
BP神经网络基本原理
2018-09-03 05:43袁冰清郑柳刚
数字通信世界 2018年8期
袁冰清,程 功,郑柳刚
(国家无线电监测中心上海监测站,上海 201419)
1 引言
机器学习中,神经网络算法可以说是当下使用最广泛的算法。神经网络的结构模仿生物神经网络,生物神经网络中的每个神经元与其他神经元相连,当它“兴奋”时,向下一级相连的神经元发送化学物质,改变这些神经元的电位;如果某神经元的电位超过一个阈值,则被激活,否则不被激活。其中误差逆传播(error BackPropagation)算法是神经网络中最有代表性的算法,也是迄今为止使用最多、最成功的算法。
误差逆传播算法,简称BP网络算法,而一般说到BP网络算法时,默认指用BP算法训练的多层前馈神经网络。BP神经网络模型的拓扑结构包括输入层(input)、隐含层(hide layer)和输出层(Output layer)。本文就以最简单的BP神经网络,只包含一层隐含层为例来推导理解BP原理。
2 BP内涵
我们知道在神经网络信号的正向传(forward-propagation)中,神经元接收到来自其他神经元的输入信号,这些信号乘以权重累加到神经元接收的总输入值上,随后与当前神经元的阈值进行比较,然后通过激活函数处理,产生神经元的输出。理想的激活函数是阶跃函数:,“0”对应神经元抑制,“1”对应神经元兴奋。然而阶跃函数的缺点是不连续,不可导,所用常用sigmoid函数:,sigmoid函数及其导数如图1所示。使用sigmoid函数作为激活函数时BP网络输入与输出关系:

图1 sigmoid函数及其导数
因此BP的核心思想就是:通过调整各神经元之间的权值,将误差由隐含层向输入层逐层反传,也就是先实现信号的正向传播到误差的反向传播过程。所以BP算法的核心步骤如下:
(1)求得在特定输入下实际输出与理想输出的平方误差函数(误差函数或者叫代价函数)。(2)利用误差函数对神经网络中的阈值以及连接权值进行求导,求导原则就是导数的“链式求导”法则。(3)根据梯度下降算法,对极小值进行逼近,当满足条件时,跳出循环。
3 有监督的BP模型训练
3.1 BP训练思想
有监督的BP模型训练表示我们有一个训练集,它包括了:input X和它被期望拥有的输出output Y。所以对于当前的一个BP模型,我们能够获得它针对于训练集的误差。正向传播:输入样本—输入层—各隐层—输出层;若输出层的实际输出与期望的输出不符,则误差反传:误差表示—修正各层神经元的权值;直到网络输出的误差减少到可以接受的程度,或者进行到预先设定的学习次数为止。
3.2 具体理论推导
以最简单的BP神经网络为例来推导原理,如图2所示:假设网络结构输入层有n个神经元,隐含层有p个神经元,输出层有q个神经元。

图2 BP网络结构图
定义变量如下:
输入向量 :x=(x1,x2,…,xn)
隐含层输入向量:hi=(hi1,hi2,…,hip)
隐含层输出向量:ho=(ho1,ho2,…,hop)
输出层输入向量:yi=(yi1,yi2,…,yiq)
输出层输出向量:yo=(yo1,yo2,…,yoq)
期望输出向量:d=(d1,d2,…,dq)
输入层与中间层的连接权值:wih
隐含层与输出层的连续权值:who
隐含层各神经元的阈值:bh
输出层各神经元的阈值:bo
样本数据个数:k=1,2…m
激活函数 :f(.)
第一步,网络初始化-给各连接值分别赋值,在区间(-1,1)内的随机数,设定误差函数e,给定计算精度值ε和最大学习次数M。
第二步,随机选取第K个输入样本及对应期望输出:

第三步,计算隐含层各个神经元的输入和输出:
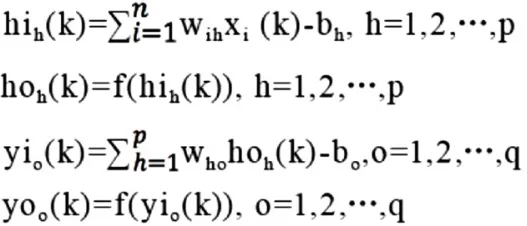
第四步,利用网络期望输出和实际输出,计算误差函数对输出层的各神经元的偏导数根据复合函数求导法则:

第六步,利用输出层各神经元的δo(k)和隐含层各神经元的输出来修正连接权值who(k):
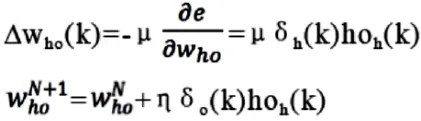
第七步,利用隐含层各神经元的δh(k)和输入层各神经元的输入修正连接权值。

特别说明,最终公式中的μ、η代表学习率,为了调整步长,防止数值过大造成不收敛,无限逼近最优解。
第八步,计算全局误差:

第九步,判断网络误差是否满足要求,当误差达到预设精度或者学习次数大于设定的最大次数,则结束算法。否则,选取下一个学习样本及对应的期望输出,返回到第三步,进入下一轮学习。
3.3 BP算法的最优解
实际上BP算法的最终目的是找到最优解,即是累积误差最小的解。通过算法的优化,可以找到最优解,在机器学习中最常用的优化算法就是梯度下降法。但是在实际过程中,会出现多个局部最优解(对应梯度为零的地方),如图3展示的可视化图形中,有一个局部最优解,一个全局最优解。通常情况下找不到全局最优解,能找到局部最优解也不错,也足够优秀地完成任务。

图3 全局最小与局部极小
4 结束语
通过上述文章对BP算法的理论推导,我们对神经网络的参数及优化有了一定的了解,希望能给利用神经网络或者深度学习算法解决无线电监测工作中的问题的同事提供一点思路与想法。■
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
制造技术与机床(2019年9期)2019-09-10
西南交通大学学报(2018年6期)2018-12-18
现代装饰(2018年5期)2018-05-26
河北遥感(2017年2期)2017-08-07
自动化学报(2017年7期)2017-04-18
现代电子技术(2016年15期)2016-12-01
衡阳师范学院学报(2016年3期)2016-07-10
中国生化药物杂志(2015年4期)2015-07-07
