
基于决策树的设备预测性维护
2018-09-03 05:43彭牡林肖逸军
数字通信世界 2018年8期
彭牡林,肖 宏,肖逸军,张 翼
(中国石油西南油气田分公司通信与信息技术中心,成都 610000)
目前,已建成的设备相关信息系统有设备综合管理系统、生产数据平台、ERP系统、作业区数字化管理平台、管道与场站管理系统、净化总厂设备完整性管理系统等,涉及电力、通信、集输净化、钻井试油、安全、环保、消防等专业领域设备信息,数据涵盖设备基础台账信息、设备运转记录、故障信息、维护管理记录等,实现了设备的全生命周期管理,积累了大量的供研究和挖掘的历史数据。
1 研究现状
近些年,随着微处理器或计算机的仪器仪表的迅速发展,以及维护管理系统的不断完善,尤其是先进以现场总线和工业以太网等通讯技术的高速发展和普及,国内外各大厂商推出了各种先进的预测性维护技术。油气井管道站库生产运行安全环保预警可视化管理系统研究与应用项目组对设备完整性及检维修预警也进行了研究,研究人员使用灰色预测模型对压力容器厚度进行灰色动态拟合,找出厚度随时间的变化规律,求时间序列函数,预测下一次检测值,以及基于多参数的设备故障预警就是通过综合分析与设备故障状态相关联的多个工况参数的变化情况,实现预警。
2 决策树分析法
2.1 决策树简介
决策树分析法是指分析每个决策或事件(即自然状态)时,都引出两个或多个事件和不同的结果,并把这种决策或事件的分支画成图形,这种图形很像一棵树的枝干,故称决策树分析法。
2.2 决策树构建流程
下面以决策树构建中的ID3算为例说明决策树构建步骤[2]。
第一步:收集数据,数据包括样本数据、验证数据,样本数据用于构建决策树、验证数据用于验证决策树的准确率。
第二步:数据构建,确定根据哪几个属性进行分类,及确定分类类别。
第三步:决策树构建。
3 基于决策树分析法的设备预测性维护
为方便构建模型我们选取两种设备状态:正常和非正常。
首先,选取样本集,样本集分两类,一类为构建决策树,二类为验证决策树。
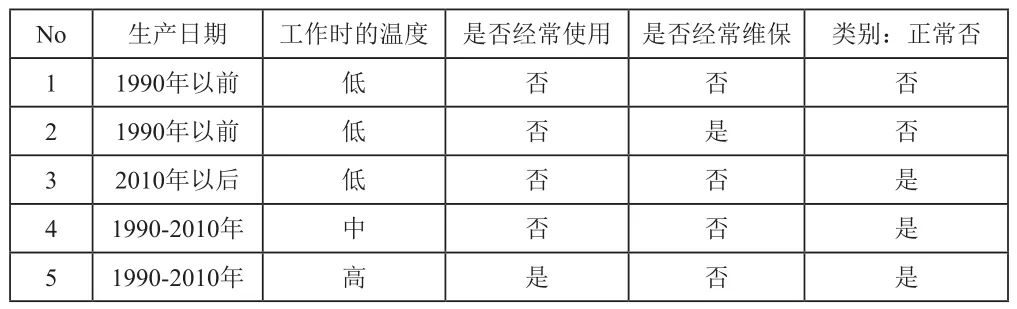
表1 设备预测性决策树构建样本数据集
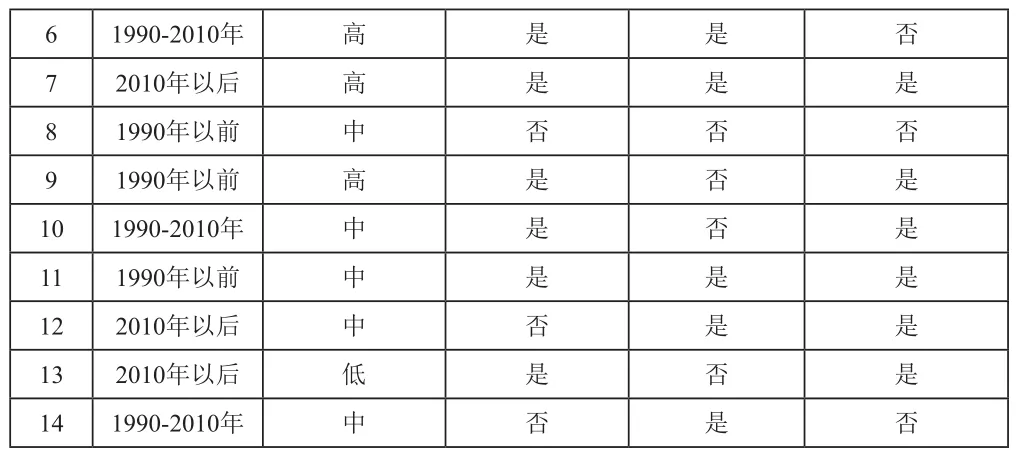
6 1990-2010年 高 是 是 否7 2010年以后 高 是 是 是8 1990年以前 中 否 否 否9 1990年以前 高 是 否 是10 1990-2010年 中 是 否 是11 1990年以前 中 是 是 是12 2010年以后 中 否 是 是13 2010年以后 低 是 否 是14 1990-2010年 中 否 是 否
通过公式计算数据集的信息熵为:I(正常,非正常)=0.9406;
生产日期:条件熵=E(样本集,生产日期)=0.6936,信息增益=Gain(样本集,生产日期)=I(正常,非正常)-E(样本集,生产日期)=0.247;
工作时的温度:生产日期:条件熵=E(样本集,工作时的温度)=0.9111,信息增益=Gain(样本集,工作时的温度)=I(正常,非正常)-E(样本集,工作时的温度)=0.0295;
是否经常使用:生产日期:条件熵=E(样本集,是否经常使用)=0.7886,信息增益=Gain(样本集,是否经常使用)=I(正常,非正常)-E(样本集,是否经常使用)=0.152;
是否经常维保:生产日期:条件熵=E(样本集,是否经常维保)=0.8955,信息增益=Gain(样本集,是否经常维保)=I(正常,非正常)-E(样本集,是否经常维保)=0.0484;
由此可见,若以“生产日期”作为分裂属性,所得信息增益最大,于是根据该属性的三个取值,将数据集分为三个子集:
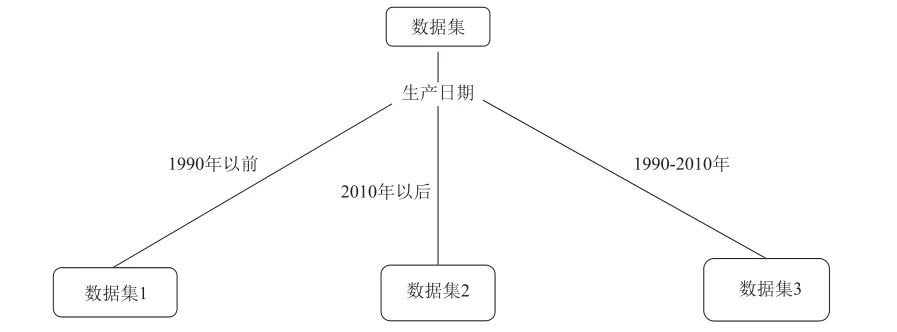
图1 数据子集构建
(1)数据集1
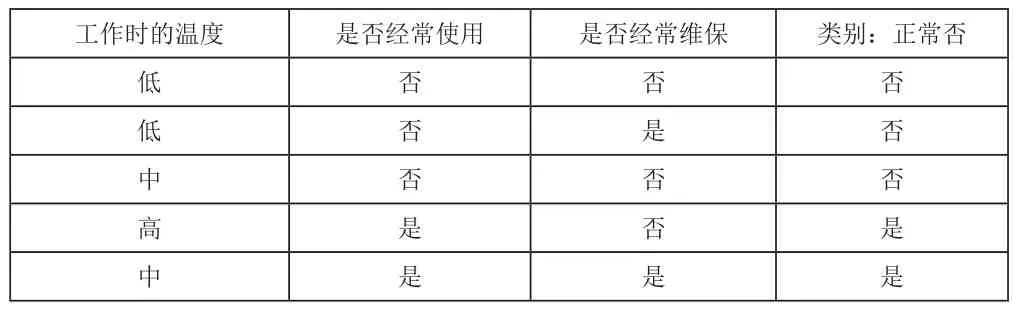
表2 数据集1
(2)数据集2

表3 数据集2
(3)数据集3

表4 数据集3
数据集2对应子集全部样本都属于同一个类别,因此它成叶子节点,不再分裂。采用同样的方法,分别对数据集1和3进行分裂,直到所得子集的全部样本属于同一个类别,得到全部叶子节点。最终得到的决策树如图2所示:

图2 最终得到的决策树
由此构建完成设备预测性维护决策树,接下来需要用验证样本集对结果进行验证。验证的方法为将样本数据的属性通过决策树进行分类,所得到的叶节点的分类即为决策树分类结果,然后将得到的结果与实际情况进行比较,计算验证样本集的决策树分类准确率。
4 建议与意见
设备的预测性维护需要IT技术与业务的深度结合,为保证预测性维护的准确性和及时性,建议如下:一是注重设备基础资料的管理,涉及设备厂商、生产日期、规格型号等出厂参数;二是加强设备运行状态数据的收集整理,尤其是压力、温度等直接反映设备运行状态的参数的收集,包括故障和正常运行状态;三是建立设备预测性维护知识库,引入专家验证机制,提高设备预测性维护的准确率。
5 结束语
决策树在设备预测性维护方面应用比较多,但是决策树本身也存在一些缺点,ID3仅维护单一的当前假设,这样就失去了表示所有一致假设带来的优势,而且ID3算法在搜索中不进行回溯,每当在树的某一层次选择了一个属性进行测试,它不会再回溯重新考虑这个选择,所以它是收敛到局部最优的答案,而不是全局最优的。但是对于其中的不足,可以结合其他算法或者对其本身进行改进来达到全局最优效果。
猜你喜欢
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
航空维修与工程(2020年6期)2020-09-21
南京大学学报(数学半年刊)(2020年1期)2020-03-19
吉林大学学报(理学版)(2018年4期)2018-07-19
环球慈善(2018年12期)2018-02-01
食品安全导刊(2017年8期)2017-08-16
烹调知识(2017年3期)2017-03-07
都市丽人(2015年4期)2015-03-20
新闻前哨(2015年2期)2015-03-11
外语教学理论与实践(2014年2期)2014-06-21
