
基于加权聚类集成的标签传播算法
2018-11-05 09:13张美琴白亮王俊斌
智能系统学报 2018年6期
张美琴,白亮,王俊斌
现实世界中存在各种各样的复杂系统,网络则是这些系统的普遍存在形式,如人际关系网,因特网、大型电力网格等。为了能清晰地发现网络中的信息,需要挖掘网络的社区结构。 社区结构是复杂网络的一个重要特性,整个网络是由若干个“社区”构成的,每个社区内部的节点之间的连接相对非常紧密,而各个社区之间的连接却比较稀疏。利用网络的拓扑结构,能更准确地发现社区。网络社区结构的发现,有助于更好地了解社区结构、理解网络的功能和特性、预测复杂网络的行为,在社会网络、信息推荐、精准营销等领域都有很大的应用价值。
目前提出的代表性社区发现算法有潜在空间算法[1]、谱聚类算法[2-3]、模块最大化算法[4-8]、标签传播算法等,根据不同的科学需要,这些算法有不同的社区定义或类定义[9]。其中,由Raghavan等[10]在2007年提出的标签传播算法(LPA)由于其拥有线性时间复杂度而被广泛应用于处理大规模网络。然而,该算法中每个节点的标签更新取决于其邻居节点,更新效果受节点初始输入和标签更新顺序的影响。因此LPA算法的最终结果存在不确定性,影响了社区划分的准确性和稳定性。基于LPA结果的不稳定性,众多学者提出了对LPA 的改进算法[11−18]。例如,Barber等[11]在 2009年提出使用模块度最大化的变体作为约束的LPA算法(LPAm),该算法将标签传播算法转化为等价优化问题处理; Liu等[12]在2010年针对LPAm算法可能会出现社区划分陷入局部极大值的问题,提出一种改进的标签传播算法(LPAm+),其核心是将LPAm算法与多步贪婪凝聚算法(MSG)融合,最大限度地减少模块空间,避免出现局部最大值; Xie等在2011年发表的文献[13]中提出了针对提高社区检测速度和提高社区质量的改进LPA算法; He等[14]在2014年使用了PageRank来衡量网络中节点的重要性,提出了基于节点重要性的LPA算法; Sun等[15]在2015年提出基于中心的标签传播算法(CenLP),通过高密度邻居节点的相似性使节点按特定顺序更新标签; Li等[16]在2017年提出改进的LPA算法Stepping LPA-S算法,它通过模块度和目标函数DN来度量节点或子网的相似性,其标签通过相似性进行传播,最终获得了比LPA更准确的结果。
虽然已有多种改进的LPA算法被提出,但依然存在稳定性和精确性不高的问题[17−18]。聚类集成技术正是解决聚类算法结果不稳定和不精确的重要方法之一。目前,多种聚类集成技术也已得到发展[19−21]。因此,本文通过将聚类集成技术与标签传播算法融合,提出了基于加权聚类集成的标签传播算法。该算法通过引入模块度来评估每次LPA结果的重要性,加强了每个基聚类的有效性,最后采用聚类集成技术实现提高社区发现结果的稳定性和准确性。
1 基于加权聚类集成的标签传播算法
1.1 标签传播算法(LPA)
标签传播算法(LPA)的核心思想是每个节点的标签通过其出现次数最多的邻居节点的标签来决定自身的标签,通过不断迭代,节点的标签变化达到稳定后,将最终具有相同标签的节点划分为一个社区,完成社区划分。其最大的特点是简单、高效,缺点是每次迭代结果不稳定,准确率不高。在文献[10]中给出了该算法的具体描述如下。
1)为所有节点初始化一个唯一的标签,每个标签代表一个社区。
2)产生随机遍历顺序遍历所有节点,每个节点选择其出现次数最多的邻居节点标签来更新自身的标签,以此达到标签的传播。
3)若存在节点的邻居节点标签数出现多个最大值,则随机选其中一个最大值所对应的标签来更新该节点的标签。重复2),直到标签更新稳定,停止迭代。
4)将具有相同标签的节点划分为一个社区。
该算法的时间复杂度为O(n+m)O(n+m),其中,n代表为结点分配标签的时间,m代表每次迭代更新的时间。
1.2 基于加权聚类集成的标签传播算法
在介绍本文提出的新算法之前,首先给出网络、模块度、基聚类集、节点加权相似性度量等相关概念如下。

第t次运行标签传播算法所产生的单个聚类结果为一个基聚类,将多个标签传播算法的结果融合来代替单个标签传播算法的结果,使用聚类集成技术从结果集中发现最一致的结果。然而,聚类集成的结果会受到单个基聚类质量的影响,为了提高聚类结果的稳定性,因此提出加权相似性度量。
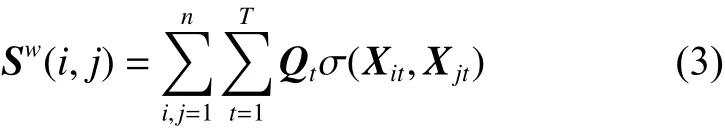
基于以上定义,提出基于加权聚类集成的标签传播算法。 用LPA算法对复杂网络进行次聚类,聚类产生的结果形成一个的基聚类集矩阵,然后根据定义4融入模块度在基聚类集上求出一个维的节点加权相似性矩阵,最后通过层次聚类算法产生最终的结果。其聚类过程如图1所示。

图1 算法框架Fig. 1 The framework of the proposed algorithm
具体算法步骤如下:
2 实验分析
2.1 实验数据
为了验证本文提出的算法的有效性,选取了5个不同规模的真实网络数据集,分别为football、dolphins、karate、web、word 数据集。其中football数据集是由美国橄榄球联赛中球队的比赛关系构成的网络,共包含115支球队。Dolphins数据集是由新西兰的一个海豚群体组成的海豚关系网,网络中的边表示两只海豚之间的频繁接触次数。Karate数据集是一个由34个空手道俱乐部成员之间的关系构成的社会网络,网络中的边表示两个俱乐部成员经常出现在俱乐部活动之外的其他场合的次数。Web数据集是某网站上所有网页构成的关系网,节点代表网页,边代表超链接。Word数据集是名词形容词搭配网络。数据集的信息描述如表1所示。

表 1 数据集描述Table 1 Description of network data sets
2.2 评价指标
本文使用标准互信息(normalized mutual information, NMI)和调整兰德系数(adjusted rand Index,ARI)来评价最终聚类质量。
标准互信息(NMI)和调整兰德系数(ARI)常常用于社区划分质量的评价,能有效衡量给定社区划分结果与真实网络划分的相似程度。NMI的定义为

ARI的定义为

2.3 实验结果分析
为了测试新算法的有效性,使其分别与5个现有的LPA的改进算法在真实数据集上进行了比较测试,这些LPA的改进算法包括LPA[10]、LPA_S[16]、LPAm[11]、LPAm+[12]、BGLL[18]。分别从NMI和ARI两个评价指标将新算法与经典算法进行了比较,每个算法在每个数据集上都运行了100次,实验结果如表2~3所示。通过对实验结果的对比分析显示,新算法的实验效果在football、dolphins、web、word 数据集上都有明显的提高,即其社区划分更接近于真实社区的划分,尤其是在 dolphins 数据集,该算法的效果较其他算法高出10%多。虽然在karate数据集上新算法的实验结果并非最高,但也表明新算法在大部分数据集上的表现仍然具有很大优势。同时,对于算法本身的性能的测评中,由于该算法只涉及因运行LPA算法次数的差异所形成的基聚类集的维度的不同对算法最终结果所造成的影响,因此本文也对运行不同次标签传播算法得出的最终社区划分结果进行了实验,实验结果表明,随着运行次数的增多,社区划分结果越稳定,且运行到一定次数时,社区划分效果均能趋于平稳。综上所述,本文提出的基于加权聚类集成的标签传播算法较其他算法在NMI和ARI上都有良好的表现,且算法本身表现也收敛,因此新算法能在社区划分的结果上更接近于实际社区划分情况,提高了社区发现的精确性。
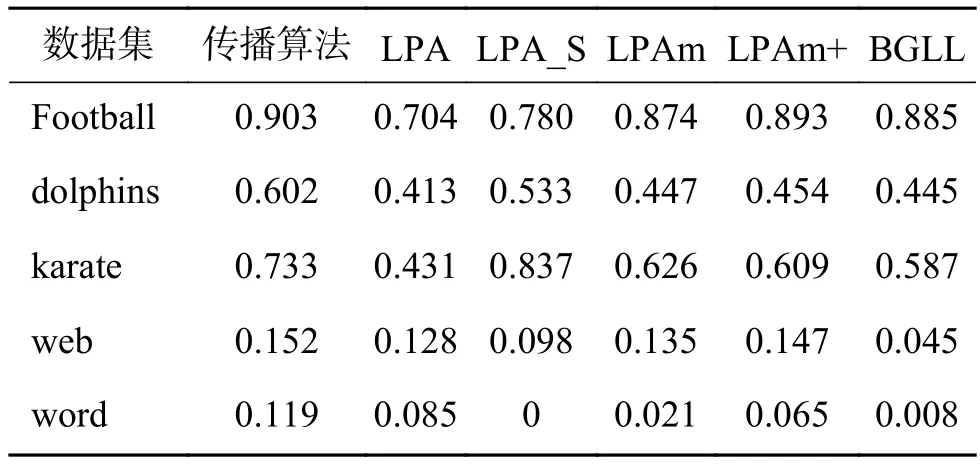
表 2 不同算法的 NMI值比较Table 2 Clustering results of different algorithms with respect to NMI

表 3 不同算法的 ARI值比较Table 3 Clustering results of different algorithms with respect to ARI
3 结束语
本文主要利用聚类集成技术对LPA进行了改进,提出了基于加权聚类集成的标签传播算法。该算法首先执行多次LPA产生多个标签传播结果作为基聚类集,并计算出每次LPA结果的模块度值作为对应基聚类的权重,然后计算出融入权值后的节点相似性矩阵,最后采用层次聚类方法得到最终的社区划分结果。在真实网络数据集上的实验结果表明,新算法在NMI和ARI两个评价指标上效果都有所提高,表明新算法可以获得更好的社区发现结果,提高了社区发现的精确性。
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12
装备制造技术(2020年2期)2020-12-14
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
铁道通信信号(2019年6期)2019-10-08
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
中国卫生(2015年12期)2015-11-10
