
训练样本数量对HOG-SVM目标检测算法的影响
2018-08-01 08:06李勇泽陈磊
现代计算机 2018年19期
李勇泽,陈磊
(中国民航大学中欧航空工程师学院,天津 300300)
0 引言
计算机视觉的目标检测算法在近十年有了突飞猛进的发展,算法研究的重心从传统的特征提取加分类器的模式,逐渐转移到了特征提取与神经网络相结合的模式。然而,相比于神经网络,传统算法所需的计算资源较少,因此,对于计算资源宝贵的嵌入式系统来说,传统的目标检测算法往往更加实用。在众多的目标检测算法中,方向梯度直方图(Histogram of Orienta⁃tion Gradient,HOG)加支持向量机(Support Vector Ma⁃chine,SVM)分类器由于具有较好的检测性能而倍受关注。
在训练HOG-SVM算法时需要用到大量经过标记的正、负样本,而且一般都采用人工标记的方式获取。这项工作需要耗费大量的人力,例如著名的PASCAL视觉目标分类数据集(The PASCAL Visual Object Class⁃es,PASCAL VOC)[1]在收集和标记PASCAL VOC 2008上花费了700小时。因此,研究训练样本数量对于目标检测算法的影响,可以在一定程度上减少研究人员在收集和标注样本上的花费,并且对目标检测算法性能的比较上也具有一定的参考价值。
1 HOG特征提取
方向梯度直方图(HOG)特征最早是由N.Nadal和B.Triggs在2005年提出[2],最早用于行人的检测,后来推广到对其他物体的检测。相比于边缘方向直方图(Edge Orientation Histograms)、尺度不变特征变换匹配算法(Scale Invariant Feature Transform,SIFT)以及形状上下文(Shape Contexts),HOG是在网格密集、大小统一的细胞单元上进行计算,为了提高性能,采用了重叠的局部对比度归一化处理[3]。
HOG特征提取的基本流程如图1所示:

图1 HOG特征提取流程
本文使用PASCAL VOC 2012数据集[5]中的四个类别来训练和测试算法,这四个类别分别是dog,cat,car,bird。提取HOG特征的步骤如下:
(1)将样本集中的图像裁剪并根据样本类别缩放至固定大小;
(2)对图像进行Gamma归一化处理;
(3)计算图像中每个像素点的梯度方向和梯度值。水平边缘算子:[-1,0,1];垂直边缘算子:[- 1,0,1]T,图像中像素点(x,y)的梯度为[4]:
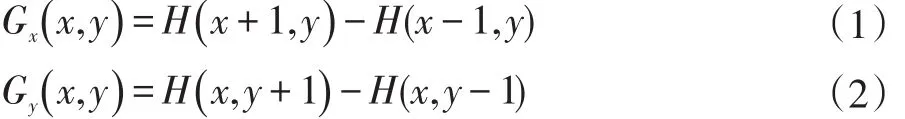
式(1)中,Gx(x ,y),Gy(x ,y),H(x ,y)分别表示输入图像中像素点(x ,y)处的水平方向梯度、垂直方向梯度和像素灰度值。像素点(x ,y)处的梯度幅值和梯度方向分别为:
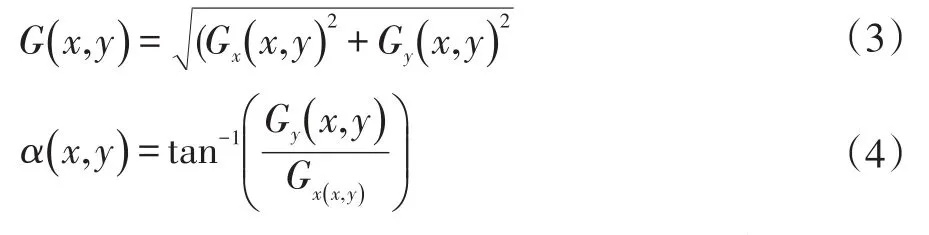
HOG特征计算图像梯度的方式有多种,使用不同的梯度算子对算法性能有一定影响。实验表明,使用上式所示的简单的梯度算子,得到的算法性能最好。
(4)将样本图像分成小的固定大小的单元格(cell),每个cell的大小为8×8像素。将cell中的梯度方向360度分成9个方向块,用一个9维的直方图来表示,对cell内的每个像素,根据其梯度方向在直方图中进行加权投票,用梯度幅值来表示权值的大小。
(5)将一定排列的 cell组成块(block),并以block为单位统计梯度向量,归一化梯度直方图。Block从图像左上角开始,以一个cell为步长移动,直至遍历整个图像。归一化block中的特征向量即可得到block上的HOG特征。Block和block之间有重叠,因此能保证同一个cell的不同的归一化结果(cell在不同的Block中被归一化)能对最后的HOG向量都有贡献,从而使得算法具有一定的平移不变性。归一化能够进一步地对光照、阴影和边缘进行压缩,使特征向量空间对光照,阴影和边缘变化具有鲁棒性。采用L2-范数方式归一化可以极大地提高HOG的性能,如公式(5)所示:

(6)合并所有block中的梯度向量,形成最终的HOG特征。本文所用到的样本检测窗口大小和特征维度数量如表1所示:
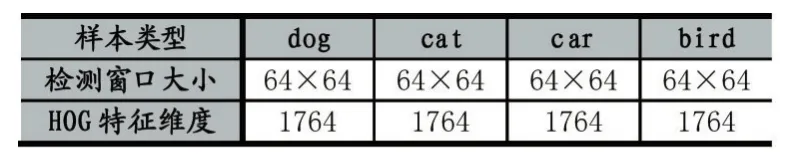
表1 检测窗口大小与HOG特征维度数量
2 评价指标
常用于评价目标检测算法性能的指标包括准确率(Accuracy)、精确率(Precision)、召回率(Recall)和 F1-Measure[6]。通常关注的类为正类,其他类为负类,算法在测试数据集上的预测或正确或不正确,4种情况出现的总数分别记作:
TP:将正类预测为正类数;
FN:将正类预测为负类数;
FP:将负类预测为正类数;
TN:将负类预测为负类数。
准确率的定义为:

精确率的定义为:

召回率的定义为:

F1-Measure是精确率和召回率的调和均值,其定义为:

精确率和召回率都高时,F1的值也会高。
3 实验结果与分析
本文的实验环境为:CPU为Intel Core i5-6200U处理器(主频为2.30GHz),内存为8GB,操作系统为Win⁃dows 10,使用的编程平台为MATLAB 2016。
采集PASCAL VOC 2012数据集时,采用人工标注的方式标记出图片中的目标,通过脚本程序读取标注信息并裁剪出目标,然后缩放至表1所示大小,从而生成正样本集,再从不包含目标的图片中随机截取表1所示大小的图片,形成负样本集。然后分别从正、负样本集里随机抽取样本,生成训练样本集和测试样本集,其中,每个测试集中包含1000个正样本和数量相等的负样本,训练集中的正、负样本数量相等,每个训练集中的正样本数量如表2所示:
本文设置四个类别,每个类别设置10个数量以指数增长的训练样本集,以此作为一组实验。为了减少实验中的偶然性误差,重复进行了9组独立实验,以9组实验结果的平均值作为最终的实验结果。
根据式(6)和式(7)计算得到准确率和召回率随训练样本数变化曲线如图2所示:
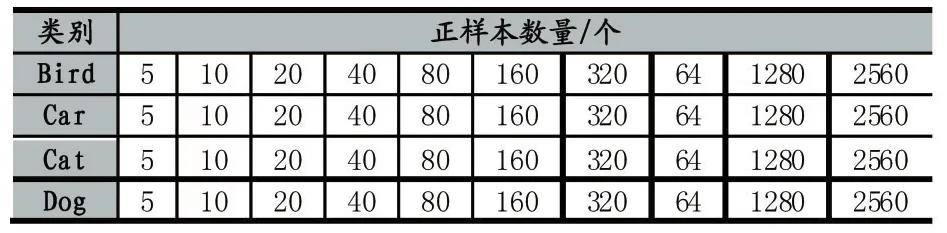
表2 各训练集正样本数量
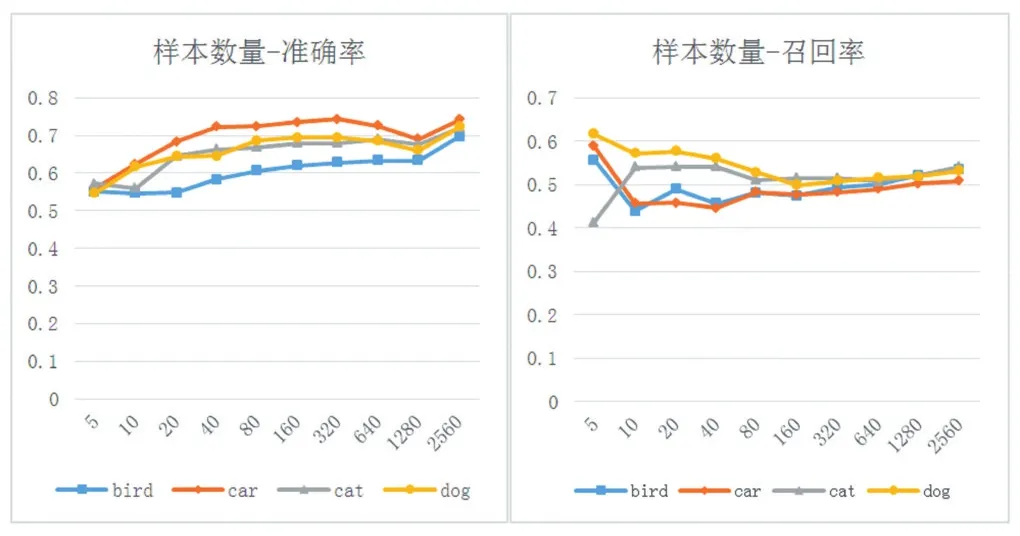
图2 样本数量-精确率与样本数量-召回率曲线
上图2的横坐标为训练所用的正样本数量,注意横坐标不是均匀增加的,而是取了以2为底的对数。纵坐标分别为准确率和召回率。可以看出,目标类型对HOG-SVM算法的检测性能有一定的影响。在样本数量相同时,HOG-SVM算法对car这类目标的检测效果最好,最高能达到75%的准确率和57%的召回率。对bird的检测效果最差,在训练样本达到一定数量之后,也能达到60%以上的准确率和50%以上的召回率。对于同一类目标,在样本数量较小时,检测的准确率随样本数量的增加而增加。在样本数量超过80时,检测准确率和召回率都趋于稳定,几乎不再增加。
与2010年的PASCAL VOC竞赛[7]的结果相比,在召回率相同的情况下,当训练样本数量达到80时,HOG-SVM算法对于这四类样本的检测准确率也能达到中等水平。
为了更深入地分析,本文计算出了不同组实验结果的F1值及其方差,如图3所示。可以发现,F1出现与准确率和召回率同样的趋势,即当样本数量达到80之后,F1随训练样本数量增加的速度变慢且趋于稳定。F1的方差也随训练样本数量增加而减小,且在训练样本数量达到80之后下降到一个极小的值并趋于稳定。说明在训练样本数量达到80之后,各组实验的差异性变得极小且HOG-SVM算法的检测性能趋于稳定。
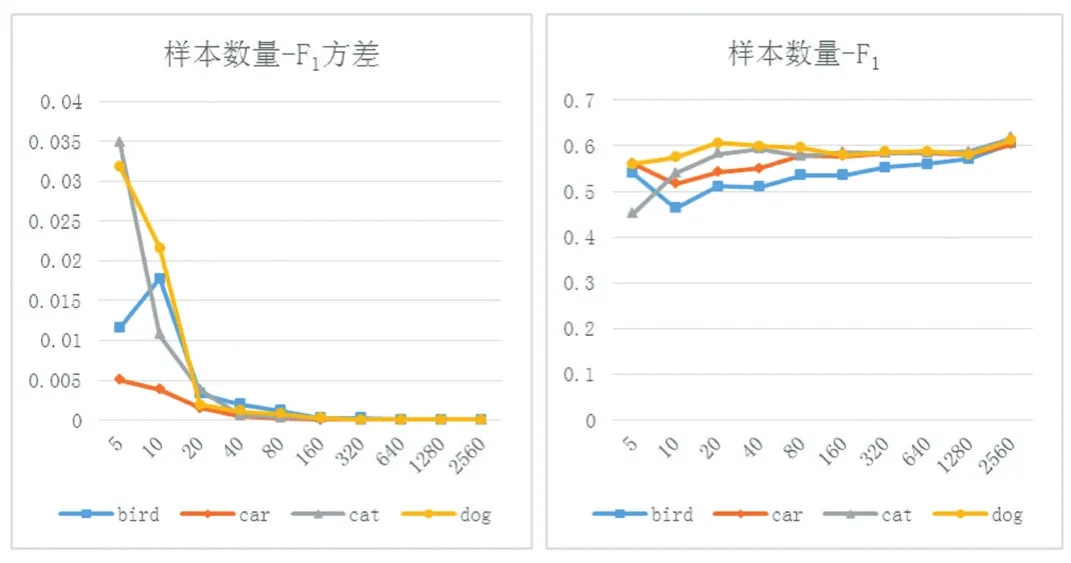
图3 样本数量-F1值方差与样本数量-F1曲线
4 结语
针对目标检测算法获取训练样本成本较高的问题,本文对HOG-SVM目标检测算法检测性能与训练样本数量的关系进行研究。通过一系列实验发现,对于同一类别的目标,随着训练样本数量的增加,算法分类准确率和召回率都有一定的增加,当训练样本数量达到80时,分类准确率趋于平缓且达到可用水平。
猜你喜欢
中国设备工程(2022年19期)2022-10-12
湘潭大学自然科学学报(2022年2期)2022-07-28
九江学院学报(自然科学版)(2022年2期)2022-07-02
天津医科大学学报(2021年1期)2021-01-26
计算机应用(2020年11期)2020-11-30
科技创新与应用(2020年6期)2020-02-29
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
北京航空航天大学学报(2017年12期)2017-04-23
初中生世界·八年级(2017年3期)2017-03-24
现代电子技术(2016年23期)2017-01-12
