].Computer & Network,2015,41(11):42-44.
[13] Eatherton W,Varghese G,Dittia Z.Tree bitmap:hardware/software IP lookups with incremental updates[J].Acm Sigcomm Computer Communication Review,2015,34(2):97-122.
[14] Sun Y,Egi N,Shi G,et al.Content-based route lookup using CAMs[C].Global Communications Conference,2012:2677-2682.
[15] Meiners C R,Patel J,Norige E,et al.Fast regular expression matching using small TCAM[J].IEEE/ACM Transactions on Networking,2014,22(1):94-109.
[16] Gao Ying,Wang He-ming,Chen Qiang.IPv6 routing lookup algorithm based on hierarchical Hash[J].Computer Engineering and Design,2010,31(22):4790-4793.
附中文参考文献:
[1] 唐 晖,林 涛,范 典,等.开展后IP技术研究发展互联网下一代[J].中国科学院院刊,2010,25(1):55-63.
[2] 张泽鑫,李 俊,常向青.互联网流量的演化研究[J].计算机应用研究,2015,32(11):3215-3221.
[3] 王瑞青,杜慧敏,王亚刚.基于Hash和CAM的IPv6路由查找算法[J].计算机工程,2012,38(8):50-53.
[4] 唐明董,张国清,杨 景,等.互联网可扩展路由[J].软件学报,2010,21(10):2524-2541.
[5] 徐 恪,徐明伟,吴建平,等.路由查找算法研究综述[J].软件学报,2002,13(1):42-50.
[9] 黄 胜,张 卫,吴川川,等.基于多分支优先级树的IP路由查找算法[J].计算机应用,2014,34(3):615-618.
[11] 胥 攀,刘胜利,兰景宏,等.一种改进的分段哈希算法[J].计算机工程,2015,41(1):266-269.
[12] 李 渊,阮军洲.基于Hash和Radix树的路由查找算法研究[J].计算机与网络,2015,41(11):42-44.
[16] 高 莹,王贺明,陈 强.采用分段哈希方法的IPv6路由查找算法研究[J].计算机工程与设计,2010,31(22):4790-4793.
猜你喜欢
智能计算机与应用(2021年6期)2021-12-17
大数据(2021年6期)2021-11-22
电脑爱好者(2021年8期)2021-04-21
综艺报(2020年21期)2020-11-30
电脑爱好者(2020年20期)2020-10-22
计算机与网络(2020年9期)2020-07-29
网络安全和信息化(2019年11期)2019-11-25
电脑爱好者(2019年17期)2019-10-30
传播力研究(2019年24期)2019-10-21
科技与创新(2018年1期)2018-12-23
