
基于足球比赛事件检测的视频分析方法*
2018-07-18 06:47罗安平
沈阳工业大学学报 2018年4期
刘 阳, 罗安平
(沈阳工业大学 信息科学与工程学院, 沈阳 110870)
视频分析方法的研究作为视频语义领域的一个重要分支在学术和商用两个方面得到了广泛关注.不仅因为其拥有巨大的商业价值,也因为其涉及到信号处理、人工智能、计算机视觉、模式识别、人机交互及数据库等诸多学科领域,具有重要的理论意义.视频分析实际上就是通过提取特定的特征来检测目标事件,并以检测出的目标事件为基础进行分析得到用户需要的信息[1].
事件检测就是将用户感兴趣的视频段从一个完整的、拥有大量信息的视频中提取出来[2].最开始的事件检测方法是通过人工来进行目标事件的检测和提取,也就是专业人士根据自己的工作经验利用纯手工的方式,将目标事件从完整的视频中检测和提取出来.但是当今社会是一个信息爆炸的社会,视频数据每天都在高速地增长着,这种方式非常耗费人力资源,同时可靠性很差,容易出错,所以如何对视频中的目标事件进行快速且准确的自动检测成为了本文研究的重点.
1 事件检测过程
本文以足球比赛视频中的进球事件为例,介绍了一种机器学习和人工规则相结合的事件检测方法,其流程图如图1所示,具体步骤如下:
1) 将训练样本视频段和完整的足球比赛视频进行镜头分割,得到训练样本镜头序列和比赛视频镜头序列;
2) 结合人工规则和传统经典算法对分割好的镜头进行语义标注;
3) 通过特殊镜头定位将疑似目标事件的语义镜头序列提取出来,本文以进球事件为例,通过检测球门镜头初步提取疑似进球事件的语义镜头序列;
4) 利用训练样本镜头序列计算隐马尔科夫模型的初始参数,建立进球事件的隐马尔科夫模型;
5) 通过前向算法计算训练样本镜头序列的概率,用来确定判断的阈值;
6) 计算该模型下产生这些语义镜头序列的概率,并根据判断阈值检测出测试数据中的进球事件.

图1 事件检测流程图Fig.1 Flow chart of event detection
2 镜头分割与语义标注
视频是由连续图像帧构成的,而当一系列保持较高相似性和连续性的帧组合在一起就形成了镜头,因此,足球视频可以看作是由一系列语义镜头组成的.而事件则是一系列按照一定规律排列的语义镜头序列.
若要得到语义镜头,首先需要将视频进行镜头分割并提取关键帧,再通过对关键帧的处理得到特征值[3],从而对镜头进行语义标注.本文选取了Twin Comparison算法进行镜头分割,该算法是一个能够识别突变和渐变的双阈值算法.算法考虑了渐变过程中帧与帧之间的累积差异,并进行了两次视频扫描,一次使用较高的阈值来检测突变,另一次使用较低的阈值来检测潜在的渐变.镜头分割完成后就可以按一定规律进行关键帧提取,需要注意的是:关键帧必须是能够反映镜头内容的[4],文中将镜头的中间帧作为关键帧.
本文通过提取特征值并结合决策树来对镜头进行分类和语义标注.在决策树的第一层首先区分的是重放镜头和非重放镜头,提取重放镜头的步骤如下:
1) 利用Logo镜头帧间差的特征提取可能的Logo.
2) 利用这些提取的Logo生成一个相对标准的模板.
3) 利用Logo模板将所有的Logo检测出来.
4) 按顺序两个Logo镜头之间的镜头就是重放镜头.决策树的第2层则是通过颜色直方图来判断场地面积,以此将非重放镜头分为场内镜头和场外镜头;第3层通过计算人脸比例提取场内镜头中的特写镜头;第4层通过计算场地和球员面积比例将剩下的场内镜头分为远镜头和中镜头.决策树流程图如图2所示.
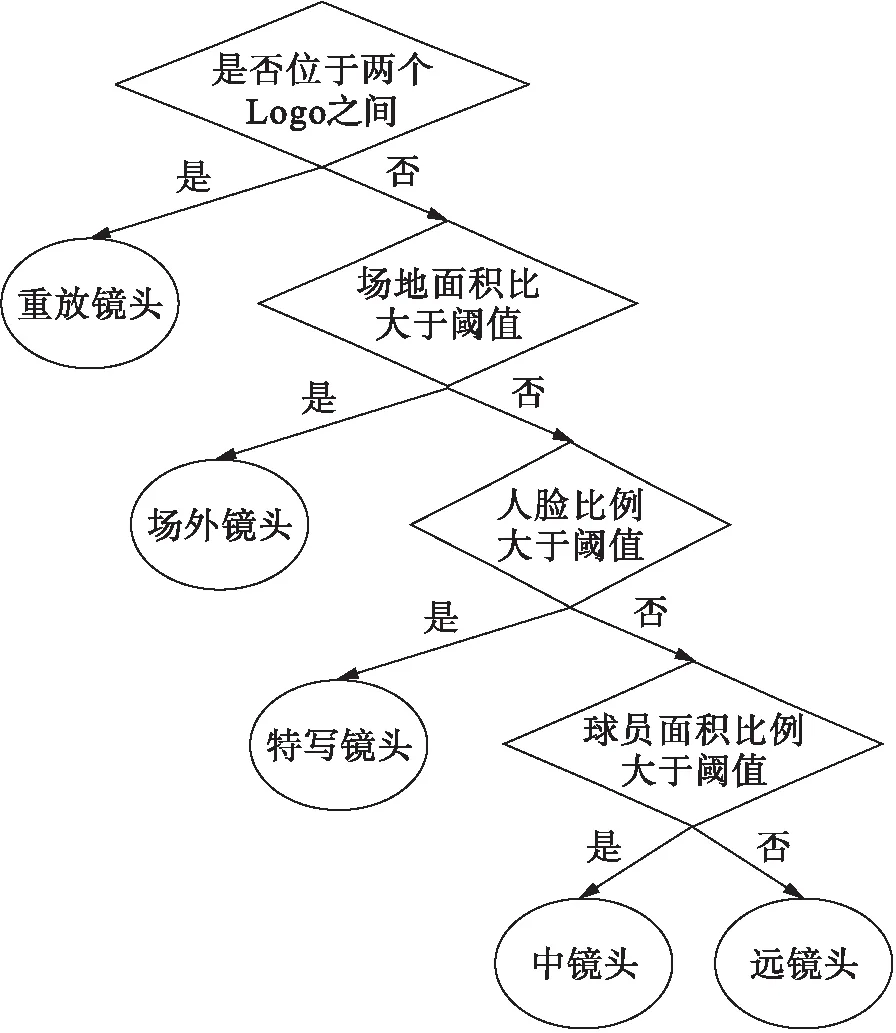
图2 决策树流程图Fig.2 Flow chart of decision tree
3 基于球门检测的进球事件定位
从一个完整的足球比赛视频中检测出进球事件,首先需要从比赛视频中提取可能的语义镜头序列.当发生进球事件时,最先出现的一定是禁区附近的区域,这通常包含了清晰的球门远镜头或中镜头,进球完成后,通常会出现运动员、教练员或者裁判员的一些特写镜头,最后会出现进球的重放镜头,因此,提取可能为进球事件的语义镜头序列步骤如下:
1) 从分割好的镜头中提取关键帧.
2) 对关键帧图像进行robert算子提取边缘检测(检测结果如图3所示).

图3 边缘检测Fig.3 Edge detection
3) 利用霍夫变换平行线检测将两条相邻的平行线合并为一条直线(霍夫变换检测结果如图4所示).

图4 霍夫变换检测结果Fig.4 Detection result of Hough transform
4) 在步骤3)得到的线段中选取两根竖直最长的线段作为候选球门柱.
5) 利用启发规则判断步骤4)中的候选门柱是否为球门,启发规则如下:
① 判断两根球门柱的长度,如果都不在一个范围内则不是球门,这个范围由图片的分辨率决定,如本文的范围是15~200个像素;
② 判断两根球门柱之间的距离,如果不在一定范围内则不是球门,本文的范围是20~260个像素;
③ 判断两根球门柱之间的长度差,如果不在一定范围内则不是球门,本文的范围是0~20个像素;
④ 判断两根球门柱之间的距离和最长球门柱之间的比值,若不在0.5~3.5的范围内则不是球门;
⑤ 两个球门柱构成的最小矩形的中心位置应处在一定的区域内,其中心点的纵坐标应在一定范围内,如果不符合则认为不是球门,本文的范围是20~340个像素.
6) 找到包含球门的镜头后,以该语义镜头为开始,在语义镜头序列中寻找重放镜头.根据实际情况确定寻找的最大长度,如本文寻找长度为10,即如果开始镜头与重放镜头之间超过10个镜头,则继续寻找下一个包含球门的镜头;反之,该镜头序列为候选进球事件序列.
图5则是通过上述方法提取的可能为进球事件的语义镜头序列关键帧.在取得可能的进球事件语义镜头序列后,则需要采用隐马尔科夫模型(hidden Markov models,HMM)来做进一步的判断.

图5 疑似进球事件序列Fig.5 Suspected scoring event sequence
4 基于HMM进球事件检测
HMM可以被看作是一个关于进球事件的语义镜头序列模型,这个序列可以通过“随机行走”产生[5],即从初始位置W0出发,通过状态转移矩阵A选择一个可能的状态θ1,并到达W1.如果W1的状态为θ1,则根据观察值状态矩阵选择一个该状态下可能的语义镜头O1,然后再根据状态矩阵转移到下一个状态.通过模型中的状态(θ1,θ2,…,θN)产生一系列的语义镜头(O1,O2,…,ON),则状态序列产生的语义镜头序列的概率便是评判该序列是否为进球事件语义镜头序列的标准.而语义镜头序列概率需要使用向前算法来计算[6],其定义为
γm(i)=P(O1,O2,…,Om,qm=θi|λ)
(1)
式中:m为镜头序列的镜头数;qm为第m个镜头的状态;λ为模型状态.因此一个语义镜头序列的概率为
(2)
对于与模型相符合的序列,HMM能以较大的概率产生序列;与模型不符合的序列,则产生序列的概率会较小[7].实践中一般采用Baum-Welch算法使模型产生更合适的事件语义镜头序列,但该算法易收敛于局部最优,本文设计了一种遗传算法来训练HMM,从训练样本中自动获得模型参数.
5 基于Baum-Welch算法的HMM
Baum-Welch算法[8]描述为:给定训练序列语义镜头O和模型状态λ,定义ξt(i,j)为马尔可夫链在t时刻处于状态θi,t+1时刻处于状态θj的概率[9-10],即
(3)
式中:αt(i)和βt+1(j)分别为t、t+1时刻处于状态θi条件下产生序列O的概率;aij为状态转移矩阵中的对应元素;bj(Ot+1)为观测符号矩阵中的对应元素.则t时刻马尔可夫链处于状态θi的概率为
(4)

(5)

6 结合遗传算法的HMM
遗传算法是模拟自然界优胜劣汰的进化现象,把搜索空间映射为遗传空间,将可能的解编码成一个染色体,并不断用适应度函数去计算每条染色体的适应值,从中选取最优解.
在HMM的参数π、a和b中,b的选取最为重要,因为π为初始状态量,对模型影响并不是很大,而a为状态转移量,由于本文应用的HMM中状态仅有三个,且应用了从左向右的诺尔马夫链,所以a的选取对模型影响也不是十分明显.只要通过遗传算法训练出最优的初值b就可以明显提高HMM的模型性能,使其能够在尽量少的训练样本下得到性能最优的模型.
6.1 编码方案
初值b中每个元素的取值范围为[0,1],为了保证精度,本文选取长度为64的二进制数来表示该参数,它能产生264种不同的编码.

6.2 适应度函数
适应度函数为判断每条染色体优劣的函数,训练模型为了能更好地描述代表进球事件的语义镜头序列,定义染色体优劣的评判标准为:在该模型下一个代表进球事件的语义镜头序列概率越大越好.适应度用各组训练样本的对数似然函数来表示,即
f(λ)=ln(P(Ok|λ))
(6)
6.3 遗传算子选择
本文采用了基于适应值比例的赌轮盘选择方法,这种方法可以想象成向划分好扇区的轮盘里扔色子,事先生成一组满足均匀分布的随机数,代表n次掷色子或者n个色子一起扔,轮盘不动,色子所在区域为选择结果,也就是要选择的染色体.
6.4 终止准则
常用的终止准则是预先设置最大进化的代数或预先设置一个适应度改善的阈值.对于前一种准则,在进化代数到达预置值时进化终止;而后一种准则是在适应度改善低于该阈值时进化停止.本文采用了两种准则相结合的方法,同时设置阈值和最大进化代数,在达到最大迭代数之前如果达到阈值,则进化结束.
6.5 训练算法
首先通过对训练样本的观察和统计得到几组初始参数,然后将这几组参数中的b进行编码,形成种群,通过适应度函数计算种群中所有染色体的适应度,并利用赌轮盘方法选择染色体,对选择出的染色体进行交叉和变异操作,将形成的子代代替父代放入种群中,重复以上操作直到达到终止准则为止.
7 实验与结论
实验视频选自2016年英超联赛多个场次的比赛.实验视频分为两部分,一部分作为训练视频片段,分为4组,分别包含10、20、30、50个进球视频片段;另一部分作为测试视频片段,含有30个进球视频片段和20个非进球视频片段.实验通过对测试样本的识别准确率来判断模型的性能.
识别率的比较结果如表1所示,由表1中可以看出,在训练样本增加的时候,本文所提算法的识别率增加速度要远高于Baum-Welch算法,因此可以得出,改进算法能够有效避免局部最优解.

表1 识别率比较Tab.1 Comparison in recognition rate
本文还做了适应性测试以证明本方法的有效性.选取了欧冠和西甲等各个联赛的完整视频作为测试数据进行进球事件的检测,适应性测试结果如表2所示.由表2可见,本文提出的事件检测方法能够比较准确地实现足球视频中进球事件的检测.

表2 适应性测试Tab.2 Adaptability test
综上所述,本文所提出的基于人工规则和机器学习相结合的事件检测算法可以有效地在不影响准确率的情况下节约时间成本,提高了HMM训练算法在训练样本相对较少情况下的查全率和查准率.本算法流程还存在不足之处,如机器学习算法有待改进.寻求更加详细和全面的镜头语义标注方法,进一步提高机器学习算法对目标事件的识别能力是今后的研究重点.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
开放教育研究(2020年2期)2020-03-31
科技创新与应用(2020年6期)2020-02-29
文萃报·周五版(2020年49期)2020-01-07
小天使·二年级语数英综合(2017年10期)2017-10-31
小天使·六年级语数英综合(2017年10期)2017-10-20
中国修辞(2017年0期)2017-01-31
现代电子技术(2016年23期)2017-01-12
北京理工大学学报(2016年6期)2016-11-22
长江学术(2016年4期)2016-03-11
