
一种特征字典映射的图像盲评价方法研究
2018-11-05 09:13王伟刘辉杨俊安
智能系统学报 2018年6期
王伟,刘辉,杨俊安
数字视频和图像缩小了人类和自然界的差距。然而不幸的是,由于各种各样的图像退化和畸变,有用的信息可能会被丢失,因此如何评价失真图像的质量成为了一种紧迫需要。理论上,人类视觉系统(HVS)是最有效和直接的方式,但是其收集大量人类打分数据的过程极其复杂、耗时。
关于图像质量评价的研究已经有较长时间。通常图像质量可以通过直接计算原始图像和退化图像之间的距离来衡量。然而在大多数情况下,我们往往只有失真后的图像,并没有原始图像做参考。这种问题的出现影响了图像质量评价的进程,进而可能会给后续分析带来麻烦,因此怎样设计出一个合适的盲图像质量评价系统是人们迫切的愿望。
1 相关工作
建立一个典型盲图像质量评价系统通常需要两个成分:一系列特征以及学习型的回归模型。典型全参考图像质量评价过程流程图如图1所示。之前的方法通常将特征提取和模型训练分开考虑。对于这些特定类型的失真图像,相应的特征被用来衡量它们的质量,比如空间域的边缘宽度[1]以及在某些转换域的峭度[2]。然而当退化种类未知时,上述论文中所提的特定特征将无法使用。
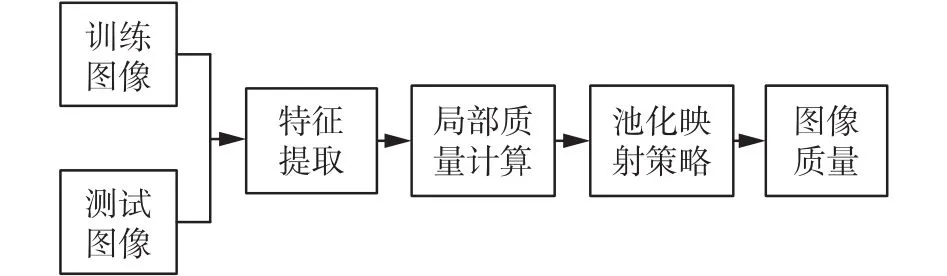
图1 典型全参考图像质量评价过程流程图Fig. 1 The flowchart of typical FR_IQA process
还有一些其他方法没有使用人工手工选取的局部描绘算子,而是基于特征学习。监督式滤波器学习已被Jain和Karu在文献[3]中采用作为纹理分类,其中特征提取和分类任务被神经网络执行。文献[4]采用了无监督特征学习,其中局部算子被编代码然后用一种无监督的方式来学习。为了学习一个更加简洁紧凑的和有区分性的字典,学习类的方法优化包括采用一个优化过的具有重建性和区分性的标准[5-6]。
2 本文方法
相较这些传统方法,一个具有区分性的特征集和灵活的学习策略可以提高表现。为了在图像质量预测阶段改善联合统计特征和学习策略,介绍了两种不同的特征提取成分:1)一个局部特征提取器;2)一个汇总了局部特征分布的全局特征提取器。
为了不失一般性,采用了一个基于字典类译码本的方法来规避标准信息的优势。传统的字典学习方法聚焦于信号的重构,同时需要字典中的学习原子,应该能很好地代表图像块,本文所提方法则没有这个限制。事实上,后续显示用于图像质量分类的字典将有很大不同。
2.1 图像特征提取
特征提取的第1步是从增强的图像块中捕捉合适的特征。在这个部分中,讨论怎么使用一系列线性滤波器来获取局部特征。受人类视觉系统发现和感知物体的启发,尝试设计出一个自然的、面向对象的检测器,在不同种类间具有一般性。首先,整幅图像被分割成互相重叠的图像块,然后从这些区域中提取两种类型的特征:一类是局部特征,另一类则是统计整幅图像局部特征分布情况的全局特征。
2.1.1 局部特征
为了方便,将原始图像块归一化成一系列局部描述算子。本节将提取以下算子来代表整幅图像的局部特征。
1) 显著性地图
图像的亮度变化传达着图像自身许多有用的信息。带通图像响应,尤其是高斯滤波器响应,可以用作描绘多种图像的语义结构,比如直线、边缘、角点以及斑点等,这些都与人类主观认知密切相关。有了这个发现,我们开发了一种语义显著性准则来感知图像中的目标[7]:

5× 5 可分离的二项式内核),||·||是 L2范数。
2) 梯度幅值图

梯度算子通常使用卷积模板来表达,本文实现中,梯度幅值的定义为式中和分别是图像相应像素位置的水平梯度和垂直梯度。自然界梯度统计分布在图像分析中扮演着关键角色,梯度相似性可被用作建立图像语义结构的基本要素,这些语义结构与人类可感知的自然图像质量密切相关。
2.1.2 全局统计特性
为了克服传统像素级评价方法的不足,我们更加关注局部特征细节和全局统计特征之间的平衡。
统计作为一种全局描述算子,是对所提取局部特征分布的概述。特别指出的是,我们使用了一种BRISQUE[8]参数模型,模型对像素值进行了GGD归一化,其中形状和尺度参数都被用作特征。虽然滤波响应的峭度和峰度值可能不能正确描述分布的形状,但对于质量高低不等的图像,它们是相对好的指示器,如图2所示。
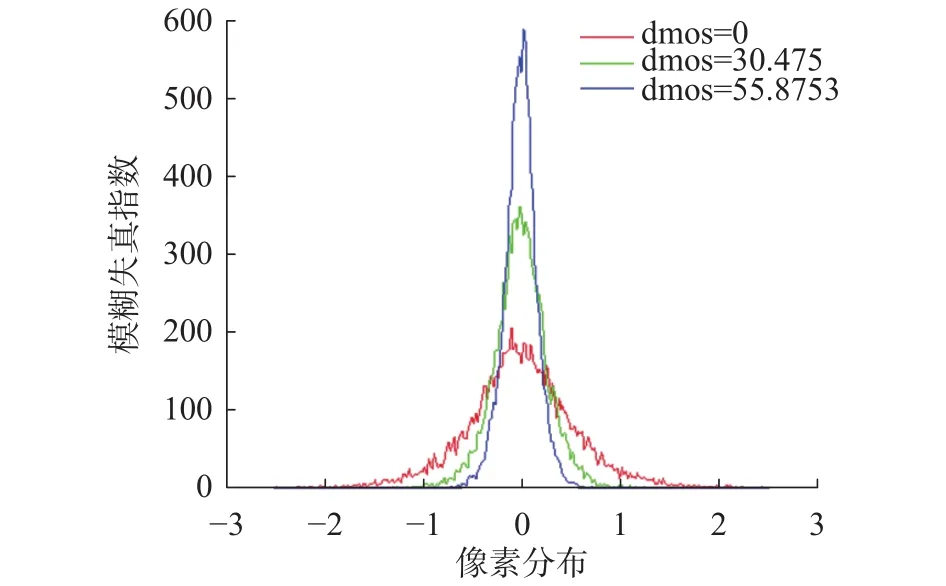
图2 滤波响应后不同等级模糊失真示例(高DMOS值表示低质量无量纲)Fig. 2 Examples of filter responses for different levels of blur distortion (high DMOS indicates low quality)

2.2 图像分类打分
本节讨论这些局部特征和全局描述算子是如何通过来学习准则预测不同图像的质量,轻松解决图像质量盲评价的病态任务问题。
2.2.1 学习阶段
为了方便训练一个值得可信的图像质量盲评价模型通常需要一个很大的人类打分训练集,通过主观测试获得这样一个模型的代价显得昂贵耗时。因此在训练阶段开发一个不需要如此大数据量的人类主观打分的图像质量盲评价模型变得迫不及待。本节求助于聚类学习和池化映射策略。
1) 池化策略
如果手里没有任何人类主观质量打分,我们瞄准学习图像质量盲评价的中心集。为了方便起见,退化图像和原始图像都被分割成重叠块。
所提方法的关键问题是怎样分配感知质量。本文我们求助于特征相似性指数[9](FSIM)来计算参考图像和变形图像之间的相似度。通过这种方式,可以去除对人类主观打分的依赖。退化图像的FSIM得分定义如下:



因此整幅图像的质量可表达为平均质量,这就与百分池化结果保持一致了。
2)聚类
通过块质量归一化策略,将相似度得分按分值分成多个组,再把那些降质块按各自的局部构造分为不同类。
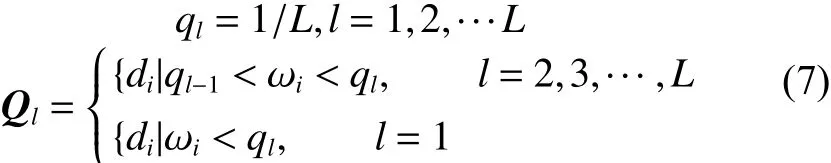

2.2.2 测试阶段
有了这些学习得到的不同质量层的中心集,可以通过把这些退化图像特征映射到相应的质量得分池,轻易地推断出感知质量,如图3所示。
通过应用滤波算法,可以获得新的增强图像及其相应的质量等级。

图3 图像质量估计流程图Fig. 3 The process of image quality prediction
通过式(9)所示的均值策略来推断新测试图像最终的质量得分。
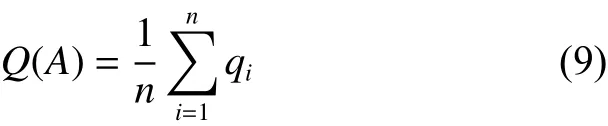
3 实验
3.1 实验设置
在通用基准数据集LIVE数据库上评估了我们所提算法。LIVE数据库包含了29幅参考图像及其对应的779幅5种不同类型的退化图像。为了代表性和简洁性考虑,仅仅选择其中两个典型的退化类型:白噪声(WN)、高斯模糊(BLUR)。对于每个退化图像,都有一个主观感知得分DMOS值,分值范围从0~100不等。较低的DMOS得分代表着较好的视觉质量。实验中,随机选取80%的参考图像及其退化图像作为训练集样本,剩余20%用作测试集。
3.2 质量预测
为了验证本文所提方法的有效性,选择LIVE数据库中一个数据集来分别预测它们的质量得分,如图4所示。

图4 LIVE数据库中同一幅基准图像不同退化程度后的图像质量预测Fig. 4 Quality prediction of different degraded degree image from LIVE database using proposed method
从结果可以看出,使用本文算法预测出的分数和人类视觉系统的结果完全一致。
3.3 对比评估
用植入线性关联系数(LCC)准则来评估本文所提算法的表现。LCC通过衡量真实分数和预测分数之间的线性关系来预测分数。假如有n幅退化图像,每幅图像有一个人类感知分数等级和一个预测的分数等级。LCC的计算为

作为对比,选择集中具有代表性的NR-IQA方法来评价LIVE数据库中特定退化类型和非特定退化类型的实验。对于前者,随机选择特定类型的退化图像来训练和测试,对于后者所有退化类型的图像将放在一起训练和测试。
前人几种表现良好的无参考图像质量评价和全参考图像质量评价方法用来作为对比:如表I所列,BRISQUE[8]、CORNIA[4]和 CNN[11]都是从原文中提取的方法。除了CNN,所有这些方法在作对比时,取LIVE数据库中的80%做训练,剩余20%做测试。对于CNN取60%做训练,20%做更新,剩余的20%做测试。

表 1 LIVE数据库上的LCCTable 1 LCC on LIVE
4 结束语
本文提出了一个简单有效的框架来自动评估图像质量。全文的创新性在于集成使用了局部特征和全局统计特性描绘图像。本文的贡献是两方面的:首先,本文用到了一个包括局部特征和全局统计特性有区分性的特征集来表征图像块;其次,研究了怎样在无标记的数据集上构建字典,使用了一个跟退化类型无关的池化策略来加速学习过程。
相比前人的方法,本文所提算法有了很大的提高,实验表明本文算法能有效处理某种程度上不可预见退化类型的图像。未来将考虑将目标检测融合到我们的框架中去,以此代替对所有检测区域质量的均值化处理。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
数学物理学报(2022年4期)2022-08-22
数学物理学报(2021年2期)2021-06-09
数学物理学报(2021年1期)2021-03-29
电子制作(2019年15期)2019-08-27
小学阅读指南·低年级版(2019年11期)2019-07-01
电子制作(2018年19期)2018-11-14
小天使·一年级语数英综合(2017年11期)2017-12-05
自动化学报(2017年11期)2017-04-04
读者(2016年14期)2016-06-29
