
基于证据等级的非主观近似算法
2018-10-17 01:45余肖生
重庆理工大学学报(自然科学) 2018年9期
陈 鹏, 何 凯,余肖生
(三峡大学 计算机与信息学院, 湖北 宜昌 443002)
火灾隐患的科学判定往往需要有效的方法,融合多个组织获取的与火灾隐患有关的不确定信息。D-S证据理论[1-2]因其在不确定性问题上表述、组合等方面的优势,被广泛应用于信息融合[3-5]、多属性决策分析[6]、风险评估[7]等领域。而Dempster组合规则[8]在处理实际问题时,往往面临“焦元爆炸”的问题。针对这些问题,国内外研究人员都给出了自己的解决方案:Smets[9]提出TBM框架,通过解决复合源的计算问题来达到减少焦元的目的,但是实际效果不佳,没有真正解决“焦元爆炸”问题;Dubois等[10]提出近似一致性算法,近似计算后焦元是嵌套的,以此减少了计算的复杂度,但是由于嵌套的焦元只能用于描述,不能进行后续的计算,因此该近似算法无法运用于实际计算中;Voorbraak[11]提出了Bayesian近似方法,这是一种非主观的近似方法,解决了复合焦元的融合问题,且在计算较少焦元时融合结果比较准确,但对“焦元爆炸”的问题依然无法很好地解决;Tessem[12]提出的(K,L,X)近似方法和Lowrance[13]提出的Summarization近似算法[13],本质上都属于主观的近似算法,基本解决了“焦元爆炸”的问题,但由于这两种算法都需要通过人为主观判断阈值,都不具备普遍适用性;Denoeux[14-15]提出的粗糙近似算法,用先“粗化”然后“细化”的方式同样解决了“焦元爆炸”的问题,但是其做法只能用于粗糙处理,计算结果容易出现结论与实际不符的情况。
本文针对“焦元爆炸”的问题,结合具体实际情况,提出一种无需人为判断且具有普遍适用性的近似算法(ELNA)。其主要通过判断主要焦元的累计mass值去确定证据的等级,根据证据的不同等级采取不同的初始标准来减少焦元的数量,以达到减少计算量的目的。最后,在融合的时候也会根据证据的等级给予不同的折扣,以此来增加融合结果的准确性。
1 证据理论基础及相关研究概述
1.1 证据理论基础
D-S证据理论被认为是表征和处理不确定事物的有效工具。最初由Shafer从数学的角度证明了其对不确定事物的建模能力,同时提出了该理论具体的量化模型。D-S证据理论基础详见文献[1-2]。
假设定义一个集合H叫做识别框架,定义如下:
H= {H1,…,Hn,…,HN}
(1)
它由N个穷尽且排他的假设组成。从其结构出发,可以得到由H组成的2N个命题,表示为:
2H={∅,{H1},{H2},…{HN},
{H1∪H2},{H1∪H3},…,H}
(2)
其中2H叫做识别框架的幂集,它的每一个元素都表示一种假设,这些假设在证据理论被称为焦点元素,简称焦元。对假设的支持程度叫做基本置信指派,用m表示。在2H→[0,1]满足:
m(∅)=0
(3)
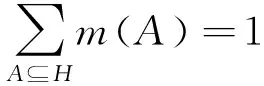
(4)
其中m(A)表示对证据支持假设A的强度,也被叫做假设A的mass值。从该基本置信指派推广,分别定义置信函数Bel和似然函数Pl:

(5)

(6)
其中:Bel(A)表示对假设A为真的度量;Pl(A)表示假设A可能为真的度量。m(A)、Bel(A)、Pl(A)可被看做对于同一信息的3种估计:一般估计、悲观估计、乐观估计。通过置信函数Bel和似然函数Pl构成的置信区间,能较为直观地表示证据对焦元的支持程度。
在不完全(不确定、不精确和不完全)数据的情况下,融合是获得更多相关信息的有效解决方案。Dempster组合规则是证据理论的第1个组合规则,也是现今使用最广泛的组合规则之一。定义如下:假设m1和m2是识别框架H上的2个独立证据,2H是它的幂集,A、B是幂集中的元素,则这2个证据组合后得到的组合证据为
(7)
其中K为归一化常数,
(8)
为了防止不可靠证据对融合结果产生影响,往往需要对融合的证据进行折扣:
mw(A)=wm(A)∀A⊂H
(9)
mw(H)=1-w+wm(H)
(10)
其中:w为折扣系数;焦点H存放折扣后剩余的mass值。
1.2 相关研究简述
为了解决证据理论中“焦元爆炸”的问题,国内外学者从不同角度进行了研究,提出了各种各样的近似算法。在众多近似算法中,最具代表性的是Bayesian近似算法、(K,L,X)近似算法和Summarization近似算法。
1) Bayesian近似算法。主要是将证据理论与概率思想相结合,将基本信度值(也叫mass值)转化为Bayesian概率。一般情况下,该算法满足:信度函数的Bayesian近似的合成等于其合成的Bayesian近似。利用这个特性可以使融合的计算量大大减少,而且这是一种非主观的近似算法,具备了普遍适用性。由于其将复合焦元的mass值分配给单焦元,降低了证据理论表示不确定的特点,丢失了大量信息。相较其他近似算法而言,其对“焦元爆炸”的处理并不具有太大的优势。
2) (K,L,X)近似算法。主要思想是通过阈值的选取来减少焦元的数量。依靠主观选取保留的焦元数量,去掉mass值较小的焦元,来减少焦元数量,从而实现减少计算量的目的。这种近似算法从应用的角度来讲,适合几乎所有的情况,但是因其是一种通过主观判断来确定阈值的方法,不同的证据都需要重新选取阈值,不同的阈值可能导致完全不同的结果,稳健性不够且要求阈值选取人员必须具备相应的知识。这些缺点导致其无法被广泛应用。
3) Summarization近似算法。主要通过将较小的焦元的mass值全部放在假定焦元A0中,且不改变较大焦元的mass值的方式进行近似处理。相当于去掉了mass值较小的焦元,在减少了焦元数量的同时,没有改变mass值较大的焦元,这样的处理不会对融合结果产生太大影响。但是,这个近似算法和(K,L,X)算法存在类似的问题:需要主观判断保留焦元的数量,不同的源可能因为保留焦元数量的不同导致完全不同的结果。另外,当焦元的mass值相等时,这种方法在处理时也存在一定问题。
这几种近似算法中,Bayesian算法不需要人为判断参与,而其他两种都需要人为主观判断参与。
2 基于证据等级的非主观近似算法
为了克服上述近似方法的不足,笔者提出基于证据等级的非主观近似算法。该方法首先根据一定规则将复合焦元转化为单焦元,再依据主要焦点的累积mass值将证据划分成不同的等级。为了保证结果的可靠性,会将近似算法舍弃的mass值按一定的比例叠加到保留的焦元上。最后,按照证据等级的不同给予不同的权重进行融合,以确保确定性较差的证据不会对结果产生过大的影响。具体处理过程如下:
1) 复合焦元的处理规则
参照Pignistic概率的处理方式,根据组成复合焦元的元素,将复合焦元的质量等比例的分配到组成其的所有单点焦元中去,从而使复合焦元转化成单焦元。
∀A⊆H
(11)
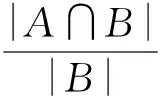
2) 证据等级评估方法(level of envidencde estimatima method)
为了能够利用累积的mass值去划分不同证据的确定性等级,将经过第1步处理后的证据按照mass值从大到小排列,将前3个焦元与前5个焦元的和分别记做A和B,且满足A,B∈[0,1],根据累积mass值A、B的大小做如下划分:

(12)
其中1、2、3、4分别代表证据的确定性等级,等级越小说明证据的确定性越好。按照累积mass值A、B的大小将证据的确定性分为4个等级,记录下每个证据的证据等级,将作为下一步近似处理及最后融合时确定权重比的依据。
3) 近似处理(approximate treament)
为了方便后续计算,所有的源都必须先进行初步处理。
初步处理:保留mass值前5的焦元,舍弃其他的mass值,将舍弃的mass值按照5个焦元的比例分配到5个焦元中去。
近似处理:根据证据的不同等级给予不同的初始标准,超过初始标准的mass值保留,低于标准mass值的舍弃。
初始标准的设定按照证据等级来确定。确定的目的主要是为了进一步减少焦元,确定主要因素。不同等级的标准由函数s确定:

(13)
标准的制定完全按照证据初始的确定性等级来确定,确定性越高的证据设定的标准也就越低,方便剔除mass值很小的焦元,确定性越低的证据设定的标准越高,以此来提高处理后证据的确定性,方便进行下一步根据权重比融合不同的证据。
4) 基于折扣处理(discounting operation)的数据融合
近似处理的目的就是为了更好地进行数据融合,而很多近似处理会丢失很多关键的信息。若直接进行融合,最后的结果往往可信度不高,不能作为决策的标准。
本文采用根据证据初始数据确定证据等级的方式,用证据等级确定融合给予的权重比大小:证据等级越小的证据在融合时给予更多的权重比,证据等级越大的证据只需要保留其主要成分,在融合时候给予较小的权重比,最后融合出来的结果就不会与实际有太大的偏差。
合理的融合顺序是得到正确融合结果的有效手段,本文采取基于证据等级的证据排序方式。
证据内的排序方式:证据内的焦元重要性排序按照少数服从多数的原则,将所有证据的同种焦元mass值相加取平均值,平均值越大说明该焦元在证据内占据比例越多,说明越重要,越重要的焦元在写入表格的时候就写得越靠前。
证据间的排序方式:首先是对不同等级的证据按照等级越小越优先的原则进行排序,因为证据等级越小的证据确定性越高,将其优先融合能提高其作主导证据的机会,有利于提高融合结果的可靠性。其次,是对相同证据等级的证据进行排序,主要采取越重要焦元mass值越小越优先的原则进行排序。这样做可以有效避免错误证据对融合结果的影响,即使融合的证据是错误证据,优先融合能使其对融合结果的影响降至最低。
经过前面近似处理的证据按照证据之间的等级差取不同的权重比进行分级融合。
融合的权重比(大∶小)=
0.5+0.1*等级差∶0.5-0.1*等级差
(14)
其中等级差为2个证据等级r(A,B)差值的绝对值。融合之后的证据等级等于用于融合两个证据等级的平均值。两个证据折扣后的剩余部分融合产生的mass值按主导证据(证据等级小)的比例分配,若存在多个主导证据就随机选取其一。由主导证据的选取方式决定,融合权重的选取要求同证据等级非错误证据在4个以上,因为这样能保证至少有93.75%的可能得到正确的结果。非错误证据的数量越多,融合错误证据造成的影响就越小,结果的准确性越高,这一点在证据等级较低的时候能得到明显的体现。在证据等级较高的时候,即使错误证据较多,也并不会对融合结果产生太大的影响。
折扣判断以及证据等级的判断过程如图1所示。

图1 折扣判断以及证据等级的判断过程
3 仿真结果及分析
3.1 一般情况仿真结果及分析
这里主要针对一般情况(包括嵌套焦元证据M1和M2、多焦元证据M4、区分度不大焦元证据M3)的融合,横向比较ELNA与其他两种方法以验证ELNA方法的一般性以及结果的可靠性。至于在针对失效证据(错误证据)的融合上,一方面其他方法融合失效证据会产生与实际情况不符的结果,错误的融合结果不方便做横向比较,无法验证 ELNA融合结果的可靠性;另一方面在实际中错误的证据毕竟只占少数,若直接融合错误证据难以反映实际情况,也无法说明方法的一般性。因此,对特殊情况(错误证据)的仿真结果及分析会在下文单独列出。
在这里假设某识别框架的概率分配函数及焦元如表1所示,分别使用本文的近似算法、非主观Bayesian近似算法和主观Summarization近似算法进行处理,处理后的结果如表2、3、4所示,再将这3种方法的处理结果分别进行融合,得到融合结果如表5所示。另外,若处理之后对应焦元的mass值为0,将无法进行证据理论合成,一般会对表中为0的部分进行微调,即根据实际情况加入相应的扰动值,方便进行合成计算。扰动值是作为替代0的存在,一般越小越好,通常按照数据的精确度设定相应的扰动值,例如本文数据的精确度只在小数点后2位,故使用扰动值ε=0.01。
根据表5中列出的融合结果进行比较,结果如图2~4所示。

表1 基本概率分配(BBA)及焦元

表2 ELNA的处理结果
表3 Bayesian近似算法的处理结果

表4 Summarization近似算法的处理结果
从处理结果可见:无论是对证据中mass较小的焦元(证据M1、M2)的舍弃上,还是对多焦元证据(证据M4)的处理上,ELNA都与主观Summarization近似算法的处理结果类似,明显优于同为非主观的Bayesian近似算法的处理结果。ELNA会依靠减少需要计算的焦元数量来解决“焦元爆炸”的问题。
从表5的融合结果可见:ELNA的融合结果与Bayesian近似算法的融合结果基本保持一致。Bayesian近似算法仅对复合源进行了处理,其融合结果应和不经过近似处理的Dempster组合规则的融合结果一致,因此ELNA融合结果是可信的。Summarization近似算法的结果与其他方法存在一定的差异,主要问题在于融合确定性较低的证据(证据M4)对其结果产生的较大的影响,因为其融合前3个证据知之后的支持度依次为0.725、0.208、0.014、0.014、0.014、0.025,而融合第4个证据使其结果产生了较大的偏差。ELNA近似算法通过融合前的权重分配,对于像上例中的确定性较差的证据(证据M3、M4)给予较低的权重值,这样产生的融合结果基本是正确可信的。本文在处理确定性较差的焦元时会突出其主要的焦元,保留其最主要的信息。在最终的融合中这些信息能提高主要信息的支持度,使得证据的每个部分都有自己的用处,避免了信息的丢失。

表5 融合结果

图2 两个证据的融合结果(m12)

图3 3个证据的融合结果(m123)
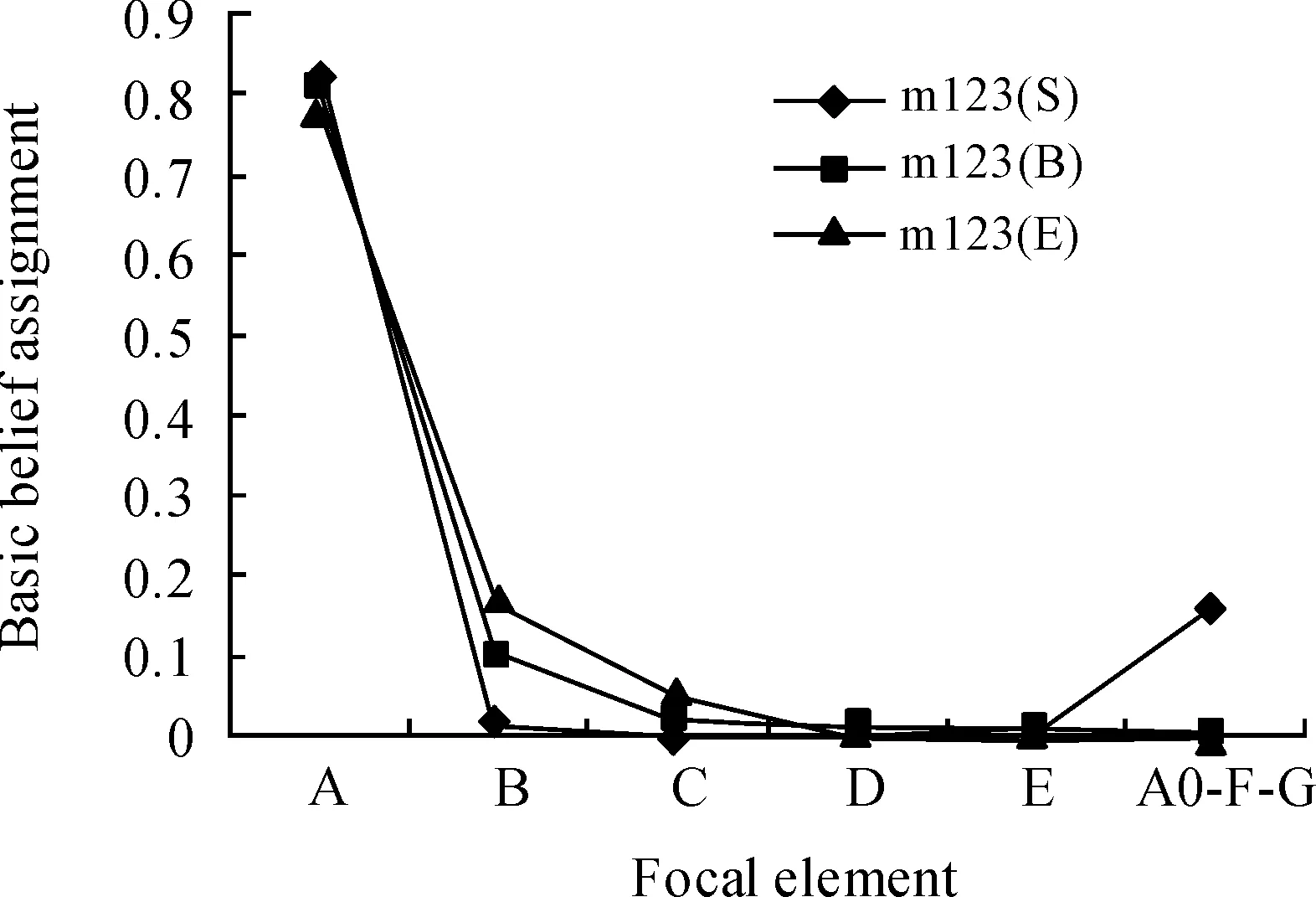
图4 4个证据的融合结果(m1234)
3.2 特殊情况仿真结果及分析
这里主要针对特殊情况(错误证据)的融合,由于Summarization近似算法通常对错误证据采取直接舍弃的方式进行处理,因此这里主要比较ELNA和Bayesian近似算法在特殊情况下的融合效果。
为了方便计算,在这里采用5个同证据等级的焦元进行融合,识别框架的概率分配函数及焦元如表6所示,因为ELNA主导证据的选取是完全随机的,在这里使用融合结果的期望值作为最终值,最终融合结果如表7所示。

表6 基本概率分配(BBA)及焦元
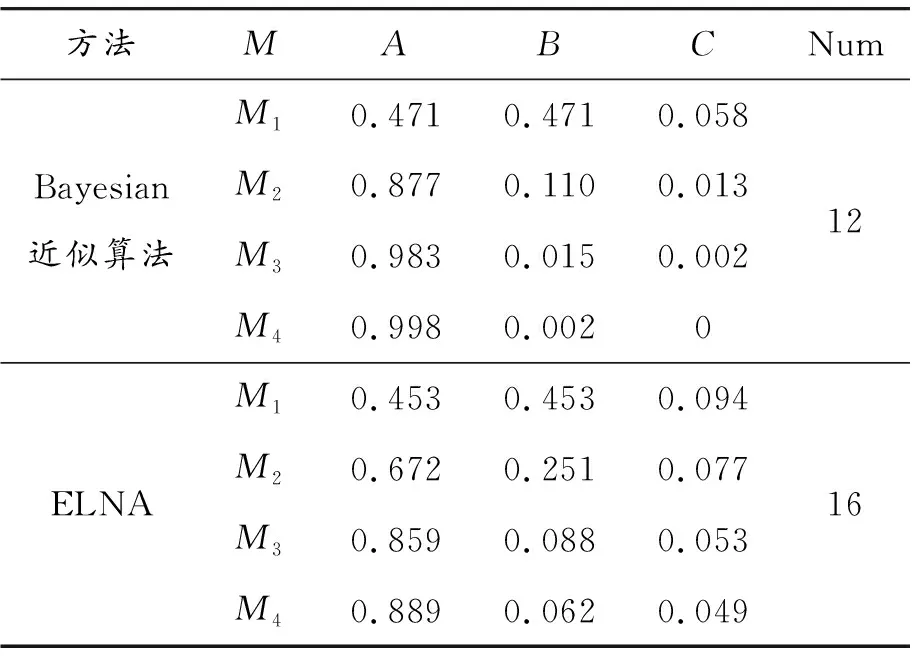
表7 融合结果
基于错误证据的融合分析结果可知:无论是Bayesian近似算法还是ELNA都说明只要融合足量的证据,即使其中掺杂着少量的错误证据也并不会对融合结果产生太大的影响。从计算的角度看,ELNA的主导证据的选取方式决定融合的证据越多融合结果的可靠性越强。从计算复杂度上看,ELNA只有在焦元个数多的证据融合方面优势明显,在应对焦元个数少的证据融合时并没有太好的表现。从融合结果各个焦元的数值上看,很显然ELNA的融合结果更符合实际情况,mass值较小的焦点C即使融合了4次0.1也能保持0.049的数值,较为直观地说明:焦元C是作为主要焦元而存在,符合5个证据焦元的实际情况。反观 Bayesian近似算法融合3次就基本忽略焦元C,融合4次焦元C的值就直接等于0了,甚至焦元B都明显被忽略掉了,很显然不符合实际情况。
4 结束语
本文提出了一种非主观的近似算法(ELNA),不需要人为判断的参与,使用ELNA可使传统的证据理论在实际中得到更广泛的应用。该算法利用焦元的累积mass值去划分证据的等级,根据不同的证据等级设定不同的初始标准,并且会将舍弃的焦元按比例分配到保留的焦元中,增加了证据的准确性,最后会根据证据的等级不同给予不同的权重值,进一步确保了融合结果的正确性。无论是对复合焦元、多焦元引发的“焦元爆炸”,还是在对错误证据融合上,ELNA都给予了相应的解决方案。适用性强且兼具准确性的特点使ELNA在参与特别是焦元数目较多且准确性要求较高的实际问题时优势明显。
猜你喜欢
社会科学战线(2022年7期)2022-08-26
法律方法(2022年1期)2022-07-21
社会科学战线(2022年3期)2022-06-15
中共云南省委党校学报(2022年1期)2022-04-26
小学生优秀作文(低年级)(2020年4期)2020-07-24
红土地(2016年3期)2017-01-15
社会科学(2016年6期)2016-06-15
幼儿智力世界(2016年6期)2016-05-14
小雪花·初中高分作文(2015年10期)2015-10-24
语言与翻译(2015年1期)2015-07-18
