
非对称信息在链接预测中的应用
2018-08-28 08:52郝志峰徐圣兵
计算机应用 2018年6期
谢 锐,郝志峰,刘 波,徐圣兵
(1.广东工业大学自动化学院,广州510006; 2.广东工业大学计算机学院,广州510006;3.佛山科学技术学院数学与大数据学院,广东佛山528000)
(*通信作者电子邮箱25457855@qq.com)
0 引言
链接预测是揭示网络演化内在规律的关键技术之一[1]。链接预测算法是基于观察到的链接关系、节点的属性和网络的结构属性来估计节点之间存在链接关系的可能性。它可以分为两类:一种是预测缺失的链接或者存在但未知的链接,另一种是预测可能存在或出现在进化网络中的未来的链接[2-3]。因此,理想的链接预测方法不仅可以应用于现有的链接可靠性的分析,还可以对缺失的或将来可能出现的链接进行预测。近年来,由于其在现代科学中的理论价值和实践意义,链接预测的研究引起了国内外很多研究机构和学者的关注[2-3],提出了应用于不同领域的链接预测方法,如用于社会基础生活的社会网络进化[4]、用于广告和朋友圈等的推荐系统[5]、虚假链接检测[6]等。
在上述的各文献中,链接预测算法主要分为两大类:其中,一类是基于马尔可夫链[7]和机器学习[8]原理的,这些算法一般先提出适当的偏好假设,然后设计相应的损失函数或目标函数,再对两个节点进行优化;但此类算法计算量大,难用于大规模网络的链接预测。另一类是基于节点相似性来判断[9-12],这类算法计算简单,认为如果两个节点相似,则它们之间更可能存在链接关系。根据相似性进行链接预测的基本问题是如何准确计算节点之间的相似度[2-3]。
此外,还有基于矩阵分解的链接预测方法等,而基于节点相似的链接预测算法简单、准确度高,是链接预测的重要方法,但目前的节点相似性度量算法中均认为节点之间的相似性是对称的,并未充分考虑节点个体的所有邻居与节点间共同邻居(Common Neighbor,CN)之间的非对称关系。本文在节点相似度的基础上,充分考虑利用节点间的非对称信息,对相似度算法进行改进,从而提高链接关系预测的准确度。
1 节点相似性度量
考虑一个无权无向的简单网络G(V,E),不存在多链接和自我链接情形。V是节点集合,E是边的集合。对于任意节点对x,y∈V,可以通过计算一个相似值来度量节点x和y之间是否存在边的可能性。一般来说,如果两个节点在拓扑或其他属性中具有一些共同的重要特征,则认为它们是相似的。
目前,节点相似度的度量方法很多。最简洁直接的方法是利用网络结构相似信息进行度量,被称为结构相似性[2-3],它又可以分为节点相似性[10-15]、路径相似性[16]和混合相似性[16]。其中,一些相似性度量方法是基于局部结构信息[10,13],称之为局部相似性,此类方法偏好度数大的节点,不利于度数小的节点。为了解决这个问题,研究者提出了诸如Jaccard指标[17]和 Salton 指标[18]等改进方法来克服这个缺点。另一些方法是基于全局结构信息进行相似性度量,包括Katz指标[16]、Simrank 指标[19]等,称之为全局相似性,这些方法在估计节点相似度方面也具有较好的结果,但时间复杂度高,计算效率低,且获取足够节点的内容和属性信息成本高、难度大,导致此类方法的相似性度量困难。此外,除了这些基于节点对相似性的预测方法外,还有基于似然分析的链接预测方法,包括层次结构模型[20]、随机分块模型[21]和闭路模型[22]等。
相似系数的概念常用来反映变量或对象的相似程度,在讨论这些问题时认为变量或对象的相似程度是对称的,变量或对象之间的相似系数是相同的。同样,在基于节点对相似的方法中,均认为两个节点相似,则相似程度是相同的,但实际上,相似节点间彼此的相似程度不一定是相同的。考虑如下甲和乙两个对象的兴趣爱好问题:甲的兴趣为足球、篮球、乒乓球、羽毛球、音乐、美术、唱歌,相应的分值分别为10、8、8、5、4、2、1;乙的兴趣为美术、唱歌、阅读、旅游、乒乓球,相应的分值分别为 10、8、8、4、1。
基于共邻的相似性度量方法建立在有共同邻居(特征)的基础上,认为两者共同邻居越多,两者之间越相似。由于甲和乙都喜欢乒乓球、美术和唱歌,有3项相同的兴趣爱好,则基于共邻的方法认为甲和乙是相似的,这种相似信息是对称的且只取决于相同兴趣爱好的项目数,但它忽略了对象兴趣爱好的广泛性(兴趣爱好数)、相同兴趣爱好集合的总体喜欢程度(总分值)和每个兴趣爱好的喜欢程度(分值)。例如,甲有7项兴趣爱好,乙有5项兴趣爱好,相同兴趣爱好数与个体总兴趣爱好数比值分别为3/7和3/5,即相同项目对于各自的兴趣爱好的广泛性的比值是不同的,它们是非对称的;对于两者之间的共同兴趣爱好集合C={乒乓球、美术,唱歌},甲的总的喜欢程度是11,乙的总的喜欢程度是19,表明甲、乙对于这个兴趣爱好的集合的喜欢程度是不同的,是非对称的;若考虑乒乓球这个兴趣爱好,甲的喜欢程度是8,很喜欢;乙的喜欢程度是1,只是一般喜欢,。因此,他们对相同的一个兴趣爱好的喜欢程度也是不同的,是非对称的。从上述分析可以得到,基于共邻的相似性度量认为相似程度是一样的,即相似是对称的,本质上只考虑了相同兴趣爱好的项目数,没有充分考虑个体这些非对称信息,而这些非对称信息可以更加细致刻画两者之间的相似程度。
本文提出了非对称相似系数(Asymmetrical Similar Coefficient,ASC)概念来反映这种不同的相似信息,并结合传统的相似性度量方法,修正相似度的计算方法,应用于基于节点相似性的链接预测方法中。在本文实验中,将这种新方法与链接预测的常用方法进行了比较,包括共同邻居(CN)[23]、Adamic Adar(AA)[4]、资源分配(Resource Allocation,RA)[13]等方法,发现新的方法可以提高链接预测准确度且具有运算速度快等特点。
2 非对称相似系数
从前面的分析可以得到对象之间的相似可以认为是不同对象相对于共同特征的相似程度的反映。简单起见,先考虑共同特征数(广泛性)而不考虑每个特征的重要程度(分值),则相似性可以表达为共同特征数与对象总特征数的比值,如图1所示。

图1 集合甲和集合乙特征分析Fig.1 Characteristic analysis of set A and set B
在图1中,甲对象有8个特征,乙对象有4个特征,则甲对象对于共同的3个特征的相似值为3/8;而乙对象对于共同的3个特征的相似值为3/4,可以认为对于共同特征,乙比甲更相似;同理,相似性也可以表现为各个对象对共同特征的总体重要程度或者各个对象对每个特征的重要程度。据此,本文给出非对称相似系数来刻画对象之间的非对称信息,非对称相似系数(ASC)的定义如下:
非对称相似系数(ASC)是指在不同集合中,所有集合的共同元素与某一集合的总元素的比值。即非对称相似系数反映的是相对于具体集合而言,共同元素所占的比值。
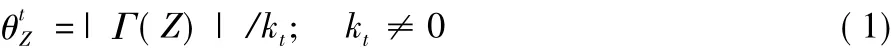
在网络拓扑中的含义为:Z设定为节点集合V;t为V中的某一节点;Γ(Z)为节点集合的共同邻居;kt为节点t的度。在如图2所示的简单网络中,A节点的邻居是Γ(A)={B,C,D},E节点的邻居是Γ(E)={B,C},节点A和E的共同邻居是Γ(A)∩Γ(B)={B,C},根据相似系数的定义,节点A对节点E的相似系数则为2/3,而节点E对节点A的相似系数为1,即两者之间的相似系数是不同的,反映了两个节点间的相似程度是不同的。
一般认为,无向无环图中的相似性是对称的。然而,从前面的分析来看,这种相似一般情况下相似程度是不同的,即相似中包含非对称信息,只有当这两个节点的度相等时,相似程度才相等,即相似对称性只是一个特例。考虑到相似的非对称信息,本文对一般的相似性度量方法进行修正,以更符合实际情况,因此相似性的修正定义如下:

其中:sxy是一般相似性度量方法得到的对称相似值;是非对称相似系数(ASC);是考虑相似的非对称信息后得到的相似值。

图2 简单网络Fig.2 Simple network
3 基于非对称信息的相似度量
在基于网络结构信息的相似算法中,共邻指标(CN)、Adamic Adar(AA)指标和资源分配(RA)指标都是均匀地为所有邻居节点分配权重,并将邻居节点的数量视为链接相似性的因素。它们可以简洁地度量节点之间存在链接的可能性,但是没有充分考虑节点间的相似程度或其他因素;因此,可以对其进行修改,以更好地度量节点之间的相似度,进而更好地判断节点之间是否存在链接关系。
3.1 CN 指标修正


式(5)的结果表明,传统的相似对称的情况是相似系数为1的特例,即不考虑相似程度的特例,而本文提出的非对称相似程度的方法更能反映实际节点之间的相似性,此方法更进一步可以扩展到考虑节点及节点属性的整体对象相似程度的度量。
3.2 AA 指标修正
AA指标对每个节点均匀分配权重,以共同邻居节点度的对数的倒数为权重值,并以这个值定义为节点间的相似值。考虑到节点间的不同相似程度,本文方法对AA指标可以采用非对称相似系数(ASC)进行修正,定义如下:

3.3 RA 指标修正
RA指标从资源的角度出发,将共同邻居节点作为传递的媒介,以共同邻居节点度的倒数为相似值,考虑到节点间的不同相似程度,本文方法对RA指标可以采用非对称相似系数(ASC)进行修正,定义如下:
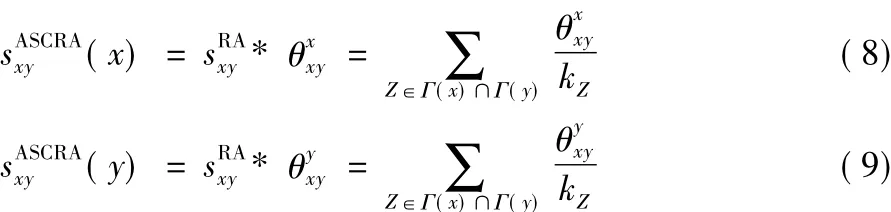
3.4 考虑非对称信息的相似性
在传统的对称相似性度量中,变量或对象之间的相似是对称的,只有一个相似值;而考虑变量或对象之间的非对称信息后,相似是非对称的,在这种情况下,变量或对象之间的相似度量应考虑方向性,因此,考虑非对称信息后的相似性是具有方向性的。
在本文的讨论中,判断两个节点之间的非对称相似时,应指出节点之间的相对方向性。例如(x)x) 和(x)是考虑非对称相似系数时节点x相对于节点y的相似值;(y)(y)和(y)是考虑非对称相似系数时节点y相对于节点x的相似值。
4 实验结果与分析
为了分析本文提出的算法的性能,本文在4个真实数据集上与参考文献[25]中涉及的8种算法进行了比较。本文实验环境为 Windowns 7 64 位、CPU i3-2350M@2.3 GHz、6 GB内存,Matlab 2014为实验仿真工具。实验中,将数据集E随机划分为训练集ET和测试集EP两部分,且E=ET∪EP,ET∩EP= 。对于节点对x,y∈V,采用本文提出的方法和现有方法分别计算相似值sxy,将所有不存在的链接根据其相似分数sxy按降序排列,则排在最前面的链接最有可能存在。
4.1 评价指标
衡量链接关系预测算法精度的常用指标主要包括3种:受试者工作特征曲线下的面积(Area Under the receiver operating characteristic Curve,AUC)[26]、精确度和排序分。AUC侧重算法整体准确度,精确度指标侧重前L位准确度,排序分侧重所预测的边。本文采用AUC衡量链接预测算法整体准确度。AUC定义如下:

其中:n表示独立地比较了n次;n'表示在n次比较中测试集中的边的分数值大于不存在的边的分数出现的次数;n″表示在n次比较中测试集中的边的分数值等于不存在的边的分数出现的次数。式(10)的含义是,如果所有的链接预测分数都是从一个独立同分布中产生的,其准确率应该是0.5左右,因此,若算法精确度超过0.5则表明该算法执行的效果比纯粹的机会要好得多[26]。
4.2 实验数据集
为了评价基于非对称相似系数的链接预测算法的有效性,本文选择了4种类型的代表性真实数据集,并根据实验条件进行了简单抽样后进行实验,数据特征描述如下:
1)美国航空网络 USAir(http://vlado.fmf.uni-lj.si/pub/networks/data/mix/USAir97.net):该网络中的每一个节点对应一个机场,若两个节点之间有连边则两个机场之间有直飞的航班。包含332个机场和2126条航线,权重为航班频次。
2)科学家合作网络 NS(http://www-personal.umich.edu/~mejn/netdata/):网络的节点表示科学家,连边表示科学家之间的合作关系。该网络包含379个节点和914条边。
3)蛋白质相互作用网络 Yeast(http://vlado.fmf.uni-lj.si/pub/networks/data/bio/Yeast/Yeast.htm):节 点 表 示 蛋 白质,边表示相互作用关系。该网络包含2617个节点和11855条边。
4)爵士音乐家合作网络 Jazz(http://deim.urv.cat/~aarenas/data/welcome.htm):网络的节点表示音乐家,连边表示音乐家之间的合作关系。该网络包含198个节点和5 484条边。
4.3 实验结果
实验测试了本文提出的考虑非对称信息后节点相似性的链接预测算法在不同条件下的性能。在所有测试实验过程中,每个实验进行100次,AUC取平均值。
4.3.1 训练集比例不同
首先,测试考虑非对称信息后基于节点相似性的链接预测方法在数据集USAir中当训练集比例不同时AUC的表现,实验结果如图3所示。

图3 USAir数据集中AUC与训练集比例关系Fig.3 Relationship of AUC and training set ratio in dataset USAir
从图3可以看出,当训练集合的比例为0.6时,ASCCN、ASCRA和ASCAA的链接预测准确度AUC超过90%,当训练集比例0.9时,ASCCN、ASCRA和ASCAA的链接预测准确度AUC值已经达到95%以上。在另外3个数据集中也可以得到相近的结论。实验结果表明,考虑非对称信息后的基于节点相似性的链接预测算法准确性AUC的值随着训练集比例的增大而上升。
4.3.2 训练集比例恒定
基于图3所示的训练集比例不同的实验结果,选择训练集比例c=0.9,测试本文所提出的方法在不同数据集中的链接预测准确度AUC。实验测试了ASCCN指标、ASCSalton指标、ASCJaccard指标、ASCSorenson指标、ASCHPI指标、ASCHDI指标、ASCAA指标、ASCRA指标等共8个指标,实验结果如表1所示。

表1 基于相似系数的链接预测准确度AUCTab.1 AUC in link prediction accuracy based on similarity coefficient
从表1可以看出,本文所提方法在不同数据集中的链接预测准确度可以达到90%,在科学家合作网络NS数据集已经达到99%以上,说明本文所提方法在在多个数据集上均可以达到理想的预测效果,表明该方法可以适用于各种不同的数据集,满足各类应用要求。
4.3.3 与其他算法的比较
为了验证本文提出方法的有效性,根据参考文献[25]中基于共邻相似性度量的8种不同链接预测算法分别进行改进,并在4个真实数据集中分别完成了8组对比实验。实验的结果如表2所示。
从表2的实验结果可以看出,同一方法在不同数据集上的预测准确度有所不同,在NS数据集上的预测准确度最高,达到99%以上,而在USAir数据集上不同方法的预测准确度变化最大。本文提出的基于相似系数的方法在同一数据集上总体上均优于其他方法的预测准确度。
其中,相比CN算法,考虑非对称信息后的算法SCCN的预测准确度在USAir数据集上提高了0.649 8%,在NS数据集上提高了0.0202%,在Yeast数据集上提高了0.0109%,在Jazz数据集上提高了1.129 5%。在考虑非对称信息后的算法SCAA相比现有AA算法的预测准确度在USAir数据集上提升了0.2173%,而在 NS数据集和Yeast数据集上与现有AA算法相同,在Jazz数据集上预测准确度提升了0.6954%;在考虑非对称信息后的算法SCRA相比现有RA算法的预测准确度在USAir数据集上提升了0.113 1%,在NS数据集上与现有RA算法相同,在Yeast数据集和Jazz数据集上预测准确度分别提升了0.0109%和0.2572%。此外,表2所示的实验结果表明改进后算法在不同数据集上的预测准确度均获得了不同幅度的提升,排除了算法在不同数据集上准确度随机提升的可能,说明本文提出的考虑非常对称信息的链接预测算法具有稳定的准确度提高效果。

表2 算法改进前后的AUC比较Tab.2 AUC comparison before and after algorithm improvement
5 结语
本文分析了节点之间的相似程度的问题,发现节点相似性具有非对称信息,提出了考虑非对称信息后的相似性度量方法,在此基础上,设计了一种新的相似性度量方法,给出了考虑非对称信息后的基于节点相似性的链接预测新方法。在真实数据集的实验表明,所提方法可以一定程度上提高链接预测的准确性。此外,非对称信息思想也可以进一步扩展到节点重要程度、节点之间的传播等因应用中。本文所提方法的算法复杂度基于原算法复杂度O(n2),对于大规模网络处理效率不够高,后续将重点关注相似系数,探讨特征的重要程度对相似性度量的影响,并寻找降低算法复杂度的方法。
猜你喜欢
社会科学战线(2022年9期)2022-10-25
交通科技与管理(2022年8期)2022-05-07
计算机研究与发展(2022年1期)2022-01-19
计算机应用(2020年12期)2020-12-31
河北画报(2020年8期)2020-10-27
航天电子对抗(2019年4期)2019-06-02
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
文苑(2015年9期)2015-09-10
筑路机械与施工机械化(2014年2期)2014-03-01
