
藏语同形异音词的消歧方法研究
2018-08-17 07:10拉巴顿珠祖漪清裴春宝
中文信息学报 2018年7期
拉巴顿珠,欧 珠,2,祖漪清,裴春宝
(1. 西藏大学 信息科学技术学院 藏文信息技术研究中心,西藏 拉萨 850000;2. 西藏民族大学,陕西 咸阳 712000;3. 科大讯飞股份有限公司,安徽 合肥 230088)
0 引言

以往在藏语语音合成技术方面,人们一直认为合成中藏语读音问题通过规则已解决,故目前很少有研究藏语语音合成中由于分词歧义造成读音不正确的问题。而藏语合成语音自然度和可懂度的测试结果表明,在藏语中,音节的声母、韵母读音错误不大,但存在声调古怪的情况。声调读法不正确往往与词性判断不恰当有关,而词性标记的不正确来源于分词的准确性。读音不正确不仅使合成语音发音不自然,甚至会改变整个句子的意思,对文本的可懂度有很大的影响。因此,如何判别其正确的读音就成为语音合成系统不得不解决的问题[7]。
字-音转换研究,是语音合成系统的前端文本分析的重要模块,其目的是将文字序列转换成相应的音标序列。首先对输入文本进行准确可行的分析,经过预处理后给语音合成后端提供必要的信息。目前藏语字音转换正确率在很大程度上取决于同形异音词的读音识别正确性,而同形异音词的读音判断又取决于藏文自动分词和词性预测的准确率。目前,汉语、英语等语言中对多音词消歧方法的研究已有不少[8-11],而对藏语的相关研究还处于初始阶段,甚至到目前为止国内外相关研究学者对藏语同形异音词方面未曾有研究工作及相关报告。
本文分以下几个方面进行论述: 第一节详细介绍了语料库的来源、数量及最终实验数据的选取情况;第二节是藏语同形异音词的构词研究;第三节对藏语同形异音词进行分类;第四节提出了基于规则的同形异音词消歧方法;第五节对基于规则的消歧方法的实验结果进行了分析;第六节给出分析的结论及今后的研究计划。
1 语料库的设计及分析
1.1 语料库的设计原则及标注方法
1.1.1 语料库的设计原则
“语料”收集是进行语音合成的基础工作,通常的做法是尽可能多地收集大规模的自然语料来为挑选训练语料和测试数据提供支撑。但为了有针对性地研究同形异音词,需要专门设计语料。设计原则是,以尽量少的语料,尽可能多地覆盖研究对象。
1.1.2 语料来源
本文主要在《西藏日报》藏文版和中国西藏新闻网藏文版等一些不同藏文网站上收集了含有法律、新闻、教育、医学、诗歌、文学等不同领域中具有代表性的语料共37万多个相对独立的句子,同时还考虑了文献的年代、地域等问题。经过自动过滤和人工校对将太长和太短、不完整的句子以及含有不常用的梵文的句子去除后剩28万多个句子,其中还有一些语料来自词典中的例句及日常生活中常用的语句,从而形成了原始语料。然后利用贪心(greedy)算法进行筛选,从28万多原始语料中挑选出含有140个同形异音词的92 229个句子,并对语料进行反复的优化(包括去重),最终选取最大覆盖藏语同形异音词的精炼语料共计35 890句作为训练数据及测试集,本文实验数据的具体构成情况及数量统计结果如图1所示。
本文收集各种语料时,为了更全面地描述和覆盖更多的语言现象,根据语料本身所表达的内容不同,我们主要收集整理了不同类别的句子文本。但由于各网站所发布和关注的侧重点不同,只利用一个网站无法覆盖所有类型的语料,因此,语料库的具体来源及分布存在一定的差异,本文语料库的具体构成情况如表1所示。

表1 语料的来源及数量
1.1.3 语料库的标注方法
“语料库不是任意文本的随意堆积。为了发挥语料库的作用,通常都需要对语料库进行一定的加工,进行何种加工和加工深度如何通常和应用目标相关”[12]。因此,收集和整理的语料根据不同领域中的应用需求出发。为了达到更好的数据训练及最终实验效果,我们特制定较为规范的标记方法,本文对语料库的标注方面做出以下几条统一规范。
(1) 语料库整体的规范
在信息处理领域中,很多藏文语料存在着编码不一且不同编码之间互不兼容等问题。这些问题导致语料分散资源无法共享等后果,这对语料库的设计带来了一定的困难[13]。目前有同元、班智达、桑布扎、北大方正、华光、藏文编码字符集扩充集和加央(jamyang)等近10种不同编码的藏文字处理软件。因此,为了便于对语料库进行管理、处理和共享,我们在收集各种大量文本时,将不同编码的藏文语料全部统一为ISO/IEC10646(Unicode6.2)的小字符集编码,以TXT文本格式保存。
(2) 分词和词性标记的规范
首先,利用传统的分词器对所有实验数据进行自动分词,并对每一个分词单位给出初始的词性。然后,通过规则和统计相结合的方法排除歧义。整个文本的词语切分和词性标记都以“信息处理用藏语词类标记集规范”和“信息处理用现代藏文分词规范”[4]为基础,结合藏语构词规则,再根据我们自己的实践经验,以及总结、整理发现的一些新处理规律,对基本规范进行改进、补充和调整,形成了分词和标注结合的规范。从实际文本的内容和不同应用的研究来看,考虑不同的处理侧重点,本文针对藏语语音合成系统前端文本分析中的切分和标记方面包括以下三个具体的规范。
1) 切分规范

3) 存在两种以上词性的标记规范

1.2 同形异音词的频率分析
本文以《藏汉大词典》为基础,在其所列出的常用藏语同形异音词的基础上,我们共收集整理了465个藏语同形异音词,并从372 320个句子文本中统计出了同形异音词在藏语文本中的出现频率。我们根据同形异音词的出现频率,选取了165个文本中出现频率较高的词,根据文本分析获取现代藏语文本中每个同形异音词不同读音的使用频率,最终整理出140个同形异音词作为本文研究的重点。前20个同形异音词在35 890句藏文文本中的数据统计结果如表2所示。

表2 同形异音词的出现频率(前20个词)
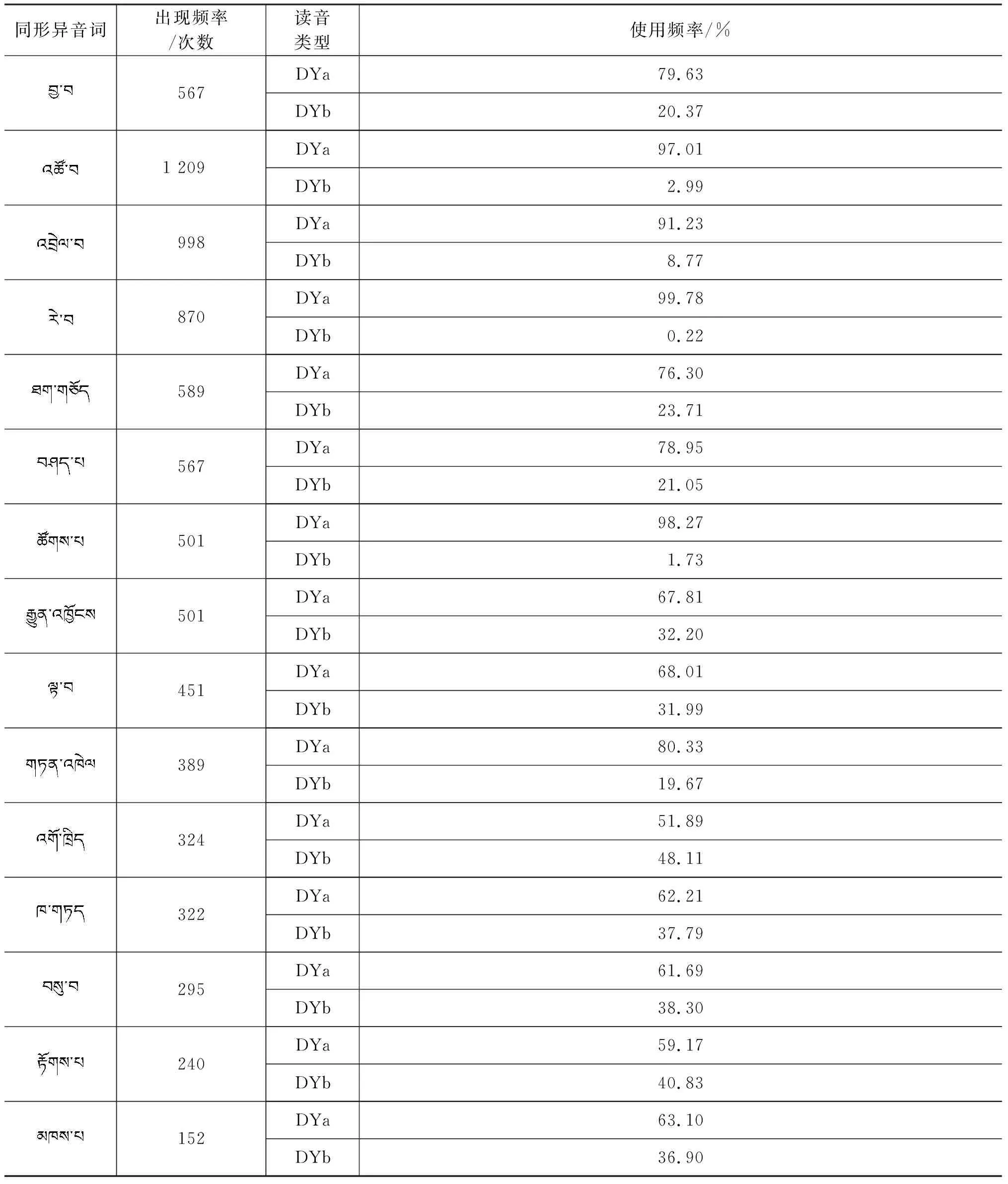
续表
2 藏语同形异音词的概念及构词研究
2.1 藏语同形异音词的界定
藏语中所谓的同形异音词,是指拼写相同而读音及词义不同的词,也可称为“同形异音异义的词”,与其他语言中所谓的多音词在本质上有很大的区别。例如,汉字中有许多多音字,多数多音字在词的层面只有唯一的读音,而多音词在具体的语境中联系上下文才能判断正确的读音。在很多不同语言中都有多音词(同形异音词),而藏语同形异音词通常并不完全是带有多音字的词语,它与双音词是两个不同的概念[10-11]。
虽藏语中基本不存在多音字的概念,但很多藏语双音节词在不同的语言环境中,由于声调的高低、强弱的不同,会发生不同的变化。因而,存在同形异音异义的词(homograph)。在计算语言学中为了与异形同音词的加以区分,被称为藏语同形异音词。
2.2 藏语同形异音词的构词形式
从藏语构词法的角度分析,藏语同形异音词有单纯词和合成词的区别。这类词的数量并不多,常用词中可能只有数百个。藏语同形异音词的构词形式只可以分成两种,一是词缀和结尾的词。即准确地判断该词后音节或是表义词缀()还是表形词缀()。因词性不同而读音不同,一般词义也不同。例如,
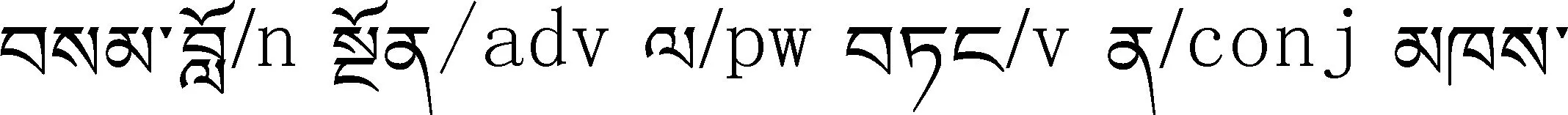

第一类同形异音词的结构与维吾尔语多音词相似,由词根和词缀构成,同形异音词词根连接构词词缀和构形词缀会构成大量的同形异音词,它们不仅发音有区别,并且改变词的意义,对合成文本的可理解度有很大的影响[15]。


第二类同形异音词是属于组合型分词歧义问题。即词的读音区别主要取决于藏文自动分词和词性预测的准确率。若不能准确地切分词语,会导致词性标记错误。然而,发出错误的读音,会改变词的意思[16-18]。两种同形异音词的所占比例如表3所示。

表3 两种同形异音词的所占比例
3 藏语同形异音词的分类
根据藏语音势论、藏语构词法及语法学,深度辨析藏语文本中同形异音词的表现形式,并在大规模语料中统计出同形异音词的出现频率和不同读音的使用频率,及同形异音词的本身特征。本文把藏语同形异音词分为四类。


表4 第一类同形异音词(T1)


表5 第二类同形异音词(T2)


表6 第三类同形异音词(T3)
第四类: (D1>>D2)词的另一种读音在文本中使用频率远大于另一个读音,并难以由上下文语境信息来确定读音的词(T4表示)。同形异音词不同读音的使用频率相差悬殊,在藏语实际文本中仅有一个读音经常出现,而另一种读音很少出现的同形异音词在所有同形异音词中也占有一定的比例。这类同形异音词主要是另一种读音的使用频率随着现代语言学的发展变化而逐渐减少,且这些词难以由上下文语境信息来判断正确的读音。如表7所示。

表7 第四类同形异音词(T4)

图2 同形异音词不同类型的数据分析结果
4 藏语同形异音词消歧方法
基于规则的消歧方法主要依据语言学规则,它具有很强的形式描述能力和形式生成能力,在自然语言处理领域中有很好的应用价值。通常做法是,通过人工方式依靠一定的专家知识来建立相对完备的规则库,在藏语TTS系统前端文本分析中可以有效地能够处理同形异音词读音判断等困难。
(1) 高频默认
在实际文本中,有些同形异音词并没有多个读音的形式出现,即在语料库中仅有一个读音经常出现。而另一种读音极少出现,并且难以由上下文语境信息来判断正确读音的同形异音词。因此,我们遵循基于真实语料的原则,采用高频默认方法来处理“第四类”同形异音词的读音,对这类同形异音词一律标注为高频音。
(2) 同形异音词所在句中的位置



(3) 同形异音词所在虚词及助词的位置
1.4 SNPs位点的选择 通过查询NCBI db SNP数据库以及phaseⅡHapma数据库并对数据库中ATG5基因相关多态性位点进行筛选,结合多态性位点所处的功能结构区域、多态性位点在我国人群中的最小等位基因频率(MAF>0.1)以及国内外学者对该基因多态性位点的功能性研究结论等影响因子,依照本研究的目的和所预期的试验效果,选取ATG5基因中rs573775、rs510432、rs6568431、rs2299863 以及 rs38043385这个多态性位点。
在藏语传统语言学中,对于虚词及一些常用助词我们是可以穷尽的,且在句子文本中与同形异音词具有一定的搭配规则。
(4) 同形异音词所在关键词的位置

(5) 同形异音词本身的信息

基于规则的同形异音词读音识别流程如图3所示。

图3 同形异音词自动标音流程图
5 实验结果分析
本文通过以上五个不同的消歧规则,对当前在藏语语音合成系统前端文本分析中出现的140个高频同形异音词读音进行了测试实验。实验数据为从9万多句语料库中挑选出的含有140个同形异音词的句子,共计35 890句。实验结果如表8所示。

表8 实验结果
实验表明,本文采用基于规则的消歧方法对140个高频同形异音词的读音识别率高达95%。经实验结果分析得出,采用的规则方法对同形异音词的消歧具有很强的分析能力,但同时也存在一定的解析困难。当然,基于规则的方法主要依赖于规则集的可靠性,若规则集不完整或整理不全等问题会直接影响最终的识别结果,同时还存在一些规则冲突的问题。

6 结束语
本文针对目前藏语语音合成系统的突出问题,深度分析了藏语同形异音词的结构及分类,并收集整理了较大规模的藏语句子文本,为进一步分析和处理藏语同形异音词的正确读音准备了素材。根据藏语同形异音词的统计和分析,结果得出: 藏语中同形异音词的出现主要问题在于词语切分和词性预测的准确性。不同的读音具有不同的词性,词义也不同。由于藏语本身受限于资源的不足,目前还无法从语义角度处理同形异音词的读音问题。
如果使用规则的方法进行同形异音词的读音分析,需对每一个词都要具体问题具体分析,这样不仅消耗大,也会发生规则冲突。因此,我们认为同形异音词的读音问题解决方法是在基于规则方法的基础上,使用以大规模的标注语料库(Annotated Corpus)为基础的统计学方法[19],即两种方法结合可实现优势互补,不仅减少算法的复杂性,而且还能获取更好的识别结果。下一步我们计划统计并扩充藏语同形异音词,尽可能地获取较大规模的标注语料库。在此基础上实现基于规则和统计结合的同形异音词自动标音方法,进一步提高同形异音词的读音准确率和工作效率。
致谢
本文在语音合成方面的工作是在西藏大学和科大讯飞公司关于藏语语音合成的研究成果基础上进行的,特别是在处理同形异音词的技术方面得到了科大讯飞多语种研发团队邵鹏飞、朱荣华、蔡明琦三位研究员的技术支持和具体帮助。关于语料库的设计思想及问题分析受益于西藏大学研究生处赵栋材副教授的指导,他为本文的研究内容提出了宝贵的意见。在此,向指导和帮助过的研发团队及个人表示由衷的谢意!
猜你喜欢
客联(2022年2期)2022-04-29
小学生学习指导(低年级)(2021年10期)2021-11-01
西藏研究(2021年1期)2021-06-09
新世纪智能(教师)(2021年3期)2021-05-21
萍乡学院学报(2020年4期)2020-12-24
小学阅读指南·低年级版(2020年1期)2020-03-30
中华诗词(2019年11期)2019-09-19
汉字汉语研究(2019年4期)2019-03-04
中华皮肤科杂志(2017年10期)2017-12-12
西藏研究(2017年3期)2017-09-05
