
一种基于最大公共子图的文本谱聚类算法
2018-07-13 15:43冯仁群山陈笑蓉
贵州大学学报(自然科学版) 2018年2期
冯仁群山 陈笑蓉


摘 要:传统的基于空间向量的文本谱聚类方法容易忽略文本上下文之间的语义联系,通过图结构进行文本表示可以很好的解决这一问题,在此基础上,本文提出了基于最大公共子图的谱聚类算法——SC-MCS算法。该算法通过求解文本之间的最大公共子图来进行文本相似度的计算,最后进行文本聚类。实验结果表明,与传统的基于空间向量的文本谱聚类方法相比,该算法在准确率和召回率都取得了一定的提升。
关键词:文本聚类;谱聚类;最大公共子图
中图分类号:TP391.1
文献标识码: A
随着互联网的飞速发展,人们访问和获取的信息呈几何级数急剧增长,如何有效地对海量文本信息进行聚类一直是文本挖掘领域的一个研究热点。大多数传统的聚类算法都是基于凸样本空间,当样本空间不凸时,算法容易陷入局部最优。为了对任意形状的样本空间都能够进行聚类并收敛到全局最优解,学者们提出了一种新的聚类算法——谱聚类算法 [1]。首先,根据给定的样本数据集定义一个相似矩阵来描述数据点之间的相似性,然后计算矩阵的特征值和特征向量,最后针对不同的数据点选取合适的特征向量来完成聚类。谱聚类算法已成功地应用于语音识别、图像和视频分割、文本聚类等领域。
谱聚类算法是一种基于图论的聚类算法,其本质是将聚类问题转化为图的最优切分问题,在文本聚类方面具有很好的应用前景。传统的谱聚类算法是基于向量空间模型(Vector Space Model)來进行相似矩阵的构造,VSM模型通过向量空间进行文本表示,进而将文本转换为向量形式,并在向量空间中计算文本相似度[2]。虽然该模型具有简单高效、处理方便的优点,然而该模型也存在一些不足之处:一是特征维度较高,冗余信息和稀疏数据较多;二是特征项相互独立,无法体现特征项在文本中出现的顺序、特征项之间的关联等文本结构信息。针对基于VSM的文本聚类存在的问题,Adam Schenker等人提出用图结构来进行文本的表示,该模型利用图结构中的边来体现文本中上下文之间的潜在关系[3]。在此基础之上,本文提出了一种基于最大公共子图的谱聚类算法(Spectral Clustering algorithm based on Maximum Common Subgraph)简称SC-MCS算法,同时设计了实验,将SC-MCS算法与基于VSM的谱聚类算法进行对比,并且对不同文本长度的聚类环境进行了探究,结果表明SC-MCS算法相比与传统基于向量空间的文本聚类算法在准确率、召回率有一定提升。
1 谱聚类基本理论
1.1 图划分准则
谱聚类算法最初源于图划分理论,通过将每个数据样本映射为图中的顶点V,样本之间的相似度映射为顶点间的边E的权重值W,这样就得到了一个基于样本相似度的无向加权图G=(V,E,W)。进而在图G中,就可以将传统的聚类问题转化为在图G上的图划分问题。同时定义图划分准则,通过最优化图划分准则,使得同一类内的点相似性较高,而不同类之间的点相似性较低。划分准则的优劣将对聚类结果产生直接影响,主要的划分准则有最小切分准则、规范化切分准则以及多路规范化切分准则等[4]。
在图划分理论中,定义将图G划分为A,B两个子图的代价函数:
1.2 相似矩阵及拉普拉斯矩阵
传统方法求解图划分准则的最优解是一个NP难问题,进而考虑问题的连续放松形式——求图的拉普拉斯矩阵的谱分解问题,可以认为谱聚类是对图划分准则的一种逼近。
在谱聚类算法中,相似矩阵A的定义:
拉普拉斯(Laplacian)矩阵分为非规范拉普拉斯矩阵和规范拉普拉斯矩阵。非规范拉普拉斯矩阵表示为L =D -A, 规范拉普拉斯矩阵有两种形式, 分别是
根据不同的划分准则及相似矩阵的构造方法,谱聚类有不同的具体实现方法,其主要的过程:
构建样本集的相似矩阵A;
构造拉普拉斯矩阵L;
计算L的特征值与特征向量,构成特征向量空间;
对特征向量采用k-means或其他经典聚类算法进行聚类。
2 SC-MCS算法
传统的文本谱聚类算法在构造相似矩阵时,不能充分体现文本上下文之间的潜在关系,针对这一问题,本文提出了一种基于最大公共子图的谱聚类(SC-MCS)算法。SC-MCS算法采用图结构来表示文本,通过计算文本图结构之间的最大公共子图来体现文本之间的相似性,进而构造出基于最大公共子图的相似矩阵。SC-MCS算法的具体过程如图1所示。
图2是单个文本图结构构建的示意图。
图结构中的节点反映了文本的特征项信息,边体现了特征项的共现信息及语序信息,边的权重反映了特征项之间语义关联程度。
2.2 最大公共子图求解
基于最大公共子图的文本相似度计算的理论依据是:如果两个图结构越相似,那么它们的公共部分就越多,即存在一个公共子图,因此可以用它们的最大公共子图来度量两个图结构的相似程度。先给出最大公共子图的相关定义[8]。
两个图结构G1和G2的最大公共子图,就是以G1和G2全部共有的节点作为自己的节点,全部共有的边作为自己的边,取共有边上较小的权值作为自己边的权值所构成的图,即图结构G1和G2的最大重叠部分。两个图结构重叠的部分越多,则它们就越相似。因此可以用最大公共子图mcs(G1,G2)对两个图结构的相似度进行度量。最大公共子图生成的示意图如图3所示。
已知两个图结构G1和G2,它们之间存在最大公共子图g,则g的求解过程分以下两个步骤进行:
遍历图结构G1和G2的节点,对节点进行比较,取图结构G1和G2的公共节点作为g的节点;
取g的节点集合中任意两个节点,如果这两个节点在图结构G1和G2中都是邻接的,则产生一体边作为图结构g的边。
2.3 文本相似度计算
利用文本的最大公共子图来进行文本的相似度计算,最大公共子图充分包含了文本之间的相似信息,可以根据其在文本图结构中所占的比例大小来完成相似度估计,具体相似度计算公式:
公式前半部分是对图结构G1和G2中节点的相似度的度量,G1和G2最大公共子图的节点数越多,且与G1,G2自身的节点数越接近,则G1,G2节点的相似度就越大,取值越接近于1;后半部分是对图结构G1,G2的边及权重的度量,G1,G2相同边的权重越接近,即min(wij,wi′j′)/max(wij,wi′j′)的值越接近于1。将所有相同边的个数求和便得到最大公共子图边的个数,其与G1,G2边的个数比值体现了G1,G2边的相似度。二者的线性组合代表了用图结构表示的两个文本间的相似程度。
2.4 文本聚类过程
文本聚类实验可以进一步地检验基于最大公共子图的文本相似度的实际效果。文本聚类是将一个文档集合分成若干聚类簇的过程,每个聚类簇的成员之间拥有较大的相似性,而不同聚类簇之间的成员则具有较低的相似性。对于给定的文本集合D={d1,d2,…,dn},聚类算法将每对文本(di,dj)之间的文本相似度作为输入,通过特定聚类算法进行处理,最后将聚类结果输出。
本文采用谱聚类算法进行文本聚类处理,相比于其他传统聚类方法,谱聚类具有明显的优势,它能够对非凸分布的样本空间进行聚类,在实际问题的处理中取得了较好的效果,而且执行起来比较容易。算法实现过程:
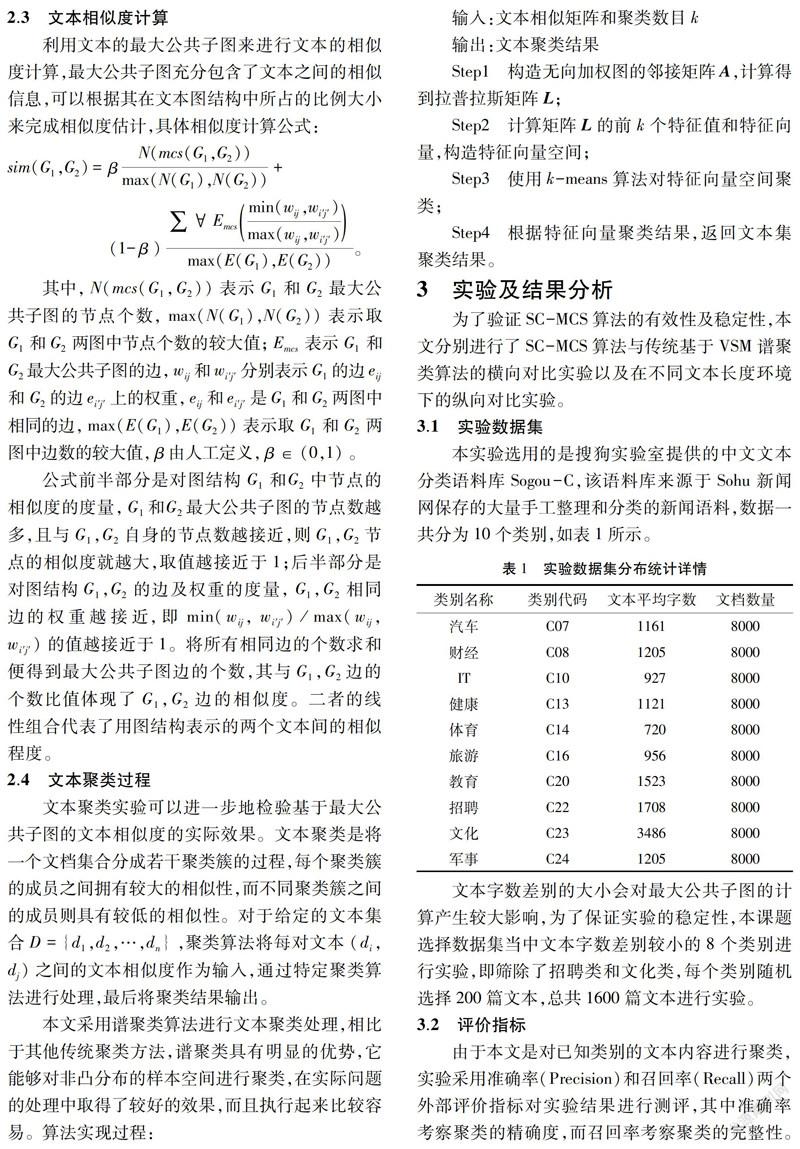
输入:文本相似矩阵和聚类数目k
输出:文本聚类结果
Step1 构造无向加权图的邻接矩阵A,计算得到拉普拉斯矩阵L;
Step2 计算矩阵L的前k个特征值和特征向量,构造特征向量空间;
Step3 使用k-means算法对特征向量空间聚类;
Step4 根据特征向量聚类结果,返回文本集聚类结果。
3 实验及结果分析
为了验证SC-MCS算法的有效性及稳定性,本文分别进行了SC-MCS算法与传统基于VSM谱聚类算法的横向对比实验以及在不同文本长度环境下的纵向对比实验。
3.1 实验数据集
本实验选用的是搜狗实验室提供的中文文本分类语料库Sogou-C,该语料库来源于Sohu新闻网保存的大量手工整理和分类的新闻语料,数据一共分为10个类别,如表1所示。
文本字数差别的大小会对最大公共子图的计算产生较大影响,为了保证实验的稳定性,本课题选择数据集当中文本字数差别较小的8个类别进行实验,即筛除了招聘类和文化类,每个类别随机选择200篇文本,总共1600篇文本进行实验。
3.2 评价指标
由于本文是对已知类别的文本内容进行聚类,实验采用准确率(Precision)和召回率(Recall)两个外部评价指标对实验结果进行测评,其中准确率考察聚类的精确度,而召回率考察聚类的完整性。
3.3 实验结果
为了验证文本提出基于最大公共子图的谱聚类算法(SC-MCS)的有效性,本文與传统的基于空间向量的谱聚类算法(VSM)进行了对比实验,表2是两种聚类算法的实验结果对比。
从表2可以看出,相对于传统的VSM算法,SC-MCS算法在准确率和召回率两方面均有一定的提升,实验结果验证了本文所提出的SC-MCS算法的有效性,体现出了基于图结构的文本表示更好的效果。能够出现这样的结果,主要是因为SC-MCS聚类算法利用图结构考虑到了文本上下文之间的语义关系,而VSM聚类算法则是将不同特征词作为相互独立的向量来处理的,忽略了它们之间潜在的语义内涵,所以SC-MCS聚类算法能够在同样的测试样本下取得更好的实验效果。
同时,为了验证算法的稳定性,本文采取了不同长度的文本进行了纵向的对比实验,来观测随着文本长度的改变算法的效果会发生如何变化,图4是不同文本长度下算法平均准确率和平均召回率的对比。
从上图可以看出,随着文本长度的增加,算法的平均准确率和召回率起初有一定幅度的增长,而随着文本长度的持续增加,算法的平均准确率和召回率出现了大幅度的降低,造成这种结果的主要原因在于:当文本长度过长时,文本之间的最大公共子图很难准确获取,进而导致无法体现文本之间的相似性。因此,我们可以针对不同聚类环境来选取合适文本长度,以确保基于最大公共子图的文本聚类算法可以取得较好的效果。
4 结语
本文提出了一种基于最大公共子图的文本聚类算法,利用文本的图结构表示来反映不同特征词之间的语义内涵,同时通过计算文本间的最大公共子图来表示文本相似度,相比于传统的基于空间向量的聚类算法取得了较好的聚类效果。
同时,本方法还存在待改进的地方。文本的共现单元选取长度可以考虑进行适当的增加,但这也会为最大公共子图的计算带来一定困难。下一步工作可以考虑引入特征扩展的方法来对算法进行改进。
参考文献:
[1]VONLUXBURG U. A tutorial on spectral clustering[J]. Statistics and computing, 2007, 17(4): 395-416.
[2]SALTON G, WONG A, YANG C S. A vector space model for automatic indexing[J]. Communications of the Acm, 1975, 18(11):613-620.
[3]SCHENKER A, LAST M, BUNKE H, et al. Comparison of distance measures for graph-based clustering of documents[C]// Iapr International Conference on Graph Based Representations in Pattern Recognition. York, UK: Springer-Verlag, 2003:202-213.
[4]BUNKE H, FOGGIA P, GUIDOBALDI C, et al. A Comparison of Algorithms for Maximum Common Subgraph on Randomly Connected Graphs[C]// Joint Iapr International Workshop on Structural, Syntactic, and Statistical Pattern Recognition. Italy: Springer-Verlag, 2002:123-132.
[5]SHI J, MALIK J. Normalized Cuts and ImageSegmentation[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2000, 22(8):888-905.
[6]蔡晓妍,戴冠中,杨黎斌. 谱聚类算法综述[J]. 计算机科学, 2008, 35(7):14-18.
[7]周昭涛,卜东波, 程学旗. 文本的图表示初探[J]. 中文信息学报, 2005, 19(2):36-43.
[8]刘巧凤. 基于图结构的中文文本聚类方法研究[D]. 大连:大连理工大学, 2009.
(责任编辑:周晓南)
