
基于k近邻算法的心脏病在线辅助诊断系统
2018-11-08 02:32王浩瑞
电子制作 2018年20期
王浩瑞
(陕西省宝鸡市宝鸡中学,陕西宝鸡,721000)
0 引言
众所周知,医生误诊、医院挂号排长队、癌症患者发现疾病过晚等现象屡见不鲜。究其原因,一是由于医生的主观判断、医疗条件很容易影响决策结果,最终可能导致诊断结果出现误差;二是由于生活节奏的加快致各类疾病患者数量显著增加,这就需要医生花费更多时间来处理分析增加的数据,导致医疗效率低下;三是一些疾病无症状或症状较轻,病人不能及时进行筛查和发现,从而可能导致病情进一步恶化。在此背景下,基于机器学习的医疗辅助诊断系统成为云霓之望,该系统可以在极短时间内对海量病人数据进行分析,对疾病进行预测。这样不仅能够提高医疗诊断的精度,而且能加快医疗决策的速度,减轻医护人员的负担,是对误诊、排长队、治疗晚等问题的有效解决方案。因此,本研究对我国目前医疗矛盾的解决以及社会效率的提高都具有十分积极的意义。
随着医疗领域快速发展,传统医疗的弊端不断显现。如今,“人工智能+医疗”的理念普遍被人们接受,由于前景广阔,包括IBM、微软在内的互联网巨头以及银行、保险公司等金融机构正纷纷布局架构医疗人工智能。比如,IBM Watson能够在极短时间内总结病例的调研结果,有助于医生为单个癌症病患规划最高效的治疗方案;Google的子公司Verily对生命科学初创公司Freenome进行投资,开发早期癌症检测技术;在3E·2018北京国际人工智能大会上,Airdoc在现场就能够实时帮助观众检查疾病。 由此可见,医疗领域的智能化正一步步地向人们的生活迈进。
本研究将机器学习与医疗领域相结合,以python语言为主要编程工具进行数据分析。借助医疗大数据技术,该系统通过k近邻算法对已知心脏疾病数据集学习概率模型,再通过人机交互的方式,收集受测人的输入数据即各项心脏相关特征指标,并由学习到的模型对该输入数据进行分析,从而预测受测人有无心脏疾病。该系统既可以帮助受测人及时判断自己有无疾病,又可以辅助医院医生进行治疗,极大地提高了医疗诊治的效率和准确度。同时,随着社会的进步,国家也越来越重视医学领域的发展,相关领域数据集增加,这更加有利于机器学习算法进行建模,从而使预测准确率不断提高。
1 机器学习背景知识
■1.1 机器学习介绍
机器学习是计算机以数据为基础构建概率模型,并运用模型对数据进行预测与分析的学科,是人工智能的核心,是使计算机智能化的根本途径。本文利用机器学习的方法,从心脏病数据集出发,提取该数据集中受测人的身体特征,借助k近邻算法从而得出医疗辅助诊断模型,再通过该模型分析和预测新的受测人是否患有心脏疾病,是一个监督学习的二分类问题。
监督学习是机器学习的一种,它要求训练集数据既包含样本的特征,又包含样本的标签。即该训练集表示为:
T ={(x1,y1),( x2,y2), L(xn,yn)}式 中 x∈x⊆Rn为 实例 的 特 征 向 量, yi∈ y = {c1,c2,L,ck}为 实 例 的 类 别,i=1,2,…,N.
监督学习利用该训练集样本建立一个概率模型,再用已建立的模型对新的输入信息进行分析和预测。机器学习的目标是使最后的模型的预测效果更好,即模型的泛化能力更好。
■1.2 训练数据集介绍
本文选用的数据集来自UCI Machine Learning Repository网站,数据集名称为“Statlog (Heart) Data Set” ,它是从Cleveland Clinic Foundation收集到的心脏数据。该数据集包含270个样本实例和13个最主要身体医学特征,目标是预测受测人有无心脏疾病,标签1表示该样本没有心脏病,2表示有心脏病。该数据集特征名及其解释如表1所示。
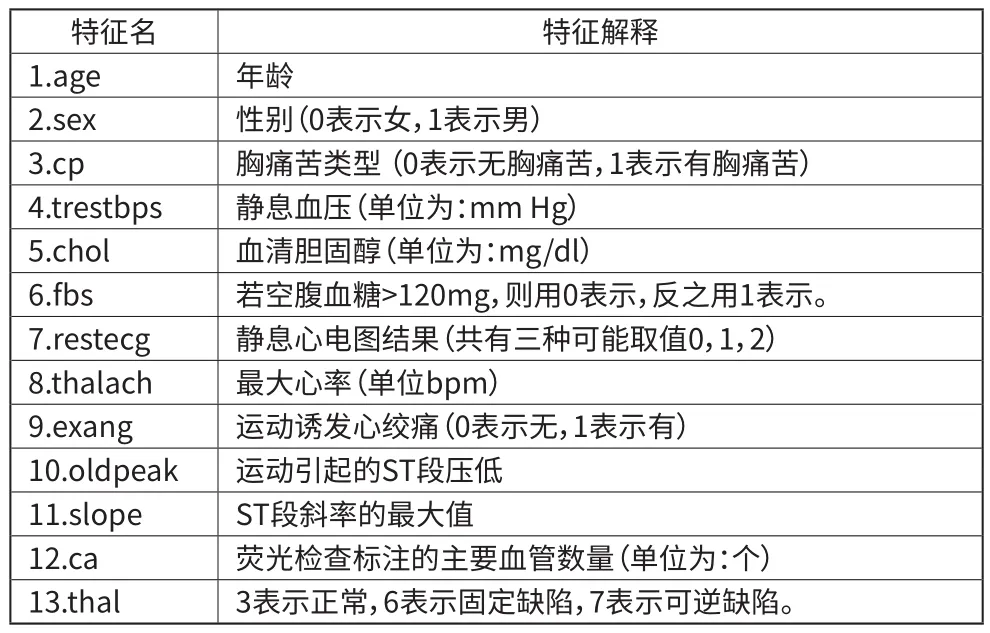
表1 特征名及特征解释
■1.3 数据集预处理
一般来说,机器学习算法受益于数据集的预处理,即把原数据规范化和整齐化。由于在线提供的数据集通常都有缺项、噪声等的问题,故只有通过数据预处理,才能使数据挖掘更有意义。标准化和归一化就是数据预处理时常用的手段。
1.3.1 标准化
数据集的标准化是许多机器学习分类器的共同要求。如果所有训练样本的某一特征的数据不符合标准正态分布,它们的预测性能可能会很差。标准化公式为:

其中X’为标准化后的数据,mean表示某一特征所有数据的平均值,std表示该特征所有数据的标准差。
标准化后的结果使每列数据均值为0,方差为1,符合标准正态分布。使用preprocessing模块中的scale函数,可以直接将给定数据进行标准化。
1.3.2 归一化
归一化是将样本数据缩放到某个区间的过程,使数据整齐,更有利于机器学习方法建模。归一化公式为:

式中Xnorm为归一化后的数据,X为原始数据,Xmax、Xmin分别为原始数据集的最大值和最小值。结果是可以将属性缩放到区间[0 ,1]内,对原始数据的等比例缩放。
■1.4 输入格式化数据
由于格式化、模块化后的数据更有利于计算机机器学习算法的识别,因此输入的新数据需要用Excel表格进行封装,之后利用python编程语言里的pandas模块导入即可。
■1.5 预测数据
利用k近邻算法和心脏训练数据集构建出来的概率模型可对新的格式化后的数据的特征进行分析预测,即可得出新输入样本的标签。
2 k近邻算法模型
■2.1 k近邻原理介绍
本文利用k近邻算法进行机器学习建模和预测。k近邻算法是机器学习中一个基本的分类和回归算法。它的原理为:给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的k个训练实例,这k个实例的多数属于某个类,就把该输入实例分为这个类。
■2.2 基本要素
由上文可见,k近邻算法具有三个基本要素,分别是:k值的选择,距离度量和分类决策规则。
其中,k值的选择十分重要,会对k近邻模型产生较大影响。若k值较小,即使用较小的训练实例邻域预测,使预测结果对近邻的实例点非常依赖,容易发生过拟合;若k值较大,即使用较大的训练实例邻域预测,使与输入实例较远的实例点对预测结果产生影响,容易发生欠拟合。两种情况都会使最后的测试误差较大,应在实验中避免出现,本文利用交叉验证的方法来选出针对该医疗数据集的最理想的k值。
距离度量的作用是衡量两个实例点之间的距离,用于判断两个点的邻近程度。本文以欧式距离作为距离度量的方法,即两个样本点之间距离为:
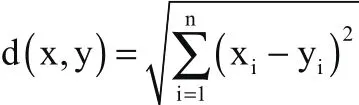
分类决策规则是判断实例类别的关键,本文选用多数表决的方式,即:

其中i=1,2,...,N;j=1,2,...,K。 Nk(x)表示涵盖这k个点的x的邻域,I为指示函数,当 yi=cj时i为1,否则为0。
■2.3 构造k近邻模型
k近邻模型为一个包含训练数据集中所有训练数据样本点的特征空间。在本研究中,训练集共有13个特征,构造k近邻模型即把该心脏数据集中的所有样本代入到该13维特征空间中。
■2.4 利用模型分析预测新数据
本文首先计算受测人心脏数据点与所有已知标签类别的训练集实例点之间的距离,再按照距离大小升序排序,接着选取与当前心脏数据点的距离最小的k个训练实例点,最后把在这k个实例点里出现频率最高的类别作为新受测人心脏数据点的类别。
■2.5 利用交叉验证衡量模型质量
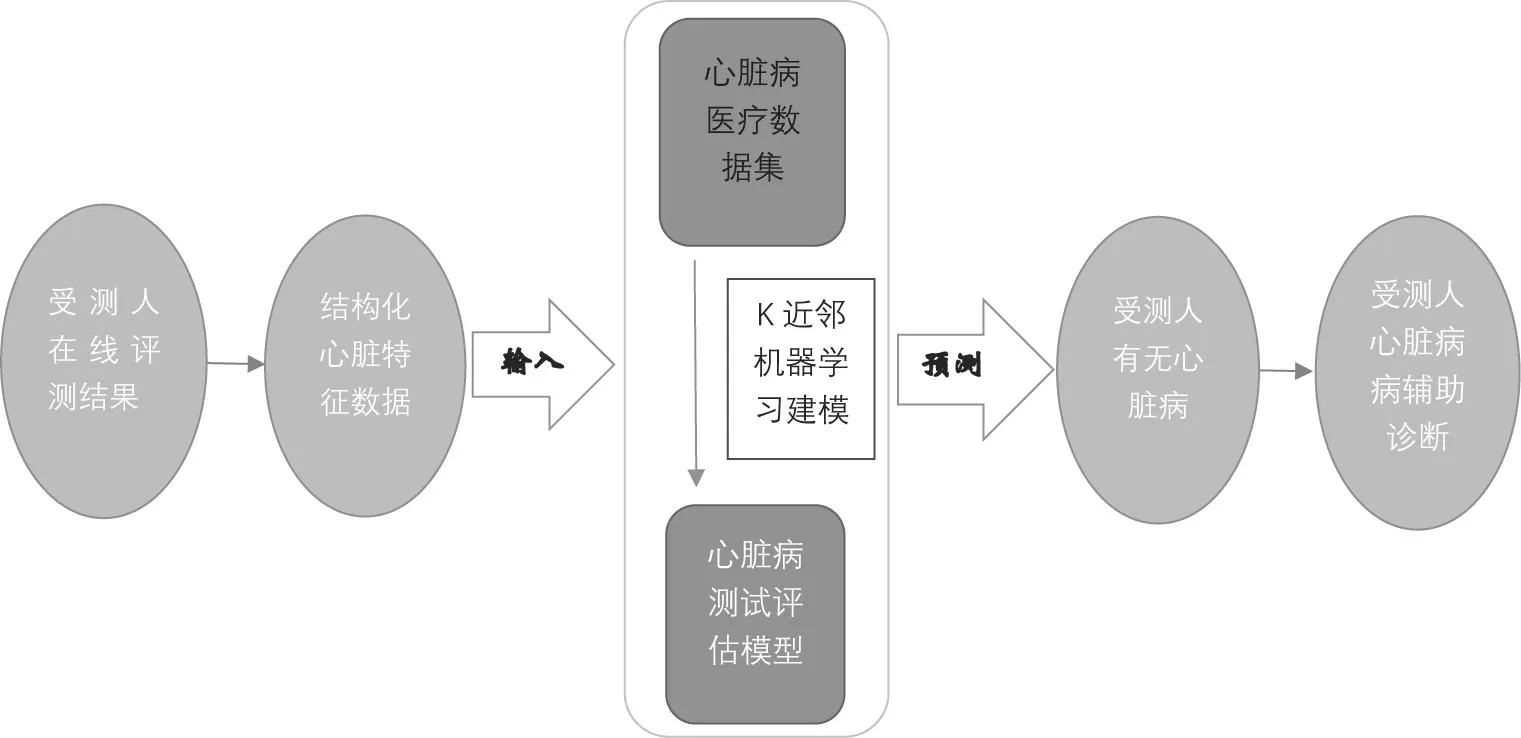
图1
本文利用交叉验证的方法来衡量取不同k值时的心脏模型的质量,最后取测试误差最小的k值作为最终模型的k值。交叉验证首先把选取的心脏数据集分成训练集和测试集,训练集用来训练心脏病预测模型,测试集用来测试该模型的质量,测试集上的准确率为验证集中分类正确的样本数与验证集总样本数的比值,直接决定模型的好坏。本文将训练集与测试集按心脏数据集的70%与30%的比例划分。
3 可实现的功能
本研究整体流程如图1所示。
该辅助诊断系统是以已知心脏医疗数据集为中心 ,通过k近邻机器学习算法构建概率模型,即心脏疾病测试评估模型。被测人可以在线将自己的身体信息输入到该平台,系统可自动将该输入的特征信息进行格式化,即用Excel表格把信息封装起来。然后将格式化后的数据输入到已建立的心脏疾病评估模型中,后台会对该数据进行模型分析,最后对被测人的标签进行预测,即得到被测人是否有心脏病的结果。
该系统可以让被测人及时知道自己的身体状况,也可以辅助医疗人员对被测人有无心脏病进行预测分析,极大提高了医疗诊断的效率和准确度。
4 项目代码及预测结果
Python是一种计算机程序设计语言,由荷兰人Guido van Rossum于1989年发明,它具有语法简洁的特点 ,并且可以导入功能非常强大的包。本程序所使用的机器学习Sklearn包,是 Python 语言中一个高效的数据挖掘与分析的工具。
代码的2至6行是利用import函数导入本文所需编程包,7-11行是把格式化后的受测人的身体特征信息导入到程序中并利用numpy包里的array函数转化为二维数组;12-14行是训练数据的预处理,操作分别为标准化和归一化;15行是利用train_test_split函数进行交叉验证,将原数据集按70%和30%的比例划分训练集和测试集;18-20行是利用sklearn包中的neighbors模块对模型进行训练和预测;22-25行的作用是计算所有k值情况下的准确率并保存在rate列表中;26-28行是选出最好的准确率与该准确率下的k值,最后得出适用于该心脏医疗数据集的最好的k近邻机器学习模型。

图2
代码执行结果如图2所示。
因为该心脏病数据集的数据仅有270个样本,所以执行时的各k值情况下的准确率相差不大,最好的准确率为86%,在当前情况下这是比较合理且比较满意的结果。
5 结语
随着近些年来人们对医疗的需求提高,传统医疗逐渐难以满足人们的需要,因此“人工智能+医疗”的新型医疗研究逐渐被人们所重视。本文从智能医疗的重要性出发,分析了智能医疗的现状。接着对机器学习的概念、本文使用的心脏数据集进行了简明的介绍,进而引出适合该数据集的机器学习算法:k近邻算法。之后详细阐述了该算法的原理以及如何利用心脏数据集训练模型、如何利用多个维度的特征对被测人是否患有心脏病进行预测等问题。最后对本项目所使用的代码以及预测结果进行了详细的介绍和分析。
文中详细阐述了基于机器学习的人工智能医疗的重要性和优点,但其也具有一定的局限性:一是计算机技术尚处于初步发展阶段,并且医疗领域十分注重病患的隐私,因此我们所能得到的医疗数据集是极其有限的;二是在线公开的医学数据集中的数据不够一致,格式不够标准,不能被机器学习工作所直接使用。上述两点都会导致通过机器学习建模的疾病预测出现误差,因此人工智能医疗还处于初步发展时期,有很大的提升空间。针对这些问题,作者相信随着社会的进步以及国家的大力支持,借助未来不断扩充着的标准化数据集,人工智能医疗会一步步登上历史的舞台。
猜你喜欢
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
电影(2018年8期)2018-09-21
科学大众(中学)(2015年10期)2015-10-12
小学生·多元智能大王(2015年7期)2015-07-03
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
祝您健康(1989年1期)1989-12-30
