
机器学习常见算法在建模中的对比
2018-11-08 02:32程靖泽
电子制作 2018年20期
程靖泽
(西安市铁一中学,陕西西安,710000)
0 引言
机器学习是一门让计算机从部分数据中累积经验,在非编程条件下可以自主采取行动的学科。近年来,机器学习在预测、分类等方向应用的越发成熟,如垃圾邮件分类、价格行情预测等,极大推进了人工智能的发展。
机器学习基于不同的规则进行划分,比如基于目标值的有无分为:监督学习、无监督学习。其中针对监督学习,基于目标值是连续或离散划分为回归算法、分类算法;基于学习方式和预测方式的不同,可划分为生成模型、判别模型。
本文主要概述机器学习中常见的基本算法如线性回归、逻辑回归等基本概念、应用及优、劣势对比。在概述这些算法时,首先基于监督学习、非监督学习,对常见的机器学习方法进行划分,然后针对监督学习算法,再根据判别、生成进行划分。
其次,结合实际预测,展示了数学建模的流程,对其中的数据清洗、特征工程、模型对比等进行简要分析和总结。
1 常见机器学习算法
机器学习算法根据目标值有无,可分为监督学习、非监督学习。其中监督学习可理解为,训练数据中有目标值作为监督,可以判定类别或目标因变量的数值。因而监督学习包含了大多数机器学习算法,如线性回归算法、LR、SVM等。
监督学习算法的模型为 ()Y=fX ,或者是条件概率形式的概率分布函数 F(x )=P(y | x )。判别模型可以直接计算出决策函数 Y=f(X )或概率分布,而生成模型则是基于贝叶斯定理,由联合概率分布 P(X ,y)推导出条件分布的一类模型。
判别模型主要包括了线性回归算法、SVM、LR等多数算法,生成模型主要包括混合高斯模型、朴素贝叶斯、隐马尔可夫模型等。
■1.1 线性回归
线性回归作为最基本的机器学习回归算法,可分类为一元线性回归和多元线性回归,以二元线性回归为例,它的基本形式为
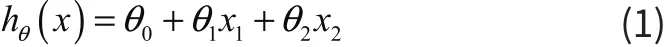
式中,x为特征属性,θ为模型参数, hθ(x)为模型。模型的学习目标函数是平方损失
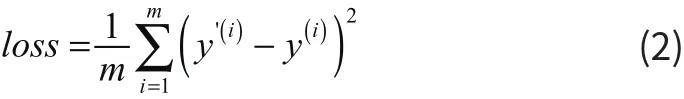
式中,y(i)为第i个样本的目标值, y'(i)为第i个样本预测值,m为样本数量。模型通过使loss最小化,来拟合出符合训练样本真实分布函数的最佳预测曲线,从而得出参数θ、映射特征和目标的关系式 hθ(x)。损失函数可通过梯度下降进行优化,不断迭代,从而计算出各个特征的权重θ。
■1.2 LR及softmax回归
LR对线性回归进行整改,因为线性回归y值区间通常是(- ∞,+∞),LR通过sigmoid函数将y值进行压缩映射。

上式为sigmoid函数形式。事实上这样得到的z值,物理意义上更像概率形式。设定阈值如ε,则二分类预测值y′如下:

由于非线性映射,若目标函数使用平方损失,则目标函数就会成为非凸函数,无法通过梯度下降取得全局最优。因而LR使用对数损失

这时的损失函数仍是凸函数,对于m个样本,整体的损失函数如下
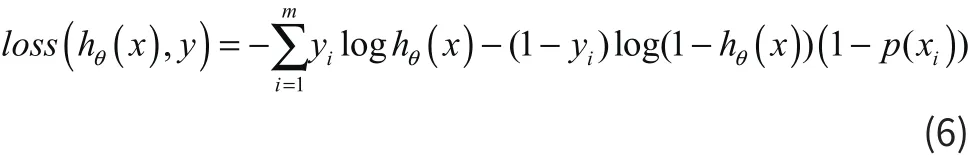
神经网络里也有这种映射机制。类比这里的sigmoid函数(激活函数,神经激活函数通常有sigmoid函数、tanh、Relu等)对上一层输入进行加工并输出。
而softmax回归,是对LR的扩充,实现了多分类问题的分类方法。它的损
失函数也是相应的扩充。假设n为类别数目,则输出形式则是一个n维的向量,预测的类别是输出向量中概率值最大的位置所对应的类别。
■1.3 SVM
SVM的目标是寻找超平面,将数据划分开。算法的关键在于如何确定超平面。
由于参数同比例放缩时,函数间隔相同,而几何间隔克服了这个缺点。因而SVM的目标函数是,几何间隔最大化,即几何间隔越大,分类确信度越高。
此外,与LR相比,SVM的优势在于,可以处理非线性数据,可以根据需要寻找合适的核函数(如果特征过多,可进行降维、特征选择,使用非线性核函数,更高维度),且对于缺失数据不敏感。
2 机器学习建模流程
本文主要介绍其中的数据清洗、特征工程、特征的归一化与标准化等内容。以预测房价为例,房价的影响因素有面积、地理位置、楼层、布局等多个。为了可视化效果,取其中2个作为特征。待预测的房价为y(单位为万元), 特征分别取sqft_living为x1、sqft_lot15为x2(由于涉及归一化,无单位)。整个流程分为数据清洗、特征工程、模型效果等。
■2.1 数据清洗
数据清洗主要是对原始数据进行一系列预处理,需要针对不同问题进行不同处理。如果数据维度高,则需要进行特征选择或降维,因为维度过高会带来维度灾难、过拟合等问题。
如果数据重复冗余,需要去重;数据缺失、或某些样本特征缺失,应根据需要,剔除样本,或者基于样本整体中该特征的分布,进行填充,或插值、拟合。插值方式有Lagrange插值或Newton插值法。拟合方式通常基于特征间的相关性建模,如回归拟合,建立该特征与其它特征的模型,预测特征缺失位置的数值。
■2.2 特征标准化与归一化
数据由于特征单位量纲的不同,取值量级可能存在着巨大的差异,需要通过标准化,或归一化进行处理,消除量纲。
标准化的前提是,假设数据符合正态分布,通过标准化处理使数据的分布为
均值为0,方差为1的标准正态分布。归一化,是为了消除由于单位不同导致不同特征之间数值差异巨大带来的不公平,压缩特征取值范围。最常见的归一化方式有线性转换、对数转换等,如最小最大归一化:

图1 未归一化

如图1和图2,未归一化和归一化的前后对比,数值取值范围差异巨大。

图2 归一化后
■2.3 特征工程
特征工程主要是对数据的特征进行分析、选择、映射等系列操作。其目的在于提升训练速度、模型准确度以及减少内存占用等。本文主要概述其中的特征选择和特征降维。
特征选择是指通过分析特征与特征之间的相关性、或特征与目标值之间的依赖关系,选择保留部分特征、剔除另一部分特征(如多个特征之间相关性很强,则只需要保留其中一个最重要的特征即可)。特征降维,主要运用协方差、特征值、特征向量等方式将数据从高维度上映射到低维度的空间,保留主要成分,丢弃噪声信息。
常见的特征选择方法有Pearson相关系数、卡方检验、互信息等方法。常见的特征降维方法有主成分分析(Principal Component Analysis, PCA)、线性判别分析(Linear Discriminant Analysis, LDA)等。
2.3.1 特征选择
由于特征间存在依赖关系,或者特征对目标的贡献、影响不同,所以需要对特征进行筛选。其目的在于,剔除对目标值不重要的特征,以及只保留对目标值同等重要的多个相关特征中的一个。
特征选择的方法有:对于离线的分类问题可以选择互信息,卡方检验(卡方值越高,拒绝概率越高,相关性越强);对于回归问题可采用皮尔森相关系数,F检验,稳定性选择,交叉验证等。基本思想是计算特征与目标之间的相互依赖,对特征的重要性进行排序。
2.3.2 特征降维
本文主要概述PCA降维,其中涉及到标准差、协方差等概念及原理。
标准差,反映变量相对中心的分布情况。协方差,反映两变量在变化过程中,是同向变化,还是反向变化,程度如何。Pearson相关系数,消除了量纲对协方差的影响,从而能达到如下效果—剔除变量的量纲、标准中的特殊协方差;反映两变量变化的同向、反向。

图3 PCA投影
PCA衡量数据重要性的主要依据是,投影方向上数据方差的大小,方差越大,越重要。因而将高维特征映射到较低维度,主要先对矩阵进行标准化,再求解协方差矩阵的特征值和特征向量。然后根据需要,选择协方差矩阵特征值最大的几个,达到去噪声,保留主要特征的效果。
2.3.3 特征降维与特征选择区别
PCA成立的假设前提是数据应该满足正交分布并且是高信噪比的,这符合多变量独立同分布的中心极限定理,整体服从正态分布。
PCA通过协方差矩阵的特征值和特征向量,旋转坐标得到主成分。所以如果输入数据不是高斯分布,特征值和特征向量就不能代表数据的特征,这样PCA也就失去了它的意义。
特征选择则是基于特征之间、或特征与目标之间的依赖关系,减少特征数;而PCA将高维的数据映射到较低的维度空间上,去掉的维度是噪声。

图4 SVM、LR等模型对比
3 模型效果对比
对于分类问题,可用准确率(accuracy)、精确率(precision)、召回率(recall)等衡量。对于回归问题,可用均方误差(Mean Squared Error, MSE)、平均绝对误差(Mean Absolute Error, MAE)等衡量。
MSE可以衡量预测值与真实值的变化程度,MSE的值越小,说明两者更接近,它的计算方式如下:
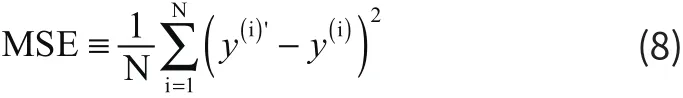
MAE反映了真实值与预测值的整体残差大小,它的计算方式如下:
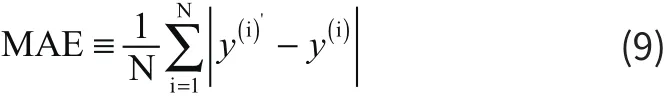
表1可知,线性回归的MSE值显著小于两种SVM的MSE值,线性回归的MAE值也显著小于两种SVM的MAE值。说明在房价预测案例中,线性回归准确度稍好于SVM。

表1 MSE、MAE对比
模型预测的时间性能对比上,线性回归显著快于SVM。因为SVM进行分类或者回归时,需要进行核函数的核卷积映射,而且核卷积是样本间两两做卷积,所以时间效率低。
因此,如果特征数量相比样本量很大,选用线性回归、无核的SVM或线性核的SVM。如果特征的数量比较小,样本数量一般,再考虑选用rbf核或高斯核的SVM。
4 总结与展望
本文首先概括了常用机器学习算法如线性回归,LR,SVM等,阐释相应算法的基本原理。然后结合分类预测实验,对机器学习算法实际建模流程,如特征工程、特征选择、模型选择等进行展示说明。由于时间和学识有限,关于机器学习算法如KNN、各聚类算法,以及集成算法均没有研究。其中集成算法结合了多种算法的优势,是目前应用的热门方向。
猜你喜欢
车主之友(2022年4期)2022-08-27
汽车实用技术(2022年4期)2022-03-07
舰船电子工程(2020年3期)2020-06-11
装备环境工程(2020年3期)2020-04-03
海峡姐妹(2019年12期)2020-01-14
经济研究导刊(2018年24期)2018-09-18
经济研究导刊(2018年19期)2018-07-24
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年25期)2016-11-16
考试周刊(2016年54期)2016-07-18
