
基于GPU数据库系统的并发查询性能优化
2018-08-15 08:02李逸龙何震瀛王晓阳1
计算机应用与软件 2018年8期
李逸龙 张 凯 何震瀛 王晓阳1,,4
1(复旦大学软件学院 上海 201203)2(复旦大学计算机科学技术学院 上海 201203)3(上海市数据科学重点实验室 上海 200433)4(上海智能电子与系统研究院 上海 201203)
0 引 言
由于物理工艺的限制,近年来CPU的性能已经难以得到大幅提升。然而,在大数据时代数据量快速增长,这使得CPU越来越难以应对日益增长的数据处理需求。与此同时,利用通用计算图形处理器(GPGPU)的并行处理能力来加速计算任务成为研究热点。由于GPU极大地提升了计算性能,数据库研究领域也出现了大量用GPU对查询计算任务进行加速的研究。跟传统的CPU数据库相比,GPU数据库在查询任务执行中展现出非常显著的加速效果。
利用GPU加速SQL运算符的执行速度,YDB系统[1]实现了一个基于GPU的数据库系统,跟CPU版本的实现相比,能够达到大约2~6倍的查询速度提升。为了进一步提高GPU的资源利用率,出现了以支持并发查询为目标的研究成果,其中突出的系统有MultiQx-GPU[2]和Ocelot[3]。以MultiQx-GPU系统为例,该系统实现了并发查询之间分时共享GPU资源的机制,提升了GPU的资源利用率和系统性能。
然而MultiQx-GPU系统的架构设计仍然导致了一些问题和缺陷。首先,MultiQx-GPU在每个查询任务进程中都需要创建CUDAContext以发起后续GPU调用,耗时较大。其次,该系统虽然能够让并发的查询任务之间分时共享GPU资源,但是在不同查询任务中重复传输了数据库中相同的列存储数据,不但浪费了PCIe总线带宽,还大量占用了GPU资源。以上两点不足会造成系统对GPU整体的资源利用率较低。
针对以上不足,本文将基于MultiQx-GPU系统,提出一种改进架构的HyperQx-GPU系统的设计与实现。该系统能够统一管理GPU硬件资源,减少了每个查询任务单独管理GPU的开销,提升了单个查询的执行效率。同时,该系统能够根据系统中实时的查询任务运行情况,实现跨并发查询任务的数据库列存储数据共享,减少系统整体的PCIe数据传输量,进一步提升了系统性能。
系统架构方面,该系统采用C/S的架构设计,将数据库系统分为查询处理客户端和数据库服务端,两端用IPC机制进行通信,使得两个部分的优化可以互不影响地进行。跟MultiQx-GPU系统的函数库实现方式相比,降低了系统组件之间的耦合性,增强了系统功能的可扩展性。
实验结果证明,本文实现的HyperQx-GPU系统能够大大提升GPU的整体资源利用率。对比MultiQx-GPU系统,HyperQx-GPU系统在执行并发SQL查询的情况下能达到平均12倍的性能提升。
1 背景和相关工作
1.1 GPU硬件结构及编程框架
CPU和GPU的硬件架构具有很大差异,具体情况如图1所示。相比于CPU大量逻辑控制单元和缓存单元的硬件架构,GPU包含更多计算核心和高性能内存单元,因而更适合被用于处理批量数据的密集型并行计算。以NVIDIAGTX TITAN X型号GPU为例,该GPU拥有3 584个计算核心,并行计算能力非常强。其还拥有具有5 005 MHz时钟频率和384 bit传输位宽的高性能内存单元,相比于通常CPU搭配的DDR4内存,前者能够达到更高的内存数据访问速度。

图1 GPU内存数据库系统架构
在目前的GPGPU领域中,最常用的编程框架为OpenCL和CUDA[4]。基于跟MultiQx-GPU对比的目的,本文设计的系统实现过程中采用了CUDA编程框架,因此此处以CUDA为例进行介绍。在CUDA编程模型中,程序代码会被编译为CPU运行的宿主程序和GPU运行的程序,其中GPU中运行的函数被称为kernel。GPU作为协处理器,执行计算任务时需要CPU上运行的宿主程序通过CUDA提供的API进行驱动,因此其整体上是一个异构的编程模型。
CUDA程序运行时,其宿主程序调用的所有CUDAAPI会被放到一个stream内。CUDA编程中的一个stream代表一串连续的CUDA API调用命令,同一个stream内的CUDAAPI调用会被GPU串行地调度执行。宿主程序可以创建多个stream,在不同的stream里发起的命令在没有数据依赖的情况下,会被GPU调度器并发执行,从而提升GPU的资源利用率。在CUDA编程中,一个常用的优化手段为利用多个stream同时发起互相不存在依赖关系的PCIe数据传输和kernel调用,使两者可以同时执行,从而有效利用GPU的数据带宽和计算资源。
1.2 GPU数据库系统
基于GPU的高性能计算能力,大量研究开始利用GPU加速数据库的join和sort等SQL操作符[5-8]以及事务的执行[9]。此后,不少研究考虑将GPU作为数据库查询执行的主要硬件[10-11],如前所述的YDB是典型的设计与实现。相比于CPU数据库系统,YDB系统能显著地提升查询任务执行效率。然而其缺点也很明显,即串行执行查询任务时,每个任务独占GPU硬件资源,无法充分利用GPU计算和PCIe数据传输带宽等资源。
为了提升GPU的资源利用率,需要支持并发的查询请求。目前支持并发查询请求的GPU数据库系统主要有MultiQx-GPU和Ocelot。以MultiQx-GPU为例,该系统通过动态链接库拦截的机制,在执行SQL查询任务前通过LD_PRELOAD环境变量预加载系统提供的动态链接库,拦截了查询任务发起的CUDARuntimeAPI调用,实现了并发的查询任务间协同管理GPU资源的机制,使得不同任务进程之间可以共享GPU资源。与YDB相比,MultiQx-GPU在执行并发查询任务时能够达到平均55%的系统吞吐量提升。MultiQx-GPU的系统架构如图2所示,虚线上方为系统实现部分,下方为CUDA提供的运行时环境。

图2 MultiQx-GPU系统架构
尽管MultiQx-GPU系统的设计和实现得到了实验结果的验证,但是该系统所达到的GPU资源利用率仍然还有很大的提升空间。具体而言,其待改进之处主要有以下两点:(1) 在不同查询任务中重复传输可共享的只读的数据库列存储数据,造成PCIe总线的带宽资源浪费。图3展示了HyperQx-GPU系统中(关闭列存储数据共享功能)一次查询任务的执行时间线。从图中可看出,在334 ms的查询任务执行时间中(不包括创建CUDA Context的时间),CPU内存到GPU内存的PCIe数据传输操作占据了超过75%的时间(262 ms)。因为数据库中的计算任务通常涉及大量的列数据扫描和表之间的连接等操作,在执行实际的SQL操作之前需要传输大量的列存储数据到GPU内存,计算结束之后还需要把结果数据从GPU内存传输回CPU内存。大量的PCIe数据传输使得本来就稀缺的PCIe总线带宽成为了该系统执行查询任务时的性能瓶颈。(2)MultiQx-GPU系统中的每个查询任务进程独立调用CUDARuntimeAPI来使用GPU资源,使得每个进程均需要创建独立的CUDAContext,增加查询任务的执行时间,进而影响系统的整体性能。

图3 MultiQx-GPU系统PCIe数据传输时间线
为了支持高性能的分析型查询任务,数据库系统通常采用列存储的数据格式,以减少扫描等查询操作在单条记录上的执行时间[11]。比如SQL语句中的where语句,通常会解析后生成进行列扫描的SQL操作,其特点是在某一列的所有数据上做同样的操作,符合向量计算模型。如果利用GPU的高性能并行计算能力来执行此扫描操作,其执行效率能够得到数量级的提升。
2 系统设计与实现
2.1 系统架构
HyperQx-GPU系统整体上采用C/S架构的设计。在查询任务端,利用动态链接库的设计达到系统对查询任务进程透明的效果,不会侵入查询任务的代码逻辑。查询进程通过动态链接库与数据库服务进程直接通过IPC机制通信,保证了具体查询任务进程和数据库服务进程之间的低耦合性,使得系统具有良好的可扩展性。HyperQx-GPU的系统架构如图4所示。

图4 HyperQx-GPU系统架构
由于CUDA编程框架的异构性,HyperQx-GPU系统架构从总体上也分为CPU和GPU运行的两部分。其中CPU部分进一步分为查询进程和数据库服务进程;GPU部分主要包括SQL操作符的kernel实现,由数据库服务进程进行加载和调用。
• 查询进程 查询进程包括两部分。第一部分由SQL查询语句请求生成,将解析后的SQL语法树与数据库schema结合起来,编译成控制数据读取和调用SQL操作符的CPU宿主程序。该宿主程序负责根据SQL查询语句逻辑,调用相应的CUDARuntimeAPI控制整个查询任务的逻辑流程。第二部分为与数据库服务进程进行IPC通信的客户端动态链接库,利用动态链接库拦截技术拦截了到CUDA动态链接库libcudart的调用,将CPU宿主程序中包含的CUDARuntimeAPI调用映射为到服务进程的IPC调用。
•服务进程 数据库服务进程通过监听Unix Domain Socket来接收查询任务端通过动态链接库发起的IPC请求,调用数据库管理层的函数进行实际的GPU查询任务执行和资源调度等任务,并将结果返回给查询任务客户端。数据库的核心管理层包含列存储数据共享、GPU硬件管理和kernel调用等核心服务的逻辑,以函数库的形式向服务进程提供数据库管理功能。
服务进程采用多线程的架构,使用独立的线程来服务不同查询任务进程的请求,以降低不同任务的相互影响,同时可以方便地支持并发查询,具有很好的可伸缩性。并且,使用多线程架构使得某一个任务的失败不会影响到系统中正在执行的其他任务,起到了查询任务隔离效果,同时系统的整体逻辑也更加清晰。
2.2 系统设计与实现
本节将详细介绍HyperQx-GPU系统中两个核心功能——共享CUDAContext和共享数据库列存储数据的设计与实现,并阐述该实现方式的优势。
2.2.1 共享CUDAContext
在数据库系统运行的所有查询任务间共享服务进程中的CUDAContext,用于发起所有的GPU调用,是HyperQx-GPU系统的核心设计之一。该设计使得查询任务的CUDARuntimeAPI调用能够被数据库服务进程统一管理,节省了每个查询任务进程需要单独创建CUDAContext的开销,提高了GPU的整体资源利用率。
HyperQx-GPU服务端进程初始化时会创建一个CUDA Context,作为整个数据库系统生命周期中,调度GPU资源的全局唯一环境。当查询任务启动时,由于其CUDA Runtime API调用被动态链接库拦截,并不会触发CUDA隐式创建CUDA Context的机制,而是通过数据库服务进程使用全局唯一的CUDA Context,节省了每个查询进程单独创建所消耗的时间。
为了使每个查询任务进程之间的CUDARuntime-API调用互不阻塞,服务进程在启动每个查询服务线程时,会在CUDAContext中创建一个单独的stream,用于发起该查询进程请求的GPU调用。不同stream上进行的CUDAAPI调用不会相互阻塞,会被GPU并发调度执行,因此可以同时进行不同查询任务的PCIe数据传输和kernel调用,充分利用GPU资源。
2.2.2 共享列存储数据
HyperQx-GPU系统的另一个核心设计是实现了跨查询任务的列存储数据共享机制:多个查询任务如果使用了相同的列存储数据,服务进程会根据当前的系统状态决定通过PCIe总线传输数据到GPU内存或者复用已经存在于GPU内存的数据。下面将详细介绍该机制的行为和实现。
服务进程在初始化时,会将数据库的列存储数据预加载到内存,并生成数据表中列的名称到内存地址空间的映射表。当查询任务进程需要访问特定列的数据时,会通过客户端动态链接库进行IPC请求,服务进程则根据请求中的数据表名和列名,返回该列对应的内存地址作为后续操作的句柄。由于列存储数据只存在于服务进程的内存地址空间,因此查询任务进程无法通过该地址直接访问或修改数据库的列存储数据,起到了隔离效果。
当查询任务发起列存储数据从CPU内存到GPU内存的传输请求时,服务进程会查看当前映射表中该列的使用情况。若该列尚未被使用过,则分配相应的GPU内存空间,将该列存储数据通过PCIe总线传输到GPU内存,然后将映射表中该列的使用进程数设置为1,并返回GPU内存地址给查询任务进程。若该列存储数据已经存在于GPU内存中,这时候将映射表中该列的使用进程数加1,然后直接返回该列存储数据的GPU地址。该查询任务中,后续对该列的使用便可以直接使用已经存在于GPU内存的列存储数据,达到了共享列存储数据的目的,节省了PCIe传输开销。当查询任务结束时,服务进程会从列存储数据映射表中将该查询任务用到的所有列存储数据减去1。极端情况下,当GPU内存空间不足时,若某个列存储数据的使用进程数为0,则该列存储数据占用GPU内存空间可以被暂时释放,之后再次使用时再重新传输到GPU内存。
通过上述的列存储数据共享机制,HyperQx-GPU系统节省了每个查询任务需要进行的列存储数据的PCIe传输,提升了系统的整体性能。
2.3 系统执行流程
本节以一个具体的SQL查询为例,详细描述HyperQx-GPU系统处理查询请求的主要执行流程,从而展示系统各个功能模块之间的关系和交互行为。如下流程描述中,编号由小到大表示时间顺序。
(1) 启动数据库系统服务进程,该进程会创建CUDA Context,并根据启动参数datadir,修改文件夹预加载列存储数据到系统内存,然后监听查询请求。(2) 用户向数据库系统提交了如下的SQL查询语句:SELECTSUM(lo_extendprice*lo_discount) AS revenue FROM lineorder,ddate WHERE lo_orderdate=d_datekey AND d_year=1993 AND lo_discount>=1 AND lo_discount<=3 AND lo_quantity<25。(3) 数据库查询前端模块先将SQL字符串解析成SQL语法树,然后结合数据库表的schema生成包含SQL操作符对应kernel调用的CPU宿主程序代码,代表查询任务的实际逻辑——在本例中会生成列扫描过滤和表之间的哈希连接等kernel调用。由SQL生成的代码被编译成可执行文件后,将LD_PRELOAD环境变量设置为数据库客户端动态链接库的路径,然后执行该文件,启动查询任务进程。(4) 查询任务进程发起的CUDARuntimeAPI调用被客户端动态链接库拦截,转化成到服务进程的IPC请求。(5) 服务端接收到新的查询任务进程的IPC请求后,创建新的服务线程处理来自该进程的后续请求。该服务线程会不断解析来自同一个查询任务进程的请求消息体,通过数据库核心管理层模块执行相应的资源管理和kernel调用等操作,并将结果通过IPC机制回传给查询任务进程。在本示例查询中,服务进程会保证kernel执行前,lineorder表中用到的4列数据和ddate表中的2列数据已经被传输到了GPU内存。如果同时发起该SQL语句的两个查询请求实例,后到的请求会复用前一个请求已经传输到GPU的列存储数据,而不进行实际的PCIe数据传输。(6) 查询结果(包括查询中产生的宿主程序需要的临时结果)会通过IPC回传给动态链接库,进而返回给查询任务进程。(7) 查询进程完成查询时,向服务进程发起退出请求,服务进程结束相应的服务线程。
3 实验设计与测试
3.1 实验环境
实验所用工作站搭载开启Hyper-threading的18核2.1 GHz Intel XeonE5-2695 CPU,和32 GB DRAM系统内存。实验使用的GPU为NVIDIA TITAN X,包含12 GB内存,以及3 584个时钟频率为1 531 MHz的计算核心。该系统的SQL操作符kernel代码和其余模块代码使用NVIDIACUDA Toolkit 9.0和GCC 6.1.0工具链进行编译。工作站运行的操作系统为CentOS Linux release 7.4.1708,Linux内核版本为3.10.0。
3.2 实验基准数据集与实验设计
本实验使用的数据集为MultiQx-GPU采用的标准测试基准数据SSB(Star Schema Benchmark)[12],其中包括13条SQL查询语句和生成的数据库数据。该数据集基于TPC-H测试基准并加以修改,在数据库相关研究中被广泛运用于测试实际查询负荷状态下的数据库系统性能。实验使用的数据库数据由SSB的数据生成工具dbgen生成,并预处理成MultiQx-GPU中使用的列存储格式,即每个表的每个列会被单独存储为一个文件。若表中包含记录数过多,每个列存储文件会包含多个数据块,最终被系统分批载入GPU处理。生成数据时,使用10作为规模放大参数(scalefactor),最终生成的数据表中大约包含6千万条记录,占用磁盘空间为4.8 GB。实验使用的查询任务共由13条SQL查询语句组成。由于实验目的是测试系统的核心模块性能,为了排除SQL语句的解析和编译时间,所有SQL查询语句均被预先编译成可执行的查询任务程序。实验开始时,所有列数据均被预先加载入内存,以避免查询过程中产生不必要的磁盘到内存的数据传输。同时,实验设定所有列存储数据和查询任务执行时产生的中间结果均能在GPU内存中同时存在而不超出内存空间总量。
实验主要测试内容为验证共享CUDAContext和共享列存储数据机制带来的系统性能提升。参照MultiQx-GPU,本实验所采用的吞吐量指标为加权吞吐量,定义如下:

3.3 吞吐量测试
本实验使用MultiQx-GPU系统性能作为基准,采用查询任务两两并发(包括两个相同查询任务并发的情况)的方式,测试HyperQx-GPU系统在共91个(互不相同并发查询组合78个,相同并发查询组合13个)查询任务组合并发执行情况下的相对吞吐量。由于单独执行一个查询所用时间较短,且启动进程等操作会给系统带来开销,有可能在第一个查询任务快结束时,第二个查询任务才开始执行。为了保证实验进行时每组中的两个查询能同时执行,本实验实在两个进程中重复串行地执行两个查询任务,以一次查询任务执行时间内的平均相对吞吐量作为最终的实验结果。实验结果数据如图5和图6所示。

图5 HyperQx-GPU相对吞吐量提升
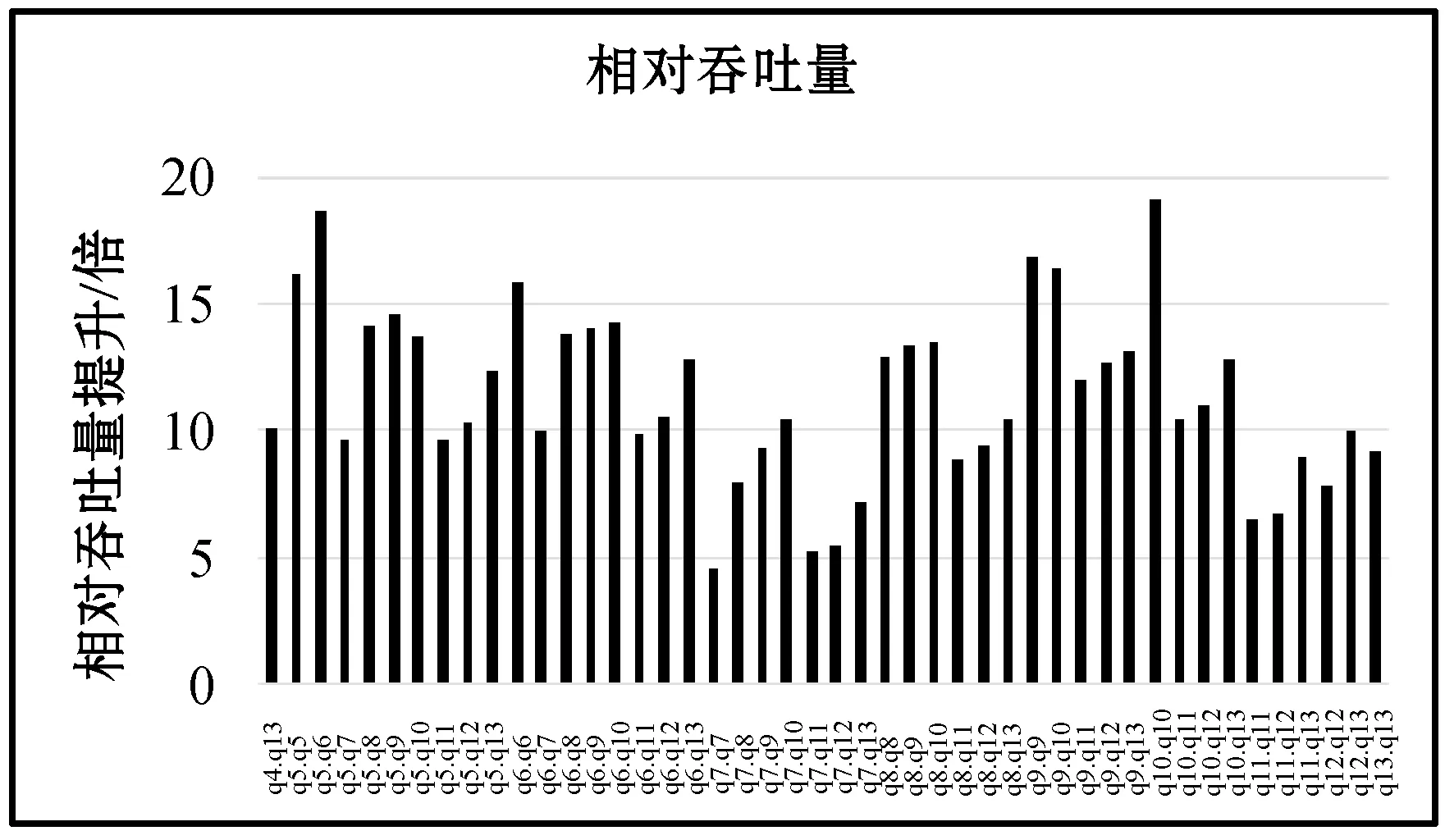
图6 HyperQx-GPU相对吞吐量提升
从图5和图6所示的实验数据可以看出,在HyperQx-GPU系统的新架构下,系统在查询任务两两并发执行的情况下,其查询请求处理的相对吞吐量平均达到了MultiQx-GPU系统的12.0倍。其中最低的查询组合为q7和q7并发执行,相对吞吐量达到4.5倍,而最高的查询组合为q10和q10并发执行,其相对吞吐量能达到19.0倍。本相对吞吐量测量结果表明,与MultiQx-GPU系统相比,HyperQx-GPU系统的性能提升非常明显。
为了进一步验证导致HyperQx-GPU系统性能提升的独立因素,下列两组实验将进一步验证和分析共享CUDAContext和共享列存储数据两项改进技术分别带来的系统吞吐量提升效果。
3.4 共享CUDAContext性能提升验证
在MultiQx-GPU系统架构设计中,每个查询任务进程使用CUDARuntimeAPI控制查询逻辑时,会在第一次调用RuntimeAPI的时候隐式地创建CUDAContext。本实验测试MultiQx-GPU和HyperQx-GPU系统(关闭列存储共享功能)执行单个查询任务的时间。实验数据如图7所示。

图7 MultiQx-GPU和HyperQx-GPU关闭共享列数据对比
根据实验数据,HyperQx-GPU利用共享CUDA Context机制,与MultiQx-GPU相比,平均性能提升(减少执行时间)为75.0%。其中提升最多的为q3查询,减少执行时间为79.6%;最低为q11查询,减少执行时间为68.5%。因此,在服务进程中使用全局唯一的CUDAContext进行GPU资源调度,能够节省在每个查询进程启动时的CUDA Context创建开销,使GPU更多地处于执行计算任务的状态,从而提升系统的查询请求响应速度和吞吐量。
3.5 共享列存储性能提升验证
为了验证共享列存储技术带来的系统相对吞吐量的提升效果,本实验测试了全部的13个SQL查询语句在HyperQx-GPU系统中分别在开启和关闭列存储数据共享功能情况下,查询任务在PCIe总线数据传输过程上花费的时间。本实验采用串行(非并发)的查询执行情况,以排除其他因素对系统性能的影响。实验结果如图8所示。

图8 HyperQx-GPU共享与不共享列存储数据情况下PCIe总线数据传输时间对比
从实验结果数据中可以看出,支持列存储数据共享机制的HyperQx-GPU系统能够大幅地减少PCIe数据传输消耗的时间。其中减少时间最多的查询为q2,减少了98.2%;减少时间最少的查询为q4,减少了96.4%,平均减少的PCIe数据传输消耗时间为97.2%。实际执行查询任务时,HyperQx-GPU系统能够根据系统中实时运行的所有查询任务的信息,重复利用已经传输过的数据库列存储数据,从而提升系统吞吐量。该实验证明,共享列存储数据的机制几乎能够消除查询任务执行时的PCIe数据传输瓶颈,为进一步的系统优化提供了有力支持。
4 结 语
本文发现并分析了已有GPU数据库系统均存在的GPU整体资源利用率低的缺陷。在此基础上,本文提出并实现了HyperQx-GPU系统。该系统设计并实现了新的软件架构,通过共享CUDAContext节省了查询任务执行时间,使用共享列存储数据方案减少了查询任务中的PCIe数据传输量,优化了GPU资源利用率。本文通过实验测试,分析了以上两个关键技术分别带来的系统性能提升。实验结果表明,HyperQx-GPU系统在MultiQx-GPU系统的基础上,提升GPU数据库处理并发查询请求的平均相对吞吐量达到了12.0倍。
猜你喜欢
电子技术与软件工程(2019年2期)2019-11-30
商品与质量(2019年34期)2019-11-29
中国外汇(2019年20期)2019-11-25
中国外汇(2019年8期)2019-07-13
计算机系统应用(2019年3期)2019-03-11
电子制作(2019年24期)2019-02-23
数码设计(2018年10期)2018-12-29
科技视界(2016年3期)2016-02-26
民主与科学(2014年3期)2014-02-28
中国信息化·学术版(2013年1期)2013-05-28
