
基于机器学习的典型社会安全事件发生规律研究及对雄安新区的启示*
2018-11-01 07:37邱凌峰胡啸峰顾海硕郑超慧张学军
中国安全生产科学技术 2018年10期
邱凌峰,胡啸峰,周 睿, 顾海硕,唐 正,郑超慧,张学军
(1.中国人民公安大学 信息技术与网络安全学院,北京 102623;2.安全防范技术与风险评估公安部重点实验室,北京 102623;3.清华大学 工程物理系,北京 100084;4.清华大学 公共安全研究院,北京 100084)
0 引言
2017年4月,中共中央、国务院决定在河北设立雄安新区,这是以习近平总书记为核心的党中央作出的一项重大历史性战略选择,是千年大计、国家大事。
随着雄安新区的建设和发展,当地的人口结构和周边环境等将会发生巨大改变,并由此带来一系列的社会安全问题[1]。《河北雄安新区规划纲要》(以下简称《纲要》)中明确提出,要构筑“现代化城市安全体系”,提高针对公共安全领域的突发事件的监测预警和应急处置能力。作为突发事件中的第4大类,针对社会安全事件的预警和防控工作将是构筑“现代化城市安全体系”的一项重要内容。社会安全事件的诱发主体往往是人,具有较强不确定性,其安全风险是动态变化的,预测和预防的难度较大,因此,针对社会安全事件的预测预警研究十分必要。
盗窃犯罪是一个比重巨大,并且严重影响社会安全的世界性和历史性的隐患,严重消耗着社会资源,是一类典型的社会安全事件。这一全国乃至全球普遍存在的犯罪形式,同样也成为雄安新区必将要面对的社会安全风险。据全国数据统计,2013—2017年,检察机关起诉的刑事犯罪嫌疑人中,盗窃犯罪达146.3万人,排名第1,占比超过25%[2]。因此,针对盗窃犯罪的治理工作将有助于降低雄安新区面临的社会安全风险,对保护人民财产安全、维持社会稳定具有重要意义。在盗窃犯罪嫌疑人中,盗窃前科人员再犯罪问题突出,常反复作案,且作案手段隐蔽、高超,涉案金额往往较大。在盗窃案高发,而社会治安资源有限的情况下,针对盗窃前科人员进行预警,从而重点治理,能够提高社会治安资源利用率,震慑其他盗窃人员,并降低盗窃犯罪风险。
本文利用脱密处理后的A市2012—2016年盗窃犯罪数据,基于多种机器学习模型,构建盗窃前科人员分类预测模型,并根据预测结果进一步挖掘盗窃人员的作案规律。A市与雄安新区同处华北平原腹地,城市间距离较近,交通便利,地貌、气候、水文等地理环境具有很高的相似度。A市是我国北方的一线中心城市,经济、文化发达,人口高度密集,雄安新区的发展定位为未来的首都副中心,经济、文化、人口密度极可能达到与A市相当的水平,成为京津冀地区的核心城市区域,社会环境也具有相似性。基于自然与社会环境的相似性,宏观上可以推断,2个城市整体的流动人口规模与密度、安全防范水平、重点人员跨地域作案动机、作案成本等多种风险要素也可能具有较高的相似性。因此,利用A市数据进行盗窃犯罪发生规律的研究,将有助于雄安新区在建立社会安全防控体系的过程中识别、归纳共性问题,有针对性地提出预防措施,完善警务、应急以及综合治理系统的顶层设计方案。
在此基础上,根据《纲要》的要求,针对研究过程中的数据应用、数据分析及研究结果中的数据挖掘规律,提出对雄安新区构建基于数据驱动的社会安全事件预测预警和综合研判系统的思考及建议。
1 相关研究
在国内外相关研究中,基于数据主导的犯罪预测取得了良好的效果[3-4]。文献[5]基于统计学的方法,利用犯罪人员的定罪历史预测3种类型的累犯;文献[6]基于随机森林,利用定罪数量,年龄,犯罪类型,犯罪历史的多样性和药物滥用等特征对患有精神障碍人员进行分类预测;文献[7]基于朴素贝叶斯,利用发案的日期和地点,犯罪类型,罪犯ID和熟人等特征预测嫌疑人犯罪风险;文献[8]通过罪犯、犯罪目标、犯罪环境3个因素预测犯罪发生的可能性;文献[9]基于支持向量机,利用案件信息及受害者身份信息,预测犯罪嫌疑人的身份特征;文献[10]基于改进的GA-BP神经网络,利用案件信息、人口及经济信息、土地利用信息等,对财产犯罪的时空分布进行预测;文献[11]基于随机森林,利用刑事案件中罪犯的特征,预测可能的犯罪嫌疑人。
已有研究为基于数据主导的犯罪预测提供了丰富的方法和思路,但是,这些研究利用的信息大多是在确定了嫌疑人身份后才能获得的,如:年龄、犯罪历史、熟人等。而在大多数情况下,盗窃事件发生后,嫌疑人的身份是未知的,能获取的信息只有案发的时间、地点、盗窃手段和损失金额。针对该问题,本文基于多种机器学习方法,利用发案时间、发案地点、实施手段和损失金额作为特征,对盗窃人员进行分类预测。
2 实验说明
本文首先从盗窃犯罪数据中提取出发案时间、发案地点、实施手段和损失金额作为特征,预处理后,按时间顺序将数据集划分为训练集和测试集,然后利用测试集检验训练好的模型,最后利用表现最优的模型进行结果分析,具体流程如图1所示。

图1 盗窃前科人员预测流程Fig.1 Forecast flow chart for Larceny Ex-convict
2.1 数据集介绍及特征提取
本文选取A市2012—2016年的实际盗窃案数据进行盗窃前科人员的分类预测研究。其中数据集共包括7 772条案件信息,每条数据包含案件信息和案犯类型(初犯累犯惯犯),按照盗窃事件发生后可获得的信息维度,提取出“发案时间”、“发案地点”、“实施手段”和“损失金额”共4个特征,对盗窃人员的类型进行分类预测。
数据集中的盗窃前科人员为此次犯罪之前受过刑罚处罚的盗窃人员,类型包括初犯、累犯和惯犯3种。累犯是在此次犯罪之前已受过刑罚处罚的前科人员;初犯和惯犯为初次受到刑罚处罚的前科人员,其中,惯犯的历次犯罪行为未被发现、处理和登记,也是初次受到刑罚处罚,惯犯的犯罪规律有可能与初犯和累犯存在差异。本文基于大量数据,挖掘规律性较强的盗窃犯罪特征,累犯数据的随机性低于初犯和惯犯,再犯罪规律预期更为显著,因此,对其作案规律的探索意义大于初犯和惯犯,本文在算法的性能评估中重点关注模型对累犯的预测精度。
因此,本文对盗窃前科人员作案规律的研究,包括了累犯、初犯、惯犯3种,但考虑到研究的现实意义与犯罪规律的鲁棒性,对累犯进行重点挖掘。3.1节发现累犯的预测精度很高,而初犯和惯犯的精度较低,印证了上文的观点,即累犯作案的规律性可能强于初犯与惯犯。
2.2 数据预处理
本文预处理工作是将“发案时间”、“发案地点”和“实施手段”的原有数据类型转化为整型数据,从“简要案情”中提取出损失金额,将初犯、累犯、惯犯分别标记为0,1,2,预处理后的数据样式如表1所示。

表1 数据样式Table1 Data pattern
由于“发案时间”、“发案地点”和“实施手段”原有分类过多,导致模型预测准确性不高,本文根据数据类型特点,结合公安工作经验,对这3个特征进行归类后,模型的分类预测精度明显提升,参见3.1内容。
2.2.1 实施手段处理
实施手段指盗窃人员进行盗窃时使用的方法,如剪门挂锁、顺手牵羊等共90多种。考虑不同类型的盗窃人员作案经验的不同,选择的手段可能具有差异性,将“实施手段”分为4类。其中,“其他类”标记为“4”(该类型为记录时无法确定具体使用的盗窃手段);将有破坏行为的手段标记为“3”(包括通过破坏车、门、窗等破坏手段盗窃房屋或车内物品);将有扒窃行为的手段标记为“1”;不包含破坏行为和扒窃行为的手段标记为“2”,如表2所示。

表2 实施手段分类Table 2 Classification of means
2.2.2 发案时间处理
原始数据中的发案时间精确到“年/月/日/时/分”,种类达到了几千种,采用原始分类会导致分类准确性下降;现实中,失主发现物品被盗与案件发生的时间往往具有不一致性,采用原有发案时间也会对结果分析带来一定的偏差。因此,本文将时间分析的尺度调整为1天中的4个时段,结果如表3所示。

表3 发案时间分类Table 3 Classification of duration
2.2.3 发案地点处理
发案地点指盗窃人员实施盗窃的地点,原始分类共90多种,如:地铁站、商场、网吧和宾馆等。根据公安实习经验,手法熟练的扒手往往会在人流量大的车站实施盗窃;有经验的盗窃人员知道网吧里上网的人戒备心较低,放在桌上的手机容易盗走。本文按照人流量大小、安保力量多少和市民在该地点所持的戒备心高低,将“发案地点”分为4类,结果如表4所示。

表4 发案地点分类Table 4 Classification of location
其中,大型公共场所包括汽车站、医院等;商业地区包括商场、繁华街道等;休闲娱乐场所包括网吧、KTV等;住所包括宾馆、居民小区等。
2.2.4 损失金额处理
损失金额指案件被盗物品的价值,其大小可能影响不同类型盗窃人员的选择。原始数据中,简要案情记录了案件发生的经过,其中包括丢弃的物品名称和估价,主要分为3种类型:“包含丢失物品的估价”、“没有估价但包含物品的品牌”、“没有估价和品牌但有丢失物品名称”,如:
1)丢失苹果牌土豪金色6PLUS手机,价值5 000元。
2)丢失苹果5手机。
3)丢失手机。
将上述3类数据标记为“1”、“0”、“2”,并采用正则表达式提取出金额或被盗物品的品牌。对类型“1”赋值“5000”;对类型“0”,提取出“苹果5”,并与建立好的字典“苹果5:4000”进行匹配,赋值“4000”;类型“2”属于缺失值,由于数量较多,用类型“0”和“1”中的频繁项进行插补,结果如表5所示。

表5 损失金额分类Table 5 Classification of loss of the victim
由于类型“2”具有较大的不确定性,针对该不确定性,本文进行了敏感性分析。统计发现,“损失金额”75%的值集中在3 000到60 000,在该区间内,以500为步长,对类型“2”进行赋值,每次赋值后都进行5折交叉验证。根据结果显示,交叉验证准确率变化的标准差较小(0.003 3),说明分类结果对类型“2”的赋值不敏感。
2.2.5 不平衡数据处理
原始数据中,初犯、累犯和惯犯的数量分别为:4 488,906和2 378条,具有一定的不平衡性,这容易导致模型对初犯和惯犯学习较好,而对累犯(盗窃前科人员)的预测效果不理想[12-14],因此,本文利用SMOTE算法对累犯样本进行采样处理。
SMOTE算法[15]首先对少数类样本进行分析,对其中的每1个样本 ,以欧氏距离为标准计算其到所有少数类样本的距离,并得到其K近邻数据点,在此基础上,根据原始数据样本的不平衡比例,设置采样比,从而确定采样倍率。进而,对于每1个少数类样本,从其K近邻数据点中随机选择若干样本,并分别与原始数据样本按照如下式(1)生成新的样本数据。
Χnew=Χ+rand(0,1)×|Χ-Χn|
(1)
式中:Χn为Χ的K近邻数据点,Χnew为新的样本数据。
利用SMOTE算法处理后,初犯、累犯和惯犯的数据量依次是4 488,2 721和2 378条,数据不平衡性得到了降低。
2.3 数据集划分
数据集划分考虑实战应用的场景:历史数据用于训练模型,利用训练好的模型对新数据进行分类预测,2者之间存在时序性。本文选取2012—2015年的数据作为训练集(共9 172条,其中初犯4 367条,累犯2 538条,惯犯2 267条),2016年的数据作为测试集(共415条,其中初犯121条,累犯183条,惯犯111条)。
2.4 模型评价指标
本文选取查准率(Precision)、查全率(Recall)和F1作为评价指标[16-17]。其中,累犯的查准率表示“预测为累犯的盗窃人员中有多少是真的累犯”;查全率表示“所有的累犯中有多少被正确预测”;当这2项指标难以直观比较时,根据F1评价模型的预测精度,该值综合了查准率和查全率,F1为1时,代表模型的综合性能最好,为0时性能最差;3项指标的计算如式(2)~(4)所示。
Precision=TP/(TP+FP)
(2)
Recall=TP/(TP+FN)
(3)
F1=2×Precision×Recall/(Precision+Recall)
(4)
式中:TP表示被正确分类为正样本数;FP表示被错误分类的负样本数;FN表示被错误分类的正样本数。
3 实验结果及分析
3.1 不同机器学习算法的分类性能比较
由于建模的目标是预测盗窃前科人员,对比不同机器学习算法时只关注其对累犯的预测精度。利用python3.6中的Scikit-learn开源机器学习模型库实现逻辑斯蒂[18]、支持向量机[19]、决策树[20]、随机森林[21]、K近邻[22]和朴素贝叶斯[23]共6种机器学习模型的建立,并计算模型在测试集上对累犯的预测精度,结果如表6所示。

表6 不同算法对累犯预测精度的比较Table 6 Comparison of prediction accuracy of recidivism by different algorithms
由表6可知,随机森林在预测累犯时性能最优,3项指标均达到了0.85。决策树和朴素贝叶斯模型有某1项指标较高,但综合指标F1只有0.6左右。
利用sklearn.metrics模块的classification_report功能计算随机森林模型对3类盗窃前科人员的分类预测结果,如表7所示。
根据表7,特征归类后随机森林模型预测3类盗窃前科人员的F1分别为0.66,0.86和0.64,较归类前提高了0.18,0.33和0.40,说明2.2节的归类是合理的。对比发现,模型对累犯的预测精度明显高于初犯、惯犯,说明2012—2016年间,盗窃前科人员作案可能具有稳定性和明显的规律性。
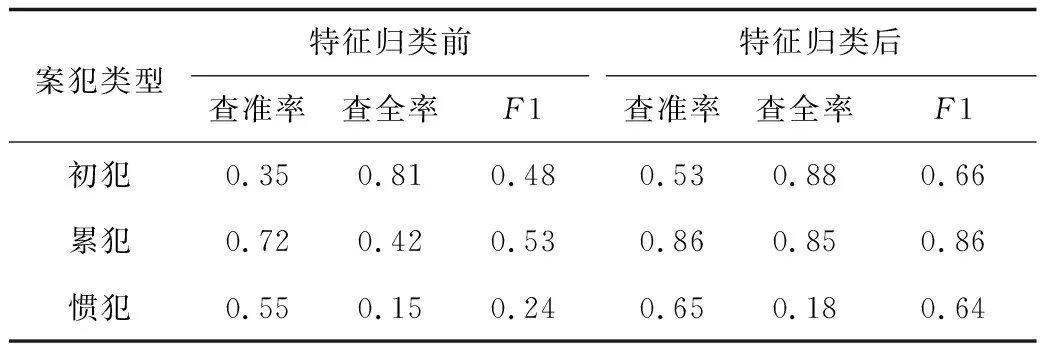
表7 随机森林分类预测结果Table 7 Classification and prediction results of random forests
3.2 盗窃前科人员作案规律挖掘
根据表7中归类后的预测精度,认为测试集中被正确分类的盗窃前科人员(尤其是累犯)的作案规律具有代表性。筛选出被正确分类的盗窃前科人员,统计其“发案时间”、“发案手段”、“地点”中各类型(类型“1”、“2”、“3”、“4”)占比及造成损失的均值,结果如表8所示。

表8 3类盗窃前科人员发案规律统计Table 8 Statistics on the law of three types of larceny ex-convict
注:手段1~4类型见表2;时间1~4类型见表3;地点1~4类型见表4;损失均值为损失金额的平均值。
由表8可知,累犯的作案规律与初犯、惯犯明显不同。累犯造成的损失均值为5 885元,比初犯和惯犯都高了2 000多元;“实施手段”方面,累犯很少选择破坏性的手段(类型“3”)且扒手较多;“发案地点”方面,累犯几乎不会选择大型公共场所和住所(类型“1”、“4”),而初犯的选择没有明显的偏好;“发案时间”方面,具有多次作案经历的累犯和惯犯几乎都选择下午时段(类型“3”)。综上所述,相比于初犯和惯犯,累犯的作案规律更为显著,对前科人员的作案规律挖掘更具有参考意义。根据累犯的作案规律,盗窃前科人员很可能偏好选择下午时段和人流量大的地区实施盗窃,另外,扒窃案高发的地区也可能是盗窃前科人员作案的热点地区。这一规律可以为雄安新区的治安巡逻区域划分、防控力量布局等社会治安防控工作提供决策支持。
4 关于雄安新区构建基于数据驱动的社会安全事件预测预警和综合研判系统的思考及建议
雄安新区的设立是我国重大的战略选择,需要结合先进的技术手段保障其长期、稳定的安全发展。《纲要》中明确提出,“要利用信息智能等技术,构建全时全域、多维数据融合的城市安全监控体系,形成人机结合的智能研判决策和响应能力”。本文利用多种机器学习算法,使用实际盗窃犯罪数据,对盗窃前科人员进行分类预测,进而根据预测结果进行分析,挖掘盗窃前科人员作案的时空热点。该方法可以根据数据的变化不断调整参数,以保证预测的准确性和稳定性,是数据驱动下社会安全风险预测的一种尝试。雄安新区的社会安全防控体系建设需要较长的迭代周期,其面临的社会安全风险需要大量的人力、物力、财力支撑,警务资源、应急资源的合理化、集约化应用具有重要意义,本文的研究提供针对类似社会安全问题的规律挖掘框架,有助于自动化地发掘类似社会安全问题的发生规律,有助于针对性地部署和调整警务与应急资源,提高智能研判决策和响应能力,符合《纲要》的要求,也对应了雄安新区安全体系发展建设的独特需求。
根据《纲要》的要求,雄安新区将要建设1套基于智能技术和多维数据的社会安全预测预警和综合研判系统(以下简称“系统”)。结合研究过程中遇到的问题,本文针对该“系统”的前期建设和后期使用提出以下思考和建议。
1)制定统一的数据格式,保证数据的使用效率。随着雄安新区建设的推进,“系统”将有大量数据接入,如人口数据、接警数据、天气数据、金融数据和通信数据等,大规模的数据集可以为社会安全事件的准确预测提供基础保障。但建设前期如果不注重统一数据格式,各类数据关联和数据清洗工作会占用大量的时间和人力,严重降低数据的使用效率,导致“系统”后期使用的时效性大打折扣。以本文研究为例,本文使用数据中,存在着大量的缺失值与不规范问题,如:数据中对损失金额的描述为阿拉伯数字与繁体字混用,单位有“元”、“美元”、“美金”,利用正则表达式提取“损失金额”很难一步到位,需要将1个表格分为近30个表格,严重消耗时间和人力;对作案地点和作案手段进行非数值特征转化时,发现同一类特征有多种的表示方法(最多可达8~10种),将多种特征按规律进行分类后,模型对累犯的预测精度显著提高。综上所述,数据缺乏统一的格式,将对“系统”的工作效率产生较大的影响。因此,雄安新区在“系统”的前期建设时,应注重数据格式的统一(即数据类型、录入格式等进行统一规范),并通过大量训练结果的反馈不断地完善这一数据格式,将有利于数据融合和综合应用,为“系统”的后期使用打下基础。
2)实现数据实时接入,提高社会安全风险的动态感知能力。社会安全风险动态变化特征明显,“系统”的数据接入也具有实时性要求。仍以本文研究为例,对预测结果的综合研判后,发现累犯作案的时空热点具有明显规律性,这一规律很可能代表了盗窃前科人员的作案规律,按这一规律进行巡逻区域划分和防控力量部署,将很可能压缩盗窃前科人员的作案空间,降低其作案风险。同时,相关的防控工作也很可能影响盗窃前科人员的作案选择,并由此带来相关数据的变化。若能将相关数据实时输入,“系统”就可以自动调整模型参数,并将新形成的规律反馈至有关部门,为相关治安防控策略的改变和部署提供决策支持。因此,雄安新区“系统”的后期使用时,应将新数据按一定的时间尺度进行接入,交付系统模型进行计算和综合研判,相关部门可根据得出的规律进行防控策略的实时调整,以应对各类动态变化的社会安全风险。
5 结论
1)利用A市2012—2016年实际盗窃数据,提取“发案时间”、“发案地点”、“实施手段”和“损失金额”作为特征,通过特征工程和SMOTE算法对数据进行预处理,基于逻辑斯蒂、支持向量机、决策树、随机森林、K近邻和朴素贝叶斯共6种机器学习模型,构建分类预测模型,对盗窃人员进行分类预测。结果显示,随机森林表现最优,预测累犯的查准率、查全率和F1分别达到了0.86,0.85和0.86。
2)根据数据挖掘的结果,累犯的盗窃金额明显高于初犯和惯犯;盗窃前科人员可能倾向于选择下午时段和人流量大的地区实施盗窃。
3)提供针对类似社会安全问题的规律挖掘框架,有助于自动化地发掘类似社会安全问题的发生规律,有助于针对性地部署和调整警务与应急资源,为雄安新区基于智能技术和多维数据的社会安全预测预警和综合研判系统建设提供方法支撑,同时,根据本文研究过程和研究结果,对该系统的建设提出“制定统一的数据格式”和“实现数据实时接入”2方面的思考及建议,为雄安新区的“现代化城市安全体系”建设提供参考借鉴。
猜你喜欢
青少年科技博览(中学版)(2022年3期)2022-04-26
证券市场红周刊(2021年26期)2021-07-06
清风(2020年5期)2020-09-10
学生天地(2020年5期)2020-08-25
儿童时代(2017年2期)2017-09-16
职工法律天地·下半月(2016年8期)2017-06-19
法制博览(2017年20期)2017-01-26
职工法律天地(2016年16期)2016-01-31
儿童故事画报·智力大王(2015年6期)2015-08-17
儿童故事画报·智力大王(2015年4期)2015-05-20
