
基于特征融合和度量学习的车辆重识别
2018-09-14 12:01王盼盼李玉惠李福卫
电子科技 2018年9期
王盼盼,李玉惠,李福卫
(1.昆明理工大学 信息工程与自动化学院,昆明 云南 650500;2.昆明聚信丰科技有限公司,昆明 云南 650500)
重识别技术旨在从不同的拍摄场景中识别出相同的目标,是智能视频监控研究领域的重要分支,近年来, 监控视频中重识别问题引起了广大科研人员的兴趣并对其进行了相应的研究。图片车辆重识别是重识别技术需要解决的问题之一,其中通过车辆的号牌识别来达到车辆重识别是一种简单有效的方法,但在道路监控视频中往往存在无车牌或车牌被遮挡的情况,给交通执法部门带来不小的挑战,这就需要通过提取、比对拍摄车辆的其他信息才能达到车辆重识别的目的。在通过监控视频提取不同摄像头拍摄同一目标时,存在着光照变化、视角变化以及摄像机自身属性的问题,导致同一目标的车辆图像的角度、颜色和轮廓等特征差别较大,使得车辆重识别问题变得更为复杂。
为了解决以上目标重识别中遇到的问题,许多方法陆续被提出,这些研究主要针对重识别所涉及到两大问题:图片的特征表示以及度量学习。文献[1]利用深度卷积网络通过计算原车辆图像的欧氏空间中的距离可以直接用来测量任意两车相似性。文献[2]利用SVM建立了特征空间和分类的空间之间的对应关系,并通过最小二乘半耦合(lsscdl)字典学习算法学习对词典的有效映射,达到分类与识别的目的。文献[3]利用相对距离比较(RDC)学习,优化目标图像之间的相似性度量,强调了目标图像的可靠性和个性化特征。文献[4]利用度量学习和局部Fisher判别分析实现目标图像的颜色之间的匹配。文献[5]提出一种融合目标图像的LBP和HSV特征的方法,并利用改进的马氏距离实现了目标图像的相识度排序。文献[6]提出了一种新的集成模型,它通过度量学习计算决策层中的不同颜色描述符间的距离,保持了颜色特征的不变性和显著性。文献[7]利用非对称距离模型实现拉近样本的类内距离,扩大样本类间的距离。文献[8]提出了一种同一摄像机下已有图像与示例图像之间的图像边缘特征向量,然后用不同摄像机下相同车辆与不同车辆的特征向量来建立分类器。文献[9]中提出一种基于空间颜色特征的重识别方法,建立一种在计算复杂度和性能上较均衡的行人外貌特征描述符。文献[10]使用一种新颖的深度学习网络来将相似度分数分配给人体对的图像。
考虑到在目标重识别时,不同的摄像机所拍摄的同一目标的图片有可能相差比较大,所以单一的图像特征不能对目标图像进行稳定并有判别力的描述,本文所提方法将车辆图片的HSV特征和LBP特征进行融合,并对融合特征矩阵进行LDA降维,然后利用马氏距离对融合后的车辆图片特征进行相似性度量,得到车辆图片的相似度排序。
1 特征融合和度量学习
1.1 特征融合
由于车辆的颜色和几何特征包含了车辆本身的一些个性化信息,所以本文提取的图片特征为车辆的HSV和SILTP特征,并将两种类型的特征进行串联,从而得到融合特征,因此本文参考文献[5]的特征提取算法提取车辆的特征信息。
本文首先对车辆图片进行Retinex(视网膜Retina 和大脑皮层Cortex 的缩写)变换[11],车辆的颜色特征经过Retinex变换后能够使不同的场景下车辆的视觉颜色特征恒定,根据此理论处理彩色图像,可以使得处理后的图像包含丰富的颜色信息,并提升阴暗区域的细节效果。本文采用该方法处理的车辆图片使车辆图片颜色更加接近物体原来的颜色,而且在阴暗区域的视觉效果得到较大的提升。
由于车辆图片分辨率低以及角度、光照等问题,拍摄的车辆图片的细节信息模糊不清,存在着许多噪声,因此利用SIFT特征来比较车辆图片的相识度是不准确的,因为SIFT特征是建立在图片清晰度比较高的基础上,所以需要选择更具表达能力的车辆图片特征。由于人眼在识别车辆身份时一般使用的是颜色特征和车型特征,所以本文选择车辆图片的HSV和SILTP(Scale Invariant Local Ternary Patterns)特征来表示车辆图片的特征信息。
颜色特征对于描述车辆图片是一个不可或缺的重要特征,但是由于光照变化以及摄像机之间设置的不同,同一车辆在不同摄像机上拍摄的图像在光照以及颜色上都有较大的差距。车辆的HSV特征即为车辆的一种颜色空间模型,该模型对目标颜色的表达接近人类眼睛的视觉感知特性。它根据色彩的3个基本属性(色调、饱和度和亮度)来表达颜色。由于不同品牌的车外形设计不尽相同,所以车辆的几何特征在一定程度上可以代表车辆的个性化信息[12-13]。
SILTP 纹理特征是LBP(Local Binary Pattern)局部二值模式的一种改进形式, LBP 计算简单且具有良好的尺度不变性,但容易受到噪声的影响,SILTP 算法比LBP算法多了一次比较,因此,SILTP算法包含了LBP 的尺度不变性的优点,又对图像噪声具有一定的鲁棒性。
1.2 LDA降维
由于提取的车辆特征信息的维数很高,为了节约运行时间以及使提取的车辆图片特征更具分类能力,所以本文采用的LDA(Linear Discriminant Analysis )降维算法对提取的车辆图片的特征数据进行降维[14]。
LDA是一种有监督的线性降维算法。与PCA保持数据信息不同,该算法能够很好的区分降维后的数据的分类信息。其原理为通过映射向量使原数据保持两种性质:(1)同类的数据尽可能的接近;(2)不同类的数据尽可能的分开。本文使用LDA降维方法将原车辆特征数据由14 154维降到457维,识别率也有所提高。
1.3 度量学习中的马氏距离
本文在车辆图片特征相似性度量方面选用马氏距离(Mahalanobis distance),马氏距离是印度统计学家马哈拉诺比斯(Mahalanobis PC)提出的,与欧氏距离相比,马氏加入了期望和方差等使其具有数据分布的统计特性,所以马氏距离又被称为统计距离,该距离已成为模式识别领域中常用的度量之一[15]。
定义摄像头probe下的车辆图片特征数据为
X={x1,x2,…,xn}∈Rd1×n
(1)
gallery下的车辆图片特征数据为
Y={y1,y2,…,yn}∈Rd2×n
(2)
其中,n为样本数,d1和d2为数据维数。则根据X,Y各个样本间的马氏距离为
(3)
其中,i表示X的第i个样本,j表示Y的第j个样本。本文分别计算X下的每个样本的特征信息与Y样本下的每个样本特征之间的距离,得出相似度排序。
2 车辆重识别流程
本文所提出的车辆重识别方法的流程为:首先对车辆图片进行归一化处理,然后提取车辆图片的HSV特征和SILTP特征,并采用串联的方式实现特征的融合,对融合的特征矩阵进行进行LDA降维,并对降维后的车辆样本数据进行相识度计算,具体步骤如图1所示。

图1 特征融合和度量学习的车辆重识别流程图
3 实验结果
该数据集是汕头至昆明的高数公路上相邻摄像头拍摄的图片数据,该数据集共有632组车辆图片,每组车辆图片由同一车辆在相邻摄像头各拍摄1张照片组成,每张图片的尺寸归一化为60×70像素值。拍摄车辆的角度以及光照条件均有一定的变化,车辆图片数据集部分图像如图2所示。

图2 车辆数据集中部分车辆图片
随机选取数据集中的一半图片作为测试集,通过计算跨视野车辆图片之间的相识度得出相识度排序,并通过累积匹配特性曲线(CMC)展示其性能。算法的最后性能表现取10次实验结果的平均值。
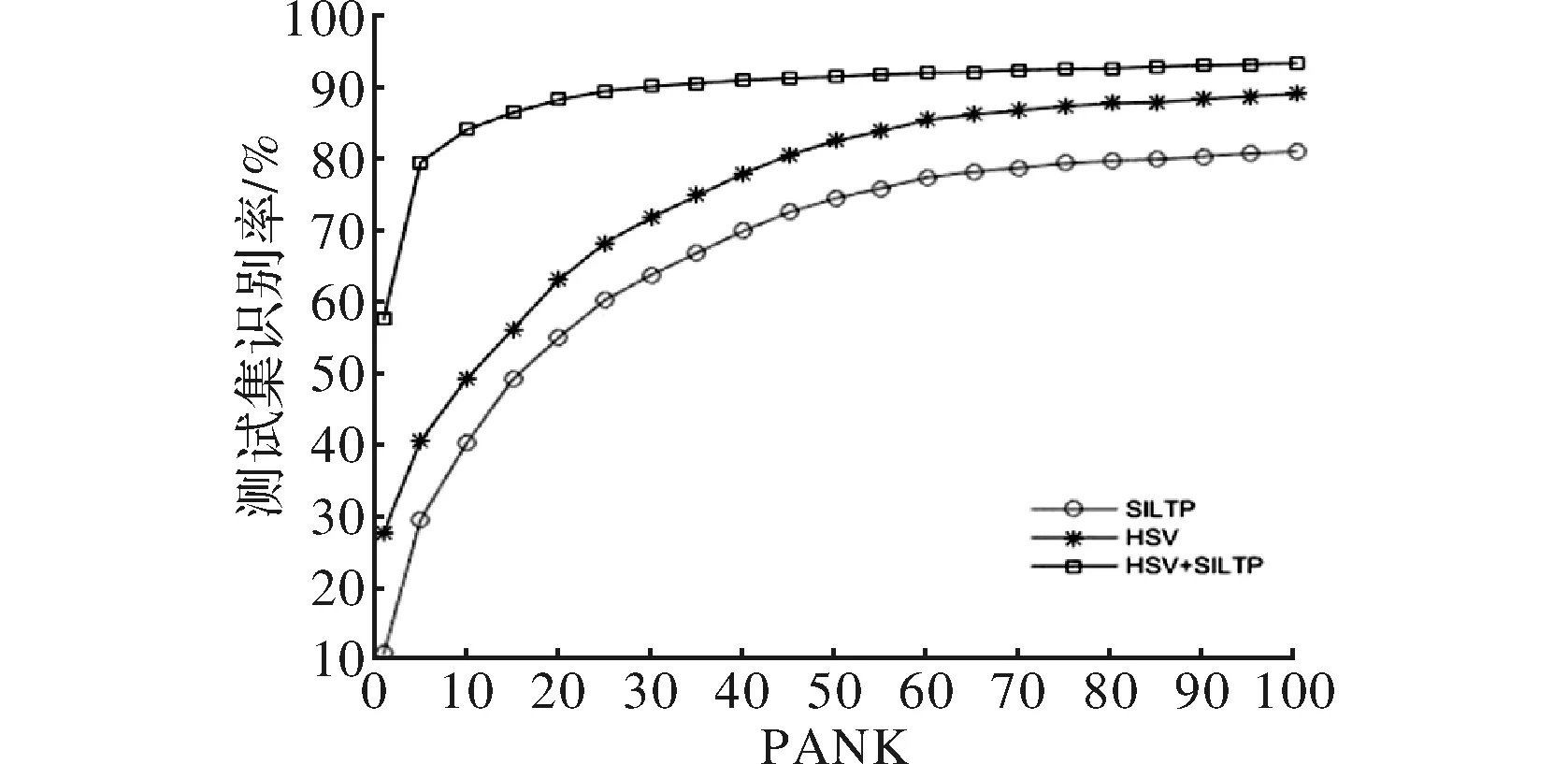
图3 采用的特征融合方法与单特征方法的测试性能的CMC曲线比较
由图3可以看出在跨视野的车辆重识别方面使用单特征来表示图像是不准确的,使用特征融合的方法能够降低因跨摄像头所带来的视角、颜色等的变化对识别率的影响。通过表1可以看到,本文的方法相比于sift特征加度量学习在识别率方面具有一定的优势,因为跨视野下车辆图片的视角会发生变化,单纯的sift特征不能完全表达车辆的特征信息,所以需要更具表达能力的方法来表示车辆特征信息,特征融合就能很好的实现提高识别率的目的。
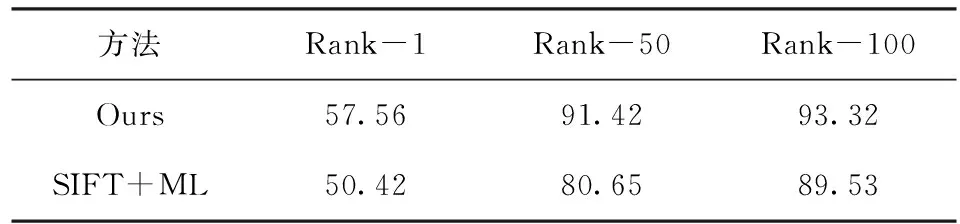
表1 本文方法与SIFT+ML方法的识别率比较 /%

图4 本文方法有无LDA降维操作的CMC曲线比较
由图4和表2可以看出,本文方法所运用的LDA降维方法不仅在计算时间上有所降低,而且会使车辆图片的特征信息得到较好的区分,有利于提高车辆图片的重识别率。
4 结束语
本文针对车辆重识别时不同拍摄视角、光照等拍摄条件同一车辆的视频监控图像存在差异的问题,提出一种结合特征融合和度量学习的车辆重识别方法。首先利用LOMO方法对车辆样本进行特征表示,并通过马氏距离对车辆样本特征进行相似性度量。由车辆重试别的验证实验结果可知,该方法在车辆的同一性识别方面具有较高的识别率,对光照变化、视角变化都具有一定的鲁棒性,且具有低计算复杂度的优点。
猜你喜欢
车主之友(2022年4期)2022-08-27
上海文化(文化研究)(2022年3期)2022-06-28
数学年刊A辑(中文版)(2022年4期)2022-02-16
数学物理学报(2021年3期)2021-07-19
数学物理学报(2020年6期)2021-01-14
数学年刊A辑(中文版)(2020年1期)2020-05-19
海峡姐妹(2019年12期)2020-01-14
数学年刊A辑(中文版)(2019年3期)2019-10-08
数学物理学报(2018年2期)2018-05-14
中国学术期刊文摘(2016年1期)2016-02-13
