
基于数据降维的机器学习分类应用问题探讨
2018-09-18 09:56隋旻言李骁汉
数码设计 2018年2期
隋旻言,李骁汉
(武汉理工大学自动化学院,湖北武汉,430070)
引言
数据降维是指将单幅图像数据的高维化,使其转化为高维空间中的数据集合,进行非线性降维,寻求高维数据结构的一维表示向量,将其作为图像数据的特征表达特定目标。数据降维可以应用于多个领域,尤其是大量数据的分析计算,包括机器学习相关工作。当前机器学习分类应用问题较为突出,很大程度上影响了具体工作的开展,分析基于数据降维的机器学习分类应用问题、探讨解决对策有一定的现实意义。
1 当前机器学习分类应用问题
1.1 样本归类不清
样本归类问题,是机器学习分类应用最基础的、最突出的问题,当前机器学习的基本方式是神经训练,该算法是对人体神经系统进行模拟,通过广泛收集非结构化的海量数据进行学习,但在对样本进行归类时,由于海量数据中相近数据极多,很难实现精确的归类,导致机器学习耗时长、效率低。
1.2 计算量较大
当前机器学习的一个核心弊端是较大的计算量,这也直接影响了分类应用工作。机器人出现之初,为求保证其能够有效模仿人类的行为、实现“人工智能”,设计人员采用了神经训练法,这一算法的优势也是其弊端。具体来说,提升神经训练成果的主要方法是大量增加样本数据,样本数据越多,计算结果越理想,机器人的模仿能力也越强。
1.3 精度问题
精度问题是当前机器学习分类应用的主要问题之一,对于精度标准,各国的看法并不一致,总体而言,机器学习依然遵循样本数量越多、精度越高的基本规律[1]。
2 数据降维方式的选取
2.1 随机森林法
随机森林法是用随机的方式建立一个拟森林状的判断系统,在“判断森林”(随机森林)中,每一个进行判断的程序都以一棵“决策树”的形式存在,随机森林的每一棵“决策树”之间是没有关联的。随机森林建成后,任意输入样本进入森林,森林中的“决策树”都会分别进行一次判断,分析该样本应该属于哪一类,被最多“决策树”判定的类别,就是该样本的类别[2]。
2.2 K近邻算法
K近邻算法是最典型的降维算法,该算法理论上十分成熟。K近邻算法的核心思路是,建立若干标准点 K,各自代表一个分类类别,将样本代入特征空间,如果样本在特征空间中最邻近某个K点,即表示该样本属于该类别。与随机森林法不同,虽然K近邻算法也强调相似判断,但样本并给完全遵循非线性规律,而是在不明确的线性标准下给予模糊分类,再进行精细化处理,而且K近邻算法不遵循“决策树”式的多数原则,只要某个样本距离K点最近,就属于该类别。
3 模拟实验
3.1 观察指标
实验在虚拟环境下进行,通过参数带入模拟实验环境,应用神经训练法、随机森林法、K近邻算法对同一个机器人软件进行训练,观察机器人的学习效率和精确性。
3.2 实验过程与结果
所有实验在人工干预下进行,应用100个、1000个、10000个样本进行三轮实验,同一轮实验内应用的样本完全相同。通过对照,发现神经训练法、随机森林法、K近邻算法的学习效率和精确性存在差异。神经训练法、随机森林法三组实验所获数据如表1所示。

表1 神经训练法和随机森林法实验数据
结果表明,随机森林法下,机器学习的效率更高,精确性也更好,能够较好的满足分类应用要求。神经训练法、K近邻算法三组实验所获数据如表1所示。
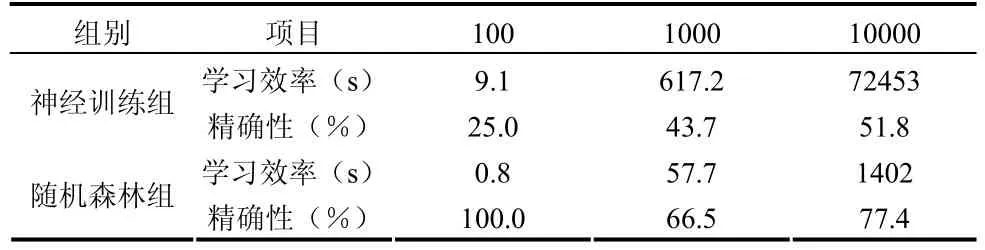
表2 神经训练法和K近邻算法实验数据
结果表明,K近邻算法下,机器学习的效率更高,精确性也更好,能够较好的满足分类应用要求。
3.3 实验结论
经过实验对比,在应用随机森林法、K近邻算法的情况下,可以实现数据降维,将多维度的数据以非线性条件进行分类,使所有数据能够直接在特征空间内与对应的分类类别实现匹配,免去线性约束条件下神经训练法复杂计算的麻烦,机器学习的效率高、分类应用的成果也更好。此外,应用随机森林法进行数据降维,机器学习效率略低于K近邻算法,但精度略高,这也体现了两类算法各自的优劣势。
4 结束语
通过数据降维的方式可以加以应对,可行的计算方式包括随机森林法、K近邻算法等。模拟实验表明,随机森林法、K近邻算法在机器学习中的效率更好,后续工作中,可作为机器学习的参考方式。
[1]杨磊, 唐晓燕.基于流形学习的高光谱图像非线性降维算法[J].河南理工大学学报(自然科学版), 2016, 35(05): 660-665.
[2]李海亭, 肖建华, 李艳红.机器学习在车载激光点云分类中的应用研究[J].华中师范大学学报(自然科学版), 2015, 49(03): 460-464.
[3]王懿.基于自然语言处理和机器学习的文本分类及其应用研究[J].《中国科学院研究生院(成都计算机应用研究所)》 , 2006.
[4]罗凯旋,钟凡,赵亮,贺福初.评估几种降维分类器应用于生物质谱数据的性能 [J]《中国科学:生命科学》, 2010,40(6):544-550.
[5]杨秀锋.基于机器学习的生物医学数据处理方法研究[J].中国科学院大学,2014.
猜你喜欢
车主之友(2022年4期)2022-08-27
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
汽车实用技术(2022年4期)2022-03-07
数码世界(2020年4期)2020-06-18
装备环境工程(2020年3期)2020-04-03
海峡姐妹(2019年12期)2020-01-14
科学与信息化(2019年28期)2019-10-21
电影(2018年8期)2018-09-21
科学与财富(2016年32期)2017-03-04
