
基于机器学习的通信网络非结构化大数据分析算法
2018-08-08 06:28安强强李赵兴张峰张雅琼
电子设计工程 2018年14期
安强强,李赵兴,张峰,张雅琼
(榆林学院陕西榆林719000)
目前,大数据的含义并没有统一。从狭义方面研究,大数据表示计算机内存储器中的载入数据。从广义方面研究,大数据指的是在传统软件、硬件和计算机技术中的某时间范围中无法获取、感知和处理的数据结合。总的来说,大数据的主要特点就是庞大的数据量和角度的数据类型,并且其变化速度较快。在此背景下实现数据的有效挖掘,是我国现代化产业在发展过程中的主要研究方向。传统机器学习主要为:实现发现全新事物程序,从而进行机器学习的设计目的;实现问题的自动规划设计。但是传统的机器学习都是通过数据环境进行,不能够进行大数据的学习。针对此问题,文中对大数据问题进行有效解决,对基于机器学习的大数据分析算法进行深入的研究。
1 大数据的特点及纬度
为了能够有效满足现代计算能力在短时间内就要求处理上百万次的需求,大数据分析具有较大挑战,此种挑战主要是大数据的特点。
大数据最基本的特点就是具有较大的数据量,然后数据为异构数据,不能够实现批量处理。并且,大数据一般都是分布式无法实现集中处理工具一次性多种操作的处理[1]。
在现代最新大数据分析过程中,调整大数据的特点,使其成为:
1)提高每分钟的大数据量;
2)数据具有多种格式,不能够实现批量处理;
3)在大数据量不断增加的过程中,数据之间的关系较为复杂,并且此种复杂关系在不断的增加;
4)能够为决策人员提供数据的支持及实证决策;
5)数据来源于多个终端设备,聚合尤为复杂。
从另外一个角度分析,大数据属于C3纬度,以存储、挖掘、机器学习及数据分析的方面进行建模及分析[2],C3分别对应的就是一下内容:
1)集合化的对象,其实现了特征和数量的记录;
2)包括大数据的表达特点和大数据的占用空间;
3)负载性主要包括三维度,分别为较高的数据集维度、较广的数据类型变化分为用户具有较高的数据高速处理需求[3]。
大数据中的数据复杂度及大小数据大数据分析过程中解决问题过程中的核心内容,只要实现问题的有效处理,大数据分析之后的结果才能够被有效使用[4]。比如现代教育已经创新了传统课堂方式的教育,成为了现代化的交互教育,各国各地的学生都能够利用互联网在虚拟化的教师中学习,学习的模式也发生了创新,在学习过程中出现的数据也在不断的增加,并且互联网互通程度越来越高,在线教育过程中数据形式及格式在不断更新。在线教育具有明显的数据源特点,首先,教学过程中使用的材料并不是电子化的形式,其属于具有一定比例的非电子化材料;其次,全新的数据不仅具有信息系统中数据运行过程中产生的数据,社交网络过程中学生对于各种内容的看法信息,学校服务器运行过程中的日志。
现代面向多样化的数据量和具有较大数据量的特点,可以使大数据的分析和处理性能更进一步的提高,从而满足不断发展大数据的需求[5]。
2 大数据分析算法
文中提出的以机器学习为基础的通信网络非结构化大数据分析算法属于在线终端分析算法,其具体的设计为以下:
在线终端分析算法床啊经模型的学习方式就是对模型和输入的数据形式进行推理,以此得到数据的最终结果[6]。
在线终端分析的学习算法在数据库挖掘中广泛使用。训练集输入数据包括非生成集、识别标签及生成集等。在迭代过程中每一次迭代都要将针对性的数据进行输入,在进行训练过程中,实现数据的预测尤为重要,在预测结果出现问题的时候能够实现自动的修改,一直到训练集的数据能够满足需求,并且实现数据的精度就结束[7]。
在线终端分析算法主要指的是对于非结构化的数据进行全面的分析设计,为了能够实现场景的直接化,在线终端分析的算法就要通过训练集的实际例子组成非结构化数据,在线终端分析算法的过程中主要实现相邻两个节点之间加权参数的关联度评价。图1为在线终端算法在Hadoop中的结构,图2为在线终端算法在HDFS中的内部文件读取过程,图3为在线终端算法在Map中的分析过程。

图1 在线终端算法在Hadoop中的结构
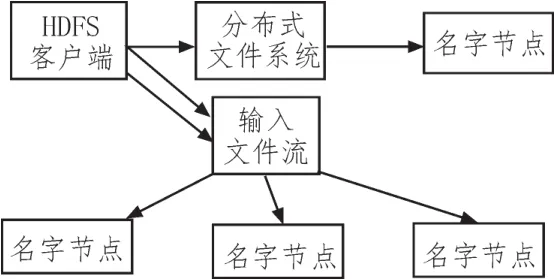
图2 在线终端算法在HDFS中的内部文件读取过程
名字节点文件的存储系统转换数据主要的形态就是两张表,第一张属于在数据节点中融入数据块,第二张属于在块编号中融入数据节点[8]。

图3 在线终端算法在Map中的分析过程
本文对在线终端分析算法中进行了任务跟踪器的布置,以此能够全面监督工作节点的任务执行,并且将其对工作跟踪器进行汇报。在任务跟踪器接收到任务的时候就会分配到本地工作跟踪器,从而实现数据生成,以此对工作跟踪器实现进程的汇报。
为了能够实现Map过程的检验,将其中的输入数据划分成为多个切片,将OTA进行输入,之后在Hadoop平台中将数据切片进行输入和处理。
在Map结束之后就会进入到Red阶段中,此过程就是实现数据的并行处理。其中的任务就是合并数据,此合并的数据就是最后的分析结果[9]。
因为Red是以Map结果为基础进行执行的 ,所以在处理过程中并不是绝对并行,是在Map结束之后开始Red,此并不能够优化。但是从理论上分析,利用Map及Red实现数据传输过程中,接收数据值和结构相互对应。接收数据映射的输出为相同映射机构,但是具体值要根据相应的步骤进行处理。
在线终端分析算法处理分类的过程就算法的核心内容,为了能够实现算法效率的进一步提高,在进行分类时就要进行以下优化:为了对x点信息密度进行检测,就将x位置作为中心,布置混合立方体X,将X体积不断的扩大,直到X中具有x点的k相邻点[10]。
利用以下公式能够实现x点信息密度的获取:
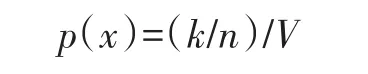
以此表示,密度为体积函数,与x的相邻点信息密度较高的过程中属于随机分布,此时k点和对于x来说初选的机率比较大。混合的立方体体积并不是最直接的关注量,最重要的就是相互对应的密度[11]。
3 算法的性能分析
为了对本文研究的在线终端分析算法性能深入分析,本文就进行在线购物研究,分析原始数据性能,表示在线购物时候的用户数据信息较多[12]。
创建大数据平台,使其能够实现数据的测试,之后实现平台的配置。在实现配置之后,全面分析运行数据,每次运行的信息节点数量不同,并且每次处理的时间也并不相同[13]。表1为每次分析使用的时间和节点数量,图4为每次分析使用的时间和节点数量图。
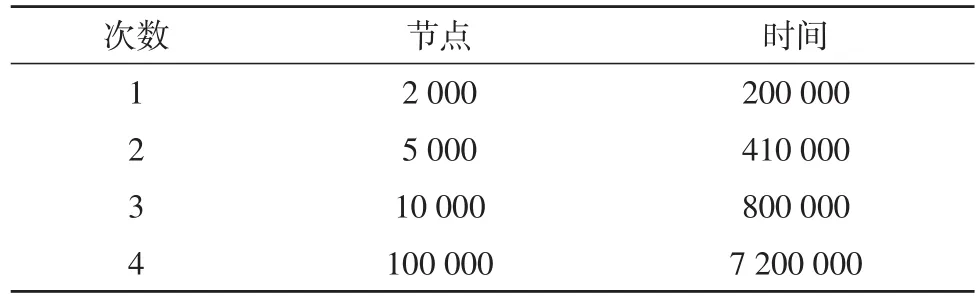
表1 每次分析使用的时间和节点数量

图4 每次分析使用的时间和节点数量图
为了能够对在线终端分析算法在运行过程中数据分析的结果进行全面的评估[14],表2和图5就对以上的分析结果名称节点及数据节点进行了全面的分析。

表2 四次运算的名字及数据节点的大小对比
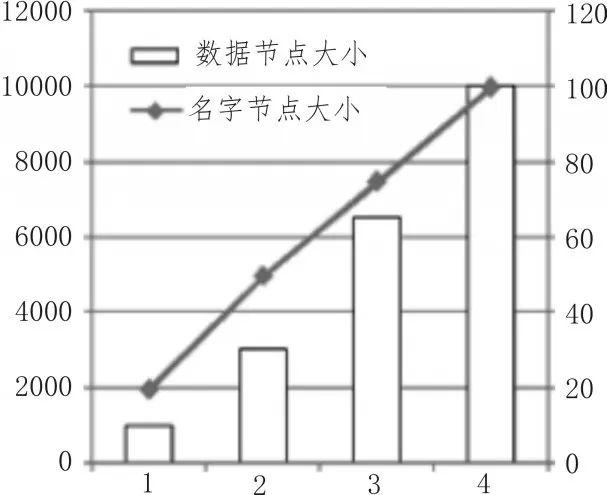
图5 四次运算的名字及数据节点的大小对比图
图6为传统数据库和本文研究的算法在计算过程中效率的对比,将两种算法每秒实现处理的次数作为单位进行对比[15-16],图6中表示的运行节点和数量也以上的分析结果全部相同。
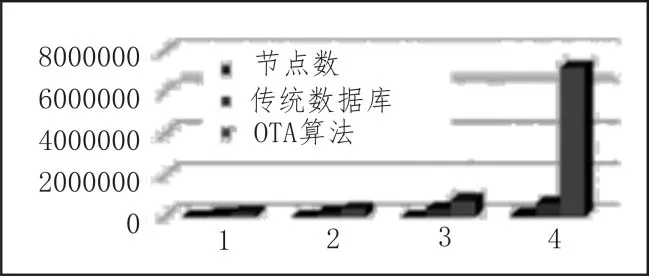
图6 传统数据库和在线终端算法分析的结果对比
4 结束语
目前,我们正处于数字化的时代中,在数据不断积累的过程中,大数据中的问题也越来越突出,大数据的构成较为复杂,并且数据量较多,变化较快,使用传统的机器学习算法无法实现大数据的处理及分析。所以,本文就对以机器学习为基础的通信网络非结构化大数据分析算法进行了全面的分析。通过对本文研究的算法性能分析表示,本文研究的在线终端分析算法性能良好,能够有效满足大数据的分析处理,还能够有效解决传统机器学习过程中遇到的问题。
猜你喜欢
环球时报(2022-07-13)2022-07-13
太阳能(2022年3期)2022-03-29
环球时报(2022-03-14)2022-03-14
北京大学学报(自然科学版)(2021年3期)2021-07-16
东北师大学报(自然科学版)(2021年1期)2021-03-27
电脑爱好者(2020年19期)2020-10-20
太阳能(2020年3期)2020-04-08
电子制作(2019年13期)2020-01-14
当代工人·精品C(2019年2期)2019-05-10
电影(2018年8期)2018-09-21
