
一种保护链接关系的分布式匿名算法
2018-10-26 02:23张晓琳何晓玉于芳名刘立新张换香李卓麟
小型微型计算机系统 2018年9期
张晓琳,何晓玉,于芳名,刘立新,张换香,李卓麟
1(内蒙古科技大学 信息工程学院,内蒙古 包头 014010)2 (中国人民大学 信息工程学院,北京 100872)
1 引 言
随着互联网技术的飞速发展,社会网络,无论是社交网站(Wechat、Facebook、Twitter等)还是用户交互网络(如emails、blogs、文件分享系统)已然成为当今人们日常网络生活中不可或缺的一部分.用户主动或被动提交的好友互动记录、兴趣爱好、消费信息等包含了大量社会结构信息和属性信息,但随着用户网络形象的进一步丰富,能够用于确定用户真实身份的信息也越来越多,如何保护网络数据中隐私信息的安全性成为隐私保护研究的热点问题.如图1所示,社会网络表示成简单无向图,图中的节点和边分别对应社会网络中的个体以及个体间的联系.社会网络中个体的属性信息,如年龄,在图中则用节点的标签来代替.如若节点具有多个标签,则将这些标签称为节点的标签列表,如(Afri,20)是节点1的标签列表.
社会网络图中,节点的标签信息尤为重要,攻击者能够将标签信息作为背景知识对节点进行重识别.在图G中,假如攻击者获知目标是一个28岁的亚洲人,由于节点标签的唯一性,攻击者很容易从图G中重识别出节点5.

图1 社会网络图GFig.1 Social network graph G
为了抵抗通过节点标签为背景知识的重识别攻击,研究者提出了不同的隐私保护技术[1,2],通过标签范化等方法使得社会网络图节点的标签不唯一而达到隐私保护的目的.文献[3]指出即使个体的身份信息被有效的隐藏,攻击者仍能推测出个体的链接关系.以图G为例,如若攻击者得知目标是一个25岁的亚洲人,此时,攻击者由图G得到节点2和3.尽管这种情况下无法唯一确定目标,但由于节点2和节点3之间存在边,无论两者谁是攻击目标,攻击者都可以认为攻击目标与亚洲人存在联系.此外,随着社会网络的普及与发展,社会网络数据的规模不断增大,呈现出海量化的趋势.对于大规模社会网络数据,传统匿名技术已不能满足实际需求,采用并行算法进行匿名处理是提高效率的有效途径.如何对隐私保护技术进行并行处理并对社会网络中个体提高有效隐私保护成为亟待解决的问题.
2 相关工作
为了保护社会网络中的隐私信息,研究者提出了不同的隐私保护方案.文献[4]将属性视作节点,利用分割用户节点的方法保护隐私信息.文献[5]提出 k-degree-l-diversity匿名模型,通过图的匿名化操作使得分组内的节点具有相同的度信息且分组所包含的敏感标签不少于L个.文献[6]利用k-histogram和Full-domain泛化技术保护带权社会网络中的隐私信息,在匿名图中,攻击者通过节点权重包识别出节点的概率不大于1/K,通过节点标签识别出节点的概率不大于1/L.文献[7]提出一种利用节点子图匹配相似度的多敏感属性t-closenss匿名方案,保持了数据的高可用性.文献[8]提出一种个性化的敏感属性(α,k)-匿名模型用于满足用户的个性化需求.文献[9]考虑到现实中用户决定自己敏感信息因人而异的特点,提出一种基于相似性的分组匿名GSGA算法.文献[10]将用户交互社会网络抽象成二分图模型,通过为用户产生一个标签列表的方式抵抗重识别攻击.文献[11]针对目前的保护技术不能够处理高维数据的缺点,提出一种节点带标签的二分图匿名模型.文献[12]提出一种utility-aware匿名方法,在进行k-degree匿名时同时考虑最短路径和邻居节点重叠度,提高了匿名图的数据可用性.随着社会网络规模的不断扩大,不少研究者提出了分布式处理的方案.文献[13,14]提出了利用MapReduce模型在大规模图中查找同构子图.文献[15,16]基于MapReduce模型对关系型数据进行匿名保护.文献[17]提出基于SMC(Secure Multi-Party)模型的隐私保护方案.然而,目前的分布式隐私保护技术都是针对关系型数据的,没有考虑个体在社会网络中的图性质特征不能很好地保护隐私信息.此外MapReduce将中间结果存放于磁盘,处理过程中需要反复迁移数据,并不适合处理图数据.
GraphX[18,19]是Spark上用于图和并行图计算的处理系统,整个计算过程由若干顺序执行的超级步(Superstep)组成.GraphX在编程模型上遵循“节点为中心”模式,在超级步S中,图中节点汇总从超级步(S-1)中其他节点传递过来的消息,改变自身的状态,并向其他节点发送消息,这些消息经过同步后,会在超级步(S+1)中被其他节点接收并做出处理.为了便于图计算,GraphX引入了扩展自Spark RDD的属性图,并提供了一组基本功能操作,如图构造操作、图反转等,以及优化的Pregel API.本文所研究的是利用GraphX对大规模社会网络进行并行处理,保护隐私的同时提高算法的执行效率,主要工作及贡献如下:
1) 提出一种分布式节点分组算法NGM(node group merge),基于GraphX的消息传递机制将互为N-hop邻居的节点分为一组,有效的保护了敏感链接.
2) 提出了保护链接的分布式匿名方法DAPLR (Distributed Anonymous Protecting Link Relationships),基于GraphX对NGM产生的分组进行标签匿名,使得匿名图G*中,对于任意节点,都至少有其它(k-1)个节点包含自己的标签.
3 背景知识及问题定义
本文假设攻击者所具有的背景知识是节点的标签信息,因此,将社会网络表示成节点带标签的简单无向图G=(V,E,L,δ),其中V是节点集,每个节点表示社会网络中一个用户,E是边的集合,代表网络中用户之间的链接关系,L是节点标签集,δ:V→L是节点到标签的映射.
定义1. (分组链接泄露) 已知社会网络G=(V,E,L,δ),C是节点集V的一个分组,u、v是分组C中的两个节点,即:u∈C,v∈C,若节点u、v存在链接关系,则称分组C存在分组链接泄露.
如图1中,若由节点1、2、3构建分组{1,2,3},由于分组{1,2,3}内节点1和2,2和3之间存在链接关系,则可知分组{1,2,3}存在分组链接泄露.
定义2.(安全分组) 社会网络图G=(V,E,L,δ),C是节点集V中的任意分组,Dist(u,v)表示节点u、v的最短路径长度.如果分组C是安全的,则满足条件:∀u∈C∧∀v∈C⟹Dist(u,v)≥2.
由定义2可知,分组C被认为是安全的当且仅当分组内任意两节点u,v满足:Dist(u,v)≥2.以图G为例,给出一个安全分组过程.假设分组C={1},并且分组中节点数目为3,图G中满足定义2的为节点3,4,5,6,7.若选择节点4构成分组 C={1,4},此时与节点1,4最短距离均不小于2的只有节点6,因此生成分组{1,4,6}.从图G可以看出,分组{1,4,6}不存在分组链接泄露.为了说明这一点,下面给出严格的数学证明.
证明:反证法.假设分组C内存在分组链接泄露,即分组C中存在节点u、v构成边(u,v),此时节点u、v的最短路径长度Dist(u,v)=1,这与定义2中安全分组条件相矛盾,故假设不成立,分组不存在分组链接泄露.
定义3. (标签统一列表)已知社会网络图G=(V,E,L,δ),C是节点集V中任意一个节点数目不小于m的分组,p={p0,p1,…,pk-1}是整数序列{0,1,…,m-1}一个大小为k(k≤m)的子集,若对 v C, 其标签范化列表generlist.v由下面公式产生[10]:
list(p,i)={u(i+p0)modm,u(i+p1)mod m,…,u(i+pk-1)mod m}
(1)
如图1中,假分组C={1,2},并选择k=2,则节点1,2的标签统一列表generlist.1={(Afri,20),(Asi,25)},generlist.2={(Asi,25) ( Afri,20)}.
4 保护链接关系的分布匿名算法DAPLR
DAPLR算法的主要思想:首先基于GraphX的消息传递机制,彼此互为N-hop邻居的节点分为一组,然后标签匿名每个分组,达到抵抗节点重识别攻击和保护敏感关系的目的.
4.1 分布式节点分组算法NGM
基于GraphX的“节点为中心”模式以及所提供的图构建操作,提出一种安全分组算法NGM:首先,将节点划分为不同的分组;其次,通过多次迭代执行“查找—合并—构建新图”完成安全分组,即初始化时,为节点添加一个被称为groupid的组信息,用来描述节点所在分组,其初始值为节点的nodeid;节点通过传递并修改groupid完成分组.在合并分组时,将Dist(u,v)设置为2,即只在2-hop邻居间进行分组合并.因此,利用GraphX查找节点的2-hop邻居成为问题的关键.
定理1.G=(V,E,L,δ)是简单无向图,其中∀u∈V,∀v∈V,节点u、v间的最短路径长度用Dist(u,v)表示,w∈{s|s∈V∧Dist(u,s)=1},∀w∈V且w∈{z|z∈V∧Dist(v,z)=1}.如果节点w是节点u的2-hop邻居,即Dist(u,w)=2,则节点w满足条件:
w∈{g|g∈V∧g≠u∧Dist(u,g)≠1}
证明:反证法.假设节点u、w不是2-hop邻居,则u、w关系分三种情况:(1)Dist(u,w)>2;(2)u=2;(3)Dist(u,w)=1.若情况(1)成立,由题设Dist(u,v)=1,则此时节点v,w应满足Dist(v,w)>1,这种情况下与定理1中的条件w∈{z|z∈V∧Dist(v,z)=1}相矛盾,故不成立.情况(2)和情况(3),如果两者成立,可知此时与定理1中的条件w∈{g|g∈V∧g≠u∧Dist(u,g)≠1}相矛盾,故也不成立.综上所述,假设不成立,节点w是节点u的2-hop邻居.
这样,利用GraphX通过两次迭代找出2-hop邻居节点.第一次迭代,所有节点向邻居节点发送一个带有自身groupid的消息,收到消息的节点生成1-hop邻居列表;第二次迭代,所有节点将1-hop邻居列表再转发给邻居节点,收到消息的节点遍历所有列表,利用定理1找出所有2-hop邻居,具体如算法1所示.
Algorithm1.Search 2-hop neighborhood
Input:messages
Output: The list of 2-hop neighborhood of vertex u
1 THNList←∅;
2 long step = getSuperstep();
3 if step = = 0 then
4 for each vertex u do
5 sendMessToNeighbors (vertext.groupid);
6 else if step= =1 then
7 long neighborhoodlist=getValue(messages);
8 sendMessToNeighbors(neighborhoodlist);
9 else if step= =2 then;
10 for each messages do;
11 if the groupid isnot vertext u′s groupid then;
12 select groupid NotExistIN vertext u′s neighborhoodlist Into THNList;
13 return THNList;
以原始图G为例,算法1如图2所示,为了便于表述图中省略了节点的nodeid,仅标出了groupid.
当Superstep=0时,节点向邻居节点发送自己的groupid,即图2(a)所示;如图2(b),当Superstep=1时,节点收到消息后生成1-hop列表并将列表再次转发给邻居节点,如节点2生成1-hop邻居列表{1,3},并将{1,3}转发给邻居节点;在图2(c)中,即Superstep=2时,节点收到邻居节点转发的列表,然后遍历所有的列表,列表中不是自己1-hop邻居且不是自己groupid的值就是自己的 2-hop邻居,如节点4,收到列表{2,4},{4}和{4,6},除去1-hop列表{3,5,7}和4,剩余的2,6就是自己的2-hop邻居.经过两次迭代后的最终结果如图2(c)所示.
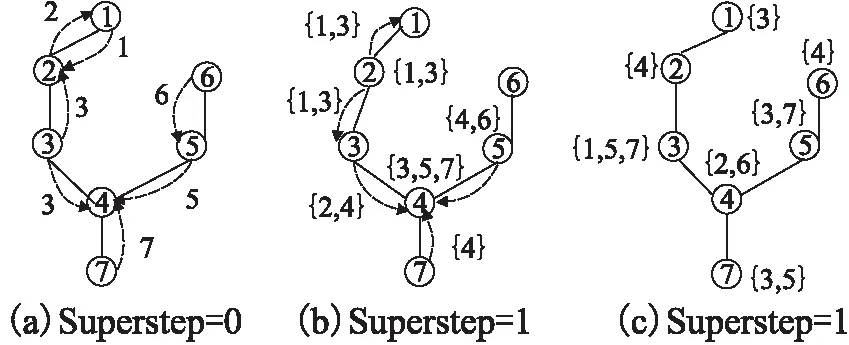
图2 查找2-hop邻居Fig.2 Search for 2-hop neighbors
完成2-hop邻居查找后,利用“中间人”策略来进行分组合并.所谓的“中间人”是指节点的邻居节点,如图3(a)中,节点2就是节点节点1和3共同的“中间人”.其思想是:节点从2-hop邻居列表中选出最小的groupid,将自己的groupid与此值以(key,value)形式发送给“中间人”, “中间人”根据收到的消息判断哪些互为2-hop邻居的节点能够合并分组,具体如算法2所示.
Algorithm2.Group merge
Input:messages
1 long step = getSuperstep();
2 if step = = 0 then
3 for each vertex u do
4 long min=getMinValue(THNList);
5 sendMessToNeighbors ((vertext.groupid,min));
6 else if step= =1 then
7 long mergerlist=getValue(messages);
8 if IsExist (u.groupid=v.min and v.groupid = u.min) IN mergerlist then
9 sendMessToNeighbors(mergerlist);
10 else if step= =2 then
11 u.groupid=min{u.group,u.min};
以原始图G为例,算法2如图3所示.如图3(a),算法执行3-5行,节点从2-hop邻居列表中选出最小groupid,并以(key,value)形式发送给“中间人”;如图3(b),执行7-9行,“中间人”判断是否转发消息,节点2满足第8行,转发{(3,1)(1,3)}给邻居;图3(c)中,执行第11行,节点3将自己的groupid为修改为groupid=1,节点4修改groupid为groupid=2.
每完成一次分组合并利用Spark提供的RDD(Resilient Distributed Datasets,RDD)构建一个新图.当前图的边信息

图3 节点分组合并Fig.3 Grouping and merging of nodes
4.2 节点标签匿名
GraphX的编程遵循“节点为中心”模式,即以节点为中心,通过彼此间的消息传递来独立完成任务.因此,提出一种基于GraphX的节点标签匿名算法,其思想是:首先,为每个分组产生一个相应的虚拟节点,其邻接节点是分组中各节点;其次,分组节点以(key,value)的形式发送自己的nodeid和标签列表给虚拟节点,虚拟节点收到消息后为分组中的节点产生标签统一列表,并将标签统一列表发送给分组节点;最后分组节点用标签统一列表替换原有标签列表完成匿名.如此,利用3个Superstep就能够完成整个过程.
1)始状态,左侧的分组节点处于Active状态,右侧的虚拟节点处于Inactive状态.
2)Superstep=0,左侧分组节点以(key,value)形式发送nodeid和标签列表给右侧的虚拟节点.
3)Superstep=1,虚拟节点收到消息,根据定义4为分组中节点产生标签统一列表,并将标签统一列表转发给右侧分组节点.
4)Superstep=2,用户节点收到消息后,将原有标签列表修改为标签统一列表.
具体如算法3所示.
Algorithm3.Generate Lable list
Input:messages
1 long step = getSuperstep();
2 if step = = 0 then
3 for each vertex u do
4 if isLeft() then
5 sendMessToNeighbors((vertext.nodeid,vertext.labellist));
6 else if step= =1 then
7 if notisLeft() then
8 long list=getValue(messages) ;
9 for vertext u in list do
10 new= (vertext.nodeid,vertext.generalizationlabellist);
11 sendMessToNeighbors(new);
12 else if step==2 then
13 if isLeft() then
14 long Anolabel=getValue(message);
15 setValue(Anolabel);
由于4.1节在分组时,并没有考虑分组中节点的数目m的值,这个需要根据实际情况进行相应的调整.同样以原始图G为例,为了方便表述,原始图G中节点1,2, …,7各自的标签列表,分别用相应的符号t1,t2,…,t7来表示.以k=m=2为例,即分组中节点数目为2,因此,需要对4.1节产生的分组{1,3,5,7},{2,4,6}做出相应的调整,这里将原分组结果调整为{1,3},{2,4,6},{5,7},则算法3的执行过程如图4所示.

图4 标签匿名Fig.4 Label anonymous
4.3 算法安全性分析
DAPLR算法包括节点安全分组和节点标签匿名,因此,对算法的安全性从这两部分进行分析.
定理2.已知图G*是社会网络图G=(V,E,L,δ)由DAPLR算法得到的匿名图,则当攻击者以节点标签为背景知识时,从匿名图G*中识别出目标的概率为1/k.
证明:由4.2节可知,对于任意节点u,在匿名图G*中都有其余(k-1)个节点包含u的标签,因此当攻击者以节点标签为背景知识时,从G*中识别出目标的概率不大于1/k.
定理3.已知图G*是社会网络图G=(V,E,L,δ)由DAPLR算法得到的匿名图,则匿名图G*不存在分组链接泄露.
分析DAPLR算法可知,需要证明NGM算法产生的分组内不存在链接,而定义2和定理1证明了NGM算法在分组合并中不会导致分组存在链接,因此只需要证明,新图的构建不会导致分组内有链接存在.
证明:NGM算法的第i次构建的图用Gi来表示,Si是图Gi中的一个节点.根据算法1和算法2可知,Si是图Gi-1中两个互为2-hop的节点u和v构成的超级节点,因此节点Si的链接关系继承点u、v的链接关系,即在图Gi-1中节点u和v的1-hop邻居节点,都会转变成节点Si在图Gi的1-hop邻居节点,因此在第(i+1)迭代中不会将链接引入分组.

图5 构建的新图G1Fig.5 New graph G1
以图1为例,NGM算法首次构建的图5所示,在图G1中,图中圆圈中数字表示groupip,花括号中数字表示分组包含的节点.对比图1可知,节点2、4将1-hop邻居节点转变成图G1中节点2的1-hop邻居,节点1、3亦是如此.通过实例也说明了NGM算法不会将链接引入分组.
5 实 验
5.1 数据集与实验环境
实验对DAPLR方法进行性能分析和评价,采用真实社会网络数据集com-LiveJournl,其中com-LiveJournal数据集包含3,997,962个节点和34,681,189条边.DAPLR隐私保护方法涉及到节点标签而数据集并不包含标签信息,因此实验中人工生成节点标签列表信息.每个节点的标签列表由3个属性构成:国籍(80个国家)、性别(男或女)、年龄(15~75),所有的值满足同一分布.
为了便于对比,实验将数据集随机等分为5份并按1∶2∶3∶4∶5重新整合数据,产生5个数据集,即split1-split5;然后,利用三种算法对每个split进行匿名:1) 将社会网络图转化为二分图,在单工作站环境下利用文献[10]进行匿名,运行结果记做“Bipartite”,2) 在单工作站环境下利用安全分组和标签统一列表对社会网络进行匿名,实验结果记做 “Sequential”,3) 利用DAPLR算法匿名社会网络图,记为“DAPLR”.
实验分别在单工作站和分布式环境匿名数据split1-split5,下面是两种不同测试环境下的软硬件配置:
单工作站环境:Intel Core i7-2720QM,CPU 2.2Ghz,16G RAM;操作系统:win7 旗舰版;编程语言:VC++2010
分布式环境:11个计算节点,Hadoop 2.7.2,Spark1.6.3; CPU 1.8GHz,16GB RAM,编程语言:Scala 2.10.4.
5.2 算法性能分析
实验从两个方面对DAPLR算法进行性能分析和评价:计算开销以及算法的复杂度.
5.2.1 运行时间
实验采用执行时间作为评测DAPLR算法计算开销的评测标准,并与单工作站环境下的“Bipartite”和“Sequential”做对比,实验结果如图6所示.
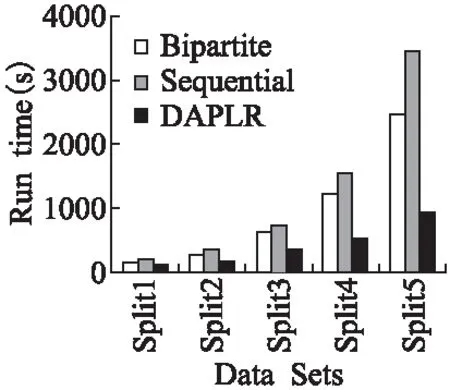
图6 运行时间Fig.6 Run time
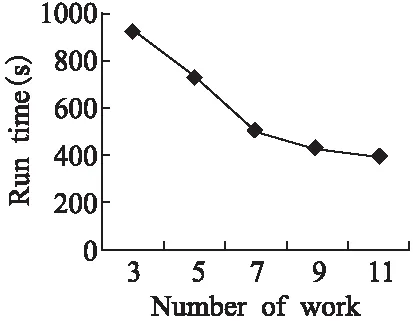
图7 运行时间随worker数量的变化Fig.7 Running time varies with the number of workers
图6展示了单工作站环境下“Bipartite”和“Sequential”方法,以及DAPLR算法消耗时间的对比图.从图中可以看出,“Sequential”方法所消耗的时间要高于“Bipartite”,这是因为所提出的安全分组条件使得“Sequential”方法需要对图进行多次遍历,需要说明的是,实验中“Bipartite”并未考虑社会网络图转化为二分图时所产生的消耗.同时,实验结果显示 “Sequential”和“Bipartite”消耗的时间要高于DAPLR方法,并且随着数据集的增大,这种趋势愈加明显.从实验结果中可以看出,所提出的DAPLR算法在处理大规模数据上更具优势.
5.2.2 算法复杂性分析
实验采用两个方法来评测DAPLR算法的复杂度:
1)保持数据规模不变,逐渐增加计算节点(worker)数目;
2)规模扩展性(Scalability).
图7显示了DAPLR算法处理数据集split3时,随着worker数目增加处理时间的变化情况.实验结果显示,随着worker数目的递增,处理数据所消耗的时间逐渐减少,大致呈线性变化.但在worker=9时,处理时间变化不再明显,这是因为随着worker数量的增加,worker彼此间通信量增加,产生更多的额外开销.
规模扩展性是评价并行算法的一个重要方法,方法是:保持计算数目不变,扩大数据规模,是用来测试算法时间复杂度的一个方法,其计算公式:

(2)
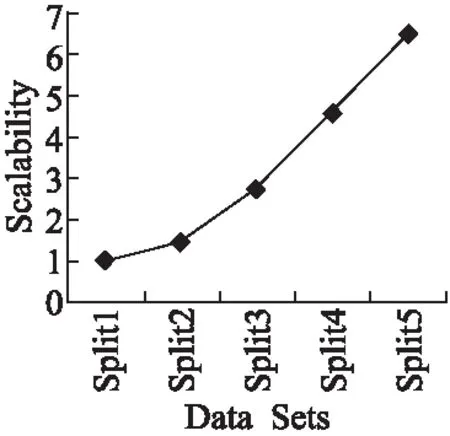
图8 规模扩展性Fig.8 Scalability
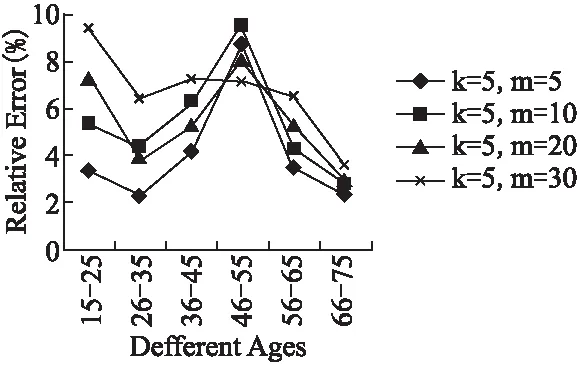
图9 查询错误率Fig.9 Query error rate
其中,T(*)是处理相应数据集消耗的时间,实验将split1作为DB,并用split1-split5 这5个数据集作为 m×DB,并在集群运行,所得结果如图8所示.由公式可知,理想情况下sizeup应不大于数据规模比例,从图8中可知,算法在split1-split3具有很好的规模扩展性,而从split4开始,sizeup则逐渐大于数据规模比例,其主要原因是受限于服务器的CPU计算能力,另外就是随着数据规模的增大,数据输入的时间会有所增加.
5.3 数据可用性分析
社会网络图匿名化处理的目的在于通过图修改操作来防止用户隐私信息泄露,同时保证匿名图在社会网络分析和图查询方面的数据可用性.DAPLR算法在对社会网络图进行匿名处理时并没有修改图结构,因此针对图结构的查询如平均最短路径、聚集系数、节点可达性等都会与在原图上查询结果相一致.因此,实验通过查询准确性来评价算法在数据可用性上的表现.

图10 单跳查询错误率图11 双跳查询错误率Fig.10 Single-hop queryFig.11 Dual-hop query error rateerror rate
针对查询操作,实验采用文献[10]所提出的单跳查询和双跳查询作为评测方法,并用查询相对误差率作为度量标准.相对误差计算公式为|N-N*|/N,其中N表示原始图数据上的查询结果, 表示匿名图数据上查询结果.实验采用不同的属性进行多次查询计算误差率,取查询误差的平均值.实验结果如图9、图10和图11所示.
图9是为了评测算法查询准确性所提出查询 “在不同年龄段,A国用户和B国用户间存在多少朋友关系”所得到的平均相对误差.从图中可以看出,在不同年龄段随着阈值k、m的变化平均误差有所变化,但都能维持在10%左右,匿名后的图数据仍具有较好地可用.
图10和图11分别展示了单跳查询和双跳查询随分组中节点数目m变化的情况.从实验结果中可以看出,随着分组中节点数目m值的增加,查询误差率随之增大,因为随着分组中节点数目增多使得节点的候选标签数随之增加,从而导致查询结果的相对误差变大.
6 结束语
针对当前社会网络隐私保护方法忽视节点敏感链接,以及处理大规模图数据存在极大局限性的问题,提出一种利用分布式图处理系统GraphX的DAPLR社会网络隐私保护方法.DAPLR方法依据分布式图处理系统GraphX编程遵循“节点为中心”模式的特点,通过节点间的消息传递进行安全分组和标签匿名,在提供隐私保护的同时保证了数据的可用性.真实社会网络中,随着时间的演变,用户之间会建立新的链接关系或取消彼此间的联系,有的用户甚至会退出社会网络,DAPLR方法并没有考虑社会网络的这种动态演变的特性,因此,接下来将考虑利用GraphX对动态社会网络进行隐私保护.
猜你喜欢
小学生学习指导(中年级)(2021年4期)2021-04-27
课堂内外(初中版)(2020年5期)2020-06-19
小学生学习指导(低年级)(2019年3期)2019-04-22
小学生学习指导(低年级)(2018年9期)2018-09-26
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
小学生导刊(低年级)(2017年1期)2017-06-12
Coco薇(2015年11期)2015-11-09
中学生数理化·中考版(2015年10期)2015-09-10
少儿科学周刊·少年版(2015年2期)2015-07-07
