
求解混合多处理机任务作业车间调度的改进粒子群算法
2018-10-26 02:42翟亚飞李心宁
小型微型计算机系统 2018年9期
翟亚飞,樊 坤,王 蒙,李心宁
(北京林业大学 经济管理学院,北京 100083)
1 引 言
中国加入WTO后,全球性的竞争加剧,给国内的制造业带来了新的挑战.随着市场竞争的日益激烈以及客户需求的日益个性化多样化,大批量流水生产模式正逐渐被适应市场动态变化的多品种、单件、小批量离散生产方式所替代[1].在这种离散制造企业中,经常会出现工件的某些工序需要由多位工人(或多台设备)同时加工的情况,这种多处理机任务加工已经逐渐成为车间生产的主要方式.然而,传统的车间调度却要求每个工件的每道工序只能在一台处理机上加工,因此具有这种单处理机任务约束的调度系统很难在现实的车间中得以应用,使得这类企业目前主要根据调度人员的经验来确定排产,成为了影响生产效率提升的重大瓶颈.如何对具有多处理机任务约束的作业车间进行高效排产已经成为如今许多离散制造企业亟待解决的问题.
多处理机任务是指需要多个处理机(处理机通常指加工设备、机器或人)同时运行的任务.Chen & Lee[2]指出多处理机任务调度(Multiprocessor task scheduling,MTS)广泛应用在制造加工过程的劳动力分配中,此外在实时机器视觉系统、并行计算机系统、多处理机诊断系统、泊位分配、人力资源计划等方面均有应用.
从上世纪90年代末开始出现了专门针对车间调度中的多处理机任务问题的研究[3].在此之前,对于MTS的研究主要都是针对只有一道加工工序的工件,Drozdowski[4]根据机器有无差异对MTS从无差异的并行机和有差异的专用机进行了详尽的综述.

虽然流水车间调度是作业车间调度的特例,但是作业车间相对于流水车间来说更加复杂,因此目前对于混合多处理任务作业车间调度(Hybrid Job-shop Scheduling with Multiprocessor Task,HJSMT)的研究就更少了,这是因为作业车间调度仅是HJSMT调度的特例.所以针对HJSMT的研究主要集中在对某一类特殊的确定性问题进行建模和设计求解算法.例如Brucker & Kramer[3]对相关问题进行计算复杂性证明.Huang 等[14]对系统中只有4台机器的情况进行研究,提出一种线性时间近似算法求解该问题.Jansen & Porkolab[15]就可打断与不可打断两种情形,提出一种近似调度方法.Gröflin等[16]对具有工件插入的多处理机任务作业车间调度进行研究,得到一个可行的工件插入定理.
由此可见,已有的HJSMT研究都是将该问题增加约束进行简化后求解,即在特定情境下进行研究,所提出的模型和求解方法普适性较差,因此本文就一般HJSMT问题进行建模,并提出一种改进粒子群算法(Improved Particle Swarm Optimization,IPSO)对其求解.同时,由于目前国内外文献中已有的求解车间调度问题的改进PSO算法,主要都是针对流水车间调度、作业车间调度以及柔性车间调度[17]等常见的调度问题进行求解,而本文提出的改进PSO算法主要专门求解HJSMT问题.编码、解码规则等算法机制的不同使得能够求解常见调度问题的改进PSO算法通常不能求解HJSMT问题.因此,本文的贡献不仅体现在对一般HJSMT问题的建模上,而且更体现在专门求解HJSMT调度的改进PSO算法的设计方面.
2 HJSMT问题调度建模
2.1 问题描述
HJSMT问题是经典JSP问题和MTS问题的结合,并且已被证明为强NP-hard问题[3].对一般HJSMT问题描述如下:n个工件(J1,J2,…,Jn)在m台处理机(M1,M2,…,Mm)上进行加工,每个工件都包含一定数量的工序,同一个工件的工序之间存在工艺路线约束.处理机之间存在差异,任意一道工序Oij(工件i的第j道工序)需要由多台指定的处理机加工,所需要的处理机集合为cij,相应的加工时间为tij.目标是找到一种调度方案,将所有工序在满足约束(工艺路线约束和有限资源约束)的前提下,分派到各处理机上处理加工,使得总加工时间Cmax最短.
该模型有以下假设:
1)不同工件的工序之间不存在约束;
2)工序的加工一旦开始就必须直到结束,中间不允许中断;
3)一台处理机一次只能加工一道工序;
4)不存在处理机损坏、原材料缺失、工件插入等突发情况;
5)处理机之间互不相同,不能相互替代.
2.2 数学建模
设S为所有工件的集合,O为所有工序的集合.对于S中的任意一个工作JiS,都有集合Ji={Oi1,Oi2,Oi3,…,Oi|Ji|},当然也有Ji⊆O.在建立数学模型时,定义一个“开始虚工序”σ和一个“结束虚工序”μ,分别代表整个加工过程的开始时刻和结束时刻.开始虚工序σ在所有工作开始之前开始,结束虚工序μ在所有工作结束之后才开始,它们的加工时间全部设定为0.如果使用xq,cq和tq分别代表工序q(其中qI∪{σ,μ})的开始加工时间、需要的处理机集合和加工时间,那么有cσ=cμ=∅,tσ=tμ=0.由“结束虚工序”μ的含义可知:xμ就是最大完工时间.基于上述符号建立数学模型如下:
目标函数:
minimizeCmaxor minimizexμ
约束条件:
xb-xa≥ta,for all {a,b}A
xb-xa≥ta∪xa-xb≥tb, for all {a,b}B
xa-xσ≥0 ∪xμ-xa≥ta, for allaI
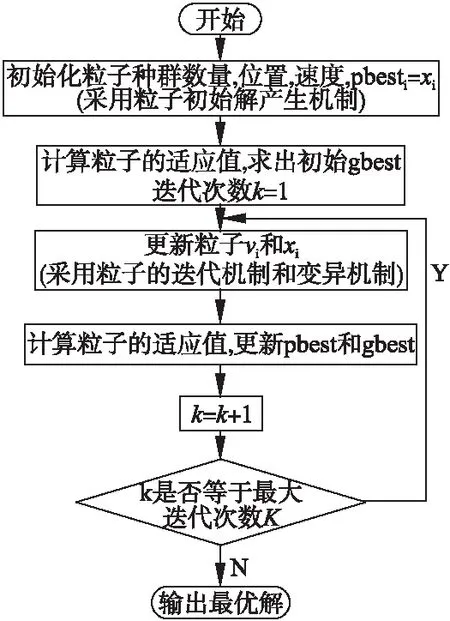
其中,A={{a,b}:aJ,bJ′withJ,J′S,J=J′anda 粒子群算法(Particle Swarm Optimization,PSO)是一种模拟鸟群觅食的进化计算技术,与遗传算法类似,也是一种迭代算法,但比遗传算法具有简单易用,精度高,收敛速度快等优点.PSO以一组初始解为基础,通过对初始解的迭代更新来不断接近最优解. PSO模拟鸟群的捕食行为,设想这样一个场景:一群鸟在随机搜寻食物,这个区域里面只有一块食物,并且所有的鸟都不知道食物的具体位置,只是知道自己当前的位置距离食物还有多远.那么,寻找食物的最优策略就是,搜寻目前距离食物最近的鸟的周围区域.在PSO算法中,每一只鸟就被抽象成一个粒子.所有粒子都有两个重要属性:一是适应值,通常由被优化的函数决定,用来评价当前位置的优劣程度;二是速度,决定着粒子的飞行方向和距离.在每一次迭代中,每个粒子都通过追求两个“极值”来更新自己的速度和位置.一个是粒子本身所能找到的最优解,称为“个体极值”pbest;另一个是整个种群目前找到的最优解,称为“全局极值”gbest.在找到这两个极值时,粒子通过公式(1)和公式(2)来分别更新自己的速度和位置: (1) (2) 图1 粒子迭代更新示意图Fig.1 Diagram of the particle iterative updating 维的速度都被限制在[-vdmax,vdmax][19].粒子通过追求个体极值和全局极值来进行自我更新的方式,反映出粒子的自我学习能力和社会学习能力,正是通过这种群体的智慧才能够不断接近最优解.在每次迭代中,种群中所有的粒子都通过公式(1)来更新速度,粒子速度在当前速度、当前位置、局部最优位置和全局最优位置的影响下发生有方向的变化,然后通过公式(2)更新其位置,如图1所示. 在采用PSO算法进行优化求解时,往往使用粒子的位置代表问题的解,通过位置的不断更新来寻求优化问题的最优解.所以在求解调度问题时,首要解决的问题就是如何在粒子位置和调度方案之间建立映射关系,主要工作包括两个方面: 图2 算法流程图Fig.2 Flowchart of algorithm 编码策略和解码策略.在建立的映射关系的基础上,必须保证粒子的迭代在可行解区域内进行.另外,PSO算法虽然精度高、收敛快,却容易陷入局部最优.为了解决这个问题,设计了类似遗传算法变异操作的变异机制.IPSO算法流程如图2所示. 为了建立粒子位置和调度方案的映射关系,本研究采用基于工序的编码规则.这种编码方式常用于JSP问题,在n个工件在m台处理机上加工的JSP问题中,每个工件都要经过m台处理机进行加工,即每个工件都要经历m道工序(工序数量和处理机数量相等)完成加工[20],那么一共有n*m道工序.与JSP问题不同,HJSMT问题中工件的工序数量是根据实际需要设定的,并不一定和处理机数量相等,用|Ji|表示工件i的工序数(i=1,2,3,…,n),此时,n个工件共有|J1|+|J2|+…+|Jn|道工序.用一个粒子代表一个调度方案,那么粒子必须包含所有工序的信息,所以粒子是一个维度为|J1|+|J2|+…+|Jn|的向量.粒子向量中的元素为:自然数1,2,…,n,每个元素表示一个工件,工件i在粒子向量中出现|Ji|次,出现的次序表示该工件的工序.在这样的编码方式下,粒子向量中元素的排列组合可以表示出所有可能的调度方案. 以一个n=3,m=4的HJSMT问题为例,表1说明了该问题的处理机使用情况以及相应的加工时间(由括号中的数字表示). 表1n=3,m=4的HJSMT问题示例 工件/工序工序1工序2工序3工件1M2M4(4)M1M2M4(4)-工件2M1M2(5)M3(5)M3M4(7)工件3M1M3(2)M1M2M3(3)M2M4(9) 以工件2的工序1中对应的内容M1M2(5)为例,则表示c21={M1,M2},t21=5,即第二个工件的第一道工序需要处理机1和处理机2在5个时间单位内共同完成. 粒子向量的长度为2+3+3=8,其中元素1出现2次,元素2和3各出现3次.现在给出一个粒子向量p=(3 2 2 1 1 2 3 3).其中的元素1,2,3代表工件1,工件2和工件3,其每一个元素出现的次序代表工序.例如,粒子中第三个元素为2,代指第2个工件,由于是第2次出现,表明这是工件2的第2道工序O22,粒子向量与工序的对应关系具体如表2所示. 表2 粒子向量与工序的对应关系示例 Table 2 An example for the corresponding relation between particle vector and process p32211233工序O31O21O22O11O12O23O32O33 在此编码规则下,粒子向量必须满足如下三个约束条件: a.每个粒子向量的长度为:|J1|+|J2|+…+|Jn|; b.粒子向量中的元素为:i=1,2,…,n; c.任一元素i∈{1,2,…,n}出现的次数为|Ji|次,每次代表工件i的一道工序. PSO算法是从一组初始解开始,通过不断地对初始解进行迭代更新来寻找最优解,所以在开始计算之前需要生成初始粒子群(初始解).随机产生的初始粒子必定不能满足约束条件c,因此必须设计一个新的策略来产生初始粒子群,使其可以满足约束a,b和c. 首先根据HJSMT问题生成一个长度为|J1|+|J2|+…+|Jn|的向量p0,并将p0的所有元素初始化为0.然后按照如下程序生成初始粒子: 步骤0.i=1; 步骤1.在p0中随机选取|Ji|个0,将其改写成i; 步骤2.i=i+1 步骤3.if(i True,步骤1; False,步骤4; 步骤4.输出p0. 重复上述程序s(种群的数量)次就可以生产一组数量为s的初始粒子群.按照这种机制产生的初始种群不但满足所有的约束条件,而且因为是随机生成,粒子均匀分布于解空间中,避免了因为初始种群过于集中而导致的早熟. 在粒子迭代的过程中需要保证新一代粒子必须在解空间内,即必须满足粒子的约束条件.但是如果仅仅使用公式(1)和公式(2)进行迭代,则在新粒子向量中难以避免地会产生小数,使新的粒子不能满足约束条件b和约束条件c,也没有实际的意义.所以必须对迭代机制进行调整,使其不仅能够保留粒子群算法的优越性,还可以使新产生的粒子满足所有的约束条件. 在新的机制中,仍然使用公式(1)和公式(2)进行迭代,但是对迭代的结果进行重新的调整和赋值.经过公式(1)和公式(2)更新后的新粒子向量中的元素可能是整数也可能是小数,这里把这些元素视为“排序指标”.记录这些“排序指标”和对应工序的映射关系.然后将“排序指标”按照从大到小的顺序降序排列,根据“排序指标”和工序的映射关系,得到新的粒子,这样的粒子显然满足约束条件. 表3 迭代机制示例 p0122312133工序O11O21O22O31O12O23O13O32O33Index3.45.43.68.72.13.26.32.81.8降序8.76.35.43.63.43.22.82.11.8p*0312212313工序O31O11O21O22O12O23O32O13O33 粒子群算法有收敛速度快的优点,但是也伴随着容易陷入局部最优的缺点.局部最优又叫“早熟”,表现为所有的粒子聚集在一个非最优解的周围区域,粒子的全局搜索能力大大减弱,其结果往往是收敛于一个非最优解,使得优化性能降低.应对局部最优的策略往往是加强粒子的全局搜索能力,例如采用线性变化的ω(本研究也做了类似的设置).本文参考遗传算法(Genetic Algorithm,GA)中的“变异”思想,在粒子迭代时增加变异过程,提高粒子跳出局部最优的能力,从而增加粒子的全局搜索能力,达到减轻“早熟”的效果. 针对本文粒子的编码规则,变异策略如下:对于任意一个粒子,随机产生两个不同的整数v1,v2∈{1,2,…,n}.然后将下标为v1,v2的元素进行交换. 表4 变异机制示例 适应值函数用于衡量粒子的优劣.本文研究的HJSMT问题的目标是使得总加工时间最短,将适应值函数设为目标函数,适应值越小的粒子越优. 适应值函数为: F(x)= minimizeCmax 在粒子的编码策略中,粒子被表示成集合了所有工序的有序向量.为了实现粒子和调度方案之间的映射关系,还必须建立粒子解码策略,将一个粒子“翻译”成一个对应的调度方案并求出该粒子的适应值.在本研究设计的解码策略中,针对粒子向量中元素的先后顺序,按照FIFO(First In First Out)规则进行排班.在这种策略下,粒子向量中排列靠前的元素(工序)具有更高的优先权.解码策略如下: 输入:粒子向量 输出:甘特图和适应值 步骤0.粒子向量中元素的下标为r(r=1,2,…,|J1|+|J2|+…+|Jn|),这里初始化为r=1;所有处理机皆处于可用状态;Ci0=0(i = 1,2,…,n); 步骤1.对于粒子向量中的下标为r的元素i所对应的工序 Oij(这里i是第j次出现,j=1,2,…,|Ji|),找出其处理机占用情况和时间:cij和 tij; 步骤2.找出前行工序Oi,j-1的完工时间为Ci(j-1); 步骤3.对于时间段 [ Ci(j-1),Ci(j-1)+tij]内的每一个时间单位,检查可用处理机是否满足cij: 不满足,则步骤4; 满足,则步骤5; 步骤4.令Ci(j-1)=Ci(j-1)+1,并回到步骤3; 步骤5.让Oij在时间段 [ Ci(j-1),Ci(j-1)+tij]内开始加工; 步骤6.更新时间段 [Ci(j-1),Ci(j-1)+tij]内的可用处理机情况,并且Cij=Ci(j-1)+tij;r=r+1; 步骤7. if(r > |J1|+|J2|+…+|Jn|): False,步骤1; True,步骤8; 步骤8.得出甘特图; 步骤9.适应值minimizeCmax=Max {C1|J1|,C2|J2|,…,Cn|Jn|}. 实验参数的设定既要保证粒子具备一定的全局和局部搜索能力,还要尽可能地提高粒子跳出局部最优解的能力.Eberhart[21]在其著作“Particle swarm optimization:developments applications and resources ”提出一种动态惯性权重法,可以满足上述要求并且结果精度更高.根据Eberhart的研究结果将算法的参数设置如下: 1)c1=c2=1.49445; 2)ω=[0.5+(Rnd/2.0)](Rnd是范围在(0,1)的随机数); 3)rand1,rand2~ U(0,1); 4)粒子种群数量为40; 5)迭代次数为120次. 为验证算法的性能,首先使用本文提出的IPSO算法求解经典JSP问题,之后再对HJSMT问题进行求解分析.本文所介绍的算法使用Java语言实现,实验在一台配置为2.10 GHz CPU和4.0 GB RAM的个人电脑上进行. JSP问题是HJSMT问题的简化,即每道工序每次只需1台处理器同时进行加工.本文选取FISHER 和THOMPSON提出的JSP标准算例FT类:FT06,FT10和FT20,以及LAWRENCE设计的LA类标准算例,选取LA01,LA05;LA06,LA10;LA11,LA15;LA16,LA20四类,共11个算例进行求解.每个算例求解10次,记录最优解以及平均解,并与 MAnt算法[22]、PaGA算法[23]、NIMGA 算法[24]、TLBO-DL算法[25]等进行比较,结果如表5所示.由表可知,本文提出的IPSO共找到7个算例的最优解,且结果稳定,10次求解均可找到最优解;对于未找到最优解的FT10、FT20、LA16、LA20问题,其10次运算找到的最优解相比其他算法表现也不差,并且稳定性明显比其他四种算法更加优秀.由此可说明,本文所提出的IPSO算法具备较好性能. 表5 JSP标准算例求解结果 算例n*mMAnt[22]最优解最优解PaGA[23]最优解平均解NIMGA[24]最优解平均解TLBO-DL[25]最优解平均解IPSO最优解平均解FT066*6555555555555.0055555555FT1010*109309449971208930952.10930949.9951967FT2020*5116511781196122411731187.4011741182.312021214LA0110*5666666666666666666.00666666666666LA0510*5593593593593593593.00593593593593LA0615*5926926926926926926.00926926926926LA1015*5958958958958958958.00958958958958LA1120*5122212221222122312221222.001222122312221222LA1520*5120712401207127312071207.001207120712071207LA1610*109459779941005946956.07945950946946LA2010*10902925912917907909.30902905907910 设有5个工件要在6台不同的处理机上面加工,处理机的编号为M1~M6.为了体现一般性,工件1、2、4的工序数为5道,工件2、5的工序数为6道,每道工序的处理机需求和加工时间具体如表6所示. 利用IPSO进行求解,得到如图3所示收敛曲线.粒子的优化过程呈阶梯状,并且“更优解”的更新效率逐渐降低.这是因为在优化刚开始的时候,初始粒子均匀分布于解空间,只需要几次的迭代就可以找到更加优质的解,如图中显示,在前20次迭代中就找到了4个“更优解”.随着迭代进行,粒子群逐渐向某一区域聚集,找到“更优解”的迭代成本也越来越高,在最后100次迭代中只找到了两个“更优解”. 从解的性质来讲,开始时初始的全局最优解为48,对应的粒子为:p0=(1,1,3,4,4,5,3,2,1,1,4,2,3,2,4,5,3,2,4,5,3,2,5,1,5,3,5),调度方案图4(图中方框中的数字“ij”代表Oij,即工件i的第j道工序). 图3 HJSMT算例的收敛曲线Fig.3 Convergence curve of HJSMT instance 由图4可以看出,不同工件的工序之间存在着严重的抵触,导致初始方案中存在大量的空闲区域,处理机的利用率很低,完工时间较长.在实际生产中就表现为资源(设备和工人)利用率不高、生产效率低下、生产周期较长、原料周转率低、甚至可能导致延迟交货.出现这种结果的原因有以下三个方面: 表6 n=5,m=6的HJSMT问题示例 工件/工序工序1工序2工序3工序4工序5工序6工件1M1M3M5(2)M2M6(1)M1M5(2)M3M4(4)-M1M4M6(2)工件2M2M4(1)M2M3M6(4)M2(1)M1M3(3)M4M5(4)-工件3M1(3)M5M6(4)M1M6(1)M2M5M6(1)M2M4(5)M2M3(1)工件4M1M4M6(2)M1M3M5(3)M2M6(2)M2M4M6(2)M2M5(1)-工件5M3M5(2)M3M6(1)M3M5M6(3)M2M4(1)M1M4M6(2)M1M3M4M6(2) 1)相同工件的工序之间存在工艺路线约束.例如:O13和O14虽然需要的处理机种类完全不同,但是由于O14必须在其前行工序O13完成之后才能开始,就增加了总完工时长. 2)同一时间单位上存在资源(这里指处理机)约束.由于 图4 初始调度方案的甘特图Fig.4 Gantt chart of initial scheduling scheme 某一处理机已经被其他工序所占用,导致后面到来的需要此处理机的工序的开始时间只能向后推迟,直到该处理机被释放.例如:O14和O22在处理机需求上存在冲突,O22必须在O14完工之后开始. 图5 优化后调度方案的甘特图Fig.5 Gantt chart of optimized scheduling scheme 3)工序分配的不合理.这是本研究提出的改进型粒子群优化算法主要解决的问题. 在优化后的调度方案中,可以找出真正影响完工时间的“关键路径”:O11-O12-O41-O52-O22-O32/O14-O53/O24-O54/O33 -O55-O34-O35-O25-O16-O44-O56或O11-O12-O41-O31-O13-O32/O14-O53/O24-O54/O33-O55-O34-O35-O25-O16-O44-O56.这些工序是制约完工时间的瓶颈,如果想要进一步缩短完工时间就要首先从这些工序上采取措施. 由图5可以看出,在工艺路线和有限资源约束的前提下,算法考虑了各个工序的处理机占用情况,尽可能地进行并行加工,大幅度提高了处理机的使用率,将最大完工时间从初开始的48缩短至36. 多处理机任务作业车间调度是多处理机任务调度和作业车间调度问题的结合,本文对HJSMT的研究有效扩展了MTS和JSP两个领域,具有重要的理论意义.此外,随着单件、小批量和定制化生产逐渐成为离散制造企业的主流生产方式,对于HJSMT问题的研究又有着重要的实践意义. 在对HJSMT问题建模时主要考虑了工艺路线约束和有限资源约束.模型的求解方面主要采用了一种改进的粒子群算法,其中的改进工作包括:为建立粒子和调度方案之间的映射关系,设计了粒子的编码策略和解码策略;为保证迭代在可行解区域内进行,改进了迭代机制;为提高粒子群跳出局部最优解的能力,引入了变异机制.并通过对JSP经典算例和HJSMT问题的仿真实验证明该算法的有效性.下一步将继续完善模型,利用提出的改进粒子群算法去解决考虑机器故障、加工时间不确定等更为符合实际生产中的调度问题.3 粒子群算法
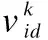

4 改进粒子群算法
4.1 粒子编码策略
Table 1 An example for HJSMT withn=3,m=4

4.2 初始解产生机制
4.3 迭代机制
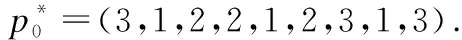
Table 3 An example for iteration mechanism
4.4 变异机制
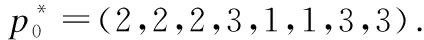
Table 4 An example for variation mechanism
4.5 适应值函数
4.6 解码策略
5 实验仿真与结果分析
5.1 JSP经典算例求解
Table 5 Computational result of JSP benchmark problems
5.2 HJSMT算例求解
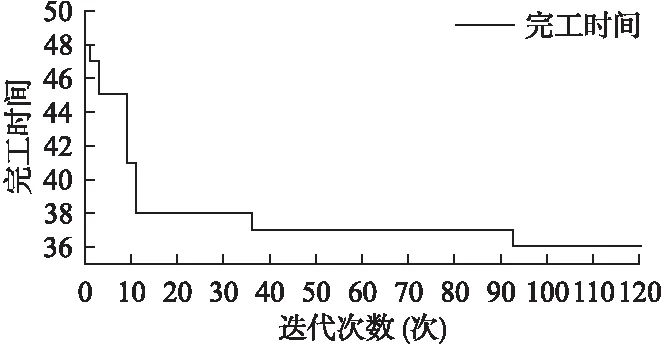
Table 6 An instance for HJSMT with n=5,m=6



6 总 结
猜你喜欢
杭州电子科技大学学报(自然科学版)(2022年4期)2022-08-23昆钢科技(2022年2期)2022-07-08杭州电子科技大学学报(自然科学版)(2022年3期)2022-06-08昆明医科大学学报(2022年1期)2022-02-28智能制造(2021年4期)2021-11-04昆钢科技(2021年1期)2021-04-13新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25杭州电子科技大学学报(自然科学版)(2020年3期)2020-06-08建材发展导向(2019年10期)2019-08-24
