
基于蒙特卡洛法红枣光谱水分模型研究
2018-08-08 08:08石鲁珍张树艳张景川
江苏农业科学 2018年14期
石鲁珍,陈 杰,张树艳,张景川,3
(1.塔里木大学信息工程学院,新疆阿拉尔 843300; 2.南疆农业信息化研究中心,新疆阿拉尔 843300;3.塔里木大学机械电气化工程学院,新疆阿拉尔 843300)
红枣是新疆南疆地区主要的经济作物,含有多种微量元素和营养物质,近些年红枣产业有了较快的发展。含水量是红枣重要的测量指标,在收购的过程中红枣含水量达不到加工企业的标准,企业将不予以收购,或者低于市场价格进行收购,因为红枣在加工过程中需要含水量相接近。收购到加工企业的红枣在加工贮藏时,含水量更是重要的测量指标。清洗、烘干、包装每个环节对水分的控制非常严格,包装是红枣成品上市的最后一关,红枣含水量决定其口感,通常认为含水量为20%左右的红枣口感最佳,因此,只有快速、准确地测量红枣含水量,才能合理评价红枣品质,提高农户的收入,提升加工企业的产品质量和经济效益[1]。
近红外光谱(NIR)技术作为一种有效的分析测试手段,目前已经广泛运用于食品[2]、饲料[3]、烟草[4]、石油[5]等领域化学性质的测定。偏最小二乘(PLS)法是近红外光谱定量分析中运用最多的多元统计方法。PLS模型可以很方便地对化学值预测,模型的质量对预测结果影响很大。所以建立一个高质量的模型非常关键,不同的预处理方法和波长变量选择对模型的质量影响很大,如预处理方法正交信号校正(OSC)、净分析信号(NAS)和小波变换(WT)[6]等,波长变量选择方法无信息变量消除(UVE)[7]、连续投影(SPA)[8]、遗传算法和间隔偏最小二乘法[9]等,这些方法已经广泛应用于近红外定量分析中,并发挥了重要作用。除了光谱数据预处理、波长变量选择方法,奇异样本识别更重要,奇异样本对模型质量有很大的影响。常用的奇异样本识别方法有马氏距离、浓度残差、光谱残差[10]等,这些奇异样本识别方法对于单个奇异样本识别方法效果很好,但是对于样本集中奇异样本较多时,其识别效果往往不是很理想。本研究利用蒙特卡洛交叉验证(MCCV)[11-14]中奇异样本的统计规律来识别奇异样本,并比较几种常见的预处理方法和波数选择方法,来建立预测性较好的红枣水分近红外定量分析模型。
1 材料与方法
1.1 材料与仪器
试验所用灰枣样本:产自新疆阿拉尔市农一师10团,采摘时间为2016年10月份,采摘后放置冷库中保存,冷库温度为1~5 ℃。傅里叶变换型近红外光谱仪Antaris Ⅱ(赛默飞世尔,美国),波数范围:10 000~4 000 cm-1,信噪比:15 000 ∶1,分辨率设置为8 cm-1,光谱点数为1557点,光谱扫描次数为32次。ME104E分析天平(梅特勒,瑞士),最大称量值:120 g,精度:0.1 mg。
1.2 光谱采集
先将灰枣从冷库中取出,在实验室放置4 h,目的是让灰枣温度与室内温度相同。近红外光谱仪Antaris Ⅱ开机预热 1 h,开始采集灰枣近红外光谱,采集方式是:采集灰枣赤道部位每间隔120°位置,每个灰枣采集3次光谱,将3条光谱进行平均作为该灰枣的近红外光谱,图1为151个灰枣的近红外光谱。为了保持光谱检测的无损特性,所有红枣样本均是整果(连皮带肉)采集其近红外光谱[15-16]。
1.3 红枣水分测定方法
将红枣去皮,取果肉约3 g,放入ME104E分析天平称质量,精确到0.000 1 g,记为m1,然后放入电热鼓风干燥箱内烘干,温度设置温度为70 ℃。每隔4 h称质量1次,至质量变化小于0.001 g时从烘箱中取出,并放入干燥器内冷却至室温,称质量直至恒质量记为m2。红枣含水率W按下式计算:
式中:m1为称取红枣果肉样品烘干前质量,g;m2为称取红枣果肉样品烘干后质量,g。
MATLAB R2012a(Mathworks,USA)用于算法的实现,光谱采集软件为Result(Thermo Fisher Scientific,USA)。
2 结果与分析
2.1 蒙特卡洛交叉验证(MCCV)剔除异常样本
在近红外定量分析[17-18]中,哪个样本是奇异样本是未知的,但是可以根据正常样本与异常样本的差异性,建立大量的定量模型,然后通过统计参数把奇异样本选择出来,这就是基于蒙特卡罗交叉验证(MCCV)的一类奇异样本识别方法。利用MCCV随机划分校正集与预测集,如果奇异样本在校正集中,整个模型的质量将受到影响;相反,如果奇异样本在预测集中,仅此样本的预测结果受到影响。尽管这种情况对预测结果都有影响,但效果明显不同。本研究就利用奇异样本出现在校正集或预测集时模型预测误差的差异,通过MCCV及统计分析来进行奇异样本的识别。根据预测集中奇异样本的预测残差会明显大于正常样本的预测残差也提出了一种基于MCCV的奇异样本识别方法。基于MCCV的奇异样本识别方法充分利用统计学的性质,能够在一定程度上降低由掩蔽效应带来的风险,检出光谱阵和性质阵方向的奇异点,有望在奇异样本检测中得到更广泛的应用[11]。
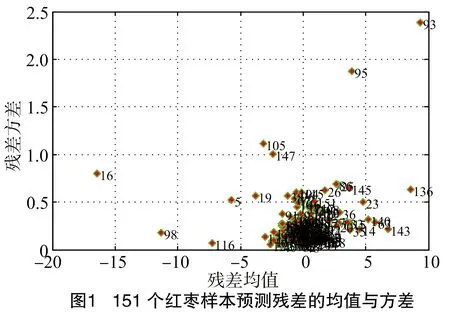
算法具体步骤:(1)用PLS确定最佳主成分数;(2)用蒙特卡洛随机取样法取80%的样本做校正集建立PLS回归模型,剩余部分做预测集;(3)循环2 000次,得到各样本的1组预测残差;(4)求各样本预测残差的均值与方差,并作图;(5)如样本偏离主体,则从校正集中剔除。图1是151个红枣样本利用MCCV的奇异样本识别方法计算出的残差均值和残差方差,将均值小于-5、大于5的样本,方差大于1的样品进行剔除。剔除异常样本共12个,编号分别是第5、16、63、93、95、98、105、116、136、140、143、147。
2.2 校正样本选择
校正样本集的选择比较关键,通常校正集的样本光谱性质和浓度范围应包括验证集的光谱性质和浓度范围,且分布均匀,这里用SPXY(sample set partitioning based on joint x-y distances)[12]法对样品进行选择。将剩余的139个红枣样本分成2组,一组是校正集用来建立校正模型,另一组是验证集用来测试模型的准确性和稳健性。如表1中所示,校正集y值范围大于验证集的范围。因此,样品分布在校正集和验证集是适当的。
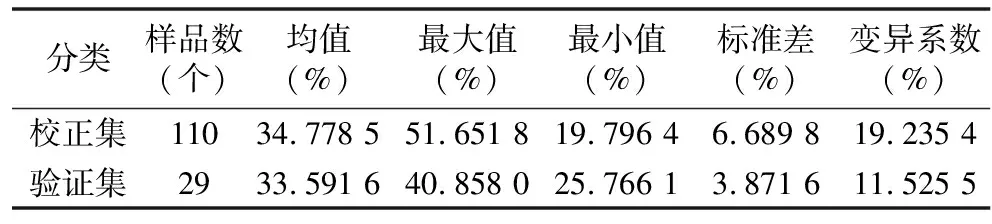
表1 校正集和验证集样品水分含量参考测量值
2.3 光谱数据预处理
在近红外进行建模的过程中,光谱的预处理是必不可少的,在近红外定量分析与定性分析中是非常关键的一步,经过适当的近红外预处理方法可有效提高模型的适用性能力。合理的预处理方法可有效过滤近红外光谱中的噪声信息,保留有效信息,从而降低近红外定量模型的复杂度,提高近红外模型的可用性。表2是选用不同的光谱预处理方法,波数用全谱建立的模型结果。从表2中可以看出一阶导数得到的模型有最小验证标准偏差(SEP),所以预处理方法选择一阶导数。
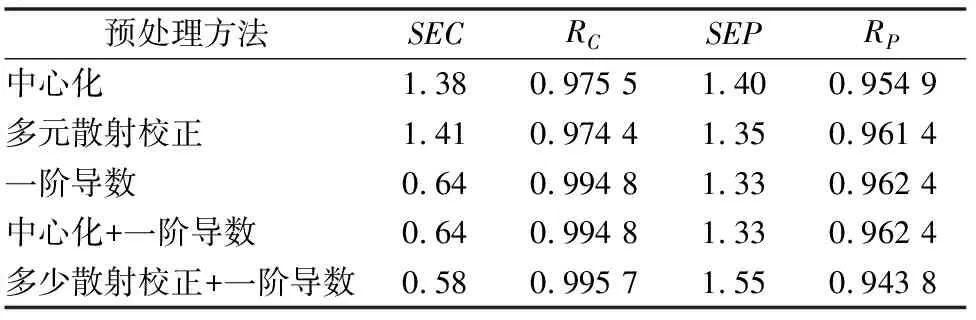
表2 不同预处理方法得到的模型结果
导数(微分)可以消除样品光谱的基线漂移、增强谱带的特征信息并克服谱带重叠,是最为常用的光谱数据预处理方法。一阶导数可以去除同波数无关的基线漂移。图2-a是红枣原始光谱图,图2-b是经过一阶导数处理后的光谱图。
2.4 波数变量选择
2.4.1 相关系数法 相关系数法是计算校正集光谱矩阵中每个波数点对应的吸光度向量与样品组分浓度向量的相关系数,然后得出每个波数点变量对应的相关系数。将相关系数排序,选择合适的阈值,保留相关系数大于该阈值的波数点,进而建立多元校正模型[6]。相关系数r由下式计算:
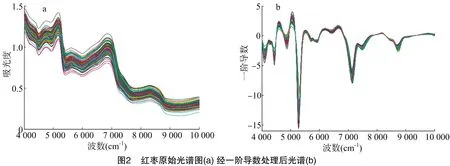
图3是校正集红枣含水量与波数的相关系数图,蓝线为相关系数,红线是所选择的阈值,绿色五角星为所选择的波数点,从图3中可以看出红枣含水量与波数有较好的相关性,阈值选择0.6(取绝对值,大于0.6和小于-0.6的波数被选择),共选择波数变量311个。

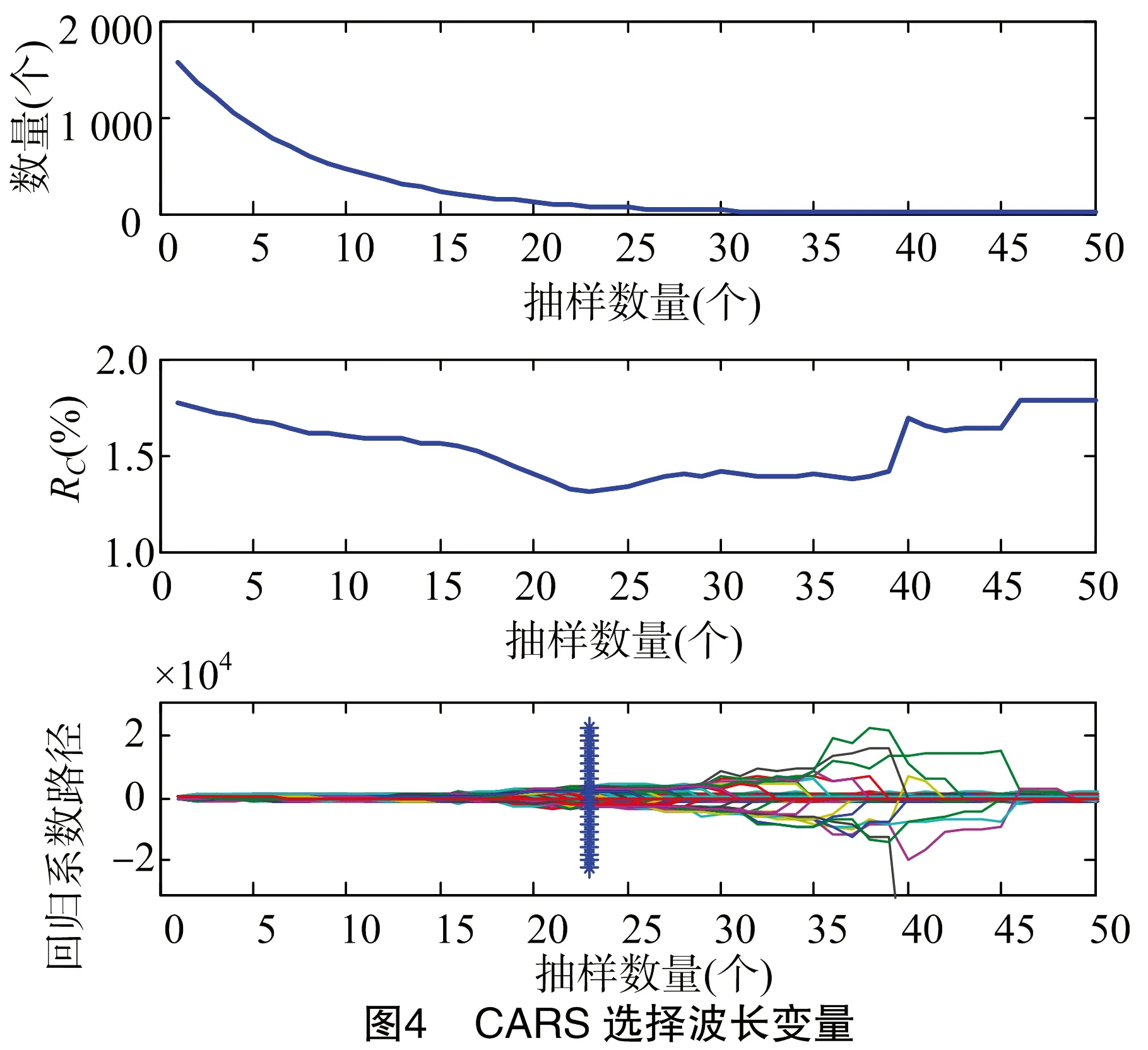
2.4.2 竞争性自适应加权取样(CARS)法 竞争性自适应权重取样(competitive adaptive reweighted sampling,CARS)选择波数的方法是基于回归系数的权重,衡量波数被选中的重要评价指标是回归系数绝对值的大小,采用交互验证选择偏最小二乘模型交互验证均方根误差最小的子集,选择出与目标值对应的最优波数组合,逐个将绝对值大的回归系数对应的波数点保留,保留方式采用指数衰减函数来计算。
CARS算法实现步骤是:首先,运用蒙特卡洛方法循环N次,每次从数据样本中随机抽取一定数量(通常取总样本数的80%)的样本作为建模集建立偏最小二乘模型;然后,利用指数衰减函数去掉回归系数绝对值相对较小的波数点,第i次循环时,保留波数点的概率为:
ri=ae-ki。
这里a与k为常数,a与k的计算公式如下:
可以看出,第1次采样时,所有的m个变量都被用于建模,故r1=1;运行第N次采样时,仅2个波数被使用,故rN=2/m。
图4是用CARS方法选择波数变量图,其采样次数为 1 000 次,PLS主成分数选择10,共选择78个波数变量。
2.4.3 模型比较 将相关系数法、CARS法得到的PLS模型与全谱建的PLS模型进行比较,结果如表3所示。对于全谱PLS模型,共选用1 557个变量来建立校正模型,这 1 557 个变量有很多和红枣含水量不相关,这些变量称为“无信息变量”。如果模型中含有“无信息变量”,会增加PLS主因子数,从表3中可以看出该模型的PLS主因子数是9个,较另外2个模型主因子数要多。过多的PLS主因子数会导致模型过拟合,通过独立的样品来测试时,过拟合模型会给出不好的预测结果,从表3可以看出,虽然全谱得到的校正标准偏差(SEC)和校正相关系数(RC)要好于其他2个模型,但是预测标准偏差(SEP)大于另外2个模型,预测相关系数(RP)低于另外2个模型。
对于相关系数法得到的PLS模型,和全谱PLS模型相比主成分数降到了8个,预测标准偏差(SEP)和预测相关系数(RP)也都好于全谱模型,这时因为相关系数法选择的波数变量数要小于全谱1 557个,大大减少了“无信息变量”。
对于CARS法得到的PLS模型,模型的主因子数为7个,“无信息变量”得到进一步降低,模型变得更加简洁和稳定。从模型的预测结果上看预测标准偏差(SEP)和预测相关系数(RP)在所以模型中是最好的。
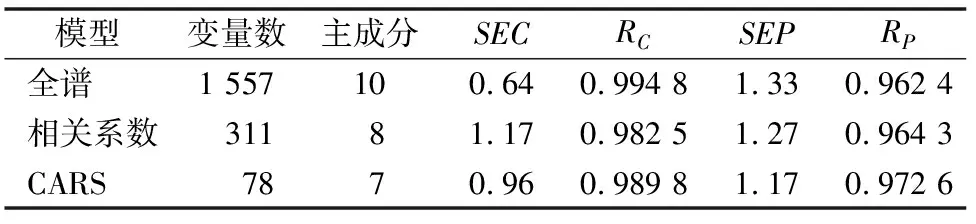
表3 选择不同波数得到偏最小二乘模型结果
3 结论
蒙特卡洛交叉验证(MCCV)能够有效地识别奇异样本。利用一阶导数对红枣原始近红外光谱进行处理,可以很好地提取有用的信息,去除同波数无关的基线漂移。CARS方法选择的波数变量建立PLS模型,与全谱模型相比,不仅提高了模型的预测准确性,而且还大大减少了建模波数变量数,使模型简化,减少建模所用时间,所选取的波数变量能够有效地反映红枣含水量的信息,建立的模型稳定性强。
猜你喜欢
电子测试(2022年16期)2022-10-17
趣味(作文与阅读)(2021年12期)2021-04-19
国学(2020年1期)2020-06-29
学生天地(2019年35期)2019-08-25
今日农业(2019年10期)2019-06-26
数学物理学报(2017年6期)2018-01-22
摄影之友(影像视觉)(2017年1期)2017-07-18
小猕猴学习画刊(2016年6期)2016-05-14
地球物理学报(2015年6期)2015-02-18
地球物理学报(2014年4期)2014-09-25
