
基于网络搜索数据的品牌汽车销量预测研究
2018-08-27 12:41谢天保
网络安全与数据管理 2018年8期
谢天保,崔 田
(西安理工大学,陕西 西安 710054)
0 引言
近年来,我国汽车产销呈现较快增长,产销总量屡创历史新高,据中国汽车工业协会统计数据,2016年中国汽车产销均超2 800万辆,连续八年蝉联全球第一[1]。据车主之家网站提供的数据显示,2009~2016年我国销量排名前十的品牌汽车占比高达55.84%,对于我国汽车消费者而言,品牌效应十分显著。但是汽车生产厂商追求规模效应时存在一定的盲目性,导致产能过剩的问题日益凸显。在严峻的形势下,汽车生产企业应认真分析市场未来的需求量和可能存在的变化趋势,合理规划生产计划,采用以销定产的生产策略。因此如何准确地预测销量,对于汽车生产企业研究市场行情及时调整生产经营策略有着极其重要的意义。随着人工智能的出现以及基于网络数据的预测研究的广泛开展,将网络搜索数据应用于汽车销量的预测已成为研究的热点。
传统的汽车销量预测研究采用的主要方法有灰色系统理论[2]、时间序列模型[3]以及人工神经网络[4]等,但这些研究采用的数据时间粒度比较大,研究对象大都集中于我国汽车年度总销量的预测,研究成果难以应用推广。文献[5]在建立网络关键词搜索数据与汽车销量理论框架的基础上,使用自动推荐技术选取关键词并进行关键词合成,然后针对不同价格区间的汽车销量与相应合成指数进行建模预测且平均绝对误差百分数均不超过4%,但是同一价格区间内包含众多不同品牌车型,预测结果无法提供有价值的决策支持;文献[6]、文献[7]针对大众途观和宝马汽车销量进行预测研究,通过人工方式进行网络数据关键词的选取,发现加入百度关键词作为解释变量的模型相比传统的ARMA模型,预测精度有了一定程度的提高;文献[8]利用经济变量和谷歌在线搜索数据建立预测月度汽车销售数据的多变量模型,结果表明包括谷歌搜索数据在内的模型在统计上超过了大多数预测领域的传统模型;文献[9]提出了一种搜索数据关键特征选取方法,但是该选取方法最终仅仅保留了相关性最高的一个关键特征,难免会造成有效信息的损失。
综上所述,目前的研究存在的问题包括研究对象与时间粒度选择不当,网络数据特征分析及选取的科学体系暂未形成,传统模型预测性能具有局限性。本文拟基于网络搜索数据,将品牌汽车销量作为研究对象,时间粒度选取为月度,将传统相关性分析与基于LASSO的特征选择方法相结合,筛选出最优的关键特征数据,然后应用多种机器学习算法建立品牌汽车销量的预测模型,从而实现针对性更强、更准确、更具有应用价值的品牌汽车销量的预测。
1 网络搜索数据关键特征选取
本文选取“大众”、“本田”、“奥迪”三个比较有代表性的品牌汽车作为研究对象,收集了2011年1月~2017年12月期间各品牌汽车月度销量数据。根据消费者购买决策过程,消费者在产生购车需求后,大多数购车消费者都会通过搜索引擎从网络中快速获取到所需要的信息,而关键词搜索是在线信息搜索时最常用的策略,所以将用户搜索关键词作为网络搜索数据的关键特征。本文选择国内应用最为广泛的百度搜索引擎的百度指数作为网络搜索关键词数据来源。下面以“大众”品牌汽车为例进行详细说明。
1.1 关键词的选取及拓展
本文采用文本挖掘的方法,结合汽车品牌、热销车型信息、车型配置指标数据等各个方面的信息,对网络上与大众品牌汽车相关的新闻、论坛文章、点评、分享交流等信息进行查找收集,剔除掉一些无用信息后,再使用NLPIR汉语分词系统对原始文本进行关键词提取,得到关键词列表及其权重,选定其中权值较高的“大众”、“大众4S店”、“大众SUV”、“大众POLO”、“大众商务车”等为初始关键词。然后围绕选取的初始关键词综合使用了长尾关键词拓展法、站长工具以及网页相关搜索推荐等方法拓展出数量更多的关键词,剔除重复或者有歧义的关键词后建立了一个包含276个关键词的初始词库。
1.2 关键词搜索指数相关性分析
首先利用网络爬虫工具获取初始词库中各关键词相同时间段内月度搜索数据,针对关键词搜索数据进行预处理(剔除缺失数据超过6个月或者搜索指数过低的关键词数据),最后得到118个符合要求的关键词搜索数据。但是并不是每个关键词搜索数据都与实际销量存在相关关系。所以本文首先应用传统相关性分析方法通过判定各个关键词搜索数据与大众品牌汽车销量的Spearman秩相关系数,筛选出相关系数大于0.5的 搜索关键词(显著相关),共计37个。然后采用时差相关分析确定上一步筛选出的关键词搜索指数与大众品牌汽车销量的时滞阶数均处于滞后1~3阶的范围(网络搜索行为是一种即时性行为,而购买汽车作为重大经济决策,消费者一般都会在做出购买决策前几个月就开始搜索相关的信息)。
现有研究针对相关性分析结果一般有两种处理方法:第一种是直接选取相关性最高的作为唯一的解释变量;第二种是利用指数合成方法将合成后的关键指数作为解释变量。两种方法难免都会造成有效信息的损失。但是若保留所有的解释变量,解释变量之间也可能存在多重共线性,所以本文在相关性分析基础上应用LASSO算法来进一步分析与选取特征[10]。
1.3 基于LASSO的特征选取
在高维数据变量选择方法的研究领域中,Tibshirani在1996年提出普通线性模型下的Least Absolute Shrinkage and Selection Operate(LASSO)算法,LASSO算法就是在损失函数后面加上惩罚项(即L1正则项),L1正则项可以约束方程的稀疏性,这种稀疏性即可应用于特征的选择,这种方法与传统的算法相比优点在于可以在进行连续的变量选择的同时进行模型参数估计[11]。而且LASSO算法可以有效解决解释变量多重共线性的问题,使得后续建立的模型拥有稳定的性能。
针对上一节相关性分析结果,采用R语言中的glmnet包实现的LASSO算法对关键词搜索数据进行分析与特征选取。通过分析模型的Lambda解路径图可以发现,随着惩罚的力度加大,越来越多的变量系数会被压缩为0,而那些在Lambda比较大时仍然拥有非零系数的变量就是越重要的解释变量[12-13]。本文选取平均绝对误差(MAE)作为评价指标,通过交叉验证得到最优Lambda值,模型MAE与Lambda之间的关系如图1所示。
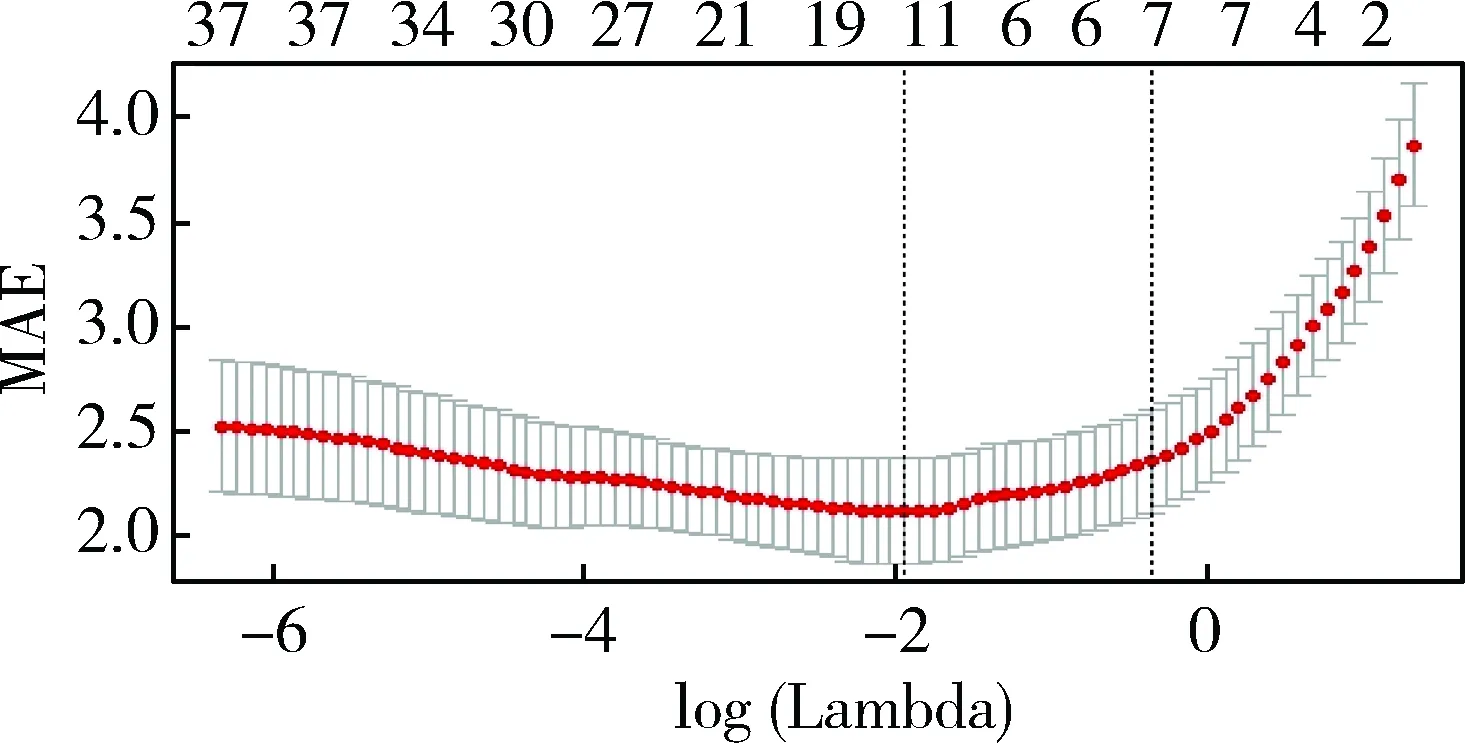
图1 Lambda与MAE关系图
图1中左侧虚线是最佳Lambda取值(lambda.min=0.143 065),也就是模型MAE最低时的Lambda取值,此时非零系数的变量个数仅为12个,相比之前37个关键词特征数据已经大幅度地缩减。通过查看coefficients参数可以得到模型的Intercept为5.630 547 963 2,所选取的关键词变量及其所对应的参数估计如表1所示。
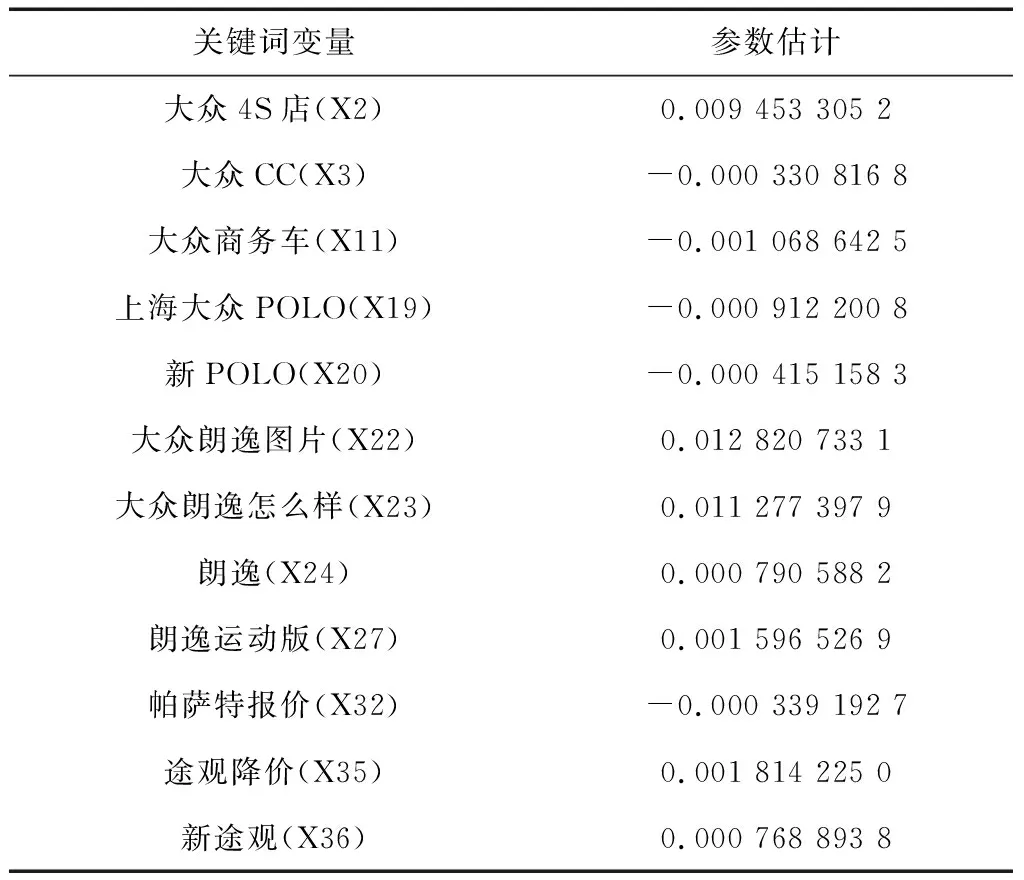
表1 模型参数表
至此,本文首先进行关键词的选取及拓展,然后将传统相关性分析与基于LASSO的特征选择相结合应用于搜索数据关键词选取,最终选出针对“大众”品牌汽车的12个网络搜索数据关键特征。使用同样的方法,筛选得出“本田”及“奥迪”品牌汽车对应的网络搜索数据关键特征分别为12个和13个。
2 实验分析与讨论
通过LASSO算法的应用有效地解决了解释变量多重共线性的问题,同时在特征选择的过程中也得到了LASSO线性回归模型参数估计,但是该模型及现有研究大都使用基于最小二乘法的线性回归模型,都无法解决异方差性及解释变量与被解释变量非线性关系的问题,这就会增加系数估计值的方差,结果造成系数估计值不稳定,对异常值非常敏感,继而会严重影响回归线,最终影响预测值的准确度[14]。所以本文又选取了两种非线性的机器学习算法建立模型并进行详细的对比分析。
本文选取2011年1月~2016年12月的数据作为训练集,将2017年12个月的数据作为测试集,采用R语言针对“大众”、“本田”、“奥迪”品牌汽车的销量预测建立了支持向量回归模型及随机森林模型,按照MAE值最小原则应用网格搜索法(GridSearch)进行模型参数调优,同时针对三个品牌建立传统的时间序列预测模型——自回归积分滑动平均模型(ARIMA)进行综合比较分析。为了有效和直观地衡量不同模型的预测能力,本文选取均方根误差(RMSE)、平均绝对百分比误差(MAPE)两个指标来评估预测结果,各模型测试集预测结果如表2所示。
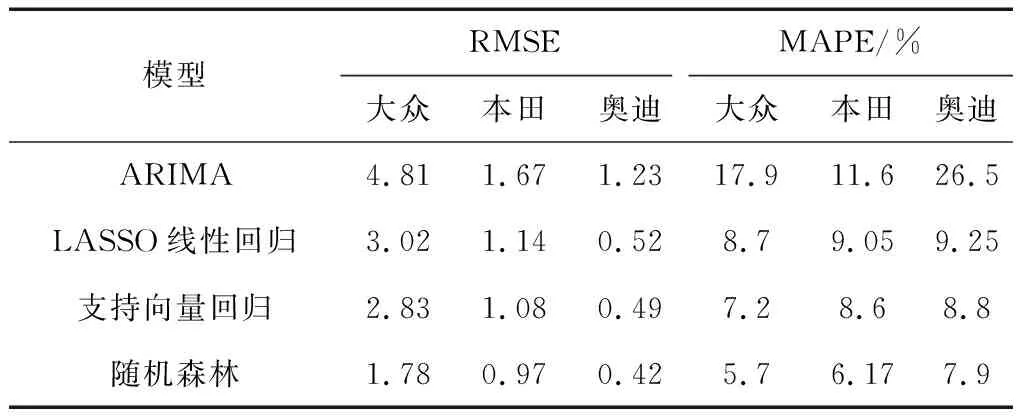
表2 各模型预测结果比较
从表2可以看出,无论从RMSE还是MAPE来说,机器学习模型的预测效果均有显著优势,相比传统的时间序列ARIMA模型大幅度提高了预测准确度,而且从MAPE指标结果来看,ARIMA模型对于不同品牌汽车销量预测差异非常大(奥迪比本田高了近15%),机器学习模型预测性能比较稳定。所有模型中性能最优的是随机森林模型,预测平均误差为6.4%,比ARIMA模型降低了12.2个百分点,相比文献[15]、[16]对大众及奥迪相同品牌汽车月度销量预测的MAPE分别降低了2.81%和4.63%,预测精度有了显著提升。从本质上分析,网络搜索数据与对应品牌汽车销量之间的关系并不是单纯的线性关系,其中非线性关系的程度应该大于线性关系的程度,因而两种非线性机器学习模型的预测更为精确。
以“大众”为例展示各模型测试集的预测值与实际值对比如图2所示。其中可以看出LASOO线性回归模型(图(b))及支持向量回归模型(图(c))的预测精度明显优于ARIMA模型(图(a)),ARIMA模型虽然能够预测销量的基本趋势,但整体预测效果比较差,而且以上三种模型的峰值敏感度都较低,即对峰值的预测误差均比较大。通过与随机森林模型(图(d))进行对比,可以清晰直观地看出,随机森林模型与其他模型相比在峰值预测准确度上有明显差异,显然随机森林模型对于峰值和整体预测的结果都更精确。由此可以得出结论,针对汽车品牌粒度的月度销量预测问题,建立基于网络搜索数据关键特征的随机森林模型是一种切实可行的方案。
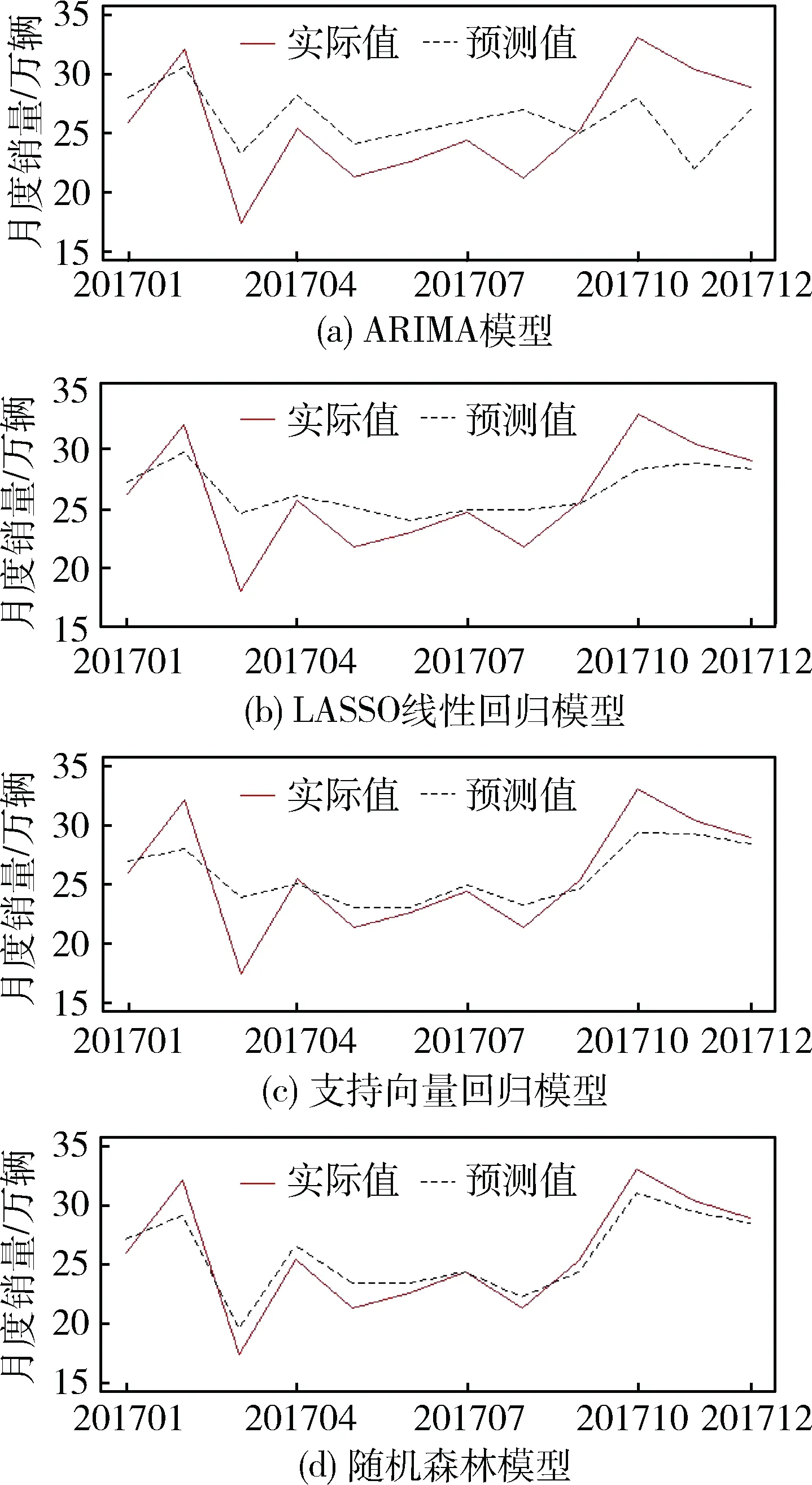
图2 各模型测试集预测对比图
3 结论
本文以品牌汽车销量为研究对象,通过关键词的选取及拓展,将相关性分析与基于LASSO的特征选择相结合,最终筛选出针对不同品牌汽车的网络搜索数据关键特征,在解决多重共线性及减少过拟合的基础上保留最有效的数据,然后分别建立了传统时间序列模型及三种机器学习模型,通过对实验结果进行分析,发现机器学习模型的预测效果均有显著优势,其中随机森林模型预测性能最优。本文提出的基于网络搜索数据的预测方法可以利用前期网络搜索数据预测后续汽车销量,而相应品牌的汽车生产厂商可以根据预测结果及时调整企业的生产和营销策略。模型的可靠性检验及推广应用是接下来的研究方向。
猜你喜欢
小学生学习指导(高年级)(2021年4期)2021-04-29
汽车观察(2021年11期)2021-04-24
汽车观察(2021年11期)2021-04-24
汽车与安全(2020年8期)2020-11-13
汽车与安全(2020年7期)2020-10-09
河北理科教学研究(2020年2期)2020-09-11
汽车与安全(2020年5期)2020-08-28
汽车与驾驶维修(汽车版)(2020年5期)2020-07-24
汽车与驾驶维修(汽车版)(2020年5期)2020-07-24
汽车与安全(2020年4期)2020-06-23
