
基于多种变异机制的帝国主义竞争算法
2018-10-25 01:21洪晓敏王帅群孔薇
现代计算机 2018年27期
洪晓敏,王帅群,孔薇
(上海海事大学信息工程学院,上海 201306)
0 引言
帝国主义竞争算法(Imperialist Competition Algo⁃rithm,ICA)是一种群智能优化算法,由Atashpaz-Gar⁃gari和Lucas从帝国之间相互竞争的社会现象受到启发,于2007年提出[1]。与其他所有的元启发式优化算法一样,算法开始于种群初始化,每一个初始化的个体看作为一个国家,而国家又可以分为帝国主义和殖民地,随后通过殖民地同化、帝国与殖民地位置互换、帝国竞争与帝国倒塌等一系列步骤,最后算法收敛于全局最优值或近似收敛于全局最优值。
帝国主义竞争算法作为一类比较新的随机优化算法,其在解决低维问题上表现出其优势,但是在解决高维问题上,还存在一系列的问题,例如:容易陷入局部最优、收敛速度慢等。因此,很多学者致力于帝国主义竞争算法的改进。2011年,Niknam[2]提出了用K均值优化殖民地群体,用来避免算法未成熟先收敛。2014年,Yang采用混沌映射函数来初始化群体,使算法的搜索广度大大增加[3]。2015年,Wang将国家之间可以自由贸易这一现象映射到帝国主义竞争算法中,提出了基于贸易机制的帝国主义竞争算法,加快了算法的收敛速度[4]。2016年,梁毅将微分进化算子融入到帝国主义竞争算法中,用以避免个体过早收敛,并将改进的帝国主义竞争算法应用在分布式电源选址和定容的优化问题中[5]。至今,帝国主义竞争算法已经广泛应用在日常生活中的实际问题上:如土木工程中的结构模态参数识别[6]、WSNs定位方案[7]、短期风功率预测[8]、电网碳排放优化模型[9],以及无人机三维航线规划[10]。本文就是在这样的情况下产生的,拟在加快算法的收敛速度和跳出局部最优之间做出平衡,因此,在同化过程中融入了四种变异因子,提出了基于多种变异机制的帝国主义竞争算法(FICA)。
1 帝国主义竞争算法
帝国主义竞争算法的基本流程如下:首先是种群和帝国的初始化,初始的个体称作国家,根据适应度的大小(国家强弱)将其划分为帝国主义和殖民地,适应度大的为帝国主义,并且根据适应度的大小,为其分配殖民地。这与其他的智能优化算法不同,即是一种基于子种群的进化策略。随后,殖民地被帝国主义同化,即向优秀的个体学习使自己变地更强大,在同化的过程中,学习能力较好的殖民地有可能优于帝国主义,那么,当前殖民地则与帝国主义进行位置互换。而在帝国之间也存在竞争,较强的帝国主义通过侵略其他国家来使自己变得更强大,而较弱的帝国主义将会失去其殖民地,当一个帝国失去所有的殖民地后,该帝国倒塌。当算法达到预设结束条件,例如只剩下一个帝国主义或者最大迭代次数,算法将终止。帝国主义竞争算法执行过程一共分为六个模块,分别是个体和帝国初始化、殖民地同化、殖民地和帝国主义的位置互换、帝国总成本计算、帝国竞争和算法收敛。
1.1 个体和帝国初始化
帝国主义竞争算法的初始化个体称为国家,在遗传算法中称作染色体,对于一个D维的优化问题可以用一个D维的向量表示出来。如:

衡量一个国家的强弱用成本值来体现,成本值由成本函数 f来计算:

初始化种群的数目设为N,帝国主义的个数设为Nimp,剩余的国家则为殖民地,其个数为Ncol,并根据帝国主义的适应度大小为其分配殖民地。在最小优化问题中,帝国主义的强弱与其成本值成反比,即成本值越大,帝国主义的势力越弱。
在帝国初始化阶段,引入标准化成本值Cn,根据该成本值来衡量该帝国主义的比重,第n个帝国主义的实力占整个总实力的比例可以用下式表示:

其中Cn,满足Cn=cn-max{ci},cn表示第n个帝国主义的成本函数值,max{ci}所有帝国主义的成本函数最大值,因此,第n个帝国所能分得的殖民地数量如下式所示:

1.2 殖民地同化
帝国初始化后,将进行殖民地的同化,这也是帝国主义竞争算法的核心。在同一个帝国中,殖民地通过向帝国主义学习而使其变的更优秀,殖民地向帝国主义的移动过程如图1所示:
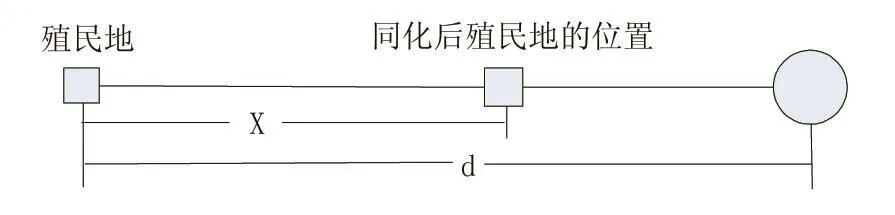
图1 殖民地向帝国移动过程
在图1中,殖民地向帝国主义移动了X个单位,X是随机均匀分布的变量,满足:

其中,α是大于1的数,d是殖民地与帝国主义之间的距离,a大于1可以保证殖民地从两边向帝国主义靠近。
1.3 殖民地和帝国主义位置交换
殖民地在同化的过程中,其势力有可能超过其帝国主义,在最小优化问题中,即殖民地的成本值有可能比帝国主义更低,则殖民地与帝国主义互换位置,如图2所示:
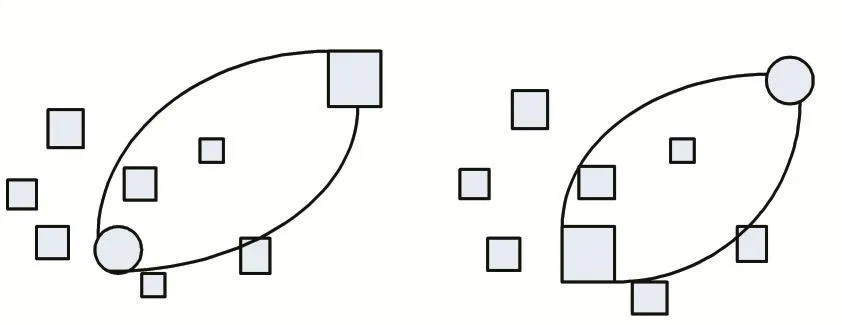
图2 殖民地取代帝国主义示意图
1.4 计算帝国总成本
帝国的整体实力应该由帝国主义与附属的殖民地共同决定,如式(6):
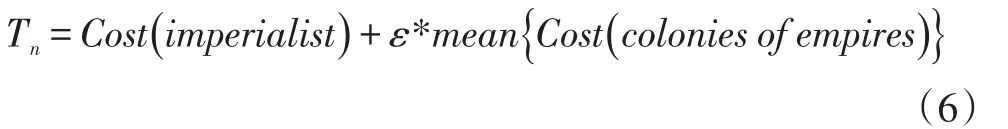
其中,n∈Nimp,Tn表示第n个帝国的总成本,ε是[0 ,1]之间的正数,不同ε值体现了帝国主义成本在总成本中对应的权重。ε的值很小时,帝国主义的成本在很大程度上将决定整个帝国的成本,随着ε值的增大,殖民地的比重将会增加,本文ε的值取0.1。
1.5 帝国竞争
在帝国主义竞争算法中,所有的帝国都试图依靠竞争来占有其他帝国的殖民地。帝国之间的竞争将导致弱的帝国失去自己的殖民地,该殖民地将分配给其他较强帝国。在竞争过程中,所有的帝国都有可能拥有该殖民地,不过,越强大的帝国将有更大的机会占有该殖民地,实力越来越强大,最终只剩下一个强大的帝国存在。其过程如图3所示:
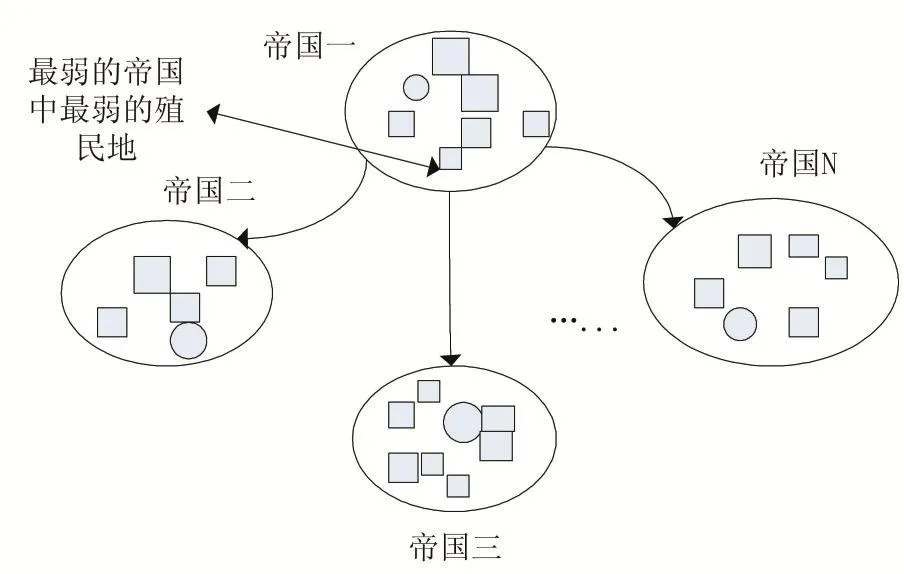
图3 帝国竞争
1.6 弱势帝国倒塌和算法收敛
帝国主义的倒塌,是指由于帝国之间的相互竞争,实力低的帝国会被剥夺他们所拥有的所有殖民地,即弱势帝国的崩塌。与此同时,强大的帝国会占有更多的殖民地,因此它们的势力也越来越强大。经过长时间的竞争,在本文当中指的是随着算法的迭代,会有一个帝国存留下来,这个帝国将会拥有所有的殖民地。与此同时,它与其所拥有的殖民地有相同的控制位置和成本。在这种情况下,帝国主义竞争算法将结束,而且算法收敛于最强大的帝国主义的位置值。
2 基于四种变异机制的帝国主义竞争算法
帝国主义竞争算法由于其在解决复杂问题的优越性被广大学者研究和关注,但它也存在一些缺陷,如容易陷入局部最优等缺点。本文将“国家之间不但可以相互学习,还可以自力更生,发展经济”这一现象映射到帝国主义竞争算法中,通过丰富算法的搜索动力学特性来使算法的性能更加优越,致力于既能提高算法的收敛速度,又可以避免算法陷入局部最优,一个好的变异机制能够快速地指导算法搜索到接近全局最优解的区域。在文献[11-12]中列举了很多变异因子,其中高斯变异因子[13]、柯西变异因子[14]、Lateral变异因子[15-16]和Baldwinian变异因子[17],因为其实现简单和易操作,被广泛研究和应用,且它们的搜索动力学特性不一样,高斯变异和柯西变异是基于个体自身的变异,仅仅给予当前个体一个步长,有利于跳出局部最优;Lateral变异因子和Baldwinian变异因子是基于个体之间相互学习,即利用了环境的因素,因此,算法具有较快的收敛速度。直觉告诉我们,可以将多个变异因子结合起来,形成一个多层变异机制,可以在加快算法的收敛速度和避免算法陷入局部最优之间做到很好的平衡。
2.1 多层学习机制
多层学习机制即多个变异因子都参与搜索过程,但在算法每次迭代过程中仅执行一个变异算子,不增加算法的复杂度。因此,在多层变异机制中,需对变异因子分配一定的概率,通过每次产生0~1之间的随机数和累计概率来控制每一次同化过程中选择哪一种变异因子,多层变异机制如图4所示。本文的终止条件指的是:算法迭代到指定次数,维度不同的函数最大迭代次数不一样,在后文中分别列出,下边将详细介绍四种变异算子。
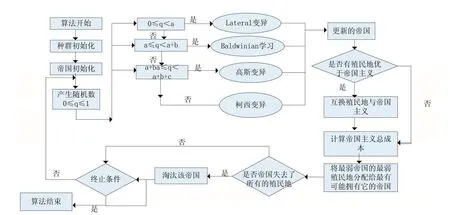
图4 FICA算法的流程图
2.2 变异因子的介绍
(1)高斯变异
高斯变异有两个参数:均值 μ和方差θ决定着变异的步长,均值为 μ和方差为θ的一维高斯密度函数为:
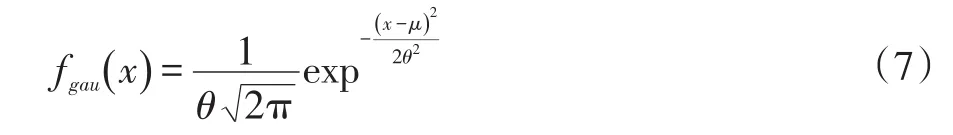
不难发现,通过高斯随机函数产生的高斯随机数,范围较小;换而言之,它能使个体在比较小的领域内进行仔细的搜索,所以当变异对象接近最优值或者已经陷入局部最优时,优先选择它。
(2)柯西变异
柯西变异主要是依靠柯西分布函数,其表达式如下:

与高斯分布函数相比,柯西分布函数具有较长的余尾,因此,具有比较大的步长,可以让个体进行较大幅度的变异,使得变异对象的搜索空间变大,因此它具有使算法跳出局部最优的能力。
(3)Lateral变异
Lateral变异的执行,所参照的表达式如下:

其中学习比率 β∈[ ]0,1是一个均匀分布随机数,它可以从种群当中随机的选择一个个体xkj,k≠i,利用该个体的信息特征来指导当前的搜索机制。因此,它可以更好地利用环境中的有效信息,这样可以加快算法的收敛速度。
(4)Baldwinian学习
Baldwinian学习主要是通过多个个体之间的相互学习、相互调节和相互适应,从而不断的对整个种群的进化起到一个推进作用。其表达式如下:
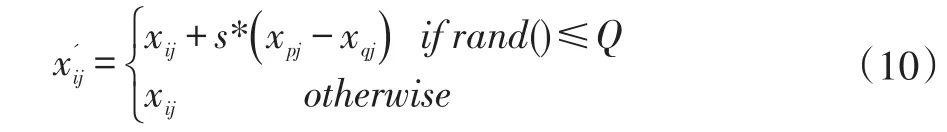
它可以充分利用环境中的变异对象之间的信息不同,进而让环境中的信息充分利用,可以加快算法的收敛速度。
2.3 FICA的流程
本文中提出的FICA的流程图如图4所示,主要操作如下:
步骤一:参数设置。
步骤二:在针对每一个目标函数所规定的搜索空间内随机产生N个国家,维度为D。
步骤三:计算种群中每一个国家的适应度 f(Xi),适应度较大的Nimp个国家作为帝国主义,其余的则为殖民地。
步骤四:执行多层学习机制:产生一个随机数,根据随机数的大小,来确定每次迭代执行哪种变异算子,通过变异来得到更新后的帝国。
步骤五:判断同化后的殖民地是否优于其帝国主义,倘若有,互换殖民地与帝国主义的位置。
步骤六:计算帝国总成本,并将最弱帝国的最弱殖民地分配给最有可能拥有它的帝国。
步骤七:判断是否有帝国失去了所拥有的殖民地,假若有,则淘汰该帝国;假若没有,继续步骤四。当算法达到最大迭代次数,即便还没收敛(还剩下不止一个帝国),算法也终止了。
3 实验结果
3.1 算法参数设置
四种变异因子各有不同的搜索动力学特性,在此通过引用多层学习机制,将它们联合起来,并且嵌入帝国主义竞争算法中,让所有的变异因子一起参与算法的搜索,才有可能更好地提高算法的性能。在本文中,对每一种变异机制都规定一定的执行概率,通过产生一个随机数,根据随机数的大小,来确定当前执行哪种变异。在不影响算法的收敛速度的情况下,又尽可能地避免算法陷入局部最优,在本文中高斯变异因子、柯西变异因子、Lateral变异因子和Baldwinian变异因子的执行概率分别设置为0.1、0.1、0.4、0.4,产生的随机数的大小在0到1之间。
为了与其他文献进行比较,初始的种群个数设为88,并且设定帝国主义国家的个数为8,则殖民地个数为80,将基于多种变异机制的帝国主义竞争算法在23个基准函数[17]上进行仿真实验,所有的仿真和统计结果均来自算法独立运行20次,前13个高维函数,最大迭代次数为2000,后10个低维函数,最大迭代次数为100。
3.2 结果分析
表1列举了基于多种变异机制的帝国主义竞争算法FICA和原始的帝国竞争算法ICA在23个基准测试函数上的仿真结果。从以上MATLAB的运行结果可以发现,FICA在函数 f6,f9和 f11上均在指定的迭代次数内得到了函数理论上的最优解,而ICA还远远没有达到,由此可以看出FICA在此三个函数上的收敛速度和跳出局部最优的能力得到了加强。 f1,f2,f3,f4,f5,f7,f8,f10,f12,f13,f15虽然针对这几个函数FICA并没有在指定的迭代次数内找到理论的最优值,但是相比较于ICA,FICA所求取的最大值与最小值均要比ICA小很多,也就意味着精度高很多。针对函数f14,f16,f17,f18,f19,f20,FICA和ICA最后得到的收敛值是一样的,也都到达了理论上的最优值,但通过各自的收敛图,可以看出FICA收敛。速度明显要快,如图 5、图 6、图 7、图 8、图 9、图 10所示。针对 f21,f22,f23这3个函数,虽然FICA与ICA最后得到的收敛值相差不多,但是ICA的均值离理论值的绝对值要比FICA的大,同时其方差也更大一点。
这表明FICA要比ICA的值更加靠近理论值。
4 结语
本文提出了一种基于多种变异机制的帝国主义竞争算法,在帝国竞争算法的最核心步骤——殖民地同化的过程中,将Baldwinian学习因子、Lateral变异因子、高斯变异因子、柯西变异因子相融合实现殖民地的同化机制。高斯变异和柯西变异利用了自身的随机扰动,而Lateral变异和Baldwinian学习充分利用了环境中的信息,这样使得融合后的变异机制具有更强的全局寻优能力。本文将FICA和ICA应用在23个基准函数上,通过比较验证了FICA具有更快的收敛速度与跳出局部最优的能力;同时在所有条件相同的情况下,FICA所得实验结果与算法CICA、AICA在3个函数上进行比较,通过比较验证FICA具有更好得跳出局部最优的能力。在本文中,并没有每个变异因子的执行概率,展开讨论,在后续的工作中,将探索更好的执行概率值,以提高算法的性能。
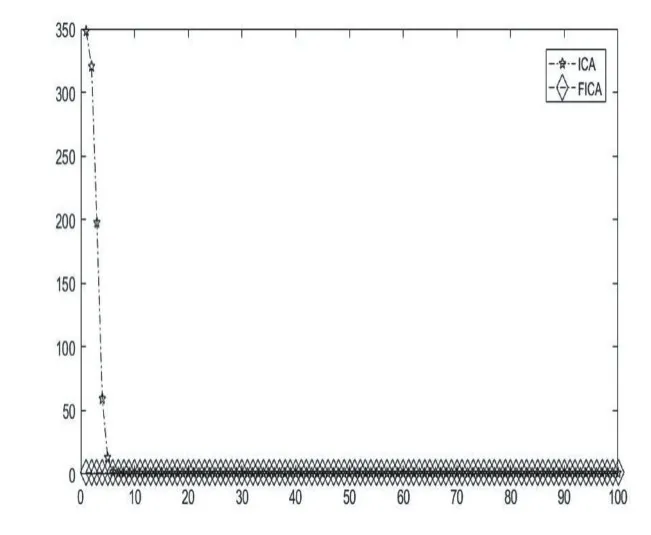
图5 函数 f14的收敛图
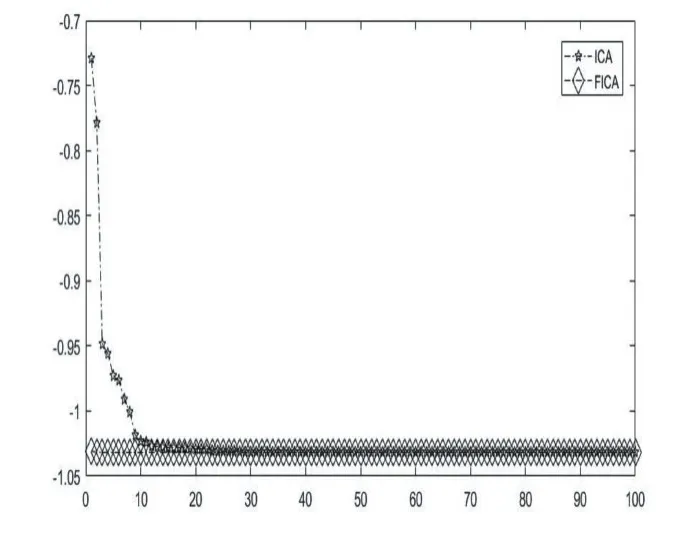
图6 函数 f16的收敛图
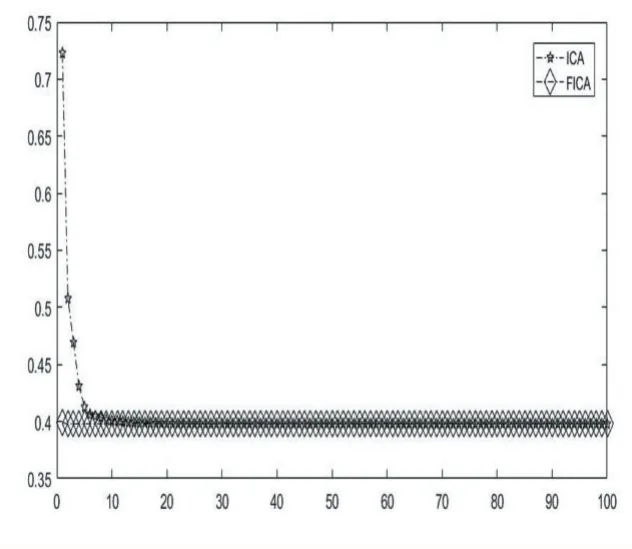
图7 函数 f17的收敛图
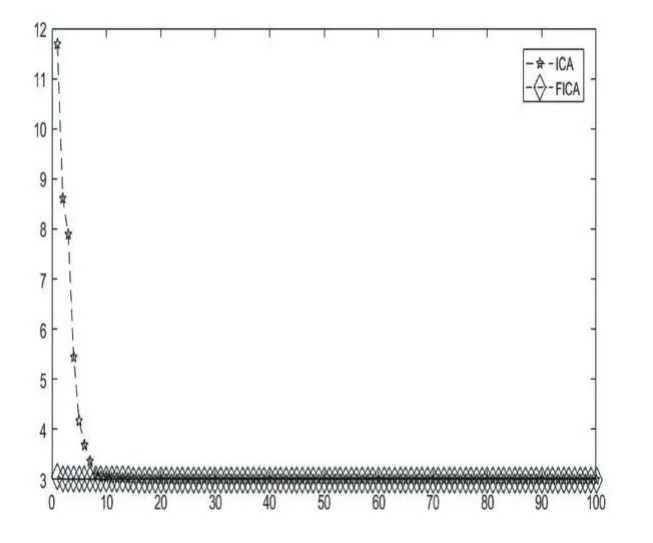
图8 函数 f18的收敛图
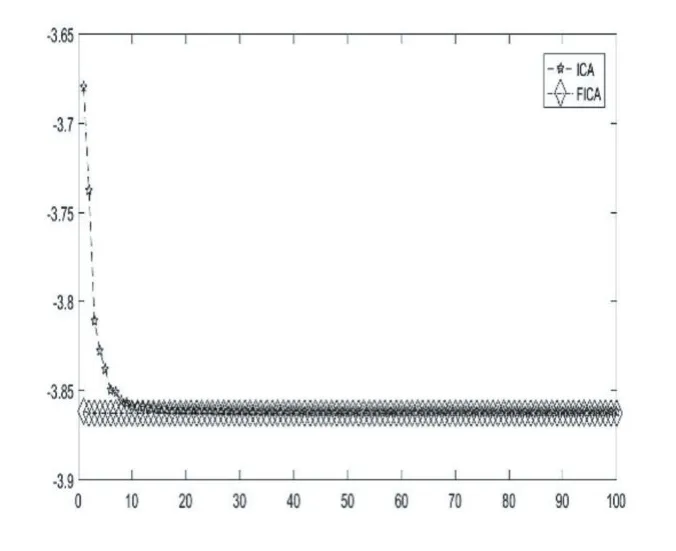
图9 函数 f19的收敛图
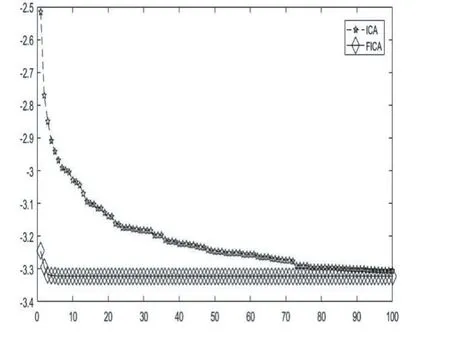
图10 函数 f20的收敛图
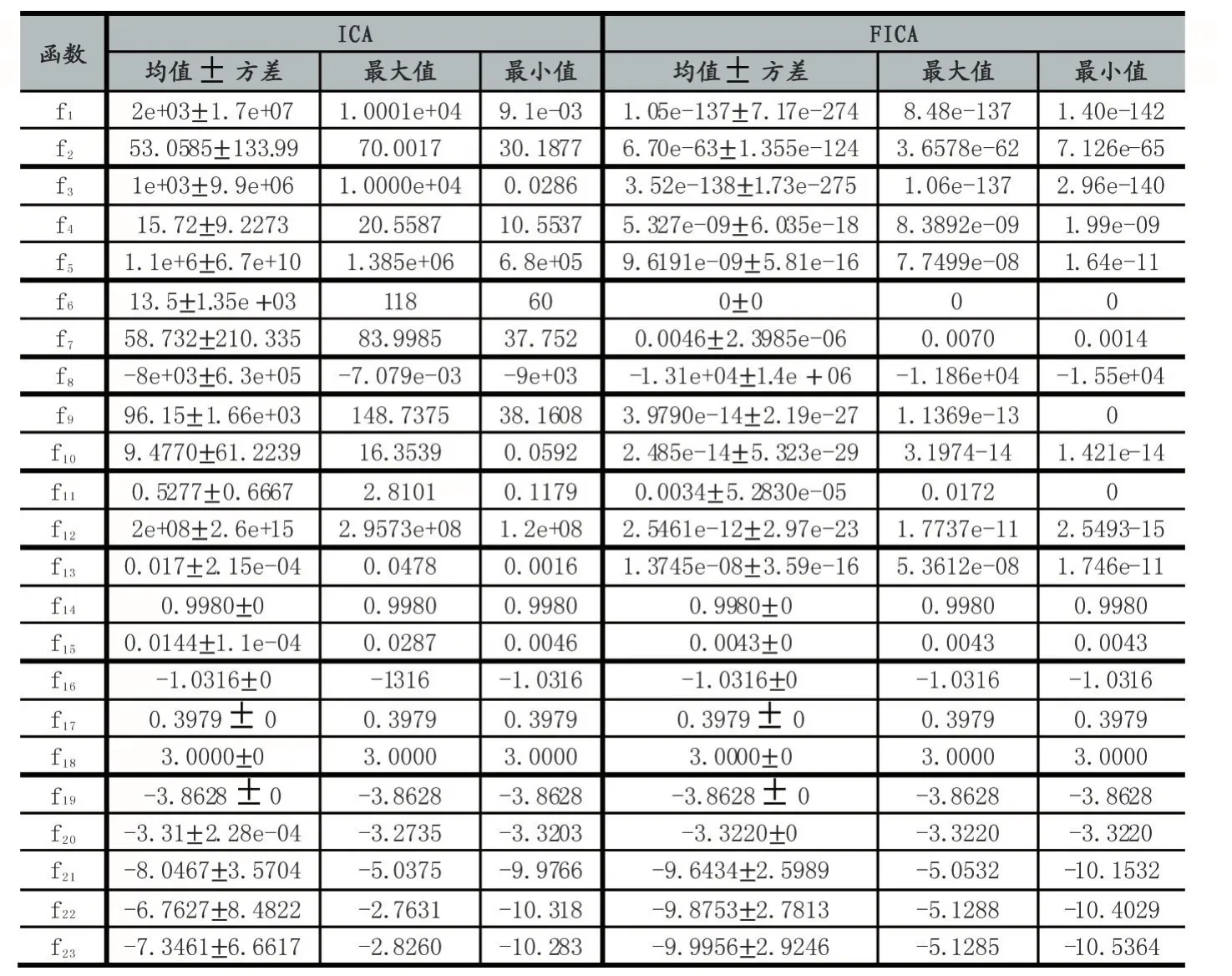
表1 横向改进:FICA与原始帝国主义竞争算法的比较争算法的比较
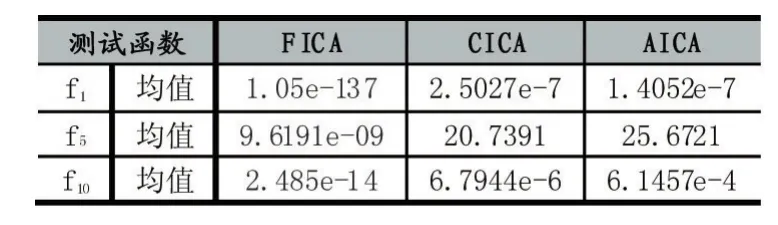
表2 纵向比较:改进的帝国竞争算法与其他优秀帝国主义竞争算法的比较
猜你喜欢
社会科学战线(2022年8期)2022-10-25
小哥白尼(神奇星球)(2022年5期)2022-08-15
小哥白尼(神奇星球)(2022年4期)2022-06-06
小哥白尼(神奇星球)(2022年3期)2022-06-06
英美文学研究论丛(2021年2期)2021-02-16
辽宁省博物馆馆刊(2020年0期)2020-08-13
人民论坛(2016年32期)2016-12-14
党史文苑(2016年21期)2016-12-01
党史文苑(2016年17期)2016-09-10
黑龙江史志(2014年9期)2014-11-25
