
基于循环结构的卷积神经网络文本分类方法
2018-10-19 02:02陈波
重庆邮电大学学报(自然科学版) 2018年5期
陈 波
(陕西理工大学 数学与计算机科学学院,陕西 汉中 723001)
0 引 言
文本分类[1]在网页检索、信息筛选、情感分析等任务中是一个至关重要的步骤。文本分类中的关键问题在于文本表示,在传统机器学习方法中,通常以特征表示的形式出现[2-4]。文本分类中最常用的特征表示方法是词袋子模型[5]。词袋子模型中,最常用的特征是词、二元词组、多元组以及一些人工抽取的模板特征[6]。在以特征的形式表示文本之后,传统模型往往使用词频、互信息、概率潜在语义分析(probability latent semantic analysis, PLSA)等方法筛选出最有效的特征。然而,传统方法在表示文本时,会忽略上下文信息,同时也会丢失词序信息。
尽管传统特征中诸如多元词组以及更复杂的特征(如树核)也能捕获词序信息,但是这些特征往往会遇到数据稀疏问题,影响到文本分类的精度。
近年来,训练词向量以及深度神经网络模型为自然语言处理带来了新的思路[7],并且在文本分类应用上得到越来越多的关注与发展,在词向量的帮助下,有人开始研究基于神经网络的词和文档语义向量表示方法[8]。文献[9]提出一种结合全局词向量特征的循环神经网络语言模型,解决了循环神经网络语言模型中长距离历史信息学习这个缺陷。文献[10]中将迁移学习应用到文本分类中,解决了不同领域的文本分类问题。文献[11]中实现了深度信念网络对文本的分类,该方法将高维特征信息降维处理,在足够信息量的前提下,快速训练进行分类。文献[12]中提出用动态卷积神经网络(dynamic convolution neural network, DCNN)来构建文本语义,实现文本分类,该方法使用动态K最大池化,一种全局的线性序列池操作,处理不同长度的输入句子,并且能够明确地捕获短距离和远程关系的句子引入特征图,适用于任何语言分类。
因此,卷积神经网络在构建文本语义时会具备更大的潜力。然而,现有卷积神经网络的模型总是使用比较简单的卷积核,如固定窗口。该模型对窗口的大小要求比较严格,过大过小都会带来弊端,因此,如何构建模型,才能更好地捕获上下文信息,同时减少选择窗口大小的影响,是卷积神经网络的关键。
为了解决卷积神经网络分类模型的缺陷,本文提出了一种改进的神经网络模型处理文本分类,提出一种基于循环结构的神经网络文本分类方法,该方法只需要对文本进行单次正向及反向扫描,能够在学习单词表示时尽可能地捕获上下文信息,本文整体算法时间复杂度为O(n),是线性复杂度。该方法使用最大池化,来自动判断对文本分类最重要的特征。本文提出方法词向量窗口长度对文本分类性能没有影响,对上下文能有效地建模,既能很好地刻画上下文信息,又能无偏地描述整个文本的内容。本文采用了20Newsgroups数据集,对比了卷积神经网络和传统分类方法的性能。实验结果表明,本文方法具有较好的分类性能。
1 基于卷积神经网络文档表示
卷积神经网络(convolutional neural network,CNN)最开始由Elman等于二十世纪八十年代提出,CNN的基本结构如图1所示,由特征提取层和特征映射层构成。特征提取主要包含每个神经元的输入与其上一层局部接受域。每个特征映射层是一个平面,每个特征映射层上所有神经元的权值相等。
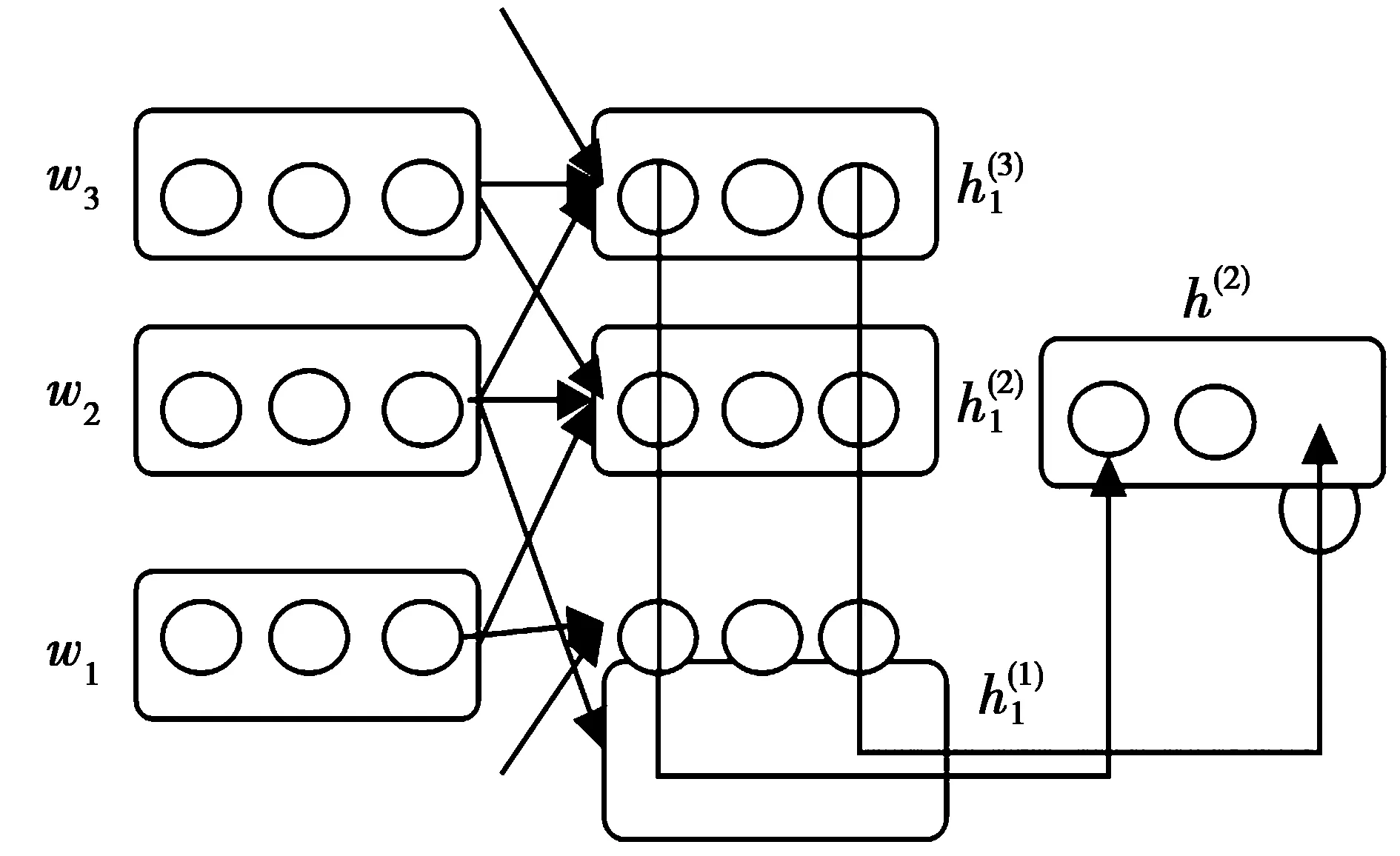
图1 卷积神经网络模型结构图Fig.1 CNN model structure diagram
CNN采取循环计算方式,算法如(1)式所示,从文本的第一个词循环计算到最后一个词。直到计算到最后一个词时,其对应的隐藏层表示出整个文本的语义。
h(i)=φ(H[e(wi);h(i-1)])
(1)
(1)式中:h(i)表示隐藏层输出;φ是非线性激活函数;e(wi)是词wi的词向量。CNN核心是局部感知和参数共享,局部感知即神经元不需要对全局图像进行感知,因为在更高层会综合局部的信息从而得到全局信息,所以只需要进行局部感知即可。隐藏层的每个节点只与输入层的一个固定大小的区域有连接,对于输入层的所有区域是权值共享的。输入层到隐藏层的公式为
xi=[e(wi-(win/2));…;e(wi);…;e(wi+(win/2))]
(2)
(3)
(3)式中:*表示卷积操作;xi为词wi的表示;wk表示权重;bk表示偏移量;g(·)为激活函数。得到若干个隐藏层之后,卷积神经网络常会采用最大池化,将不定长度的隐藏层压缩到固定长度的隐藏层中。本文采用最大池化,表示为
(4)
(4)式中,hi(1)表示池化层域内元素。卷积神经网络通过其卷积核,可以对文本中的每个部分的局部信息进行建模。CNN最大池化层(POOLING)可以从各个局部信息中整合出全文语义。
CNN是递归神经网络的一种特殊情况,较递归神经网络优势在于构建的时间复杂度低和便于捕捉上下文信息,可以处理长句子。但其也有缺点,针对正向的循环神经网络,文本中靠近后面的词主导地位较前面的词主导地位要高,从而导致在构建整个文本语义时,会使得文本更加接近于后面词的意思,影响文本表示的精确度。
2 基于循环结构的卷积神经网络文本分类方法
2.1 词表示
本文将词和其上下文组合在一起,用来表示一个词。本文使用一个双向循环结构来捕捉上下文。wi的上文表示为cl(wi),其表示见 (5) 式,wi的下文表示为cr(wi),其表示见 (6) 式。
cl(wi)=φ(w(l)cl(wi-1)+w(sl)e(wi-1))
(5)
cr(wi)=φ(w(r)cr(wi+1)+w(sr)e(wi+1))
(6)
(5)—(6)式中:e(wi-1)是词wi-1的词向量;w(l)是一个矩阵,表示把上文隐藏层转移到下一个词的上文表示中;w(sl)也是矩阵,表示将当前词语义合成到下一个词的上文表示中,φ是非线性激活函数。
图2为改进构建文本模型整体结构。图2中展示了例句“Keep on going never give up”的中间部分,其中,各元素的下标表示对应各词在句子中的位置。
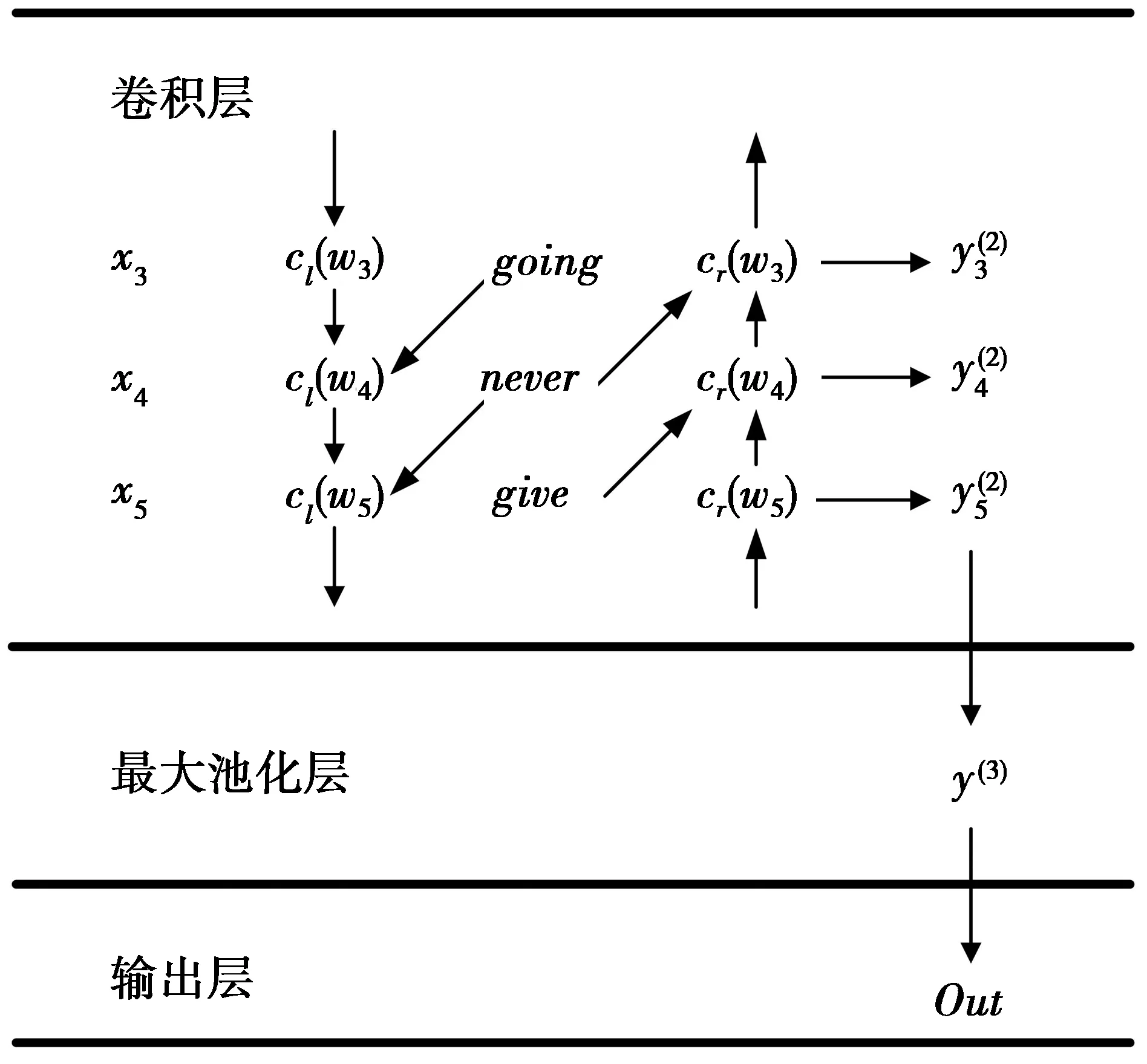
图2 改进构建文本模型整体结构Fig.2 Improved structure of building a text model
本文将词wi的表示xi定义为:词wi的上文表示cl(wi)、下文表示cr(wi)以及其词向量e(wi)的拼接。
xi=[cl(wi);e(wi);cr(wi)]
(7)
使用循环结构,只需要对文本进行一次正向(从左往右)扫描,就可以获得上文表示cl;同样地,只需要一次反向(从右往左)扫描,就可以获得下文表示cr,计算复杂度为O(n),使用这种循环结构捕获到的上下文信息,会比使用窗口表示的上下文有更好的效果。原因是,固定窗口的上下文表示方法只包含了部分上下文信息。
本文分析了Softplus函数及正线性单元(rectified linear unit,ReLU)激活函数的特性,结合两者的特点,改进得到新的激活函数具有稀疏与光滑的特性,表示为
(8)
当得到词wi对应的表示xi之后,采用改进激活函数作为神经元的激活函数,将值送入神经网络的下一层。
2.2 文本表示
本文使用循环结构的卷积神经网络来构建整个文本的语义。2.1节中的循环结构可以看作卷积核。当得到所有的词表示之后,本文在此基础上加入了CNN的最大池化层(POOLING),表示为
(9)
(9)式中,max操作是逐个元素计算的,也就是y(3)的第k维就是各yi(2)向量的第k维的最大值。通过最大池化,可以将不同长度的文本转成固定长度的向量,从而表示整个文本。本文选用CNN最大池化的主要出发点是,对于文本分类而言,最具决定性的词或者短语往往只有几处,而不是均匀散在文本各处。最大池化操作正好可以找出其中最有判别力的语言片段。模型的最后一部分是输出层,输出层定义为
y(4)=w(4)y(3)+b(4)
(10)
最后,使用softmax函数将输出值转为概率值。
(11)
2.3 模型训练
训练模型参数,训练目标为最大化以下似然
(12)
(12)式中:M是训练文档集;classD是文档D的正确分类。
本文使用随机梯度下降法来优化上述训练目标。每次迭代,随机选取一个样本(D,classD),按照(13)式进行梯度迭代计算。
(13)
(13) 式中,α表示学习速率。
在训练中,本文参考了Hinton的建议使用了一个神经网络训练中常用的优化技巧。所有的参数在初始化时均使用均匀分布,其中,随机数的最大绝对值为该元素入节点个数的平方根。入节点个数也就是神经网络中上一层的节点个数。对应的学习速率也同时除以入节点个数。
词向量是一种词的分布表示,这种表示更适合作为神经网络的输入。最近的研究表明,如果选择一个好的初始值,神经网络可以收敛到更好的局部最优解。
2.4 本文算法流程
由2.1—2.3节的算法描述,可以得到本文提出循环结构的卷积神经网络的算法流程,如图3所示。
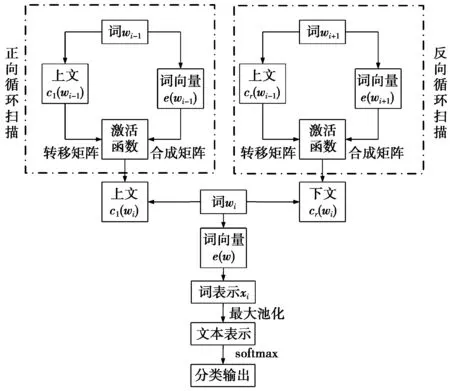
图3 循环结构卷积神经网络分类流程Fig.3 Cyclic structure CNN classification process
3 实验结果与分析
为了证明改进改进的构建文本分类模型的有效性,本文选用20Newsgroups数据集分别做了对比实验来进行证明。
20Newsgroups数据集,包括了20个新闻组的共约2万封邮件,是目前使用最广泛的英文文本分类数据集之一。该数据集有若干不同的版本,本文选用了BYDATE 版本,因为该版本已经将数据集分成了训练集和测试集,方便和现有工作进行对比。20Newsgroups数据集是不均衡数据集上文本分类数据集,样本数分为4个大类大约呈6∶3∶5∶3的比例。
3.1 模型参数
本文使用20Newsgroups对语料进行分词。文本中的停用词和特殊符号均当作普通单词保留。网络参数的选择一般需要根据数据的不同而有所不同。在实验中,使用参数分别为学习速率;隐藏层大小为100;训练工具包为word2vec;改进ReLU函数作为激活函数;卷积窗口大小为5,过滤器数为100,batch为50,dropout为0.5,迭代次数为10。
3.2 对比实验与结果分析
本文采用5种分类方法与本文提出方法进行比较,这5类方法分别是:词袋子+Logistic、二元词组+Logistic、词袋子+支持向量机、二元词组+支持向量机和卷积神经网络。本文采用准确率、召回率和F1值作为分类的性能指标。
向量维度的增加造成模型复杂度成倍增长,因此在实验中,特征向量维度的选择对实验结果有重要影响,本文对4种维度二位词向量矩阵(50,100,150,200)进行实验,采用十折交叉法,进行10次实验,取10次结果平均值,实验结果见表1所示。
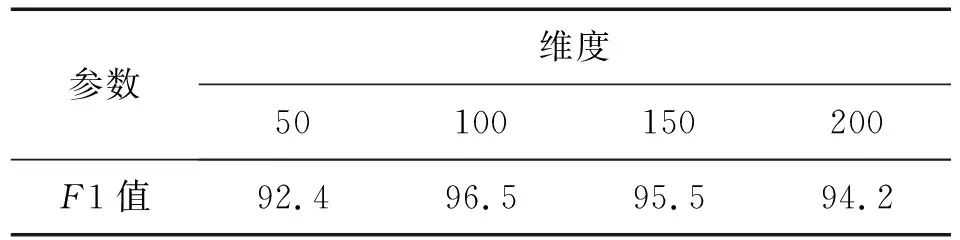
表1 不同维度向量实验结果Tab.1 Experiment results of different dimensional vector %
由表1可知,词向量维度为100维时能够得到最佳性能。
采用十折交叉法进行10次实验,最终结果为10次实验的均值,将本文方法与上述5种方法进行对比,在20Newsgroups数据集上的性能体现如表2所示。
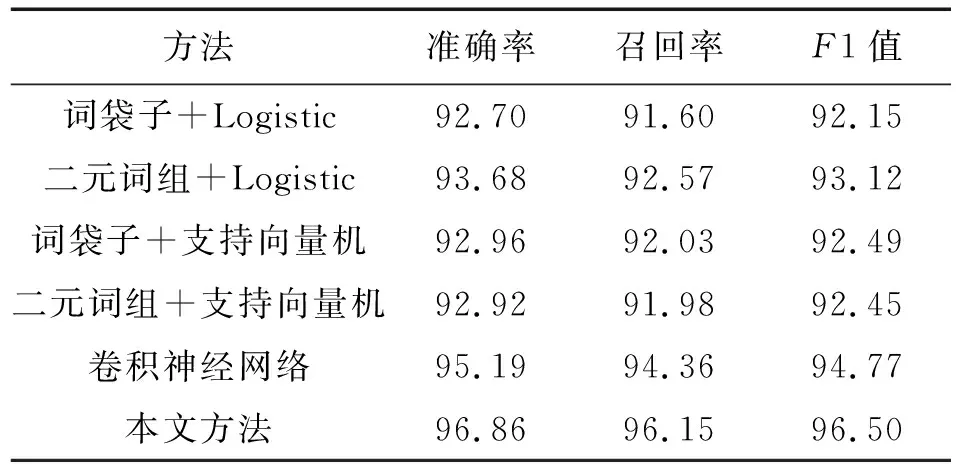
表2 文本分类结果
由表2数据可知,使用本文算法能够得到较好的分类结果,结合图5可以得出,基于特征及二元词组特征的传统分类方法,最多只有93.12% 的性能,相比而言,卷积神经网络性能达到了94.77%,而本文提出的循环结构卷积神经网络文本分类方法F1值达到96.5%,相对卷积神经网络的性能提高了1.73%;在文本分类性能上有明显的优势。
为了更好地体现本文方法,实验中采用从 1 到 19 之间的所有奇数大小的窗口,作为卷积网络中上下文信息的数据源。比如,窗口为1时,xi=[e(wi)],词的表示就是词向量。当窗口为 3 时,xi=[e(wi-1);e(wi);e(wi+1)],即词表示为当前词、前一个词以及下一个词的词向量的组合。
图4给出了在20Newsgroups数据集上,不同方法在不同窗口下性能对比结果,可以得到,卷积神经网络在不同大小的窗口下,在测试集上取得的评估结果。图4中的横坐标表示卷积神经网络选择的不同窗口大小,纵坐标为F1平均值,表示模型在测试集上的性能。由此可以得到,随着窗口的变大,测试效果先变好,再变差。当窗口大小取 10个词时(前5个词,后5个词),模型的性能达到最佳状态。而本文提出的方法不同大小的窗口下,在测试集上取得的评估结果。由此,可以得到窗口大小对本文方法性能无影响。
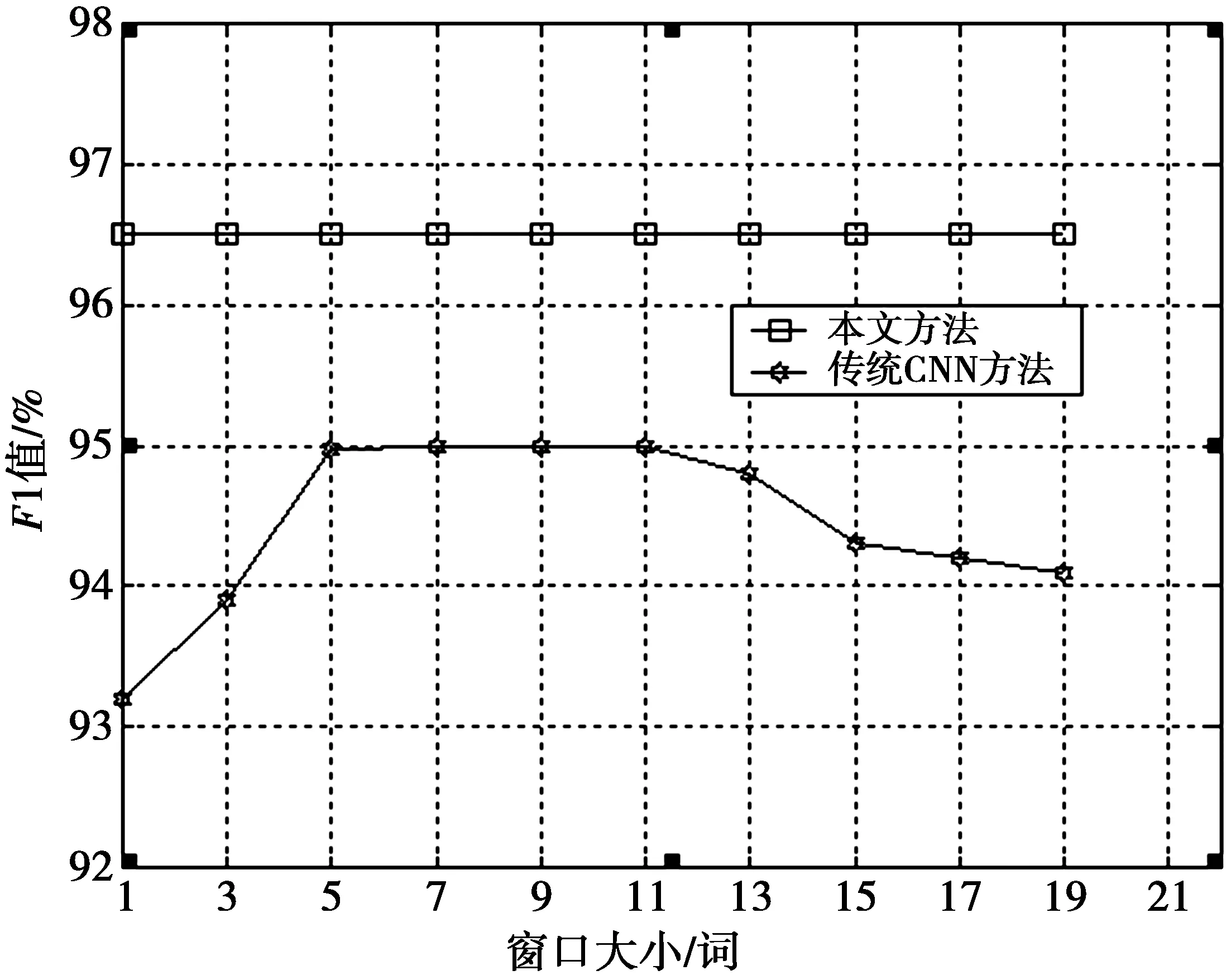
图4 不同方法在不同窗口下的性能Fig.4 Different methods in different windows performance
根据上述实验结果,可以得出,对比传统文本分类算法(词袋子+Logistic)和卷积神经网络方法,本文所提方法能够以更好的性能构建文本语义,实现文本分类。
4 结 论
本文在研究卷积神经网络分类方法的基础上,提出一种基于循环结构的神经网络文本分类方法,该方法解决了现有卷积神经网络在文本分类性能受到词向量窗口长度的影响这一问题,构建文本语义模型可以捕获长距离的依赖关系,词向量窗口长度对文本分类性能没有影响,对上下文能更有效地建模。另外,该方法只需要对文本进行单次正向及反向扫描,即可得到尽量多的上下文表示。实验结果表明,本文方法构建文本语义模型的准确率达到96.86%,召回率达到96.15%,F1值达到96.5%,性能优于传统文本分类算法和卷积神经网络方法。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
开放教育研究(2020年2期)2020-03-31
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
中国社会历史评论(2016年2期)2016-06-27
现代语文(2016年21期)2016-05-25
高中生学习·高三版(2016年9期)2016-05-14
