
山东农业大学硕博士论文摘要语料库的研制
2018-10-25 08:21葛晓帅司艳辉
山东农业大学学报(社会科学版) 2018年3期
□葛晓帅 司艳辉
一、引言
Sinclair在《Corpus, Concordance, Collocation》中写到“当同时观察大量的语料时,语言看上去会截然不同(The language looks rather different when you look at a lot of it at once.)。”[1](P:100)为了能够大量观察语料,在上世纪六十年代,美国布朗大学的学者率先建成了世界上第一个大型电子语料库,即著名的布朗语料库(Brown Corpus)。自此,语料库日益成为语言研究和调查的重要方法。
我国的电子语料库建设始于1979年武汉大学建立的汉语现代文学作品语料库。之后,国内涌现了一大批通用或专用语料库,如清华大学建设的现代汉语语料库,广东外语外贸大学与上海交通大学合作研制的中国学习者语料库(CLEC)等。专用语料库中关注摘要这一语类的并不多见,现有的也主要关注期刊摘要[2][3]。近年虽出现了对硕博士论文摘要的研究,也集中在语言学领域的论文[4][5]。这些语料库一般库容较小,仅包含几十上百篇摘要;语种单一,仅搜集英文摘要,通常用于中外摘要的对比研究。牛桂玲[2]创建的中外学术论文中英文摘要语料库是笔者所知的唯一一个中英文平行摘要语料库,其搜集的摘要也都来自权威期刊。对硕博士论文摘要的研究,尤其是平行语料的研究,尚且无人涉及。
硕博士论文是学生阶段学术水平和写作水平的集中体现。无论汉语摘要还是英语摘要,都经过反复修改润色,反映了一个学生对两种语言驾驭的最高水平。硕博士论文摘要的研究对汉语和英语的教学有重要启示,如辅助翻译教学,学术英语教学等。
硕博士论文摘要的研究如此匮乏,思考其背后的原因,笔者认为缺乏研究对象,也就是缺乏硕博士论文摘要的语料是重要因素。期刊摘要较易获取,通常可通过期刊所在出版社网站检索到完整的摘要;硕博士论文摘要则难以获取,构建一个大型硕博士论文摘要语料库更是费心费力。我们经过两年的搜集和整理,研制了山东农业大学硕博士论文摘要语料库(后简称山农摘要语料库)。
二、语料库的设计与建设
(一)语料库的总体设计
语料库的建设必须首先进行总体设计和规划。山农摘要语料库设计包含两个子语料库:一是翻译语料库,二是平行语料库。
翻译语料库包含所有可获取的硕博士论文中英文摘要以及语料的元信息。在翻译语料库基础上对各年份和学科进行抽样,通过人工对齐双语语料,建成具有代表性和平衡性的句级平行语料库。
(二)翻译语料库的建设
翻译语料库由彼此具有翻译关系的原文与译文构成,但原文与译文之间没有进行段落、句子乃至词语层面上的对齐处理。[2](P:35)一篇硕博士论文的汉语摘要与其对应的英语摘要构成一对翻译语料,将多篇论文摘要搜集整理可构成翻译语料库。山农摘要语料库的子库即翻译语料库计划包含所有可获取的山东农业大学硕博士论文的摘要。
1.语料的采集
语料来源为中国知网。采集知网全部学位授予单位为山东农业大学的硕博士论文中英文摘要。
具体检索方式为:打开知网检索页,选择“博硕士”论文库,选择检索条件为“学位授予单位”,输入“山东农业大学”检索。
山东农业大学1978年获批硕士点,1986年开始招收博士研究生;但早期硕博士论文未进行电子化,知网可获取的最早论文为2000年的1篇硕士论文。
截至2017年9月28日,按照上述检索条件,在知网可搜索到10 539篇硕博士论文,其中53篇在网页上无摘要或摘要不完整(博士6篇,硕士47篇),可获取摘要的论文共10 486篇。
综上,摘要的时间分布范围为2000年至2017年9月底,共采集10 486篇论文的双语摘要。
2.采集内容
根据总体设计,除了中英文摘要本身外,应尽可能采集语料的元信息,包括中文标题、英文标题、副标题、作者姓名、指导教师姓名、学科专业、级别(硕士或博士)、写作年份、中文关键词、英文关键词、下载数量等。元信息越详尽,越能丰富今后的研究角度。
3.具体采集步骤
(1)按照上述采集条件检索出符合条件的论文列表。
(2)点击结果的“中文提名”打开其中文摘要页面。
(3)将中文摘要页面网址中开头的“kns”替换为“eng.oversea”,点击回车即可看到中英文摘要页面。
(4)采集页面上所需信息。
4.语料的存储
语料的常用存储方式为纯文本文件,纯文本文件便于读写,但难以存储元信息,难以按照指定条件查找特定文本。例如,在纯文本文件中查找2015年果树学方向的所有博士论文英文摘要很难实现。虽然有在文件头部添加元信息标签的方案,但元信息标签会污染原文,给后续的检索工作带来麻烦。
山农摘要语料库采用数据库存储的方式。数据库文件可以简单理解为常用的MS Excel工作簿,一个数据表相当于Excel的一个工作表(sheet),一个数据表的字段类似于Excel表的一列。每篇论文的摘要占一条记录,即一行,每条记录都包含下面各字段(列)内容:
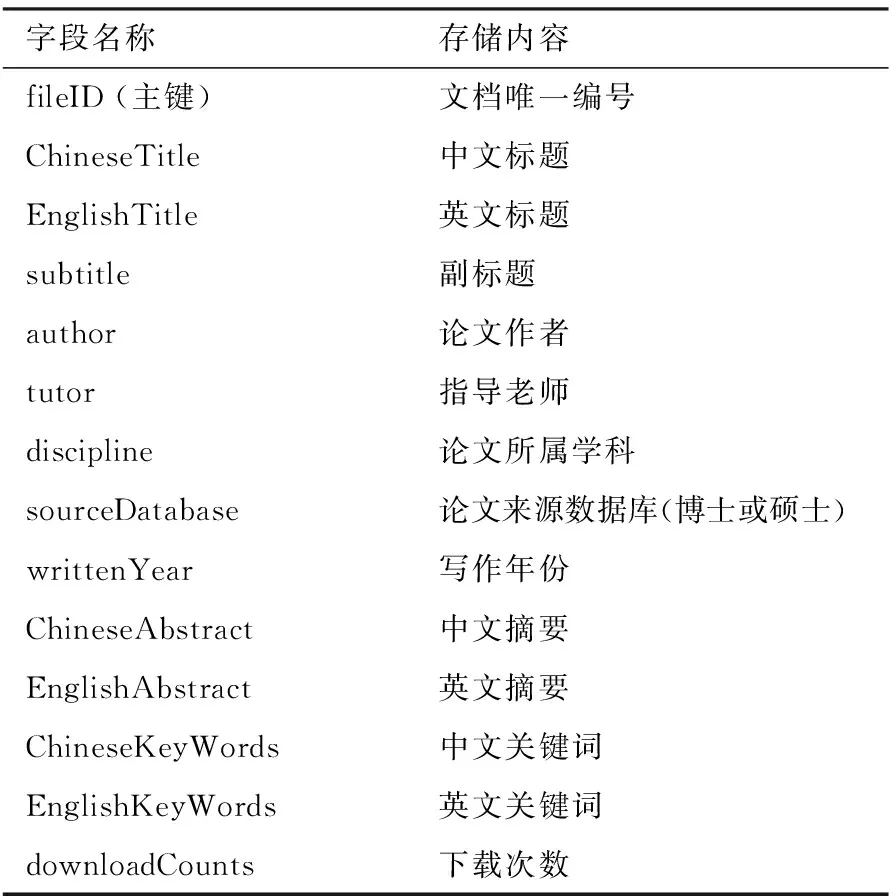
表1 语料库存储表字段设计
数据库存储有两个优势:
(1)分字段存取
不同信息被分别存入不同字段,可按需求导出。
例如上文提到的2015年果树学方向的所有博士论文英文摘要,只需要按照指定条件写出SQL查询语句:
“SELECT EnglishAbstract FROM Abstracts WHERE writtenYear=’2015’AND discipline=’果树学’AND sourceDatabase=’博士’;”
即可从数据库中导出语料为纯文本文件,构成符合要求的语料库。这种便利性是纯文本存储方式无法实现的。
(2)方便数据分析
每篇摘要均有一些常用的描述性指标,如单词数,平均词长,平均句长等。取得这些指标数据后存入相应字段,会为之后的数据分析提供极大便利。
翻译语料库在语料存入数据库后即已完成,可根据研究需要导出纯文本文件,随时构建语料库。翻译语料库总库容为汉英摘要各10 486篇,汉语摘要共计10 828 933字次,英语摘要共计6 277 006词次。
完成翻译语料库的建设后,下一步是建设平行语料库。
(三)平行语料库的建设
平行语料库是指收录某一源语言文本及其对应的目的语文本的语料库,不同语言文本之间构成不同层次的平行对应关系[6](P:33)。平行语料可在语料库级,篇章级,句子级和句珠级等层次进行对齐。[7](P:9)鉴于当前自然语言处理以句子为单位,因此大部分双语语料是以句对形式出现。[8](P:221)句对即为句子级别对齐,山农平行语料库同样采用主流的句对齐方式。
语料之间的平行对齐处理是一项难度较高而且耗费时间和精力的工作。[6](P:34)汉英语料按照句子对齐需要大量的人工介入,将篇章级对齐的一万多篇语料进行一一句子对齐在短期内难以完成,鉴于此,我们进行了科学分层抽样,考虑了学科、年份、硕博士论文比例后选取了596篇论文的中英文摘要进行人工对齐。
1.句子的界定标准
对齐语料需要将汉语句与其译文英文句子一一对齐。在对齐前首先要进行句子划分。句子的划分标准通常采用句号、问号及感叹号。然而考虑到摘要本身的特点,如汉语句多用长句,有时一段话仅包含一个句子,而其对应英文翻译却包含多个句子。咨询相关专家后,在不影响句义完整性的条件下,可将部分冒号和逗号也作为句子的界定标准,即如果按照冒号或逗号进行划分能够得到更小的句对,则按照冒号或逗号划分句子。在实践中,汉语句的逗号是常见的句子划分标准。
2.对齐操作
对齐操作采用Tmxmall Aligner[9]在线对齐系统。Tmxmall Aligner是一款在线的免费双语对齐工具,有自动句对齐功能,如果提前进行了段落级别的对齐,其自动句对齐效果也非常显著,能大量减少人工对齐的负担。
每一篇选定的论文汉英摘要各存入一份纯文本文件,汉语文件以“论文编号-CN.txt”命名,英语文件以“论文编号-EN.txt”命名。如某篇论文编号为205011089,则其对应汉语文件名为“2015011089-CN.txt”,英语文件名为“2015101089-EN.txt”。
我们首先对团队成员进行对齐操作培训,并进行试对齐。统一标准后进行正式对齐操作。
分配对齐任务,团队成员在线进行对齐操作,完成后导出对齐的tmx格式文档,文件名为论文编号。tmx格式是通用的翻译记忆库交换格式,各大翻译辅助软件如Trados等均支持tmx文件。
汇总tmx文件,将tmx文件转换为纯文本文件即建成句子级对齐平行语料库。
平行语料库总库容为汉英摘要各596篇,对齐句数15 849句对,汉字676 355字次,英文356 257词次。
3.平行语料库检索软件的开发
平行语料库建成后,我们考察了现有的四款平行语料库检索软件,发现各有优缺点,但均无法满足我们的需要,如ParaConc是收费软件,其他的软件或者无法处理大规模语料,或者对中文支持不友好。借鉴各软件的优点,并设计增添了新的特性后,我们自行开发了SDAU-ParaConc平行语料库检索软件。该软件除支持纯文本文件外还可直接导入tmx文件检索,自动识别对齐方式,检索速度更快,结果界面更友好,能大幅减少语言研究者的学习使用成本。软件现可在北外语料库语言学工具页[10]下载。
综上所述,山农摘要语料库构成可总结为下述图表:
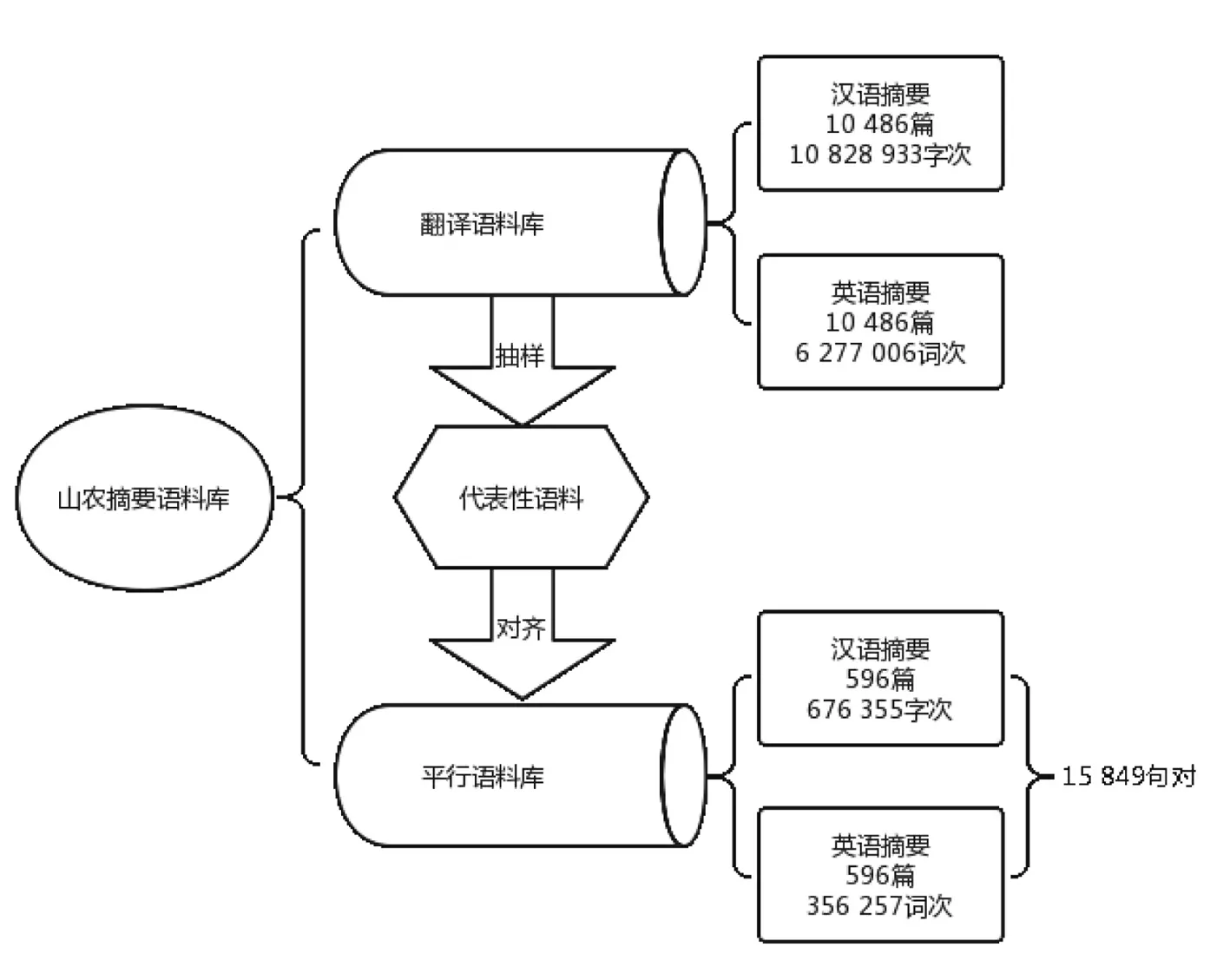
图1 山农摘要语料库的构成
三、山农摘要语料库的特点和用途
建成的山农摘要语料库有三个特点。第一,全面性。该语料库是首个对一所院校的硕博士论文摘要全面收录的语料库。第二,首创性。该语料库的平行语料库子库是第一个硕博士论文摘要汉英平行语料库。第三,灵活性。语料存储采用数据库方式,便于按需导出语料。
以上三个特点使得语料库可分可合,可横向对比也可纵向对比。将语料分为单语语料库,可进行汉语或英语单语研究;将语料合并,可进行翻译研究;将语料按照不同学科分割,可进行学科间的横向对比;按照年份划分语料则可进行学科内的纵向对比研究。
语料库建设是基础建设,在其基础上能够开展多种多样的研究。可预见的研究方向有:
语言研究:对摘要语言特征进行研究,如词汇、句法、文体等。
翻译研究:硕博士论文摘要是一项汉译英翻译活动,可进行翻译的显化隐化研究,翻译错误研究等,这些研究能进一步促进翻译教学的改革。平行语料库还可作为机器翻译记忆库,进行计算机辅助翻译研究。
教材编写:EAP教材可以从相关学科语料获取词表等辅助教材编写。
文献计量学研究:文献计量学与语料库语言学都依赖关键词分析。[11](P:36)对学校发表的硕博士论文进行文献计量学研究能够为学校的学科建设和发展提供参考。
四、总结
山农摘要语料库的研制填补了大型硕博士论文摘要语料库的空白,其采用的数据库存储方式为语料库增添了强大的灵活性,能够按照研究者的需要提供相应的语料库,供研究者进行多种角度的研究。其平行子库,是第一个硕博士论文摘要句级对齐平行语料库,在计算机辅助翻译、翻译教学研究等方面均可提供支持。我们还开发了平行语料库检索软件SDAU-ParaConc,获得了同行认可,也为未来研究提供了便利的工具。
